

笔者之前在工作期间接触过超分辨率领域的任务,最终实现了SRGAN with WGAN算法,也对这个算法进行了开源及文章介绍(SRGAN With WGAN,让超分辨率算法训练更稳定)。但在工业界应用的时候,如果遇到的是带有失真的JPEG图片,超分的图片依然会带入压缩伪像(compression artifacts),导致最终的效果欠佳。这次为大家介绍ICCV2017中一篇有关失真消除的工作,来自L Galteri et al.的《Deep Generative Adversarial Compression Artifact Removal》[1]
Compression Artifact
在对算法进行介绍之前,我们先来了解一个概念——Compression Artifact,这个短语直译过来叫“压缩失真”,意思就是图片在压缩保存、格式转换过程中产生的图片失真现象。
图片有很多种格式,比如最常用的png、jpg格式,其中png格式称为“无损格式”,jpg格式则为“有损格式”。顾名思义,“有损”就代表jpg格式在保存的时候会丢失一些“人眼难以察觉”的信息,从而使得图片体积变小,方便储存、传输;而“无损”的png格式则可以保留图片的全部信息,但体积较大。
我们来看看两种最常见的图片失真现象。
- ringing artifact
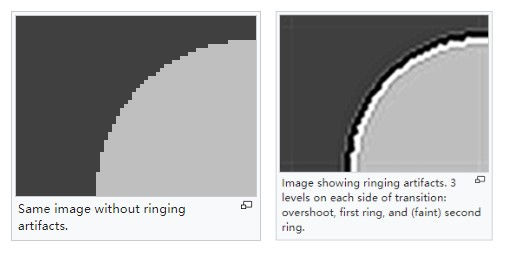
ringing artifact 振铃效应,上图左边是无振铃效应的高清图片的物体边缘,可以看到前后景交界的地方是很分明的;而右边的图则有振铃效应,可以看到边缘地方产生了“涟漪”一样的过渡效果(灰-黑-白-淡灰)。
- blocking artifact
blocking artifact就是在图像上会出现一些“方格”的效果,类似于“马赛克”的情况,如下图,猫咪左耳背以及地板上都出现了严重的blocking artifact。

还有其它类型的artifacts,详细介绍可以到这个维基百科链接查看。
超分辨率与失真消除
在本质上,超分和失真消除是两个不同的任务,超分辨率负责把“低分辨率”的图片resolve成“高分辨率”的图片,同时保留更多的图像细节;而失真消除指的是在JPEG一类使用有损压缩的图像上,把ringing artifact、blocking artifact等失真效果消除,此过程没有改变图像的分辨率。


从上面长颈鹿的对比图可以看到,白圈地方把“红红绿绿”的失真效果消除了,同时保持图像的分辨率。超分辨率任务其实也可以利用失真消除任务的优点,对于超分JPEG低质量的图片有帮助,我们后面再谈。
模型介绍
作者提出了一个基于GAN训练的全卷积残差网络(fully convolutional residual network model trained using a generative adversarial framework)来消除JPEG图片的失真现象,效果如下图所示:

作者在文中首先吐槽了PSNR、SSIM这类图像质量评测标准根本体现不了实际肉眼观察的图像质量,因此提出了两种模型,一种是针对优化SSIM(Structural Similarity index)损失函数的单模型,一种是针对优化包含生成对抗损失的GAN模型,由于前者只是在SSIM、PSNR评测上数值高,但是实际肉眼效果不佳,因此这里不作介绍,重点介绍后者。
生成器Generator
失真消除任务过程中要求图像尺寸不变,因此自然而然我们需要一个类似FCN的模型,这种模型输入输出尺寸保持一致,即输入一个带有失真效果的图像,输出一个消除失真的图像,相当于模型要学习一个能实现这种转换的函数。
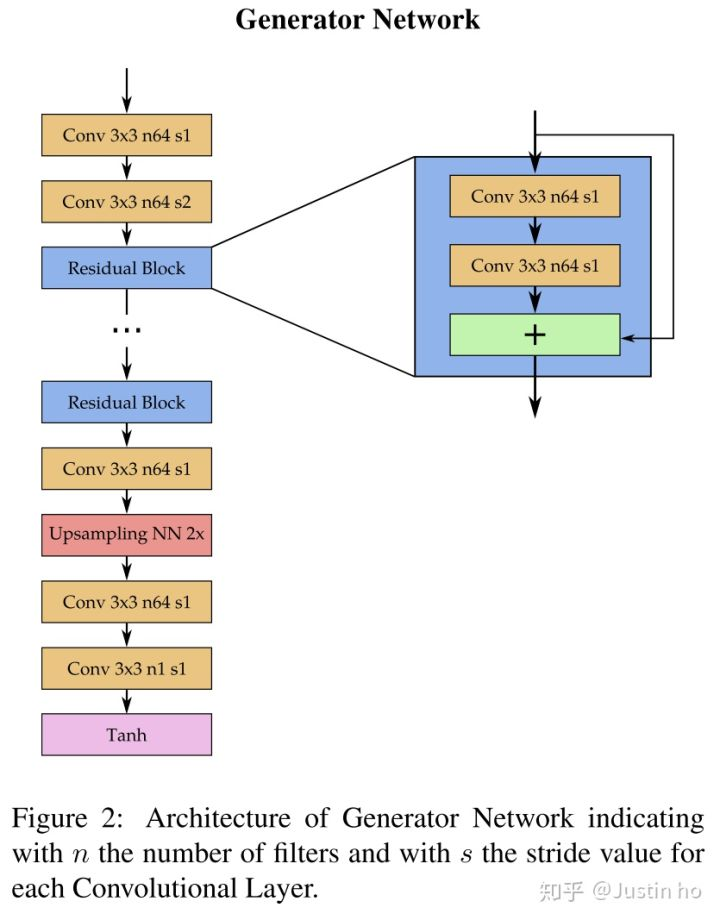
模型首先输入到两层卷积层,第一层卷积层用于提取初步特征,注意第二层卷积层使用了步长为2的strided convolution,此时feature map尺寸变成了二分之一,此后直到最后的Upsampling层之前都保持尺寸不变,而Upsampling层再使用最近邻插值的方法放大为原尺寸,这样做能够大大减少计算量(在超分领域的subpixel network也是类似的操作,但不是使用最近邻插值的方法)。而另外一点,据Chris Olah等人的研究,模型到最后先使用这种传统的upsampling操作再接卷积层能够有效消除checkerboard artifact(棋盘型失真),大家可以看看这篇文章:Deconvolution and Checkerboard Artifacts
中间使用了许多residual blocks的堆叠,每个residual block包含两个卷积层,每个卷积层接的激活函数都是LeakyRelu。而此时的padding为1,strides也为1,但这里的padding并不是pad 0,而是使用复制的操作,以缓和边界伪像的效果。最后一层使用tanh激活,使得数值范围在[-1, 1]之间,与输入的范围相同。
所以生成器的结构算是比较中规中矩,用到了当前流行的residual block、类FCN(或者类似Unet)结构等等,但没有尝试引入底层特征的操作,比如类似U-net的跨层连接,也有可能是怕引入底层特征中的artifact,有心思的朋友可以尝试下。
判别器 Discriminator
作者使用的判别器模型结构也是比较普遍的情况,像VGG那样的纯卷积层堆叠,卷积核大小均采用3×3(最后一层2×2),no padding,一共6层卷积,最后接一个sigmoid输出这张图是原图的概率。
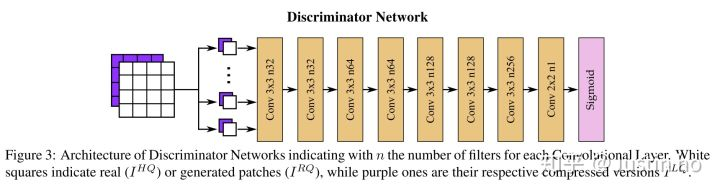
有意思的是,这里最后没有使用全连接层,最后一层卷积也没有接使用pooling,如果输入的是一张224×224的图片的话,最后一层卷积的feature map的尺寸不可能是1×1,这样sigmoid会输出一个矩阵,而不是一个数。这样设计是因为作者在输入图片之前把图片切成一个个16×16的“sub-patch”,那么输出的尺寸就是1×1×1(有兴趣的读者可以自己验证一下)。作者通过实验发现,通过使用这些sub-patch来训练判别器,能有效消除“mosquito noise and ringing artifacts”,如下图:

值得注意的是,在判别器这里使用了Conditional GAN的做法,判别器的输入是HQ|LQ或者 RQ|LQ。这里的HQ|LQ指的是把“高质量”和“低质量”图片的tensor,以channel维度直接concatenate起来,作为模型的输入,RQ|LQ同理。目的是通过引入特定条件来引导判别器去提高识别能力,利用了多方面的信息或者跨模态的信息。
损失函数
- 生成器的损失函数:
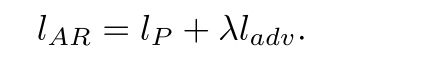
生成器的损失函数由两个部分组成,其中lp是图像风格迁移常用的content loss:
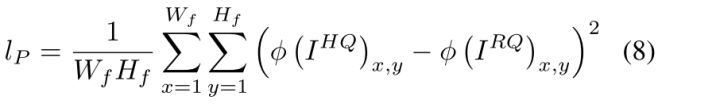
这里的W、H指的是在VGG19上最后一个MaxPooling层前的第二个卷积层的激活feature map,因此除了生成器、判别器之外,还要准备一个预训练好的VGG19,把生成器生成的RQ图和HQ图分别输入VGG19,提取该层的特征图,计算content loss。
ladv则是标准的对抗损失:
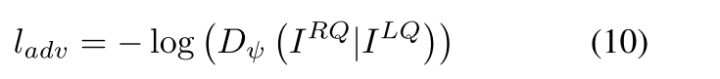
即把RQ|LQ输入到判别器中(此时判别器已结束训练),输出的结果再取-log。
- 判别器的损失函数:
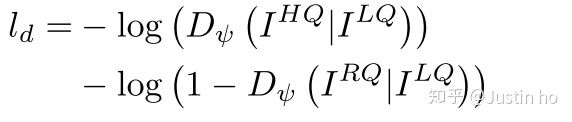
也就是常见的二分类交叉熵函数,这里应该理解成当输入何种照片时,只需计算相应部分的loss,另一部分忽略。
训练过程
很遗憾,作者在论文中并没有公开模型训练流程以及模型代码,尤其是生成器、判别器的交叉训练周期秘而不宣,这增加了第三方复现的难度。只提到了以下训练细节:
All the networks have been trained with a NVIDIA Titan X GPU using random patches from MSCOCO [19] training set. For each mini-batch we have sampled 16 random 128×128 patches, with flipping and rotation data augmentation. We compress images with MATLAB JPEG compressor at multiple QFs, to learn a more generic model. For the optimization process we used Adam [16] with momentum 0.9 and a learning rate of 10−4. The training process have been carried on for 70, 000 iterations. In order to ensure the stability of the adversarial training we have followed the guidelines described in [28], performing the one-sided label smoothing for the discriminator training.
到目前为止github上也还没有第三方复现的项目,通篇论文看下来,网络结构搭建不难,主要是训练流程比较玄学。
目标检测的应用
作者在文中思考如果把图片先经过失真消除,再进行目标检测是否能提高目标检测的mAP?于是作者把Pascal VOC2007的数据集先压缩成20%质量的JPEG图片,然后用不同的算法对压缩后的图片进行失真消除,再测试Faster RCNN对这些经过不同处理后的图片进行目标检测的成绩,如图所示:
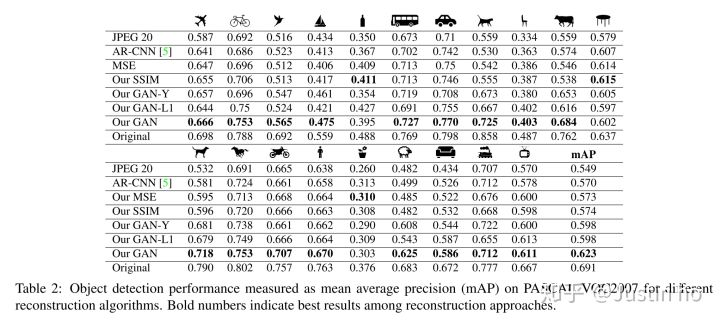
可以看出,经作者提出的算法进行失真消除后,比没有经过失真消除的mAP足足多了7个点,证明失真消除对于目标检测任务有一定程度的提升(工业界中确实存在许多失真图片)。
超分辨率的应用
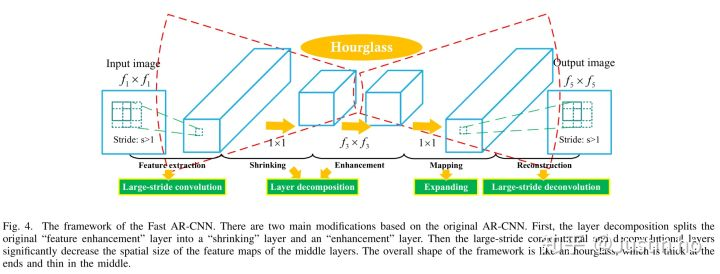
作者在文中并没有提到在超分领域的应用,主要是笔者之前在实现超分任务时,工业界中存在许多低清晰度图片伴随着失真的效果,此时如果直接超分,会把失真效果也带到复原图中,影响效果。因此当时笔者参考了ARCNN[2],希望把ARCNN与SRGAN结合起来,用一个模型同时解决失真消除和超分的问题。ARCNN结构如下图所示:
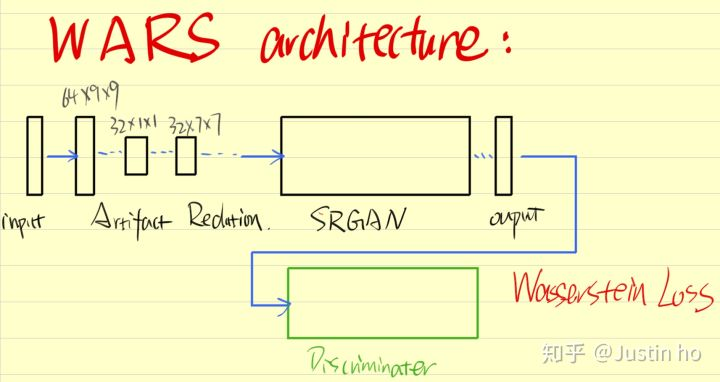
笔者在SRGAN的浅层网络中假如类似ARCNN的卷积结构,然后引入WGAN,将其命名为“WARS”。但是实际上训练下来loss非常难降,而且参数量庞大,导致11G显存的1080ti都稍显吃力。经过多次的实验后,发现可能把超分和失真消除结合在一起并不是很好的idea,或许分开实现,先经过失真消除模型,再经过超分辨率模型,这样效果可能会更好。
效果欣赏


以上图片都是截取自作者展示的官网:Artifact Removal Lens,有兴趣的朋友可以查看其余ARCNN的失真消除效果对比。不得不说,引入GAN后,物体的细节比较丰富,而ARCNN的效果则是比较“模糊”、“平滑”(MSE loss的缺点)。
总结
超分辨率、失真消除、图像去噪、去雾等等基础任务都可以对所有计算机视觉算法的性能提到一定程度的提升,在工业界中尤其如此,不可能所有摄像头都能拍出高清的图像,有一些情况也不需要高清图像,比如无人机视觉,图像太大反而影响传输速度。希望后面有越来越多的工作能针对这些基础任务进行拓展,如果能有一个算法能端对端的解决多个问题,这样工作也是非常伟大的。我们期待这样的工作出现!
参考文献
[1] Galteri, Leonardo Seidenari, Lorenzo Bertini, Marco Del Bimbo, Alberto. Deep Generative Adversarial Compression Artifact Removal. ICCV 2017.
[2] C. Dong, Y. Deng, C. Change Loy, and X. Tang. Compression artifacts reduction by a deep convolutional network. In Proc. of IEEE International Conference on Computer Vision (ICCV), pages 576–584, 2015.
