启发式算法(Heuristic Algorithm)是一种基于直观或经验的构造的算法,对具体的优化问题能在可接受的计算成本(计算时间、占用空间等)内,给出一个近似最优解,这个近似解与真实最优解的偏离程度一般不能被预计。
由于 NP 问题一般的经典算法求解效率过低甚至无法求解,从而促使了启发式算法的诞生。一个精心设计的启发式算法,通常能在较短时间内得到问题的近似最优解,对于 NP 问题也可以在多项式时间内得到一个较优解。
启发式算法不是一种确切的算法,而是提供了一个寻找最优解的框架。从开头的定义可以看出,启发式算法需要根据实际应用场景,建立一系列切合实际问题的启发式规则。同时启发式算法存在以下问题:
目前缺乏统一、完整的理论体系;
启发式算法都会遭遇到局部最优的问题,难点在于如何设计出有效跳出局部最优的机制;
算法的参数设置对效果有很大的影响,如何有效设置参数值得思考;
如何设定有效的迭代停止条件等。
因此值得注意的是,启发式算法不能保证得到最优解,效果相对不稳定,它的效果依赖于实际问题和设计者的经验。但瑕不掩瑜,面对复杂问题启发式算法能以相对简单的方式进行解决,并且它容易设计程序。
大部分启发式算法是通过生物现象或物理现象演变而来,我们据此将它分为以下类别:
仿动物类的算法:粒子群优化算法、蚁群算法、鱼群算法、蜂群算法等;
仿植物类的算法:向光性算法、杂草优化算法等;
仿人类的算法:遗传基因算法、神经网络、声搜索算法等;
仿物理现象的算法:模拟退火算法。
接下来挑选以上类别中较为经典的启发式算法进行介绍。
模拟退火算法 SA
在热力学上,退火(annealing)现象指物体逐渐降温的物理现象。温度越低,物体的能量状态越低;当能量状态足够低后,液体开始冷凝与结晶,在结晶状态时,系统的能量状态最低,也最稳定。
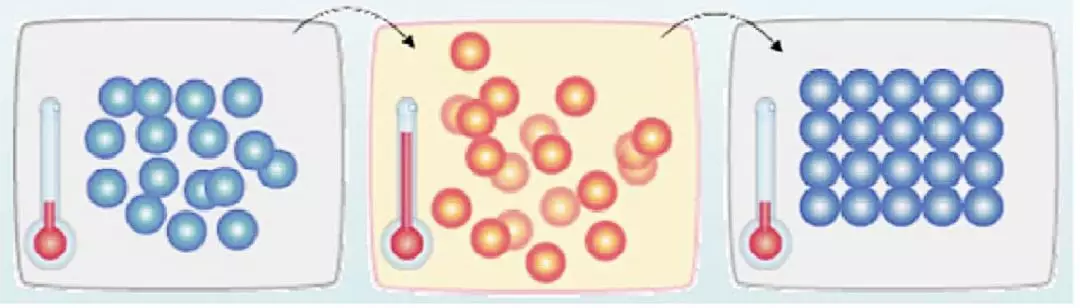
物理退火过程由三部分组成:
加温过程:目的是增强粒子的热运动,使其偏离平衡位置。
等温过程:对于与周围环境交换热量而温度不变的封闭系统,系统状态的自发变化总是朝自由能减少的方向进行。
冷却过程:使粒子热运动减弱,系统能量下降,达到能量最低态。
模拟退火法是一种通用的启发式算法,我们把问题搜索空间内每个解都想象成物体内的分子,对于搜索空间内的每个解,如同物体分子一样带有「能量」,用于表示这个解对问题的合适程度。算法以搜索空间中的一个任意解作为初始解,每一步随机产生一个新解,并计算从当前解到达新解的概率。其中,加温过程对应算法的初始温度,等温过程对应算法的 Metropolis 抽样过程,冷却过程对应控制参数的下降。
Metropolis 准则是指以一定的概率接受恶化解,从而使算法具有逃脱局部极值和避免过早收敛的全局优化能力。
能量的变化就是目标函数值的变化,能量的最低态就是最优解。其中 Metropolis 准则是 SA 算法收敛于全局最优解的关键所在,当搜索到不好的解,Metropolis 准则会以一定概率接受这个不好的解,使算法具备跳出局部最优的能力。假定当前可行解为 x,迭代更新后的解为 x_new,那么对应的「能量差」定义为:
Δf = f ( x_new ) − f ( x )
以一定概率接受不好的解,则该概率为:
p (Δf) = exp( -Δf/kT )
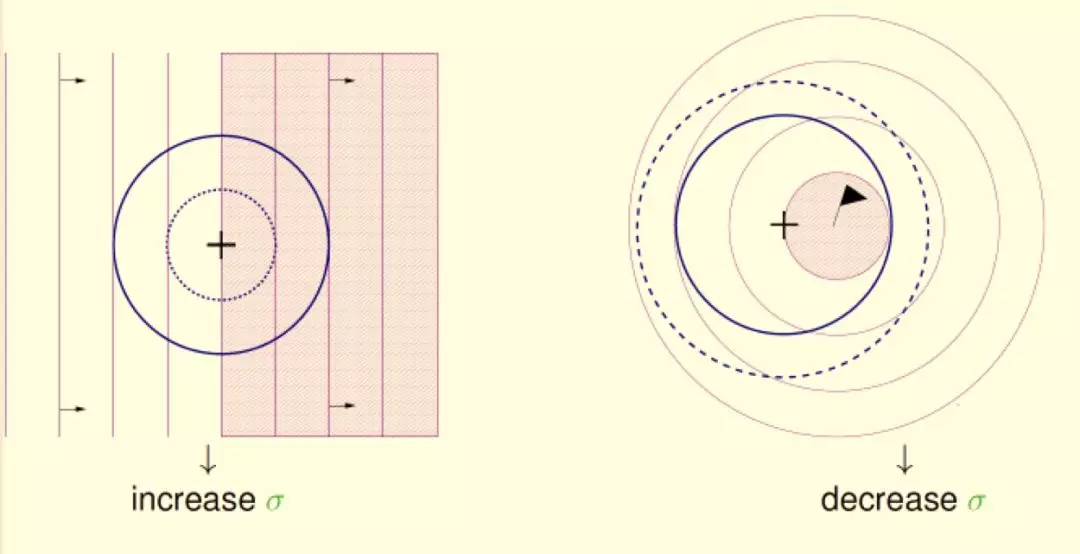
温度 T 是 Metropolis 准则的影响因素之一:在高温下,可接受与当前状态能量差较大的新解;在低温下,只接受与当前状态能量差较小的新解。
模拟退火算法的具体流程如下图所示:
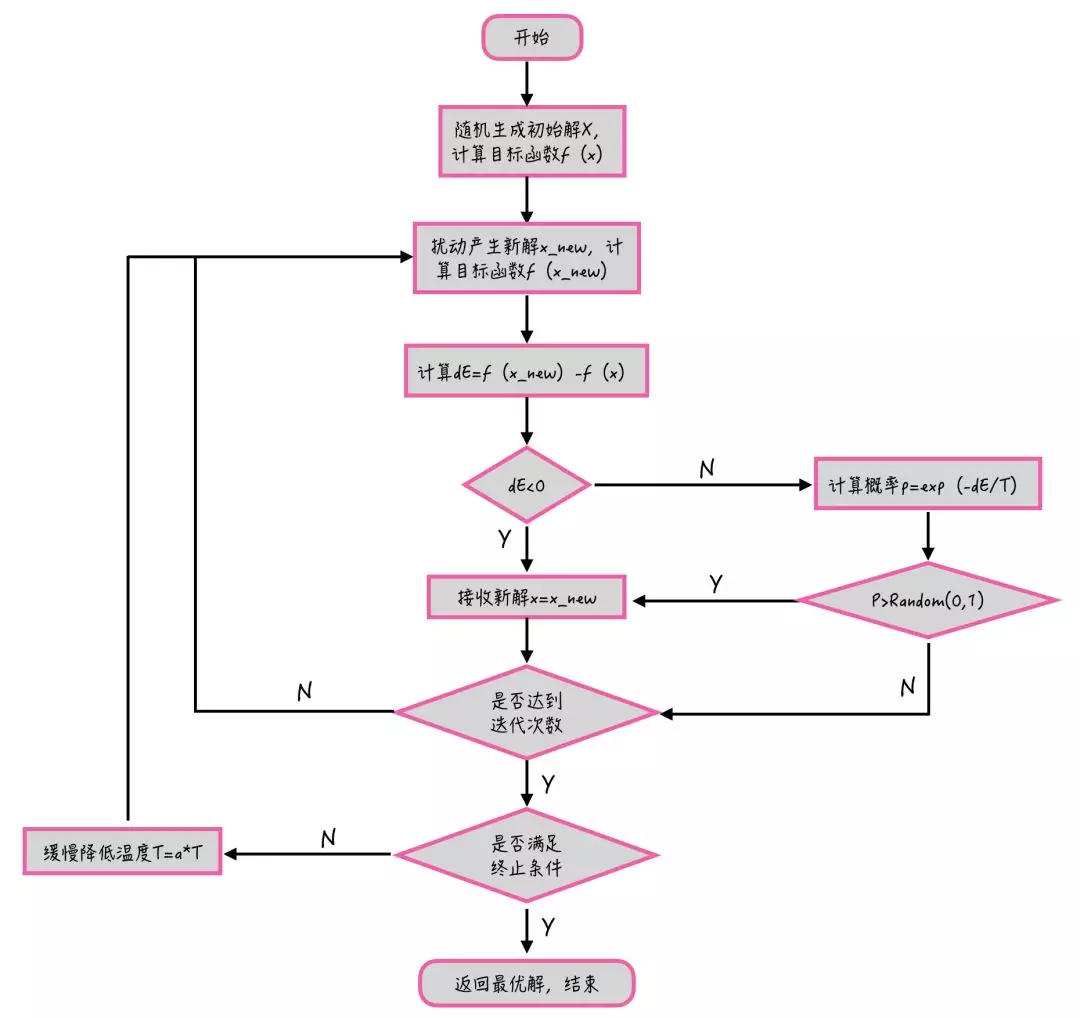
模拟退火算法的应用广泛,可以高效地求解 NP 完全问题,如旅行商问题、最大截问题、0-1 背包问题等。但是其参数比较难控制,不能保证一次就收敛到最优值,大部分情况下还是会陷入局部最优值,主要受三个关键参数影响:
初始温度值设置
初始温度值的设置是影响模拟退火算法全局搜索性能的重要因素。初始温度高,则搜索到全局最优解的可能性大,但因此要花费大量的计算时间;反之,则可节约计算时间,但全局搜索性能可能受到影响。退火速度问题,即每个温度值的迭代次数
模拟退火算法的全局搜索性能也与退火速度密切相关。一般来说,同一温度下的「充分」搜索是相当必要的,但搜索越「充分」,计算开销自然越大。温度管理问题
温度管理问题也是影响模拟退火算法全局搜索性能的重要因素。实际应用场景下,因为需要考虑计算开销问题,常采用温度衰减的方式进行降温:T=α×T.α∈(0,1)
为了保证较大的搜索空间,α 一般取接近于 1 的值,如 0.95、0.9。
🌰举个例子:买菜问题
买菜问题是一个典型的组合优化问题:假设给定一组包含n个蔬菜的集合,其中每个蔬菜都有自身的体积 w_i 和价格 v_i,买菜阿姨有一个容量为C的购物篮,买菜阿姨的任务是在不超过购物篮容量的前提下,购买一组价格最高的蔬菜放入篮中。
给定 n 个蔬菜的集合{x_1, x_2, ..., x_n},x_i∈{0, 1},每个蔬菜 x_i 的具有属性{(w_i, v_i)},购物篮容量为正整数 C,即求解如下优化问题:
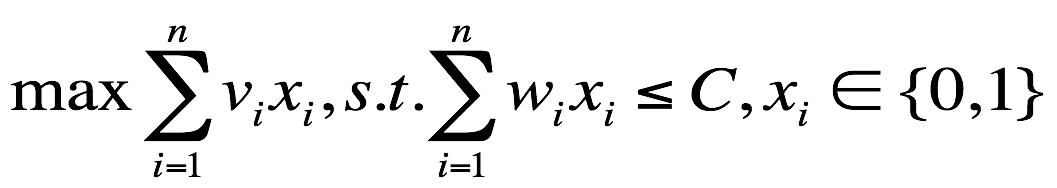
假设蔬菜的体积集合 size={2,2,3,4},蔬菜的价格集合 value={5,6,7,8},阿姨的购物篮容量为 7,一般设置初始方案为 S0 = {0,0,0,0}。既然是最大化蔬菜的总价格,那么目标函数和限制函数就是:
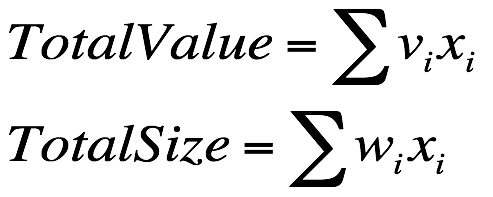
若阿姨每次蒙着眼睛随机挑选一个蔬菜 i 则有三种新解产生方式:
1.如果蔬菜 i 不在购物篮中,就直接把它丢进篮子里;
2.如果蔬菜 i 不在购物篮中,但是篮子满了,那么蒙着眼睛从篮子里取出蔬菜 j,把位置让给蔬菜 i;
3.如果蔬菜 i 已经在购物篮中,那么先把蔬菜 i 取出来,然后蒙着眼睛挑一个蔬菜j并放进篮子里。
根据三种新解产生的情况,那么购物篮的价值差、体积差都会出现三种情况。
购物篮的价值差:
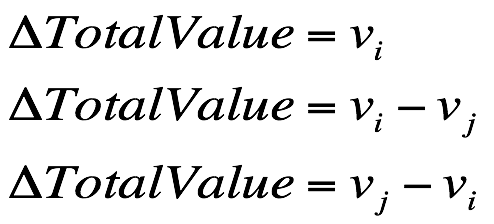
购物篮的体积差:
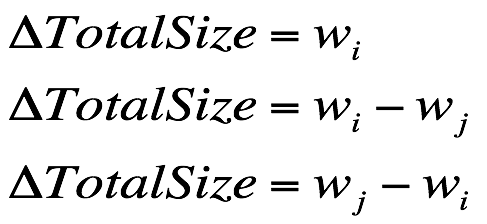
由于买菜问题是有约束的最优化问题,所以 Metropolis 准则需要做一些相应的调整:
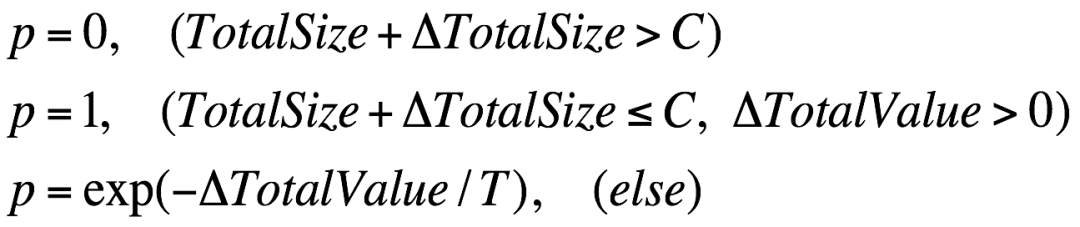
然后,根据前面所述的计算规则,设置好初始温度 T、温度衰减系数 α、每个温度的迭代次数 K,会获得一个最优买菜方案:S = {1,1,1,0}。即 Totalsize=7,Totalvalue=18。
遗传算法 GA
遗传算法借鉴了达尔文的进化论和孟德尔的遗传学说,将待解决的问题模拟成一个生物进化的过程,通过复制、交叉、突变等操作产生下一代的解,并逐步淘汰掉适应度函数值低的解,增加适应度函数值高的解。这样进化 N 代后就很有可能会进化出适应度函数值很高的个体。
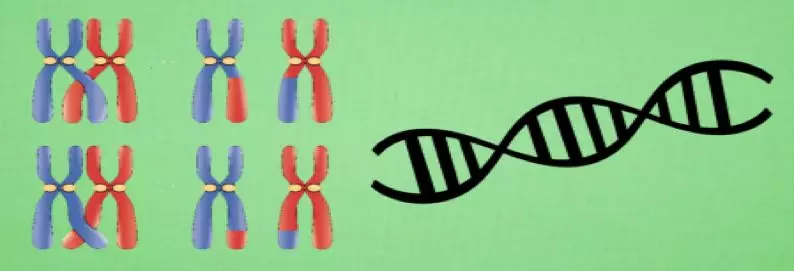
先看一些遗传学的相关生物概念:
种群:生物的进化以群体的形式进行,这样的一个群体称为种群;
个体:组成种群的单个生物;
基因:一个遗传因子;
染色体:包含一组的基因;
生存竞争,适者生存:对环境适应度高的个体参与繁殖的机会比较多,后代就会越来越多;适应度低的个体参与繁殖的机会比较少,后代就会越来越少;
遗传与变异:新个体会遗传父母双方各一部分的基因,同时有一定的概率发生基因变异。
而对应的遗传算法也有以下基本组成:
编码
适应度函数
遗传算子
运行参数
编码
遗传算法通过某种编码机制把对象抽象成按一定顺序进行排列的字符串,编码主要分为以下种类:
最简单的一种编码方式是二进制编码,既是把问题的解,编码成二进制数组的形式;
互换编码一般用于解决排序问题:比如 TSP 问题,用一串基因编码表示遍历的城市顺序;
树形编码用于遗传规划中的演化编程;
值编码用于解决复杂的数值问题。
编码主要遵循三个原则:
1.完备性:问题空间的所有解都能由编码规则进行表示;
2.健全性:任何一个基因都对应一个可能解;
3.非冗余性:问题空间和编码规则形成的表达空间一一对应。
适应度函数
遗传算法对一个个体(解)的质量评估,是用适应度函数值来度量的,适应度函数的值越大,个体的质量越好。适应度函数是遗传算法进化过程的驱动力,也是进行自然选择的唯一标准,需要根据求解的具体问题进行设计。
通常来说,适应度函数与目标函数是正相关的,可对目标函数作一些变形来得到适应度函数。
遗传算子
遗传算子包括选择算子、交叉算子和变异算子。
选择运算
选择运算是指对个体进行优胜劣汰操作。适应度高的个体被遗传到下一代群体中的概率大;适应度低的个体,被遗传到下一代群体中的概率小。
基本遗传算法(SGA)中选择算子采用轮盘赌的选择方法,其基本思想是每个个体被选中的概率与其适应度函数值大小成正比。
轮盘赌选择方法的实现步骤如下所示:
计算群体中所有个体的适应度值;
计算每个个体的选择概率;
计算积累概率;
采用模拟赌盘操作(即生成0到1之间的随机数,与每个个体遗传到下一代群体的概率进行匹配,用以确定每个个体是否遗传到下一代群体中。)
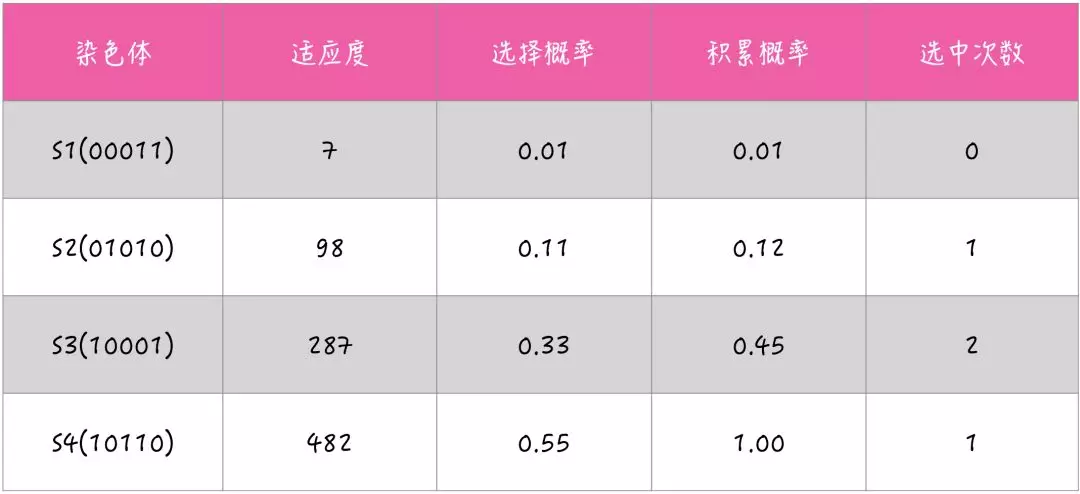
🌰举个例子
假设有染色体 S1 = 3(00011)、S2 = 10(01010)、S3 = 17(10001)、S4 = 22(10110),根据适应度函数 F(S) = S^2 -2 可得出各个染色体的适应度:
F(S1) = 3^2 -2 = 7
F(S2) = 10^2 -2 = 98
F(S3) = 17^2 -2 = 287
F(S4) = 22^2 -2 = 482
假设有 4 个随机数 r1=0.061,r2=0.242,r3=0.402,r4=0.728;再结合各个染色体的适应度可得出:
交叉运算
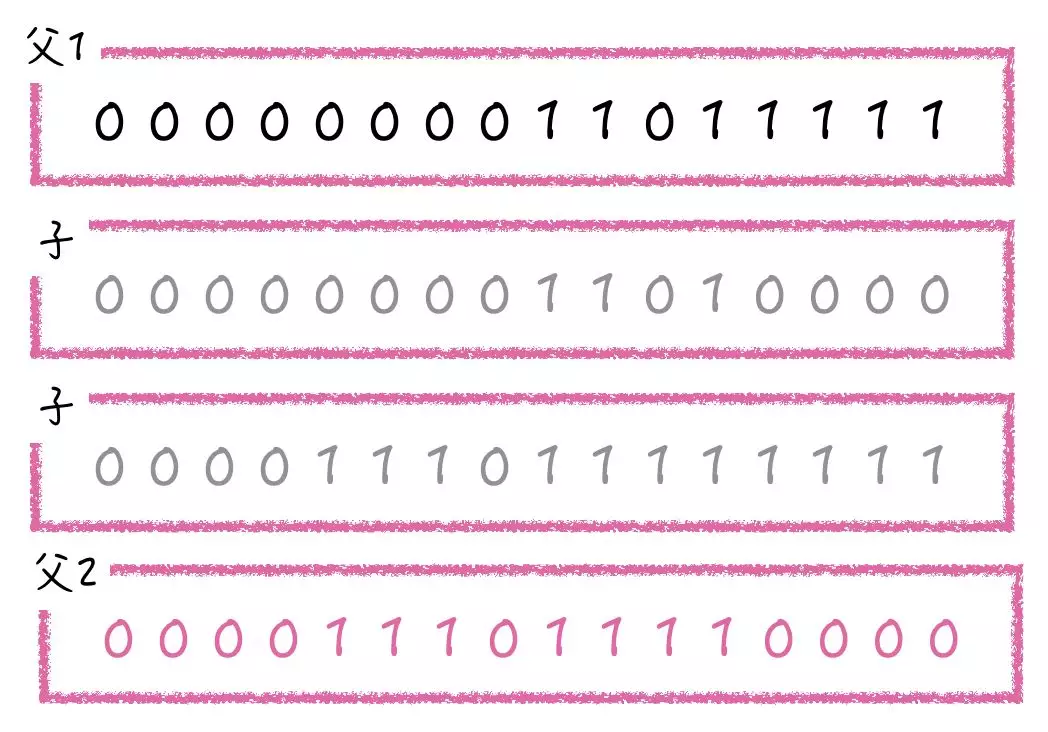
交叉运算是指对两个相互配对的染色体依据交叉概率 Pc 按某种方式相互交换其部分基因,从而形成两个新的个体。交叉运算是遗传算法区别于其他进化算法的重要特征,它在遗传算法中起关键作用,是产生新个体的主要方法。基本遗传算法(SGA)中交叉算子采用单点交叉算子,除此之外,还有双点交叉和基于「与/或」的交叉。
单点交叉(二进制编码)是指选择一个交叉点,子代在交叉点前面的基因从一个父代基因中获得,后面的部分从另一个父代基因获得。

双点交叉(二进制编码)是选择两个交叉点,子代基因在两个交叉点之间的部分从一个父代基因中获得,剩下的部分从另外一个父代基因中获得。

基于「与/或」的交叉(二进制编码)则是对两个父代基因,进行按位「与」/「或」处理,得到子代基因。
变异运算
变异运算是指依据变异概率 Pm 改变个体编码串中的某些基因值,从而形成新的个体。变异运算是产生新个体的辅助方法,决定遗传算法的局部搜索能力,保持种群多样性。
交叉运算和变异运算的相互配合,共同完成对搜索空间的全局搜索和局部搜索。基本遗传算法(SGA)中变异算子采用基本位变异算子。

基本位变异算子是指对个体编码串随机指定的一位或者多位基因,进行简单翻牌操作,即 1 变 0、0 变 1。是否接受变异,由变异概率决定。
运行参数
运行参数包含种群规模、交叉率、变异率、最大进化代数等。
种群规模指的是群体中个体的个数,比较大的种群的规模并不能优化遗传算法的结果,种群的大小推荐使用 15-30。交叉率一般来说应该比较大,一般使用 85%-95%。变异率一般来说应该比较小,一般使用 0.5%-1%。
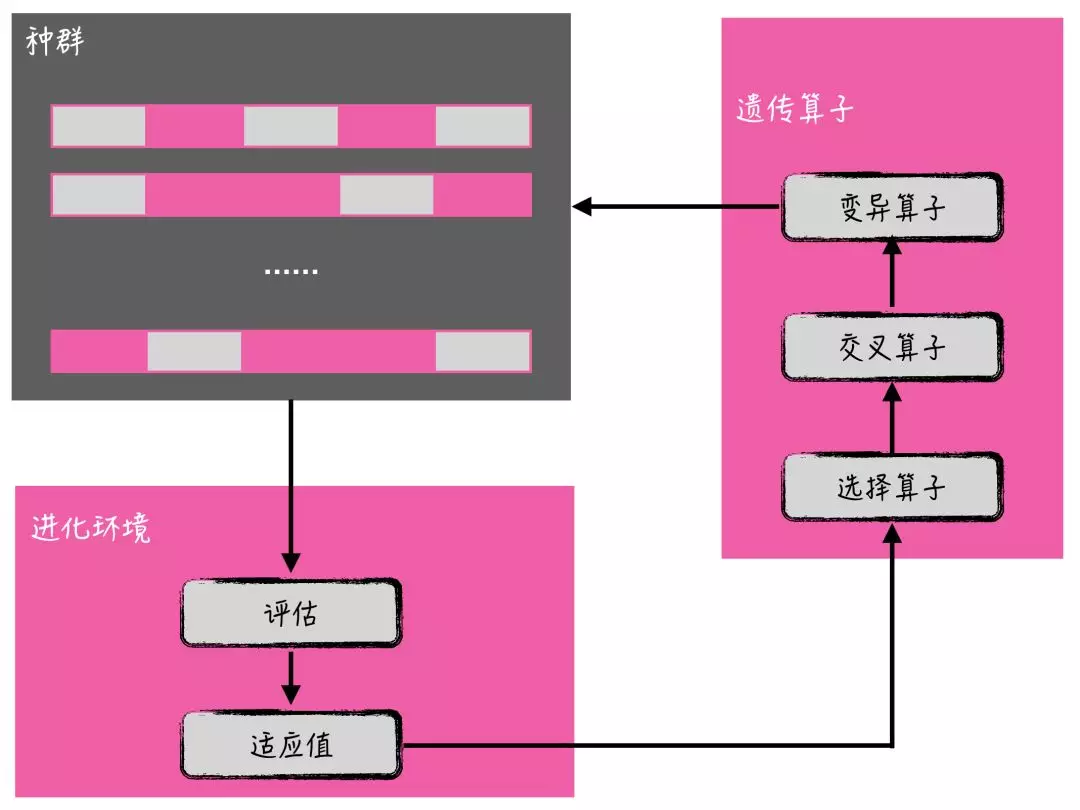
如上图所示,遗传算法基本流程是:
1.初始化进化代数计数器(t=0),T 是最大进化代数,然后随机生成 M 个个体作为初始群体 P(t);
2.进行个体评价:计算 P(t)中各个个体的适应度值;
3.进行选择运算:将选择算子作用于群体;
4.进行交叉运算:将交叉算子作用于群体;
5.进行变异运算:将变异算子作用于群体;
6.通过步骤 2-5,得到下一代群体 P(t+1);
7.终止条件判断进化代数是否达到最大值:若 t≦T,则 t←t+1,转到步骤2;若 t>T,终止,输出解。
遗传算法有两种性能优化方案:灾变与精英主义。
遗传算法的局部搜索能力较强,但很容易陷入局部最优的陷阱,要跳出局部极值就必须杀死当前的优秀个体,从而让远离当前极值的点有充分的进化余地,这就是灾变的思想。当利用交叉和变异产生子代时,很可能在某个中间步骤丢失得到的最优解,在每次产生子代时,首先把当前最优解复制到子代中,防止进化过程中产生的最优解被交叉和变异破坏,这就是精英主义的思想。
灾变与精英主义,这两者间存在一定程度的矛盾:灾变机制是把产生的优秀个体杀掉;精英主义机制则是把优秀个体保留到子代。但其实两者其实是可以共存的,在每一代进行交叉运算前,都把最优秀的个体复制到下一代,但当接下去连续 n 代都没有出现更优秀个体时,可能是遗传算法陷入局部最优,这个时候就可以采用灾变机制,帮助算法跳出局部最优。根据具体场景构建遗传算法时,可以有选择性的采用灾变和精英主义。
🌰再回到上文的例子:买菜问题
买菜问题是一个典型的组合优化问题:假设给定一组包含n个蔬菜的集合,其中每个蔬菜都有自身的体积 w_i 和价格 v_i,买菜阿姨有一个容量为C的购物篮,买菜阿姨的任务是在不超过购物篮容量的前提下,购买一组价格最高的蔬菜放入篮中。
给定 n 个蔬菜的集合{x_1, x_2, ..., x_n},x_i∈{0, 1},每个蔬菜 x_i 的具有属性{(w_i, v_i)},购物篮容量为正整数 C,即求解如下优化问题:
阿姨买菜问题,天然符合二进制编码,将待求解的 n 个蔬菜的集合{x_1, x_2, ..., x_n},表示为长度为 n 的二进制染色体。
假设蔬菜的体积集合 size={2,2,3,4},蔬菜的价格集合 value={5,6,7,8},阿姨的购物篮容量为 10,随机生成如下种群(n=4,种群规模为4): S1 = 0001,S2 = 0101,S3 = 1000,S4 = 1111。
既然是最大化蔬菜的总价格,那么首先计算个体的总价格,然后计算个体的总体积:
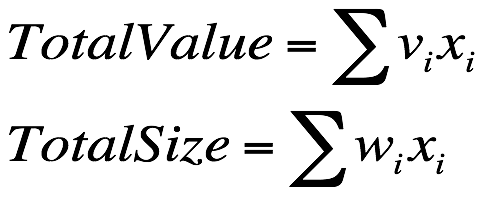
由于容量上限的限制,那么适应度的计算需要考虑这个因素,因此加入惩罚项:
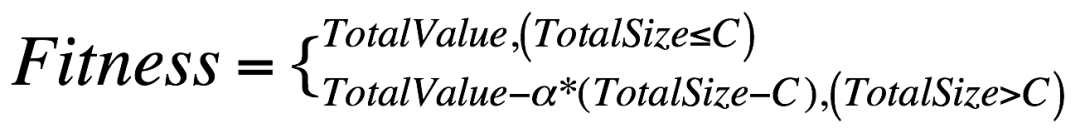
其中,参数 α 是惩罚系数,α > 1.0,数值越大,惩罚力度越大。
假设惩罚系数取 10,那么每个个体的适应度为:
S1 = 0001,TotalSize=4,TotalValue=8,Fitness=8;
S2 = 0101,TotalSize=6,TotalValue=14,Fitness=14;
S3 = 1000,TotalSize=2,TotalValue=5,Fitness=5;
S4 = 1111,TotalSize=11,TotalValue=26,Fitness=16。
假设生成 4 个随机数,r1=0.22,r2=0.57,r3=0.41,r4=0.79。
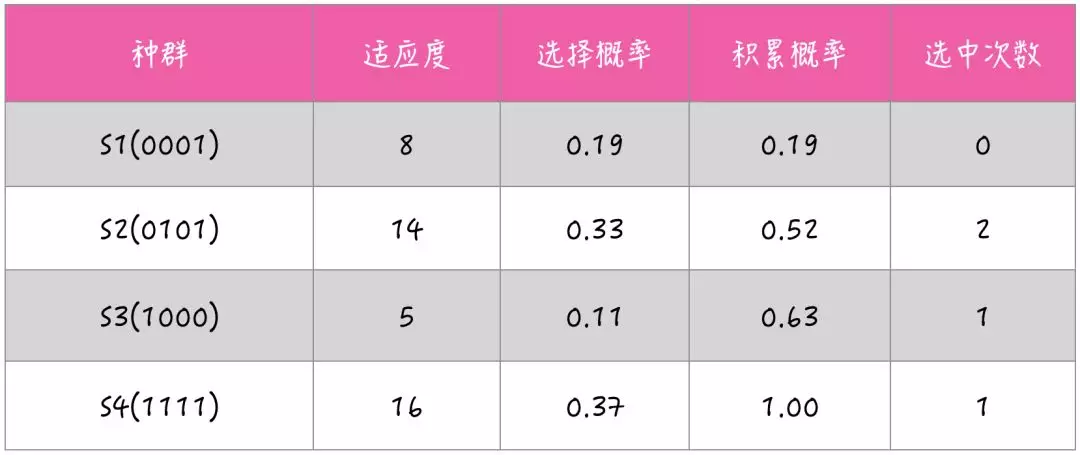
那么,下一代的种群就是 T1 = 0101,T2 = 1000,T3 = 0101,T4 = 1111。接着对经过选择后的种群进行随机配对,然后根据交叉率随机设置交叉点,采用单点交叉的方式,互换已配对的染色体的部分基因。
假设 T1 和 T4 配对,交叉点是第二位;T2 和 T3 配对,交叉点在第三位,那么交叉后的新种群为:
U1 = 0111,TotalSize=9,TotalValue=21,Fitness=21;
U2 = 1001,TotalSize=6,TotalValue=13,Fitness=13;
U3 = 0100,TotalSize=2,TotalValue=6,Fitness=6;
U4 = 1101,TotalSize=8,TotalValue=19,Fitness=19。
再次假设 U3 在第三、四位上发生了变异,那么:
U1 = 0111,TotalSize=9,TotalValue=21,Fitness=21;
U2 = 1001,TotalSize=6,TotalValue=13,Fitness=13;
U3 = 0111,TotalSize=9,TotalValue=21,Fitness=21;
U4 = 1101,TotalSize=8,TotalValue=19,Fitness=19。
至此,阿姨已经找到了最佳的买菜方案 U1和U3。
🌰再举一个例子:旅游问题(如果你懂了,可快速滑过~)
阿姨从家里出发,游玩所有祖国的著名城市之后回家。这又是一个经典的组合优化问题,这次的任务是选出一条路线,让这次旅游的总行程最短。
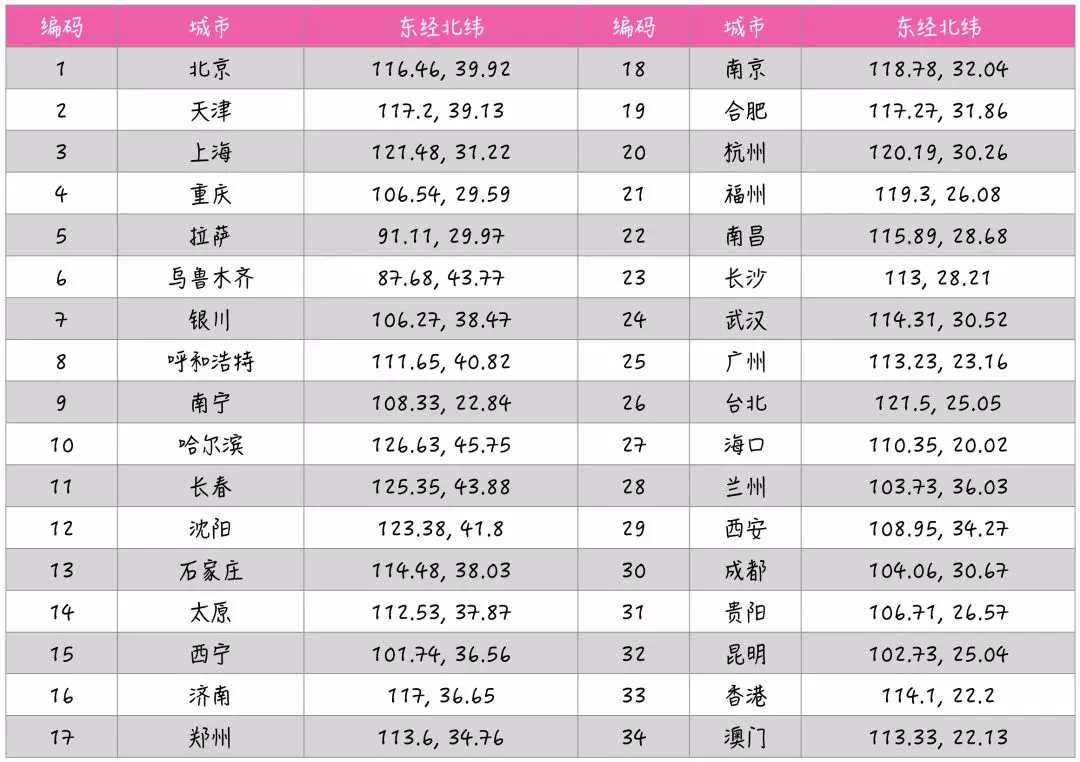
如上表所示,给每一个城市赋予一个数字编码,那么一条路线(即一条染色体)用包含 n 个城市编码的数组来表示,数组元素的顺序表示旅行的顺序,而且数组中的元素不会重复,因为一个城市只去玩一次。
假设:S1 = {17, 3, 21, …, 30},表示旅行的顺序为:郑州 -> 上海 -> 福州 -> … -> 成都。
阿姨的这次旅行总行程越短越好,那么取一条路线的总行程的倒数,作为适应度函数。假设东经为 x,北纬为 y,那么一个城市的坐标即为(x, y),那么一条路线 S_i = {(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)},i∈[0, m],所以:
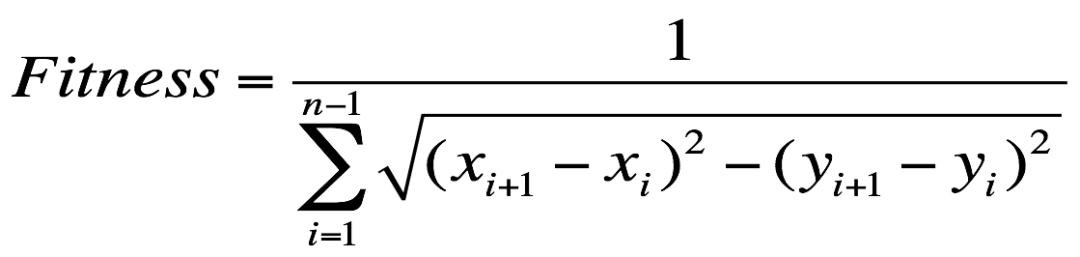
这里同样采用轮盘赌的选择方法。接着对路线随机配对,根据交叉率随机挑选出交叉点。对于路径序列,不能利用单点交叉法简单的互换父母染色体的部分基因,因为这样容易造成子代染色体中出现重复的城市编码。从父亲中获得交叉点的城市编码,保持这些编码在父亲中是顺序并填充到子代的头部,剩余的城市编码从母亲中获取并填满子代。比如:
父亲:{1,2,3,4,5,6,…}
母亲:{31,2,3,11,1,5,…}
子代:{1,3,4,5,6,…,31,2,11,…}
这里采用的变异方式是根据变异率随机挑选一条路线中的某两个城市编码,然后交换这两个编码的位置。比如 S = {1,3,4,5,6,…,31,2,11,…},那么,变异后 T = {1,11,4,5,6,…,31,2,3,…}。
至此,阿姨就可以根据这个遗传算法寻找总行程最短的旅游路线啦~
进化策略 ES
进化策略(Evolution Strategy)是一种求解参数优化问题的方法,模仿生物进化原理,假设不论基因发生何种变化,产生的结果(性状)总遵循零均值、某一方差的高斯分布。进化策略特点如下:
进化策略中的选择是按照确定方式进行的,不同于遗传算法中的随机选择方式;
进化策略中的重组算子,不同于遗传算法中的交叉,它不是简单的将个体的某一部分进行互换,而是使个体中的每一位都发生变化。
进化策略可分成两类,(μ+λ)-ES 和 (μ,λ)-ES。
(μ+λ)-ES
每次迭代产生 λ 个新解,通过和父代进行比较,将较好的 μ 个成为下一次迭代的父代,其他的直接舍去。
这种方式引入种群的思想,易于并行化,但容易陷入局部最优陷阱,主要用在多目标优化。
(μ,λ)-ES
每次迭代产生 λ 个新解(λ>μ),其中较好的 μ 个成为下一次迭代的父代,其他的直接舍去。这种方式所有解都只存活一代,可较好避免陷入局部最优。
(μ+λ) 选择可以保证最优个体存活,使群体的进化过程呈单调上升趋势,但是 (μ+λ) 选择保留旧个体,容易带来局部最优问题。(μ, λ)-ES 通常优于 (μ+λ)-ES,是当前进化策略使用的主流。
进化策略的 DNA 不再是用二进制进行表示, 而是用实数来代替,可以解决很多由实数组成的实际问题。进化策略产生子代的基因交叉,和遗传算法类似,可是基因变异应该怎么操作呢?由于基因是实数,所以无法像遗传算法那样采用简单的翻牌做法。
进化策略中的基因变异由变异强度来决定,正态分布在这里发挥了关键作用。
我们将父代遗传下来的基因值看做是正态分布的平均值,接着在这个平均值上附加一个标准差,这个时候便确定了一个正态分布,然后使用该正态分布产生一个数。比如在这个 8.8 位置上的变异强度为 2.5, 按照 2.5 的标准差和 8.8 的均值确定一个正太分布,然后产生一个新的值 8.7。
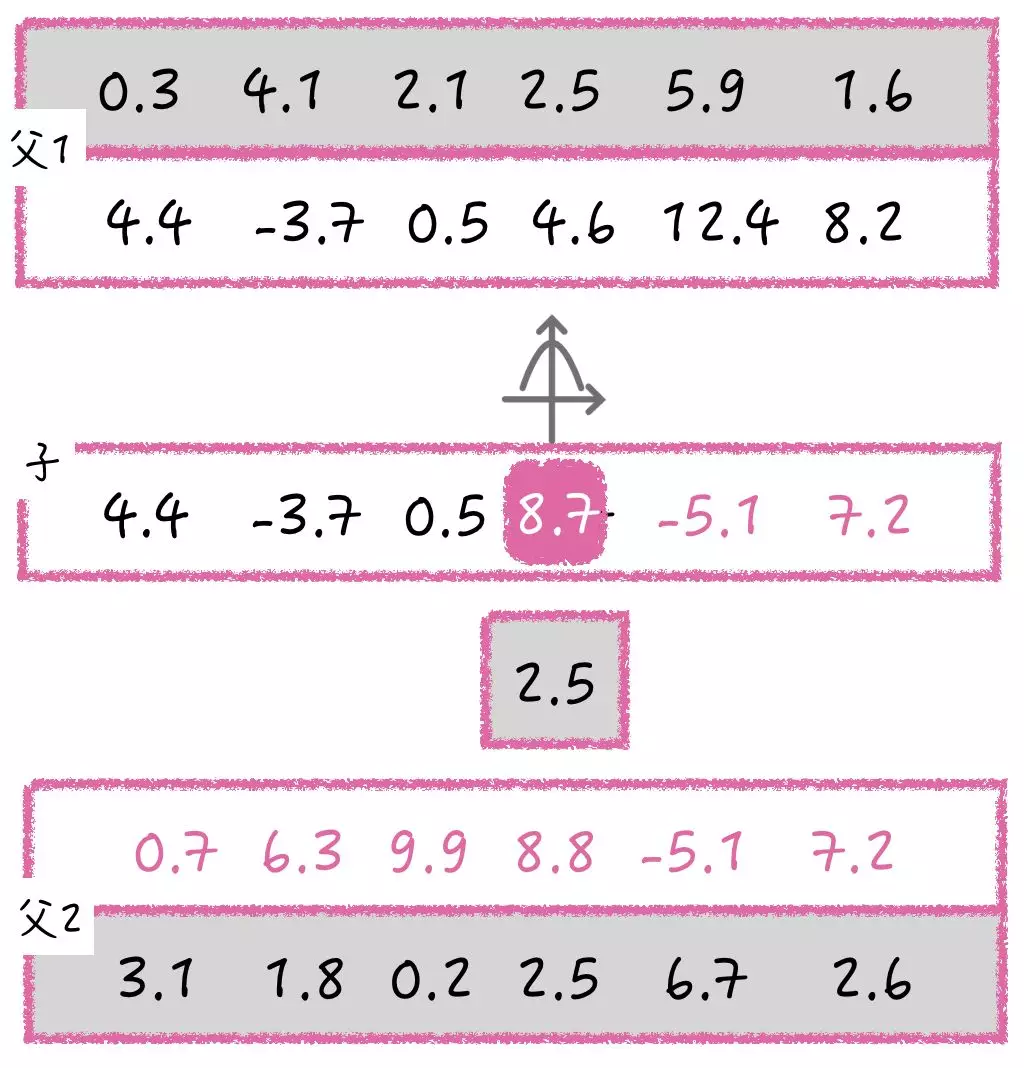
子代基因每一位上的值都会经过不同的状态分布进行变异,这样就会产生全新的子代 DNA。 所以,变异强度也可以被当成一组遗传信息从父代的 DNA 中遗传下来,而且变异强度本身也能进行变异。
进化策略的关键步骤在于:交叉、变异、选择、变异程度的变化。
和遗传算法一样,交叉就是交换两个个体的基因,主要有三种方式:
1.离散重组:先随机选择两个父代个体,然后将其分量进行随机交换,构成子代新个体的各个分量,从而得出新个体。
2.中值重组:这种重组方式也是先随机选择两个父代个体,然后将父代个体各分量的平均值作为子代新个体的分量,构成新个体。
3.混杂重组:这种重组方式的特点在于父代个体的选择上。混杂重组时先随机选择一个固定的父代个体,然后针对子代个体每个分量再从父代群体中随机选择第二个父代个体。也就是说,第二个父代个体是经常变化的。至于父代两个个体的组合方式,既可以采用离散方式,也可以来用中值方式。
变异比较简单,就是在每个分量上面加上零均值、某一方差的高斯分布的变化产生新的个体。这个某一方差就是变异程度,变异程度是会变化的,算法开始的时候变异程度比较大,当接近收敛后,变异程度会开始减小。
接着通过一个比较具体的进化策略案例来了解,如下图所示是 (1 + 1)-ES 中的变异程度公式。

变异程度的控制这里采用 1/5 成功规则。在还没收敛的时候增大变异程度,快要收敛的时候就减小变异程度。判定是否收敛的条件是,如果只有 1/5 的变异比原始父代好,那么就是快收敛了;如果有一半的变异比原始父代好, 那么就是还没收敛。