

Python 文件操作
读取键盘输入
Python提供了 input() 置函数从标准输入读入一行文本,默认的标准输入是键盘。
input 可以接收一个Python表达式作为输入,并将运算结果返回。
str = input("请输入:");
print ("你输入的内容是: ", str)
读和写文件
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
filename:filename 变量是一个包含了你要访问的文件名称的字符串值。
mode:mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。

例如,写入字符串到文件 foo.txt 中:
# 如果此文件存在则打开,否则创建此文件
f = open("/foo.txt", "w")
f.write( "Python 是一个非常好的语言。" )
# 关闭打开的文件
f.close()
第一个参数为要打开的文件名。
第二个参数描述文件如何使用的字符。 mode 可以是 'r' 如果文件只读, 'w' 只用于写 (如
果存在同名文件则将被删除), 和 'a' 用于追加文件内容; 所写的任何数据都会被自动增
加到末尾. 'r+' 同时用于读写。 mode 参数是可选的; 'r' 将是默认值。
注意:上面的案例中如果路径为:“D://test/foo.txt”且路劲不存在则会报错!为避免此
种情况,我们在创建文件时应该首先保证文件的路径正确。
import os
srcfile = "D://test/fool.txt"
fpath,fname=os.path.split(srcfile) #分离文件名和路径
if not os.path.exists(fpath): # 判断当前路径是否存在,没有则创建new文件夹
os.makedirs(fpath)
# 如果此文件存在则打开,否则创建此文件
print(fpath,fname)
f = open(srcfile,"w")
f.write( "这是测试文本" )
# 关闭打开的文件
f.close()
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符
串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容
都将被读取并且返回。
f.read()
# 打开一个文件
f = open("D:/test/fool.txt", "r")
str = f.read()
print(str)
# 关闭打开的文件
f.close()
f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 '\n'。f.readline() 如果返回一个空字
符串, 说明已经已经读取到最后一行。
f.readline()
# 打开一个文件
f = open("D:/test/fool.txt", "r")
str = f.readline()
print(str)
# 关闭打开的文件
f.close()
f.readlines()
f.readlines() 将返回该文件中包含的所有行。
如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
f.readlines()
# 打开一个文件
f = open("D:/test/fool.txt", "r")
str = f.readlines()
print(str)
# 关闭打开的文件
f.close()
另一种方式是迭代一个文件对象然后读取每行:
f = open("D:/test/fool.txt", "r")
for line in f:
print(line, end='')
# 关闭打开的文件
f.close()
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
# 打开一个文件
f = open("D:/test/fool.txt", "w")
num = f.write( "这是测试内容\n是的,的确非常好!!\n" )
print(num)
# 关闭打开的文件
f.close()
如果要写入一些不是字符串的东西, 那么将需要先进行转换:
# 打开一个文件
f = open("D:/test/fool.txt", "w")
value = ('www.baidu.com', 14)
s = str(value)
f.write(s)
# 关闭打开的文件
f.close()
复制/移动文件
如果要复制/移动文件,可以使用shutil模块中的方法:
shutil.move(srcfile,dstfile) #移动文件
shutil.copyfile(srcfile,dstfile) #复制文件
JSON、XML
JSON
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。
Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
json.dumps(): 对数据进行编码。
json.loads(): 对数据进行解码。
Python 编码为 JSON 类型转换对应表:
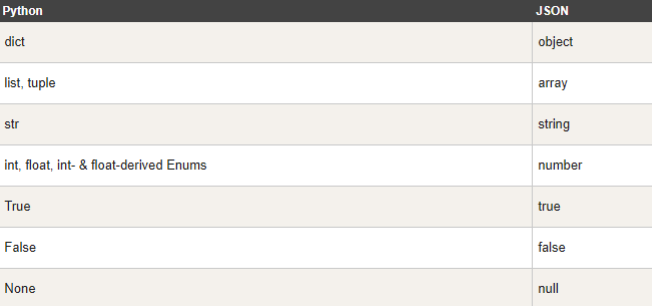
python转JSON:json.dumps()
import json
# Python 字典类型转换为 JSON 对象
data = {
'no' : 1,
'name' : 'nicaicai',
'url' : 'http://www.baidu.top'
}
json_str = json.dumps(data)
print ("Python 原始数据:", data)
print ("JSON 对象:", json_str)
JSON转Python :json.loads()
# 将 JSON 对象转换为 Python 字典
data2 = json.loads(json_str)
print(data2)
如果要处理的是文件而不是字符串,可以使用 json.dump() 和
json.load() 来编码和解码JSON数据。例如:
import json
data = (1,2,3,4,5)
# 写入 JSON 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据
with open('data.json', 'r') as f:
data1 = json.load(f)
print(data1)
XML
XML 指可扩展标记语言。XML 被设计用来传输和存储数据。它是一套定义语义标
记的规则,这些标记将文档分成许多部件并对这些部件加以标识。
python有三种方法解析XML,SAX,DOM,以及ElementTree
SAX (simple API for XML )
Pyhton标准库包含SAX解析器,SAX用事件驱动模型,通过在解析XML的过程中触
发一个个的事件并调用用户定义的回调函数来处理XML文件。SAX是一种基于事
件驱动的API。利用SAX解析XML文档牵涉到两个部分:解析器和事件处理器。
解析器负责读取XML文档,并向事件处理器发送事件,如元素开始及结束事件;而事
件处理器则负责对事件作出处理。
优点:SAX流式读取XML文件,比较快,占用内存少。
缺点:需要用户实现回调函数(handler)。
ContentHandler类方法介绍
characters(content)方法
调用时机:从行开始,遇到标签之前,存在字符,content的值为这些字符串。标签可以是开始标签,也可
以是结束标签。
startDocument()方法
文档启动的时候调用。
endDocument()方法
解析器到达文档结尾时调用。
startElement(name, attrs)方法
遇到XML开始标签时调用,name是标签的名字,attrs是标签的属性值字典。
endElement(name)方法
遇到XML结束标签时调用
make_parser方法
以下方法创建一个新的解析器对象并返回。
xml.sax.make_parser( [parser_list] )
参数说明:
parser_list - 可选参数,解析器列表
parser方法
以下方法创建一个 SAX 解析器并解析xml文档:
xml.sax.parse( xmlfile, contenthandler[, errorhandler])
参数说明:
xmlfile - xml文件名
contenthandler - 必须是一个ContentHandler的对象
errorhandler - 如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
parseString方法
parseString方法创建一个XML解析器并解析xml字符串:
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])
参数说明:
xmlstring - xml字符串
contenthandler - 必须是一个ContentHandler的对象
errorhandler - 如果指定该参数,errorhandler必须是一个SAX ErrorHandler对象
import xml.sax
class MovieHandler(xml.sax.ContentHandler):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# 元素开始调用
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print("*****Movie*****")
title = attributes["title"]
print("Title:", title)
# 元素结束调用
def endElement(self, tag):
if self.CurrentData == "type":
print("Type:", self.type)
elif self.CurrentData == "format":
print("Format:", self.format)
elif self.CurrentData == "year":
print("Year:", self.year)
elif self.CurrentData == "rating":
print("Rating:", self.rating)
elif self.CurrentData == "stars":
print("Stars:", self.stars)
elif self.CurrentData == "description":
print("Description:", self.description)
self.CurrentData = ""
# 读取字符时调用
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if (__name__ == "__main__"):
# 创建一个 XMLReader
parser = xml.sax.make_parser()
# 关闭命名空间
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = MovieHandler()
parser.setContentHandler(Handler)
parser.parse("movies.xml")
DOM(Document Object Model)
将XML数据在内存中解析成一个树,通过对树的操作来操作XML。一个DOM的解
析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内
存中的一个树结构里,之后你可以利用DOM提供的不同的函数来读取或修改文档
的内容和结构,也可以把修改过的内容写入xml文件。
优点:使用DOM的好处是你不需要对状态进行追踪,因为每一个节点都知道谁是
它的父节点,谁是子节点.
缺点:DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,使
用起来也比较麻烦!
DOM 解析案例
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print ("Root element : %s" %
collection.getAttribute("shelf"))
# 在集合中获取所有电影
movies = collection.getElementsByTagName("movie")
# 打印每部电影的详细信息
for movie in movies:
print ("*****Movie*****")
if movie.hasAttribute("title"):
print ("Title: %s" % movie.getAttribute("title"))
type = movie.getElementsByTagName('type')[0]
print ("Type: %s" % type.childNodes[0].data)
format = movie.getElementsByTagName('format')[0]
print ("Format: %s" % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print ("Rating: %s" % rating.childNodes[0].data)
description =
movie.getElementsByTagName('description')[0]
print ("Description: %s" % description.childNodes[0].data)
ElementTree(元素树)
ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度
快,消耗内存少。
相比而言,第三种方法,即方便,又快速。
两种实现
ElementTree生来就是为了处理XML ,它在Python标准库中有两种实现。
一种是纯Python实现,例如: xml.etree.ElementTree
另外一种是速度快一点的: xml.etree.cElementTree
尽量使用C语言实现的那种,因为它速度更快,而且消耗的内存更少! 在程序中可以这样写:
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
import xml.etree.ElementTree as ET
tree = ET.parse("movies.xml")
root = tree.getroot()
print(root.tag, ":", root.attrib) # 打印根元素的tag和属性
# 遍历所有的movie标签
for movie in root.findall("movie"):
# 查找movie标签下的第一个type标签
type = movie.find("type").text
# 获取movie标签的title属性
title = movie.get("title")
print(title, type)
Python 多线程
线程模块threading
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
threading模块常用方法:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前
和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以
下方法:
run(): 用以表示线程活动的方法。
start():启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的
异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
我们可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,也可使用threading.Thread()添加线程,接收参数target代 表这个线程要完成的任务,需自行定义。
不加 join() 的结果
我们让 T1 线程工作的耗时增加.
import threading
import time
def thread_job():
print("T1 start\n")
for i in range(10):
time.sleep(0.1) # 任务间隔0.1s
print("T1 finish\n")
added_thread = threading.Thread(target=thread_job, name='T1')
added_thread.start()
print("all done\n")
预想中输出的结果为
T1 start
T1 finish
all done
但实际却是:
T1 start
all done
T1 finish
加入 join() 的结果
线程任务还未完成便输出all done。如果要遵循顺序,可以在启动线程后对它调用join:
added_thread.start()
added_thread.join()
print("all done\n")
使用join对控制多个线程的执行顺序非常关键。举个例子,假设我们现在再加一个线程T2,T2的任务量较小,
会比T1更快完成: def T1_job():
print("T1 start\n")
for i in range(10):
time.sleep(0.1)
print("T1 finish\n")
def T2_job():
print("T2 start\n")
print("T2 finish\n")
thread_1 = threading.Thread(target=T1_job, name='T1')
thread_2 = threading.Thread(target=T2_job, name='T2')
thread_1.start() # 开启T1
thread_2.start() # 开启T2
print("all done\n")
输出的”一种”结果是:
T1 start
T2 start
T2 finish
all done
T1 finish
现在T1和T2都没有join,注意这里说”一种”是因为all done的出现完全取决于两个线程的执行速度, 完全有
可能T2 finish出现在all done之后。这种杂乱的执行方式是我们不能忍受的,因此要使用join加以控制。
我们试试在T1启动后,T2启动前加上thread_1.join():
thread_1.start()
thread_1.join() # notice the difference!
thread_2.start()
print("all done\n")
输出结果
T1 start
T1 finish
T2 start
all done
T2 finish
可以看到,T2会等待T1结束后才开始运行。
如果我们在T2启动后放上thread_1.join()会怎么样呢?
thread_1.start()
thread_2.start()
thread_1.join() # notice the difference!
print("all done\n")
输出结果
T1 start
T2 start
T2 finish
T1 finish
all done
也可以添加thread_2.join()进行尝试,但为了规避不必要的麻烦,推荐如下这种1221的V型排布:
thread_1.start() # start T1
thread_2.start() # start T2
thread_2.join() # join for T2
thread_1.join() # join for T1
print("all done\n")
"""
T1 start
T2 start
T2 finish
T1 finish
all done
"""
使用 Lock 的情况
lock在不同线程使用同一共享内存时,能够确保线程之间互不影响,使用lock的方
法是, 在每个线程执行运算修改共享内存之前,执行lock.acquire()将共享内存上
锁, 确保当前线程执行时,内存不会被其他线程访问,执行运算完毕后,使用
lock.release()将锁打开, 保证其他的线程可以使用该共享内存。
Python日期和时间
Python 提供了 time 和 calendar 模块可以用于格式化日期和时间
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
如函数time.time()用于获取当前时间戳
import time; # 引入time模块
ticks = time.time()
print ("当前时间戳为:", ticks)
时间戳单位最适于做日期运算。但是1970年之前的日期就无法以此表示了。太遥远的日期也不行,
UNIX和Windows只支持到2038年。
很多Python函数用一个元组装起来的9组数字处理时间:
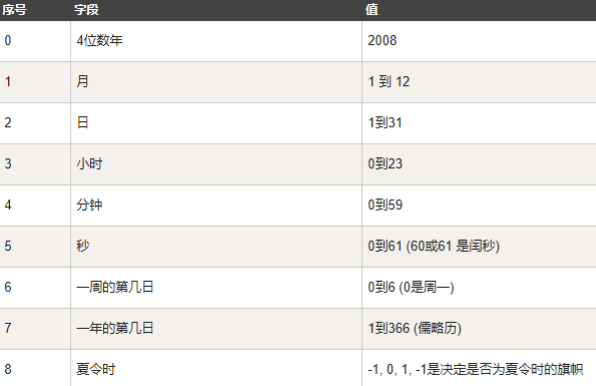
时间元组 上述也就是struct_time元组。这种结构具有如下属性:
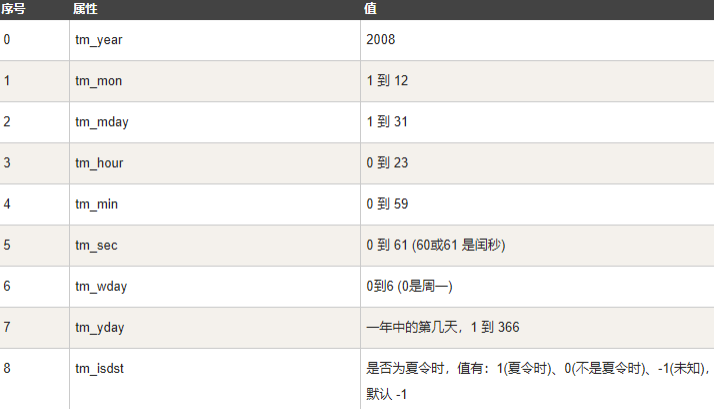
获取当前时间
从返回浮点数的时间辍方式向时间元组转换,只要将浮点数传递给如localtime之
类的函数。
import time
localtime = time.localtime(time.time())
print ("本地时间为 :", localtime)
获取格式化的时间
可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是
asctime():
import time
localtime =
time.asctime( time.localtime(time.time()) )
print ("本地时间为 :", localtime)
我们可以使用 time 模块的 strftime 方法来格式化日期,:
time.strftime(format[, t])
import time
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 格式化成Sat Mar 28 22:24:24 2016形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星
期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星
期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
日历(Calendar)模块
Calendar模块有很广泛的方法用来处理年历和月历,例如打印某月的月历:
import calendar
cal = calendar.month(2016, 1)
print ("以下输出2016年1月份的日历:")
print (cal)
日历(Calendar)模块
模块包含了以下内置函数:
calendar.calendar(year,w=2,l=1,c=6)
返回一个多行字符串格式的year年年历,3个月一行,间隔距离
为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每
星期行数。
calendar.firstweekday( )
返回当前每周起始日期的设置。默认情况下,首次载入caendar
模块时返回0,即星期一。
calendar.isleap(year)
是闰年返回True,否则为false
calendar.leapdays(y1,y2)
返回在Y1,Y2两年之间的闰年总数。
calendar.month(year,month,w=2,l=1)
返回一个多行字符串格式的year年month月日历,两行标题,一
周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星
期的行数。
calendar.monthcalendar(year,month)
返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的
整数。Year年month月外的日期都设为0;范围内的日子都由该月
第几日表示,从1开始。
calendar.monthrange(year,month)
返回两个整数。第一个是该月的星期几的日期码,第二个是该月
的日期码。日从0(星期一)到6(星期日);月从1到12。
calendar.prcal(year,w=2,l=1,c=6)
相当于 print calendar.calendar(year,w,l,c).
calendar.prmonth(year,month,w=2,l=1)
相当于 print calendar.calendar(year,w,l,c)。
calendar.setfirstweekday(weekday)
设置每周的起始日期码。0(星期一)到6(星期日)。
calendar.timegm(tupletime)
和time.gmtime相反:接受一个时间元组形式,返回该时刻的时
间辍(1970纪元后经过的浮点秒数)。
calendar.weekday(year,month,day)
返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1
(一月) 到 12(12月)。
