

最近我们在尝试深度学习模型,离线的auc已经高于基线,上线后ctr表现也由于基线,但是基于线上实际反馈的打点日志,深度学习的模型的auc要明显低于基线。但以前的模型迭代auc是可以和线上ctr对应的。
这个问题比较奇怪,一般情况下,因为线上样本存在bias,将新模型同时去测试基线流量和实验流量时,实验流量的auc会略高于基线流量。
可以这样理解,新的模型的增量是带来了一些新的好样本,但是如果直接去评估基线的数据,由于推荐或排序的数据是动态反馈的,这部分的好样本就没有了,auc会偏低。但我们的实验情况恰恰是相反的。
分析gauc指标
第一反应是auc这个指标失真了,由于排序是个性化的,不同用户之间的排序结果不可比,不同用户的负样本的得分可能比正样本高,导致全局AUC指标失真。
举个例子:假设有两个用户A和B,每个用户都有10个商品,10个商品中有5个是正样本,我们分别用A+,A-,B+,B-来表示两个用户的正样本和负样本。也就是说,20个商品中有10个是正样本。假设模型预测的结果大小排序依次为A+,A-,B+,B-。如果把两个用户的结果混起来看,AUC并不是很高,因为有5个正样本排在了后面,但是分开看的话,每个用户的正样本都排在了负样本之前,AUC应该是1。显然,分开看更容易体现模型的效果,这样消除了用户本身的差异。
考虑到用户的每个样本之间的差异,一般将样本权重加到auc系数上去,这样计算更为合理。前面这种情况发生的前提是:两个用户的排序预测结果相互干扰,也就是分数越相对集中,正负样本在不同用户之间差异越大,导致线上的排序效果看似降低,但每个用户的auc计算不受干扰,各项线上指标并未降低。
我们采用了阿里提出来的gauc定义:
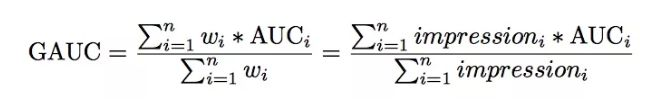
再统计后的指标如下:

我们发现了gauc后,diff变小了,但是还是基线高,说明gauc和ctr也不一致。
用户分数分布
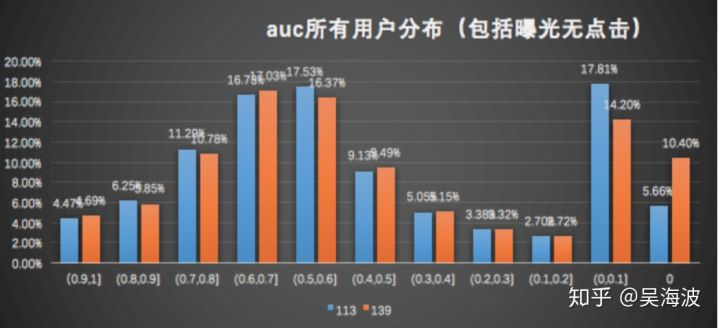
可以看到,auc分布中,实验无点击的曝光用户数量增加,在auc[0,0.1]区间基线auc较差。考虑到用户auc为0的用户数量,曝光并不多,
例如113 为0.4%,139为(1.2%),曝光增加1.565%,说明除了曝光,在有用户行为的样本中用户更愿意曝光。
接下来把这种样本去掉,考虑有点击行为的用户
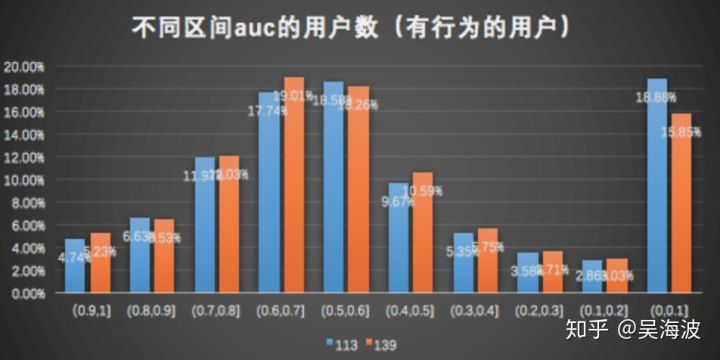
我们看到,用户在【0.6,1】这个区间,实验对比基线用户auc预测更贴近真实label分布。我们认为在用户auc=0的用户中图墙占比更多,实验比基线略高。从有行为反馈的用户中,auc在高分段实验更有优势。
用户auc的计算说明
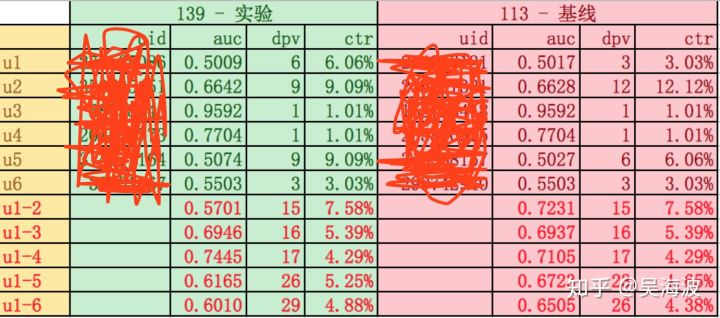
上图中,我们选取了5个用户,他们在基线和实验的单用户auc是接近的,但是在两两用户的样本组合后,实验和基线的auc差别很大。说明实验和基线的模型分数分布差距很大,单独看gauc也不能说明问题。
抽样观察每个用户一个浏览路径下的商品预测分数,我们发现基线和实验的斜率是不一样的,也就是更容易发生上面说明的情况。
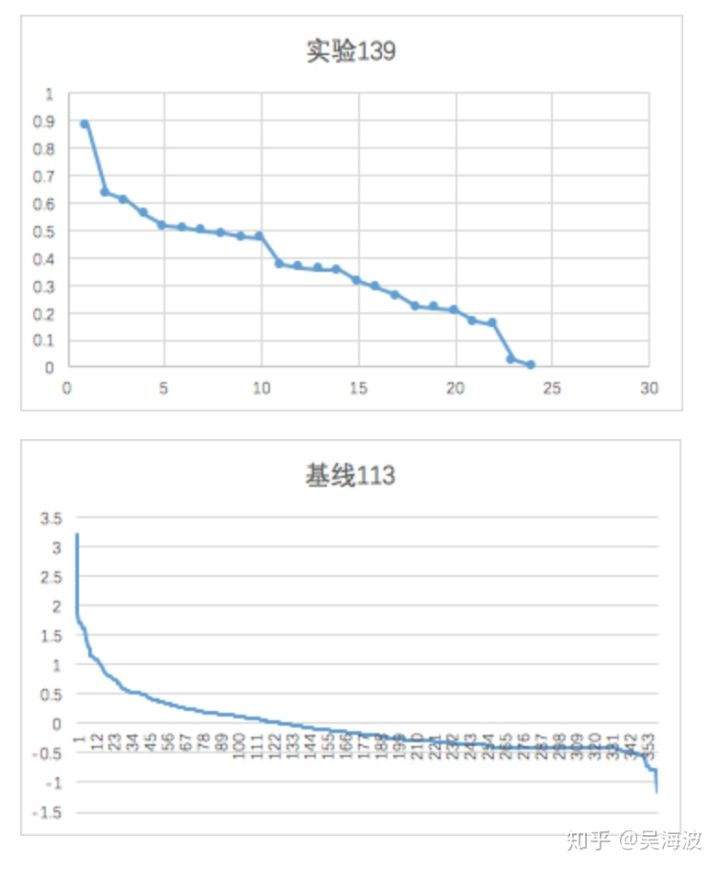
我们发现基线的模型,在分数预估上两级分化明显。
结论
由于基线是大规模离散模型,特征以0和1为主,会导致个性化命中和不命中的score分数diff很大,而深度模型是基于embedding做的,在计算个性化上,分数变化会更均匀,导致更多相近的难以区分的样本出现在样本集里,导致二者的样本分布发生剧烈变化。导致auc不可比,gauc只能参考。
在模型发生剧烈变化时,会带来很多意想不到的问题,深入分析后能对模型和数据有更好的认识。
