

上一期说了官网建议的一些数据输入方式,除了自己能逐个读取图片数据进行输入之外,还能用官方的generator来进行数据的自动生成。这期的花式数据输入,就教大家手动写一个自定义的生成器或迭代器出来,实现多线程多进程训练哦!这样遇到一些需要特殊操作的模型,比如faster-rcnn或者RPN,这类输入不能直接使用官方的API,就要自己写一个出来了。
一、生成器-Generator
如果熟悉python的generator都知道,生成器是能够被无限循环、不断yield数据出来,不熟悉的同学可以稍微看看这里:python生成器-廖雪峰。我们先来构建一个生成器:
import glob
import math
from PIL import Image
import numpy as np
def read_img(path, target_size):
try:
img = Image.open(path).convert("RGB")
img_rs = img.resize(target_size)
except Exception as e:
print(e)
else:
x = np.expand_dims(np.array(img_rs), axis=0)
return x
def my_gen(path, batch_size, target_size):
img_list = glob.glob(path + '*.jpg') # 获取path里面所有图片的路径
steps = math.ceil(len(img_list) / batch_size) # 确定每轮有多少个batch
print("Found %s images."%len(img_list))
while True:
for i in range(steps):
batch_list = img_list[i * batch_size : i * batch_size + batch_size]
x = [read_img(file, target_size) for file in batch_list]
batch_x = np.concatenate([array for array in x])
y = np.zeros((batch_size, 1000)) # 你可以读取你写好的标签,这里为了演示简洁就全设成0
yield batch_x, y # 把制作好的x, y生成出来然后我们导入keras自带的ResNet模型,使用fit_generator进行训练。
# 代码紧接上面
from keras.applications import ResNet50
from keras import optimizers
path = '/home/ubuntu/dataset/yoins_all/img/'
model = ResNet50()
model.compile(optimizer=optimizers.Adam(1e-4), loss='categorical_crossentropy')
batch_size = 64
steps = math.ceil(len(glob.glob(path + '*.jpg')) / batch_size)
target_size = (224, 224)
data_gen = my_gen(path, batch_size, target_size) # 使用上面写好的generator
model.fit_generator(data_gen, steps_per_epoch=steps, epochs=10, verbose=1,
use_multiprocessing=False, workers=2)二、Sequence-序列数据
细心的读者可能会发现,上面使用fit_generator的其中一个参数“use_multiprocessing”设置为False,也就是不使用多进程来输入数据进行训练。为什么不能用多进程?keras给出的说明如下:
using a generator with `use_multiprocessing=True` and multiple workers may duplicate your data. Please consider using the`keras.utils.Sequence' class.
意思是如果你使用generator的时候,如果设置多进程输入,代码就会把你的数据复制几份,分给不同的workers进行输入,这显然不是我们希望的,我们希望一份数据直接平均分给多个workers帮忙输入,这样才是最快的。而Sequence数据类能完美解决这个问题。
大家可以看看Sequence的官方说明:Utils - Keras Documentation。我们需要把数据生成的方式写成一个迭代器的形式,定义一个Sequence类,类内要包含“__init__”、“__len__”和“__getitem__”3个方法。下面直接给出例子:
import cv2
import glob
from keras.utils import Sequence
import math
import numpy as np
class SequenceData(Sequence):
def __init__(self, path, batch_size, target_size):
# 初始化所需的参数
self.path = path
self.batch_size = batch_size
self.target_size = target_size
self.x_filenames = glob.glob(self.path + '*.png')
self.x_filenames.sort(key=lambda x: int(x.split('/')[-1][:-4]))
def __len__(self):
# 让代码知道这个序列的长度
num_imgs = len(glob.glob(self.path + '*.png'))
return math.ceil(num_imgs / self.batch_size)
def __getitem__(self, idx):
# 迭代器部分
batch_x = self.x_filenames[idx * self.batch_size: (idx + 1) * self.batch_size]
x_arrays = np.array([self.read_img(filename) for filename in batch_x]) # 读取一批图片
batch_y = np.zeros((self.batch_size, 1000)) # 为演示简洁全部假设y为0
return x_arrays, batch_y
def read_img(self, x):
try:
img = cv2.imread(x) # 这里用cv2是因为读取图片比pillow快
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #opencv读取通道顺序为BGR,所以要转换
img = cv2.resize(img, self.target_size)
except Exception as e:
print(e)
else:
return img接下来的训练部分跟generator部分的基本上相同了,不过现在是可以使用多进程了,当你数据量大的时候,多进程能够让你的GPU保持98%以上的使用率,这样你的训练就非常高效了!(GPU如果在等待CPU喂数据,训练时间就变长了)
# 代码紧接上面
from keras.applications import ResNet50
from keras import optimizers
path = '/home/ubuntu/huzhihao/qinquan/yoins/dataset/1121_4/a/anchor/'
model = ResNet50()
model.compile(optimizer=optimizers.Adam(1e-4), loss='categorical_crossentropy')
batch_size = 64
steps = math.ceil(len(glob.glob(path + '*.png')) / batch_size)
target_size = (224, 224)
sequence_data = SequenceData(path, batch_size, target_size)
model.fit_generator(sequence_data, steps_per_epoch=steps, epochs=10, verbose=1,
use_multiprocessing=True, workers=2)三、彩蛋
写这篇文章之前,我测试了一下,同一个Sequence数据(1000张图片),同一个ResNet模型,如果用多进程和单进程多线程分别来比较速度,结果会是怎样?

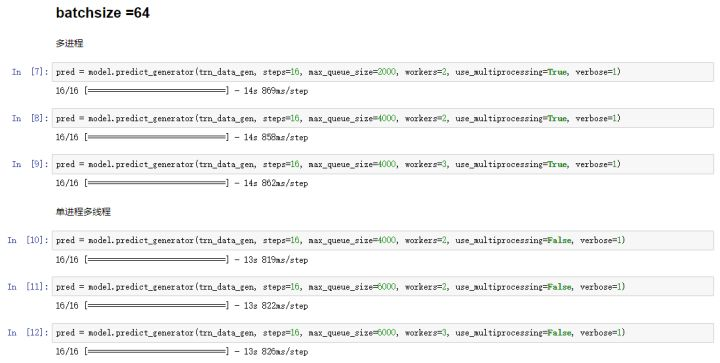
可以看到,使用多进程和单进程多线程在这个数据量的时候并没有很明显的速度差别,估计是数据量太少的原因,大家可以拿imagenet级别的数据量来试试。另外,测试到结果发现workers数量等于2或3的时候速度是最快的,因为太多的workers增加了通讯时间,反而减慢了速度。本节的代码可以在我github找到,地址是:JustinhoCHN/fancy_keras
如果你觉得有用,请点赞或分享给您的朋友!
