

粗略介绍下小伙伴剑语最近在搭配推荐的工作
0. 两个前提假设
1)将计算商品的搭配特性转化为计算商品的style信息,具有相同或相似style的商品是相互搭配的。在这个style space上,搭配的商品即使不属于同一个类目,距离也很接近。
2)如果两个商品被用户同时购买(或者被同一个用户购买)的频率较高则说明他们搭配。即商品的共现信息决定了其在style space上的分布情况。这是模型训练和评估时的主要思想。
1. 类目限制
只选择了服装+鞋子类目的商品,且对于每个商品只看其较高层级的类目信息,原因是高层级的类目是独立于style的,即避免类目划分过细时某些小类目跟style强相关对样本选择情况有影响。同时在正样本构造时,加入先验,人为限定搭配类目。
2. 商品池子处理(待定)
1. 长尾冷门商品处理
在上述已经圈定大类目的商品池子的基础上,去除掉长尾部分的冷门商品,这里是过滤掉近30天中总的行为数不高于1人次的商品。
过滤完后剩下约百万的商品。
2. 同图商品处理
1)利用图像向量计算出的i2i图像相似度数据,阈值设为0.9,高于阈值的作为主商品的同图商品看待,然后将各个主商品用其同图商品中最优(这里选择了近期行为数来衡量)的商品替换。这就是一份同图可替换的映射关系数据。
2)将这份同图替换数据使用在搭配的商品池子上。
3)同时,这份同图替换数据会应用到训练样本中,将原先的商品映射到其同图中较优的商品集合上。
3. 模型实现
1)目前基于商品的原始图像向量的tsne评估结果来看,根据叶子类目来聚类的效果区分度较大;从人工看case也发现,不同style的同类目商品之间的相似度高,而相同style的不同类目商品之间的相似度低。综上,说明,原始图像信息并不能很好地反映style信息。
2)模型训练的几种方式
2-1)对于输入的pair对向量,concat成一个向量,然后直接进入全连接层,使用二分类的logloss,同时不会对原始输入向量进行训练。
优点:直接将商品的图像信息作为特征对搭配目标进行建模;可以扩展到所有商品向量上。
缺点:无法构建商品的style空间表示,不能产出直观的style信息。
评估方法:auc。
2-2)采用Siamese结构,对于输入的pair对向量,对每个向量均使用相同的全连接层将原始向量映射到style space中的向量,并将在style space中pair对向量的距离作为loss。(目前选定这个)
优点:将商品的图像信息作为特征对搭配目标进行建模;能够构建商品的style空间表示,产出直观的style信息;可以扩展到所有商品向量上。
缺点:没有直接的评估指标。
评估方法:看style空间表示是否合理,或者将欧式距离映射成prediction score再使用auc评估。
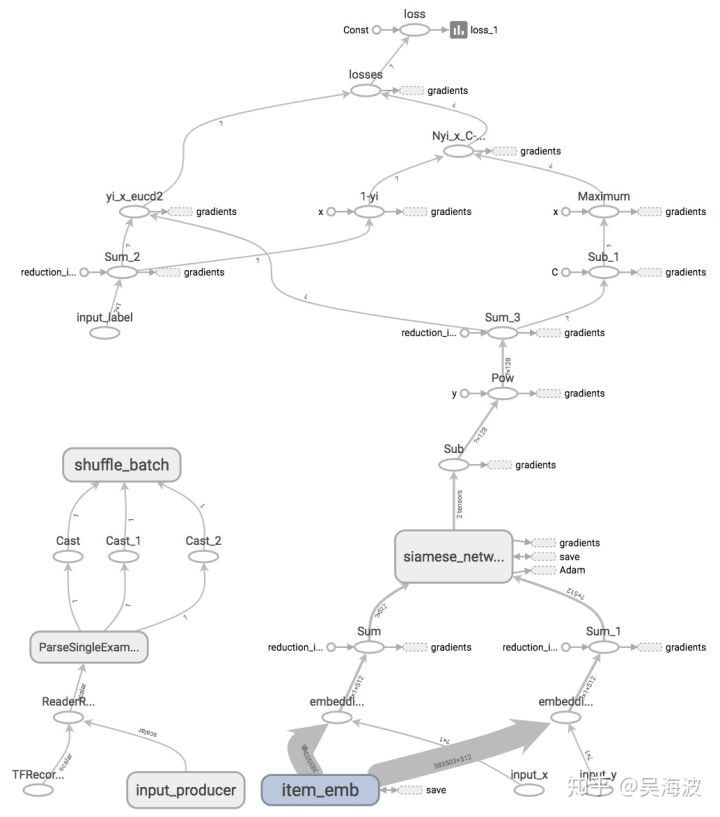
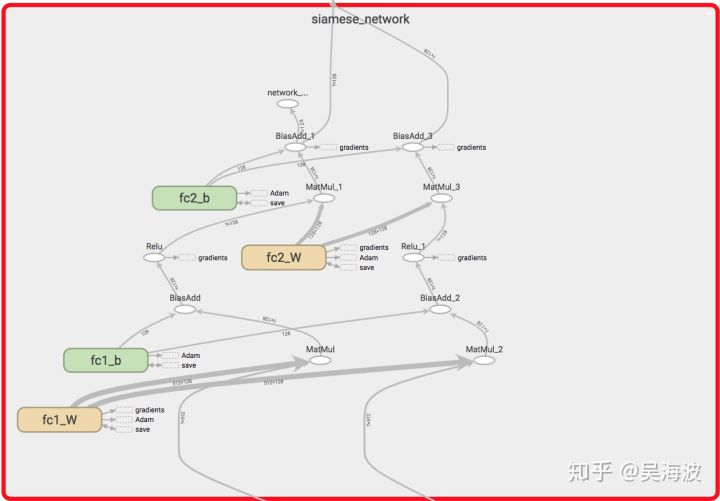
4. 训练样本构建
1)正样本选择为用户在30天内成交的商品中构造pair对,其中需要过滤掉成交数过多(目前选择100个)的用户。正样本量级400w+。
2)负样本即在没有共同成交的pair对中随机抽样获得。负样本按照正样本的5倍数量级采样,2000w+。
5. 模型训练
look up table(90w商品*512维向量)
解决初始化向量tensor的2GB限制方法:
https://github.com/tensorflow/tensorflow/issues/6117
https://eklitzke.org/pinning-gpu-memory-in-tensorflow
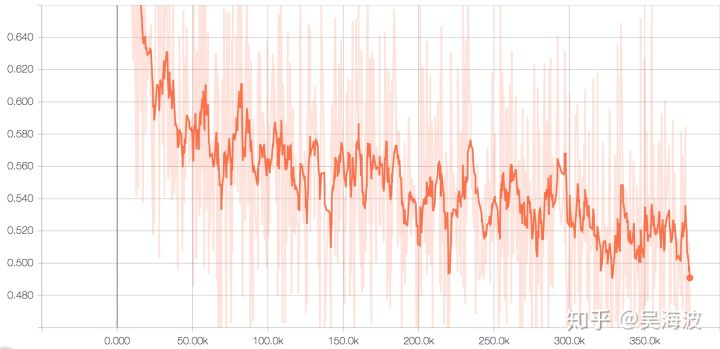
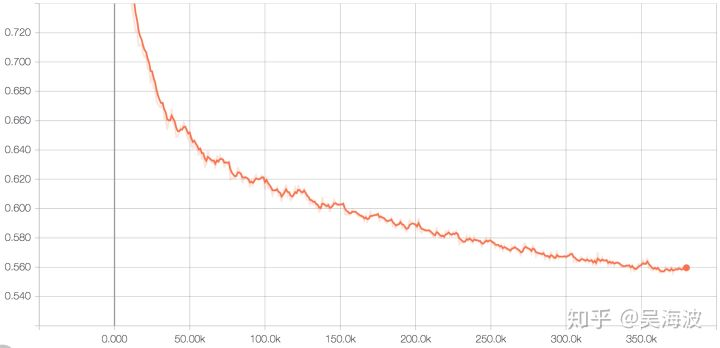
训练时长:15个epoch 用时约10h+。
train set loss:
validation set loss:
6. 结果评估
1)style space有效性
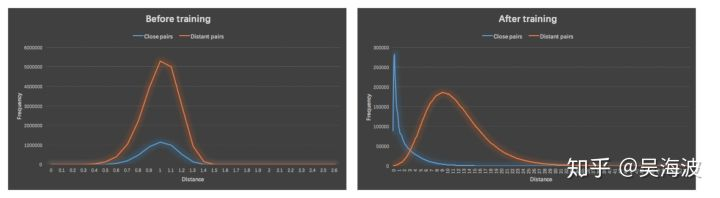
style space是否改变向量分布。对比训练前embedding(图像) vs 训练后embedding中,搭配pair(正样本)和不搭配pair(负样本)的distance分布情况,可以说明学到的模型是否能够将两者区分开。
下图为在训练样本上查看的distance分布结果,在验证集合上分布情况也完全一致。说明模型改变了向量的分布,同时将match pair和non-match pair分隔开来。
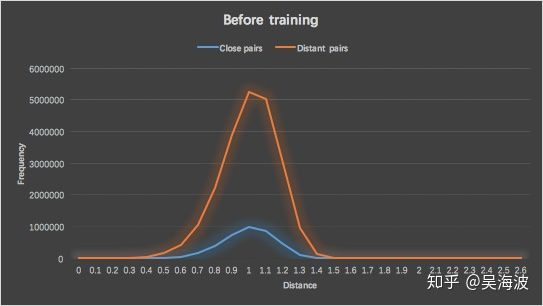
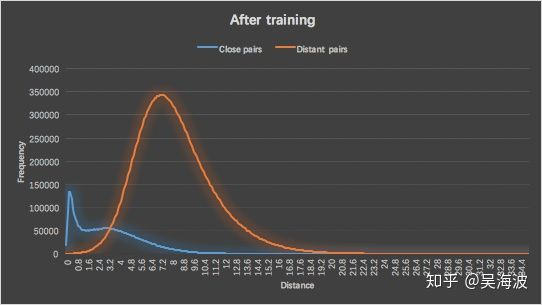
2)单类目内聚类比较
对单类目内进行聚类,聚成100个cluster。
2-1)查看聚类分布情况
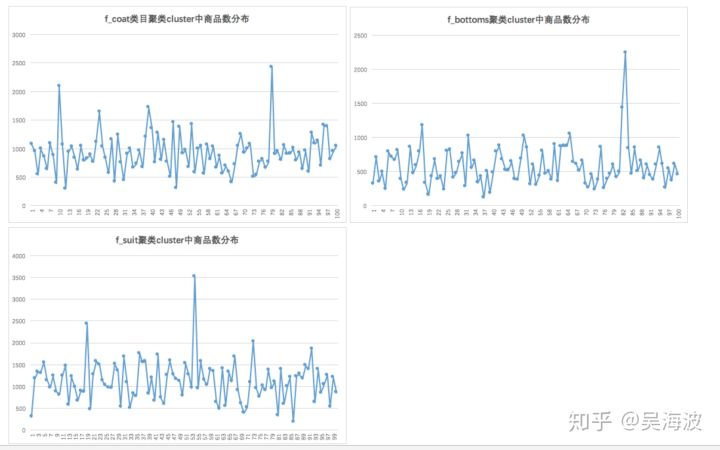
2-2)查看每个cluster中的商品风格是否相近




3)类目pair间聚类比较
对于每个大类,在类内进行聚类操作,将同一个大类的商品聚成多个cluster,然后对于每个目标类目对,找出其中较近的cluster pair和较远的cluster pair。
如果模型训练有效果,则较近的cluster pair中的商品风格较为接近,较远的cluster pair中的商品风格不太相同。
目前在人工对比 cluster pair 中的结果时,采取的方法是对于每个cluster,取与centroid最近的top n个结果,然后再pair间比较风格。
如下图所示,即是按照上述方法选择的cluster中的top 5结果,同一行的左右两组结果组成pair对。上部分是pair比较接近的,下部分是pair比较远的。
较近的cluster pair
pair 1:

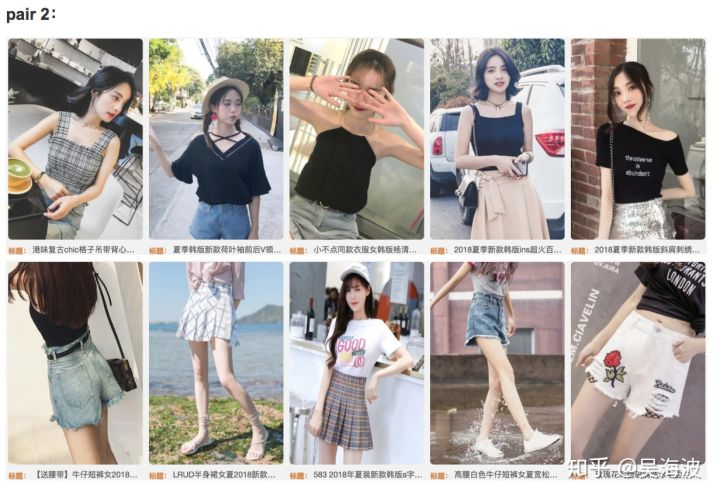

较远的cluster pair
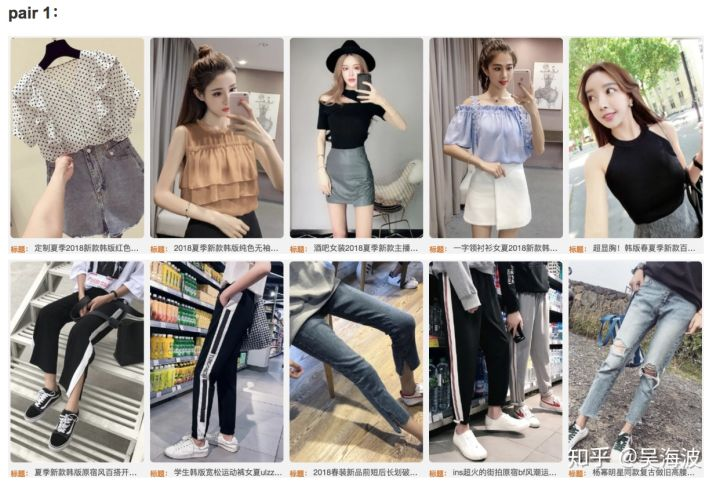

4)商品级别获取搭配结果
对于每个商品,在其目标类目中找到距离最近的商品集合。
随机选取一些相对不怎么冷门的商品作为主商品作为trigger,搭配结果如下:

7. 遇到问题的分析
1. 单类目内聚类效果问题
每个类目聚类后的cluster中会有一个商品数很大的,其余cluster的商品数相对平均些;这个大cluster里的商品之间的距离相比其它cluster里的商品之间的距离平均而言要小不少(0.02~0.1 vs 0.1~1),且这个cluster里的商品相对比较热门,风格比较多样。
2. 商品映射向量分布改变问题
经过模型训练,改变了向量的分布,同时将match pair和non-match pair的distance distribution分隔开来。
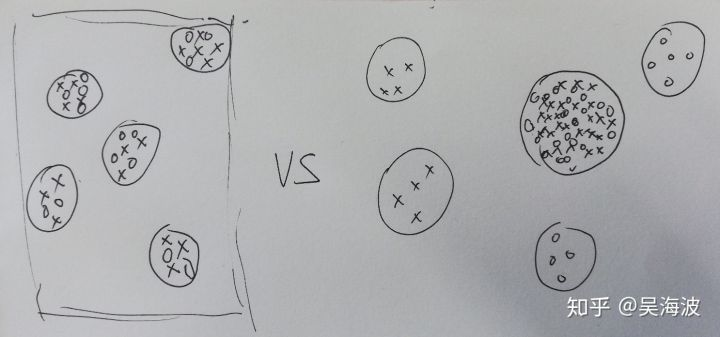
结合上述两者,会发现个问题,就是虽然向量分布改变了,但是改变后的分布并不是预期的分布。如下图,预期是左边的分布,但基于上述两个现象,目前更可能是右边的分布。
问题的原因
1. 这些大cluster的商品估计是正样本中的商品集合。因为模型对正样本学的很好,所以正样本中的商品pair(总体偏热门)之间的距离会靠的很近,但为什么它们所有的都靠到一起了?猜测是因为这些正样本pair中同一个商品link的其它商品较多,导致了连锁聚集效应?即如下所示,预期是左边的关联关系,但实际上是右边的关联关系,导致了连锁聚集效应。

就单个类目来说(以女上衣举例):最大cluster的商品占比约5%,在负样本中的占比也是5%,但其在正样本中的占比却达到了58%。其它类目中大cluster商品的正样本占比也都在60~70%。
正样本pair中同一个商品link的其它商品较多,导致了连锁聚集效应。
2. 另外负样本中没有能够很好地表达对于这些商品(正样本中的商品)之间的区分的效果,导致模型学习过程中没有能够将它们之间区分开来,所以就导致了上述现象。
如果模型拟合的效果很好,那么最终效果就基本上由训练样本决定了。
综上所述,大量的正样本 & 正样本之间的link density较大 & 少量的负样本 用于描述了这些大cluster中的商品集合,导致了它们的聚集效应;而使用 大量的负样本 & 少量的正样本 来描述了剩余的商品,导致这两拨商品彻底分开,但其实并没有学习到它们内部各自的分布(可以想象,大cluster中的这部分商品的分布基本上都被正样本的分布所决定了,所以聚集在了一起;而剩余商品,尤其是占比很大的那些从未在正样本里出现过的商品的分布基本上都被随机采样的负样本的分布所决定了)。
解决方案: 调整正负样本量级,对于top pair商品的正样本进行采样,缓解这些商品的热门属性
3. 长尾商品在正样本中已经出现过的关系没有被模型学习到
虽然已经对top pair商品的正样本进行了采样,但是由于总体样本还是按照用户行为数趋势来做的,所以模型对top pair商品正样本的关系学习的比 非top pair商品 要更好,这也是不可避免的,除非将所有pair的正样本均采样为出现1次。正如点击率预估时,top样本自然会学习得较好,因为其代表的信息也更可靠,长尾样本本身也相对不可靠。换到我们这边,1如果认为pair关系在正样本中出现的次数越多,则这个pair的商品搭配关系也更可靠,那么就应该接受这一现象,也正是利用可靠的正样本商品pair来得到更靠谱的模型从而去除长尾商品样本带来的噪音;2如果认为不管pair关系在正样本中出现多少次,其权重应该是一样的,那么就可以将所有pair的正样本均采样为出现1次。
4. 推荐结果中风格不搭配的badcase
不管是top pair商品还是长尾商品,都存在个别推荐结果里出现风格明显不搭的商品,长尾商品验证不了,因为可能是模型对其没有学习好;但通过top pair商品能够看出来,这是因为正样本中本身就存在这样的情况,即我们模型成立的前提假设是同一个用户购买的多件商品是具有相同风格的,但实际上也会出现本身不是相同风格的情况,尤其在top商品中,因为比较热门,所以可能性更大,这样就会导致模型训练出来的结果中存在不同风格的商品距离接近。
这边有一定的争议,即这些看上去风格不同的商品pair是否应该作为正样本。一种思路是既然是共现信息(同一个用户购买)即是代表它们之间是存在联系的,应该放在一起来学习这样的pattern。但我这边认为,商品的共现其实包含了多种pattern,如相似、搭配、还有热门等,我们判断两个商品共现关系是有用关系的前提是:用户对这两个商品的行为之间是有原因可解释的是存在某些pattern的,如啤酒与尿布,而如果用户对两个商品的行为之间是没有联系没有原因是相互独立的话(如热门商品),这样的共现关系(如热门商品)表达不了特定的pattern,即没法表达特定场景需求下(如搭配场景)商品的关系。所以这里想说明的是共现关系的pattern还是包含了较多的因素,不能简单地认为对所有特定场景需求都是有强相关的。如果应该场景没有限制,如买了又买等,那确实不需要对样本进行剪枝;而对于有一定限制的应用场景,应该提取出符合该场景需求的pattern,所以我们在相似i2i(可替代关系)需求时会加入叶子类目限制;在搭配时之前会加入类目配对限制。只不过限制在同一个叶子类目要比限制不在同一个大类目的约束更强,更容易过滤噪音。
所以,目前看来这种方式组的pair关系存在噪音,且越是top商品越容易出现噪音。
8. 讨论总结
把上面问题结合起来看会发现,本身top商品pair更容易影响模型学习,但同时top商品pair又更容易受到噪音干扰,这就是一个很矛盾的事情。
再次来看问题1,我们习惯性地按照用户行为数直接来作为训练样本,适合这样做的前提是top商品pair信息更可靠,但是否适合现在这个场景呢?
1)点击率预估时,之所以可以将query-item行为数直接作为训练样本,是因为query-item本身存在强关联噪音很小存在的pattern很确定(item是在该query下召回和曝光的),再利用概率统计的方式(最大似然)来衡量这种联系(确定的pattern)的大小,而这时候样本出现次数的多少就影响了概率统计的可靠程度;
2)而在我们现在的场景下,商品pair的共现是没有强联系和约束的(存在的pattern很多),就直接拿来衡量关系的大小,所以很容易被热门因素影响(如我们计算相似i2i时并不是pair出现次数越多就认为两者越相关,还加入叶子类目作为约束、热门因素作为归一化);
3)这就好比在query-item场景下,如果想通过同时在搜索场景搜索某个query(连衣裙)和在所有场景有点击某个商品(运动鞋)的用户数的多少来衡量该query和item是否相关一样,或许这是一种pattern,但应该不是相似或者搭配的这些特殊pattern;
4)如果我们的训练样本提取时有限制,如给定一个主商品,给用户展示可供搭配的若干商品的场景,就比较适合根据用户的行为数来判断pair的搭配关系强弱,行为数越充分的应该对模型影响越大。实验方式
针对正样本数据,对于top pair商品的正样本进行采样,缓解这些商品的热门属性,才能让其风格分布显现出来;同时避免这些正样本dominate模型训练,从而让模型学习到更多商品的分布
参考papers
- Learning Visual Clothing Style with Heterogeneous Dyadic Co-occurrences
- Image-based Recommendations on Styles and Substitutes
- Learning visual similarity for product design with convolutional neural networks
- Style2Vec: Representation Learning for Fashion Items from Style Sets
- Boosting Recommender Systems with Deep Learning
- Compatibility Family Learning for Item Recommendation and Generation
- Recommending Outfits from Personal Closet
