

一、理解熵
1、首先看到这个词会产疑问,熵是什么?谁定义的?用来干什么的?为什么机器学习会用到熵?
有了这些疑问后慢慢的开始探索~
熵,热力学中表征物质状态的参量之一,用符号S表示,其物理意义是体系混乱程度的度量。 克劳修斯(T.Clausius) 于1854年提出熵(entropie)的概念, 我国物理学家胡刚复教授于1923年根据热温商之意首次把entropie译为“熵”。A.Einstein曾把熵理论在科学中的地位概述为“熵理论对于整个科学来说是第一法则”。
为了理解熵,必须讲一点物理学。
19世纪,物理学家开始认识到,世界的动力是能量,并且提出"能量守恒定律",即能量的总和是不变的。但是,有一个现象让他们很困惑。
物理学家发现,能量无法百分百地转换。比如,蒸汽机使用的是热能,将其转换为推动机器的机械能。这个过程中,总是有一些热能损耗掉,无法完全转变为机械能。
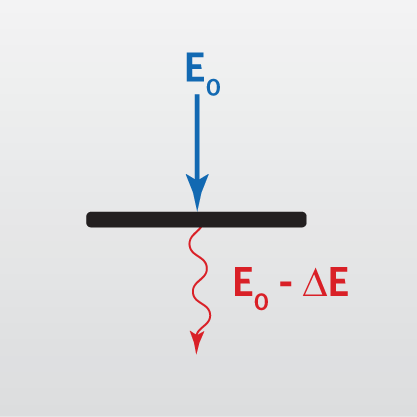
(上图中,能量 E 的转换,总是会导致能量损耗 ∆E。)
一开始,物理学家以为是技术水平不高导致的,但后来发现,技术再进步,也无法将能量损耗降到零。他们就将那些在能量转换过程中浪费掉的、无法再利用的能量称为熵。
后来,这个概念被总结成了"热力学第二定律":能量转换总是会产生熵,如果是封闭系统,所有能量最终都会变成熵。
熵既然是能量,为什么无法利用?它又是怎么产生的?为什么所有能量最后都会变成熵?
物理学家有很多种解释,有一种我觉得最容易懂:能量转换的时候,大部分能量会转换成预先设定的状态,比如热能变成机械能、电能变成光能。但是,就像细胞突变那样,还有一部分能量会生成新的状态。这部分能量就是熵,由于状态不同,所以很难利用,除非外部注入新的能量,专门处理熵。
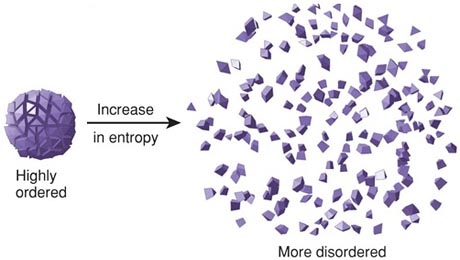
(上图,能量转换过程中,创造出许多新状态。)
总之,能量转换会创造出新的状态,熵就是进入这些状态的能量。
现在请大家思考:状态多意味着什么?
状态多,就是可能性多,表示比较混乱;状态少,就是可能性少,相对来说就比较有秩序。因此,上面结论的另一种表达是:能量转换会让系统的混乱度增加,熵就是系统的混乱度。
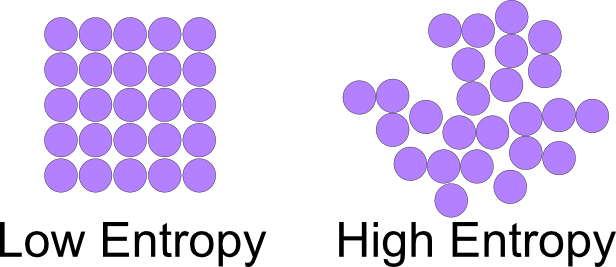
(上图中,熵低则混乱度低,熵高则混乱度高。)
转换的能量越大,创造出来的新状态就会越多,因此高能量系统不如低能量系统稳定,因为前者的熵较大。而且,凡是运动的系统都会有能量转换,热力学第二定律就是在说,所有封闭系统最终都会趋向混乱度最大的状态,除非外部注入能量。
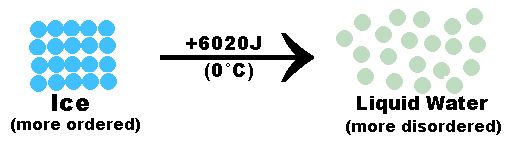
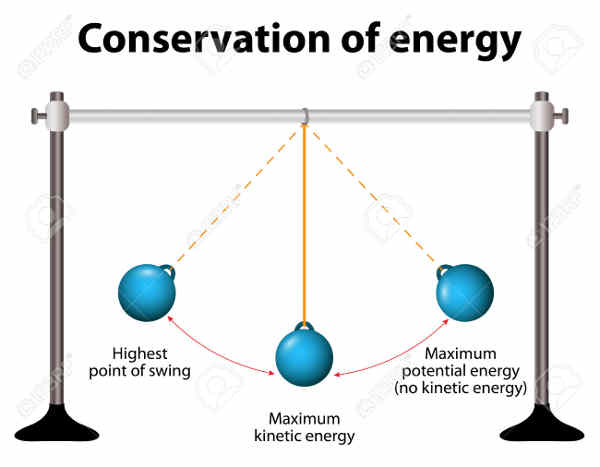
熵让我理解了一件事,如果不施加外力影响,事物永远向着更混乱的状态发展。比如,房间如果没人打扫,只会越来越乱,不可能越来越干净。

(上图中,如果不花费能量打扫,房间总是越来越乱。)
熵的解释是混乱度的度量单位,一个系统的混乱度越高它的熵就越高
二、理解信息量
我们知道了熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面,熵是对不确定性的测量。
这里有又产生了疑问,熵怎么就合信息论产生了关系?
信息是我们一直在谈论的东西,但信息这个概念本身依然比较抽象。在百度百科中的定义:信息,泛指人类社会传播的一切内容,指音讯、消息、通信系统传输和处理的对象。
1、信息量和事件发生的概率相关,事件发生的概率越低,传递的信息量越大;
2、信息量应当是非负的,必然发生的事件的信息量为零;
3、两个事件的信息量可以相加,并且两个独立事件的联合信息量应该是他们各自信息量的和;
用数学表达如下:

三、理解信息熵
但信息可不可以被量化,怎样量化?答案当然是有的,那就是“信息熵”。早在1948年,香农(Shannon)在他著名的《通信的数学原理》论文中指出:“信息是用来消除随机不确定性的东西”,并提出了“信息熵”的概念(借用了热力学中熵的概念),来解决信息的度量问题。
好了,这里就产生了信息熵!那么怎么解释呢?那信息熵如何计算呢?
举个吴军在《数学之美》中一样的例子,假设世界杯决赛圈32强已经产生,那么随机变量“2018年俄罗斯世界杯足球赛32强中,谁是世界杯冠军?”的信息量是多少呢?
根据香农(Shannon)给出的信息熵公式,对于任意一个随机变量X,它的信息熵定义如下,单位为比特(bit):
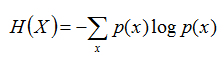
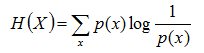
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思。
那么上述随机变量(谁获得冠军)的信息量是:

其中,p1,p2,…,p32分别是这32强球队夺冠的概率。 吴军的书中给出了几个结论:一是32强球队夺冠概率相同时,H=5;二是夺冠概率不同时,H<5;三是H不可能大于5。 对于第一个结论:结果是很显然的,夺冠概率相同,即每个球队夺冠概率都是1/32,所以H=-((1/32)·log(1/32)+(1/32)·log(1/32)+…+(1/32)·log(1/32))=-log(1/32)=log(32)=5(bit)
对于第二个结论和第三个结论:使用拉格朗日乘子法进行证明,详见《求约束条件下极值的拉格朗日乘子法》。这实际上是说系统中各种随机性的概率越均等,信息熵越大,反之越小。
从香农给出的数学公式上可以看出,信息熵其实是一个随机变量信息量的数学期望。
日常生活中,我们经常说某人说话言简意赅,信息量却很大,某些人口若悬河,但是废话连篇,没啥信息量;这个电视剧情节太拖沓,一集都快演完了也没演啥内容。这里的信息量/内容与信息熵有什么关系呢?
很多人把这些东西与信息熵混为一谈,得出“说话信息量越大,信息熵越高”“语言越言简意赅,信息熵越高;语言越冗余堆积,信息熵越低。”等等结论。
不是说这些说法错了,而是容易引起误导。个人认为,这里日常语境的信息量与其说是信息量,不如说是信息质量和信息传递效率问题,有没有干货,有没有观点,有没有思想,并且在一定的文字长度/播放时间内,能不能有效的表达出来,这个其实是人的能力问题,和信息熵没啥关系好不!
四、联合熵、条件熵、交叉熵
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
且有此式子成立:H(Y|X) =H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
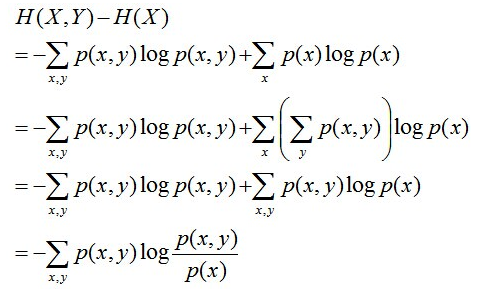
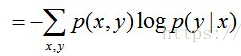
第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(logp(x,y)-logp(x))写成- log(p(x,y)/p(x)) ;
第五行推到第六行的依据是:条件概率的定义p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
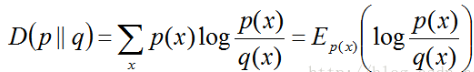
#交叉熵例子
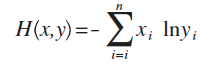
假设x是正确的概率分布,而y是我们预测出来的概率分布,这个公式算出来的结果,表示y与正确答案x之间的错误程度(即:y错得有多离谱),结果值越小,表示y越准确,与x越接近。
比如:
x的概率分布为:{1/4 ,1/4,1/4,1/4},现在我们通过机器学习,预测出来二组值:
y1的概率分布为 {1/4 , 1/2 , 1/8 , 1/8}
y2的概率分布为 {1/4 , 1/4 , 1/8 , 3/8}
从直觉上看,y2分布中,前2项都100%预测对了,而y1只有第1项100%对,所以y2感觉更准确,看看公式算下来,是不是符合直觉:

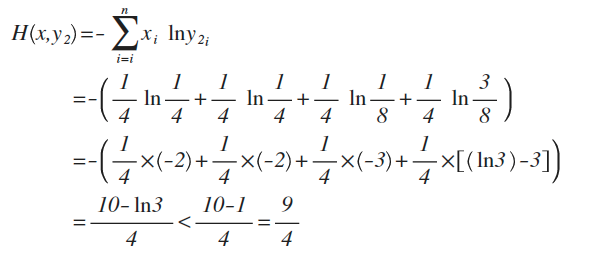
对比结果,H(x,y1)算出来的值为9/4,而H(x,y2)的值略小于9/4,根据刚才的解释,交叉熵越小,表示这二个分布越接近,所以机器学习中,经常拿交叉熵来做为损失函数(loss function)。
