

期望极大算法(expectation maximization algorithm),简称EM算法,是一种迭代算法,可以用于含义隐变量(hidden variable) 的概率模型参数的极大似然估计,或极大后验概率估计. 期望极大算法(expectation maximization algorithm),简称EM算法,是一种迭代算法,可以用于含义隐变量(hidden variable) 的概率模型参数的极大似然估计,或极大后验概率估计.
延森不等式
在介绍EM算法之前,首先介绍一个重要的不等式——延森不等式(Jensen's Inequality)
- 令
,
是一个凸函数,且如果它有二阶导数,其二阶导数恒大于等于0,那么有:
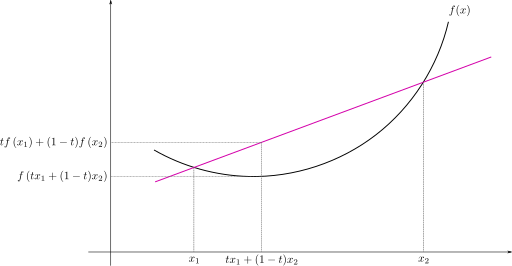
如果我们在此条件下,假设 为随机变量,则有:
-
同理,当
-
进一步,如果函数的二阶导数大于0,那么:
EM算法
问题定义
假设训练集 是由
个独立的无标记样本构成。我们有这个训练集的概率分布模型
,但是我们只能观察到
。我们需要使参数
的对数似然性最大化,即:
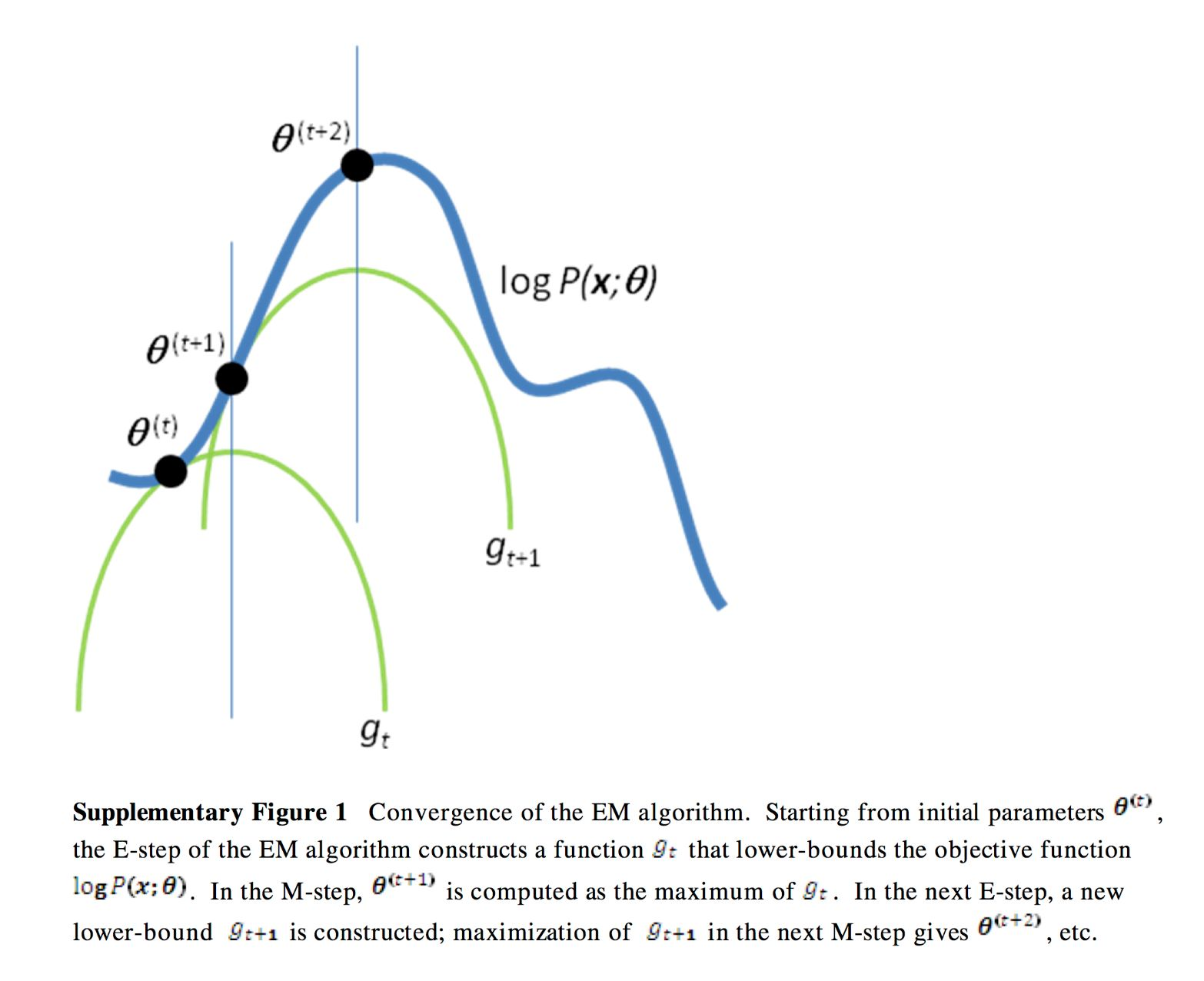
形式化过程
具体来说,我们需要每次为函数上的点
,找到一个凹函数
, 每次取
的最大值点为下一个
,迭代直到目标函数
达到局部最大值.
如下图所示:
推导
我们假设每一个 的分布函数为
,所以有
,有:
我们知道 是一个凹函数,如果把
看作随机变量,
看作随机变量的概率分布函数
的期望,则由延森不等式(3)可得到上述不等式.
这样以来, 的对数似然函数
便有了一个下界,但我们希望得到一个更加紧密的下界,也就是使等号成立的情况. 那么有:
则:
又 ,所以:
所以:
那么再由式(8),有:
算法流程
repeat
(E step) for each i
end for
(M step)
until 似然函数达到最大值
参考资料
[1] danerer-CSDN. Andrew Ng机器学习课程笔记(十三)之无监督学习之EM算法[EB/OL] , https://blog.csdn.net/danerer/article/details/80282612#expectation-maximization-algorithm, 2018-5-11/2018-7-30.
[2] 维基百科. Jensen's inequality[DB/OL], https://en.wikipedia.org/wiki/Jensen%27s_inequality, 2018-06-06/2018-7-30.
延森不等式
在介绍EM算法之前,首先介绍一个重要的不等式——延森不等式(Jensen's Inequality)
- 令
如果我们在此条件下,假设 为随机变量,则有:
-
同理,当
-
进一步,如果函数的二阶导数大于0,那么:
EM算法
问题定义
假设训练集 是由
个独立的无标记样本构成。我们有这个训练集的概率分布模型
,但是我们只能观察到
。我们需要使参数
的对数似然性最大化,即:
形式化过程
具体来说,我们需要每次为函数上的点
,找到一个凹函数
, 每次取
的最大值点为下一个
,迭代直到目标函数
达到局部最大值.
如下图所示:
推导
我们假设每一个 的分布函数为
,所以有
,有:
我们知道 是一个凹函数,如果把
看作随机变量,
看作随机变量的概率分布函数
的期望,则由延森不等式(3)可得到上述不等式.
这样以来, 的对数似然函数
便有了一个下界,但我们希望得到一个更加紧密的下界,也就是使等号成立的情况. 那么有:
则:
又 ,所以:
所以:
那么再由式(8),有:
算法流程
repeat
(E step) for each i
end for
(M step)
until 似然函数达到最大值
参考资料
[1] danerer-CSDN. Andrew Ng机器学习课程笔记(十三)之无监督学习之EM算法[EB/OL] , https://blog.csdn.net/danerer/article/details/80282612#expectation-maximization-algorithm, 2018-5-11/2018-7-30.
[2] 维基百科. Jensen's inequality[DB/OL], https://en.wikipedia.org/wiki/Jensen%27s_inequality, 2018-06-06/2018-7-30.
