

在11月27日至12月3日的KDnugget网站上,这篇文章被转载最多(https://www.kdnuggets.com/2017/12/top-news-week-1127-1203.html)。
我们使用for循环来完成大部分工作,这些工作需要对一长串的元素进行更新。我敢断言,几乎所有人阅读这篇文章的读者,在他们高中或大学里都里有肯定有使用过for循环语句编写自己的第一个矩阵或矢量乘法代码。for循环为编程社区提供了长期稳定的服务。
然而,for循环在处理大型数据集时执行速度通常较慢(例如:在大数据时代处理几百万条记录)。对于像Python这样的解释性语言来说尤其如此。如果您的循环体很简单,那么循环解释器会占用大量的开销。
幸运的是,大部分主流的编程语言都有另外一种编程语言可以取代它。Python也是如此。
Numpy是Numerical Python(http://numpy.org/)的简称,同时也是Python生态系统中高性能科学计算和数据分析所需要的基本包。它几乎是所有高级语言工具的基础,如Pandas和 scikit-learn都是在Numpy的基础上编译的。TensorFlow使用NumPy阵列作为底层编译块。在这之上构建了Tensor对象和用于深度学习的graphflow(使用了大量的线性代数运算在一个长的列表/矢量/矩阵)。
Numpy提供的两个最重要的特性是:
- Ndarray:一个快速空间高效的多维数组,提供了矢量化计算操作和复杂的广播能力(https://towardsdatascience.com/two-cool-features-of-python-numpy-mutating-by-slicing-and-broadcasting-3b0b86e8b4c7)
- 标准的数学函数,可以在不写循环的情况下,对整个数据数组进行快速操作。
在数据科学、机器学习和Python社区中,您经常会遇到这样的断言:Numpy是更速度的。因为它是基于矢量的实现,而且它的许多核心例程都是用C语言编写(基于CPython 框架:https://en.wikipedia.org/wiki/CPython)。
这篇文章是一个CPython 框架的很好阐述(http://notes-on-cython.readthedocs.io/en/latest/std_dev.html)Numpy可以与各个方面协同工作。甚至可以使用Numpy api编写裸机骨C例程。Numpy阵列是均匀类型的密集阵列。相反,Python列表是指向对象的指针数组,即使它们是相同的对象类型。你可以从区域性关联(https://en.wikipedia.org/wiki/Locality_of_reference)得到收获。
许多Numpy操作是用C语言实现的,避免了Python中循环的开销、指针指向每个元素的动态类型检查(https://www.sitepoint.com/typing-versus-dynamic-typing/)。Numpy速度的提升取决于你所执行的操作。对于数据科学和现代机器学习来说,这是一个非常宝贵的优势,因为通常数据集的大小会达到数百万甚至数十亿。并且您不希望使用For循环和它的相关的算法进行更新。
如何用一个中等大小的数据集来验证它呢?
这里是Jupyter Github代码链接(https://github.com/tirthajyoti/PythonMachineLearning/blob/master/How%20fast%20are%20NumPy%20ops.ipynb)。其中在一些简单的代码行中,Numpy的操作速度与常规Python编程的速度不同,比如for循环、map-function(https://stackoverflow.com/questions/10973766/understanding-the-map-function)或list-comprehension(http://www.pythonforbeginners.com/basics/list-comprehensions-in-python)。
这里我简单的概括下基本流程:
- 创建一个中等数量集的浮点数列表,最好是从连续的统计分布中抽取出来,比如高斯分布或均匀随机分布。为了演示我选择了100万条数据
- 在列表中创建一个ndarray对象,也就是矢量化
- 编写简短的代码块来更新列表,并在列表上使用数学运算,比如以10为底的对数。使用for循环、map-function和list-comprehension。并使用time()函数来核实处理100万条数据需要花费多长时间
t1=time.time()
for item in l1:
l2.append(lg10(item))
t2 = time.time()
print("With for loop and appending it took {} seconds".format(t2-t1))
speed.append(t2-t1)- 用Numpy的内置数学方法(np.log10)在ndarray对象上做同样的操作。计算出花费了多长时间
t1=time.time()
a2=np.log10(a1)
t2 = time.time()
print("With direct Numpy log10 method it took {} seconds".format(t2-t1))
speed.append(t2-t1)- 在一个列表中存储执行时间,并绘制出一个差异的柱状图
下面是结果显示。你可以运行Jupyter笔记本上的所有代码单元块来重复整个过程。每次它会生成一组新的随机数,因此精准的执行时间可能会有所不同。但总体来说,趋势始终是相同的。您可以尝试使用各种其他的数学函数/字符串操作或者集合,来检查是否适用于一般情况。
这里有一个由法国神经科学研究员编写的完整开源在线书籍(https://www.labri.fr/perso/nrougier/from-python-to-numpy/#id7)。
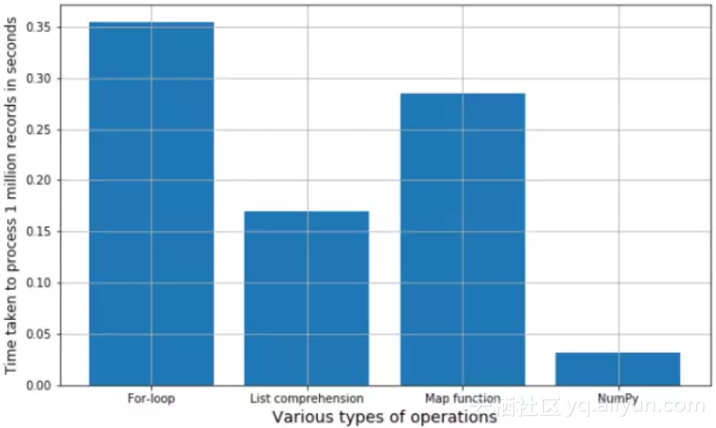
简单数学运算比较速度的柱状图
如果你有任何问题或想法要分享,请与作者联系(tirthajyoti@gmail.com)。您也可以在Python、R或MATLAB和机器学习资源中查看作者的GitHub库(https://github.com/tirthajyoti),获得其他有趣的代码片段。你也可以在LinkedIn(https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/)上关注我。
原文发布时间为:2017-12-21
本文作者:数据派
