

近期工作中调整了搜索得分策略,考虑影响面比较广,原工程里并没有A/B测试,因此完整实现了A/B测试部分代码,在此记录心得。
一. 什么是A/B测试
我们以具体例子引入:Airbnb曾经推出了2个关于推广产品的文案:
-
文案一:“邀请你的好友可以获得25美元”
-
文案二:“邀请你的好友将使好友获得25美元”
如下图:

哪种文案更好呢?我的直觉是文案一,但没有数据支撑很难下结论。一个对策是:将这2个文案同时发布到线上,各为其分配50%流量,观察二者点击率的差异。事实上后来结果令人吃惊,文案二效果好于文案一。
以上想法就是A/B测试的基本思想。简单来说就是把总流量分为A和B两份,部分用于旧方案,部分用于新方案,上线一段时候后对比二者各项指标(点击率、转化率),从而衡量新策略的优劣。A/B测试是一种横跨前端/后台/算法的产品优化思想,例如UI层面上的广告位置在屏幕中的偏移量对点击流量的影响(Google),又或新搜索/推荐策略的提出,最终效果均需要线上A/B测试验证。
二. 算法策略类的A/B测试
算法策略类的优化步骤
搜索/挖掘/推荐三者的优化步骤很相似,一般流程是:
-
模型训练/策略优化,并自行确认效果
-
交给PM评估几组(100-1000条,视影响面情况而定)数据
-
修复、优化PM评估过程中发现的问题
-
由PM确认新模型/策略在效果上确实有提升
-
线上小流量A/B测试
-
线上流量对比有提升,考虑全量上线
搜索策略架构简介
简单的搜索算法主要分为3部分:倒排索引(离线)和keyword搜索(实时),和实时更新索引。因keyword搜索部分用户感知最强烈、影响面最广,因此大部分A/B测试都设置在这一阶段。keyword搜索阶段总体分为如下几个步骤:
-
用户query分析
-
按照query中的条件,构建过滤(Filter)/查询(Query)条件
-
查询得到召回集(Recall Set)
-
对结果集进行打分(Score)、排序(Rank)
流程图如下:
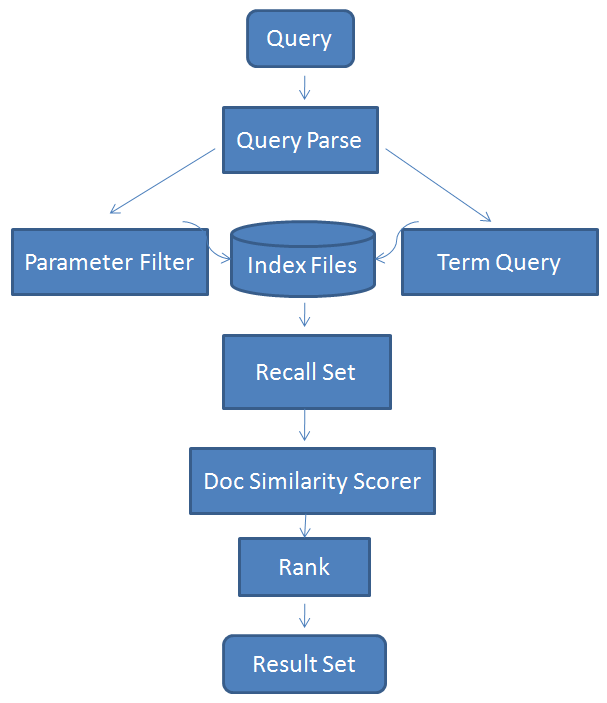
文字解释为:
-
首先对用户query进行分析,获取其可用
Filter做过滤的term和只能通过查询Query得到的term,原因很简单,查询比过滤慢多了 -
从索引里查询、过滤得到结果候选集Recall Set
-
对结果进行相似度打分、排序
-
召回最终结果
关于第一步,实际sample如下:
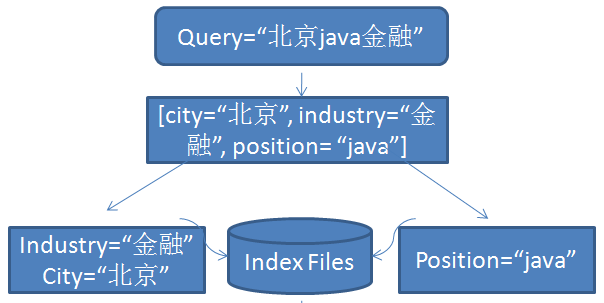
注意到industry和city字段可以通过Filter过滤以提高检索速度。
A/B测试实际开发
设计思想
在设计之初我们就应该明确:到底哪些环节可以做A/B测试呢?
答案是:全部。
整个keyword搜索过程中,Query分析、Query过滤和查询、结果集召回、结果集打分、排序过程均可以设置A/B测试。在实际使用中,我们往往一次只需要在某一个环节做A/B测试,此时可以将其他环节的策略置为相同策略。但从设计思想上,编写伊始就针对所有环节配置A/B测试是值得推荐的。
代码编写
1. 原始策略类的编写
首先针对所有环节编写一个Strategy接口,
public interface ISearchStrategy {
# query解析,构建搜索条件
public ISearchConditionParser getSearchConditionParser();
# 打分
public SortDocsScorer getSortDocsScorer(SearchCondition searchCondition);
# 排序
public ISortDocsSorter getSortDocsSorter(SearchCondition searchCondition);
public void setStrategyName(String strategyName);
public String getStrategyName();
}为何以上接口没有查询、过滤环节的方法呢?这是因为所有策略的查询和过滤过程均相同,不同的是query解析过程中封装的filter/query参数,因此没有必要添加该方法。
接下来不同策略的实现:
例如我们本次只是对结果集打分环节做A/B测试,那么编写2个类:DefaultSearchStrategy 和NewScoreStrategy ,先来看DefaultSearchStrategy :
public class DefaultSearchStrategy implements ISearchStrategy {
private String strategyName;
public DefaultSearchStrategy() {
}
@Override
public ISearchConditionParser getSearchConditionParser() {
return new DefaultSearchConditionParser();
}
@Override
public SortDocsScorer getSortDocsScorer(SearchCondition searchCondition) {
if (searchCondition != null) {
DefaultDocSimScorer simScorer = new DefaultDocSimScorer(searchCondition);
pass
}
return null;
}
@Override
public ISortDocsSorter getSortDocsSorter(SearchCondition searchCondition) {
if (searchCondition != null) {
pass
}
return null;
}
@Override
public void setStrategyName(String strategyName) {
this.strategyName = strategyName;
}
@Override
public String getStrategyName() {
return strategyName;
}
}NewScoreStrategy 和以上区别在于打分环节:
@Override
public SortDocsScorer getSortDocsScorer(SearchCondition searchCondition) {
if (searchCondition != null) {
NewSimScorer simScorer = new NewSimScorer(searchCondition);
pass
}
return null;
}2. 策略的使用
现在策略已经写好了,怎么在实际的搜索过程中决定调用哪一个呢?首先我们一个类ABStrategyContext 用于初始化新旧策略并为二者命名:
public class ABStrategyContext {
/** 旧策略 */
public static final ISearchStrategy oldStrategy;
/** 新策略 */
public static final ISearchStrategy newStrategy;
static {
/** 策略初始化 */
oldStrategy = new DefaultSearchStrategy();
oldStrategy.setStrategyName("defaultStrategy");
newStrategy = new NewScoreStrategy ();
newStrategy.setStrategyName("newScoreStrategy ");
}
}然后构建工厂向消费者稳定提供这2种策略。针对每个用户id,我们为其分配新旧策略中的某一个。
public class SearchStrategyFactory {
private SearchStrategyFactory() {
}
/** 双重检验锁 */
public static SearchStrategyFactory getInstance() {
if (instance == null) {
synchronized (SearchStrategyFactory.class) {
if (instance == null) {
instance = new SearchStrategyFactory();
}
}
}
return instance;
}
public ISearchStrategy buildSearchStrategy(UserIdentify uid) {
/** 用户被分配走新策略 */
if (shouldUseNewStrategy(uid)) {
return ABStrategyContext.newStrategy;
}
/** 用户被分配走旧策略 */
return ABStrategyContext.oldStrategy;
}
}上述代码描述了针对不同用户id分配新旧策略的方式,该工厂的模式使用了双重检验锁(double checked),能保证该工厂只创建一次且被所有线程高效共享。
针对某个用户,策略分配方法被调用处代码为:
ISearchStrategy strategy = SearchStrategyFactory.getInstance()
.buildSearchStrategy(criteria.getUserIdentify());
/** 拿到strategy后,为各个环节填充具体策略 */
ISearchConditionParser parser = strategy.getSearchConditionParser();
SortDocsScorer scorer = strategy.getSortDocsScorer(searchCondition);
ISortDocsSorter sorter = strategy.getSortDocsSorter(searchCondition); 注意到SearchStrategyFactory 中中有一个判断shouldUseNewStrategy(uid)方法没有实现,那么现在问题是,我们如何决定某个用户该走哪种策略呢?
3. 用户分桶
A/B测试的几个要点:
-
同一用户在任意时间,看到的应该是同一策略
-
确保A和B样本分布与总体分布相似
-
置信度保证。如果总体流量就不大,对新策略分配的流量为总流量的1%,实际对比后即使效果有提升,也很难断定新策略更优
针对第一点,我们需要构建一个很大的缓存池,将产生搜索动作的用户id对应策略分配方案记录下来。针对第二点,我们需要使分配过程尽量随机,针对第三点,新策略流量可以适当设置大一些。
分桶代码如下:
/** 利用LRU策略缓存已经计算过的hash值 */
private LRUCache<String, Long> cache = new LRUCache<>(500000);
private static volatile SearchStrategyFactory instance;
/** 总流量权重 */
private static final int WEIGHT = 100;
private boolean shouldUseNewStrategy(UserIdentify uid) {
hashValue = getRandom(getHashValue(userIdentify.getUserId()));
/** 根据新策略流量占百分比[0-100]决定用户分配概率 */
if (hashValue * WEIGHT < DynamicConfig.NEW_STRATEGY_FLOW) {
return true;
}
return false;
}
/**
* 从cache获取hash值,不存在则计算hash值并存入cache
* @param key
* @return
*/
private long getHashValue(String key) {
Long hash = cache.get(key);
if (hash == null) {
hash = SimpleHashFunction.DJBHash(key);
cache.put(key, hash);
}
return hash;
}
/**
* 根据seed返回[0,1]之间的随机数
* @param seed
* @return
*/
private double getRandom(long seed) {
return new Random(seed).nextDouble();
}三. 后续及总结
我们此处仅对策略进行了A/B测试,要配合数据平台日志分析对比工作,还需要在用户搜索日志中增加strategyName字段来作新旧策略区分。
最后一个问题是,什么样的方案不适合A/B测试?以下是我的个人理解。
-
两个版本变量差异过大。例如多个新策略混合在一起与原始策略做A/B测试,尽管我们能对比新策略组合是“变好了”还是“变差了”,但无法预知具体是哪个新策略产生的增益,后续一旦做策略优化则不知从何做起。
-
功能性方案。例如现在新增“高级搜索”需求,项目完成后我们是不需要对有“高级搜索”和没有“高级搜索”做A/B测试的,原因是它是功能性方案。评估“高级搜索”是否有价值,后续对“高级搜索”流量分析和调研用户反馈即可,这并不是A/B测试的范畴。
