


文章来源:GitHub 作者:Chih-Yao Ma 翻译:马卓奇
导读:本文是基于论文《TS-LSTM and Temporal-Inception: Exploiting Spatiotemporal Dynamics for Activity Recognition》实现的。最近双流(two-stream)深度卷积神经网络(CNN)在识别视频人物动作领域取得了重大进展。尽管他们取得了成功,但是基于基础双流CNN拓展出来的方法却没有对可能的网络结构进行系统的探索,从而更深一步的在视频序列中探索时空动力学。除此之外,这样的网络通常使用具有不同基准的双流网络。因此,那些使用循环神经网络(RNN)或基于时间构造的特征向量的卷积网络(Temporal-CNN)的各种方法,它们的不同之处,以及区分因素是很不清晰的。作者基于这一现状,提出了时间分割RNN(TS-LSTM)和时间开始(Temporal-inception)CNN两个网络。
如何利用时空动力学进行活动识别?
什么是双流CNN?
自从卷积神经网络(CNN)在静态图像上取得了巨大的成功之后,许多科学家开始研究相似的方法在视频理解和人物活动识别领域的应用。最近的大多数工作都是受到了双流(two-stream)卷积神经网络的启发。双流卷积神经网络整合了从RGB图像和光流图中提取的空间和时间信息。这两种类型的图像分别输入两个分离的网络,每个网络的预测分进行融合形成最终的输出。
如何将双流CNN用于视频活动识别
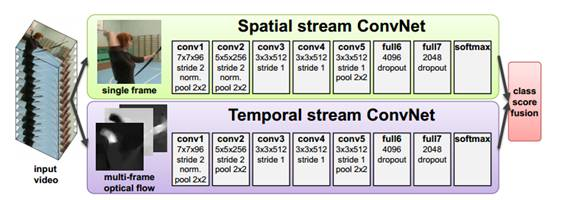
双流网络由空间卷积网络和光流场卷积网络(时间维度网络)构成。视频可以分成空间与时间两个部分,空间部分指独立帧的表面信息,如物体、场景等;而时间部分信息指帧间的光流,携带着帧之间的运动信息。相应的,所提出的双流网络结构由两个深度网络组成,分别处理时间与空间的信息。
空间卷积网络的输入是单帧,这样的分类网络其实有很多,例如AlexNext,GoogLeNet等,可以先在imageNet上预训练,再进行参数迁移。光流场卷积网络的输入是几个连续帧之间的堆积光流位移场,可以描述物体的运动信息。
论文内容提要
在这个工作中,作者首先演示了一个强基准的双流CNN,使用ResNet-101。然后使用这个基准来完整的检查RNN和Temporal-CNN在提取时空信息时的使用情况。基于实验结果,作者提出两个不同的网络来进一步整合时空信息:1)时间分割RNN(TS-LSTM),和2)Inception结构的时间卷积网络(Temporal-Inception)。结果显示使用RNN(使用LSTM)和时间卷积在时空特征矩阵上都可以利用时空动力学来提升整体性能。然而,每个方法都需要合适的调整来达到目前最好水平的性能。比如说,LSTM要求数据进行预分割,否则他们就不能完全利用时间信息。该实验分析证明了每个方法各自特定的局限性,这些方法可以组成将来工作的基础。算法在UCF101和HMDB51上的实验结果达到了最好的水平,分别是94.1%和69.0%。
算法框架的结构:
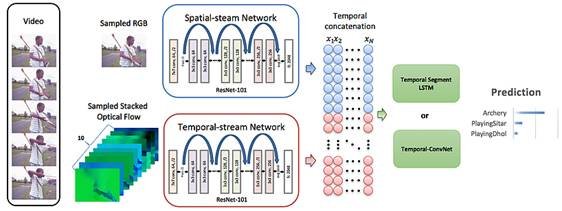
作者使用在ImageNet上进行预训练的ResNet-101来搭建双流卷积神经网络,从中提取空间和时间特征,然后微调来进行单帧活动预测。空间和时间特征进行连接,并且时间上构造进特征矩阵。构造的特征矩阵输入到作者所提出的两个网络中:TS-LSTM和Temporal-Inception。
TS-LSTM:
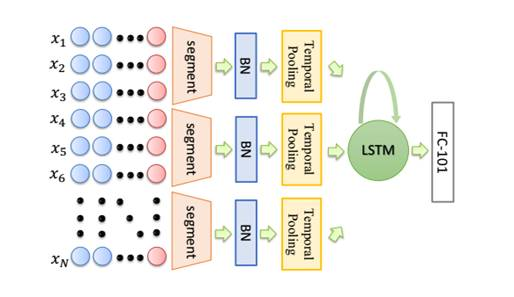
TS-LSTM首先将特征矩阵划分为几个时间分割段。每个时间段通过平均或最大池化层进行池化,然后该输出按顺序依次输入LSTM层。
Temporal-Inception:
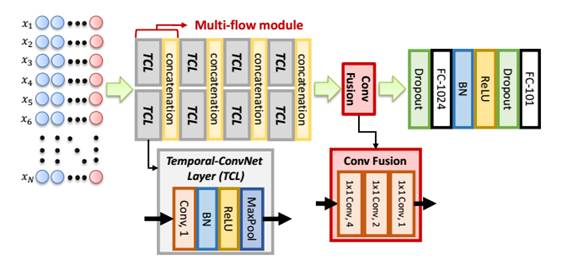
Temporal-Inception的输入是一个2D矩阵,由横跨不同时间间隔的特征矢量组成。每个多流模型中,有两个不同卷积核的时间卷积层(TCL)。每个多流模型将时间维度减少至一半。因此,用多个时间卷积层和两个全卷积层,输入特征矩阵就可以映射到类别预测。
论文的实现
示例动图:
下面的动图展示了TS-LSTM和时间开始算法预测结果的前三名结果。动图顶部的文字是真实值,剩下三个是每个方法的预测值。预测值右侧的横条代表模型进行预测的可信度。

数据库环境要求:
目前项目使用UCF101和HMDB51数据库。
-
Linux (实验在Ubuntu 14.04上测试)
-
Torch
-
CUDA 和 cuDNN
-
NVIDIA GPU (强烈推荐)
-
torch-pastalog (训练状态可视化)
我们提出了两种不同方法来训练活动识别模型:TS-LSTM和Temporal-Inception。
怎样输入数据?
采用第一阶段双流ConvNet产生的特征向量作为训练输入。可以使用"/CNN-Pred-Feat/"路径下的代码来产生特征。也可以直接下载作者用网络生成的特征向量。作者按照UCF101和HMDB51的数据划分来划分训练集和测试集,如果想和作者的结果对比,请使用同样的训练列表和测试列表,因为划分方法会很大程度上影响整体的性能。
训练特征:
|
UCF101 |
HMDB51 |
C |
|
|
1 |
RGB |
sp1 sp2 sp3 |
sp1 sp2 sp3 |
|
2 |
TV-L1 |
sp1 sp2 sp3 |
sp1 sp2 sp3 |
测试特征:
|
UCF101 |
HMDB51 |
C |
|
|
1 |
RGB |
sp1 sp2 sp3 |
sp1 sp2 sp3 |
|
2 |
TV-L1 |
sp1 sp2 sp3 |
sp1 sp2 sp3 |
如何使用RNN进行训练?
作者使用Element-Research提供的RNN库进行训练。
安装方法:
$ luarocks install rnn
在下载了特征向量之后,请修改./RNN/data-ucf101.lua 中的代码,将路径改为你放置特征向量文件的路径。
开始训练:在./RNN下执行
$ th main.lua -pastalogName'model_RNN' -nGPU 1 -dataset 'ucf101' -split '1' -fcSize'{0}' -hiddenSize '{512}' -lstm -spatFeatDir'<path/to/feature/>' -tempFeatDir '<path/to/feature/>'
训练和测试损失会汇报,结果会存入日志文件。每一个epoch之后,如果学习率和最高的测试准确率有更新,算法会进行汇报。
用Temporal-ConvNet进行训练
开始训练:在./Temporal-ConvNet下执行:
$ th run.lua -o<output_folder_name> --dataset <dataset-name>
在下载了特征向量之后,请修改./Temporal-ConvNet/data-2Stream.lua中的代码,将路径改为你放置特征向量文件的路径。
更多细节和超参数调整,请参考./Temporal-ConvNet/文件夹中的readme文件。
训练和测试损失会汇报,结果会存入日志文件。每一个epoch之后,如果学习率和最高的测试准确率有更新,算法会进行汇报。
实验结果对比
基准双流ConvNet:
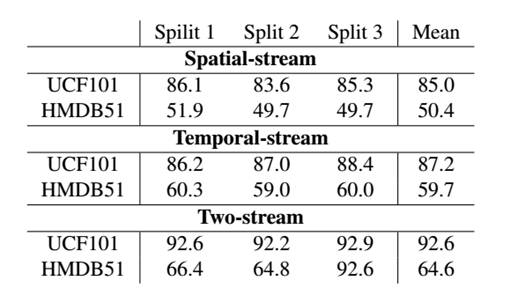
空间卷积网络、时间流卷积网络和双流ConvNet在UCF101和HMDB51数据库上的结果:
TS-LSTM:
TS-LSTM中每个结构在UCF101划分1上的对比结果:
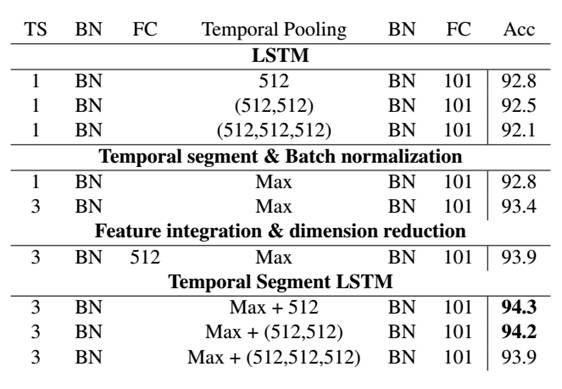
通过结合时间分割和LSTM单元,算法可以在每个时间片段上权衡时间动力学,并且显著提高预测准确度。该发现表明我们需要仔细思考和理解LSTM是如何对时间信息建模的。实验结果显示,在UCF101上,使用更深的LSTM层会有过拟合的倾向。这可能是因为,我们从时间和空间CNN中产生的特征,经过微调可以在帧级别对视频类别进行鉴定。时间上的特征表示动力没有其他序列数据那么复杂,例如声音和文本。所以,当增加堆积LSTM层的数量时,算法就会趋于过拟合。
Temporal ConvNet:
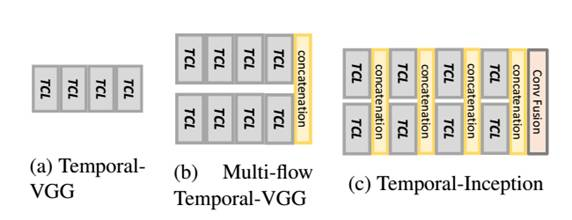
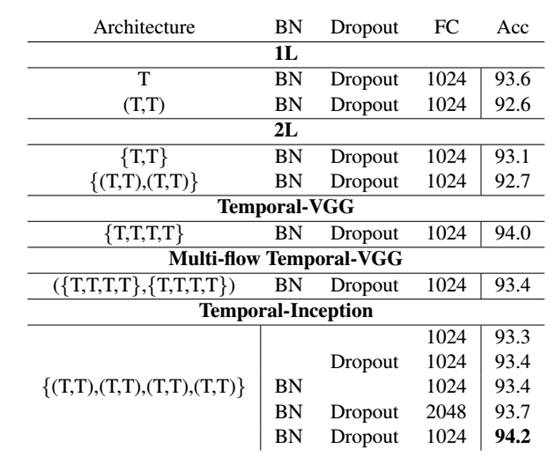
三种不同Temporal-ConvNet的结构对比,其中Temporal-Inception结构有最好的表现。
Temporal-ConvNet在UCF101上的结果对比,可以看出Temporal-Inception结构的准确率最高。
最终整体结果:
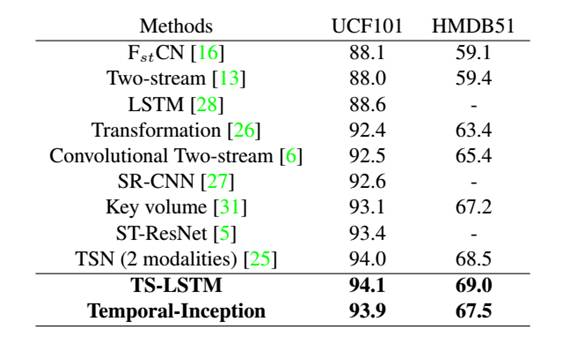
提出的TS-LSTM和Temporal-Inception网络在UCF101和HMDB51数据库上,与当前最好方法的整体结果对比。可以看出我们所提出的两个网络达到了最高的准确率。
可以用帧级别的特征进行训练吗?
为了标准化对比,作者所采用的特征是在每个视频上进行均匀采样得到的。如果想用帧级别的特征(对UCF101中所有视频进行提取特征,速率为25fps)进行训练,请参考《采用帧级别特征以及RNN进行时间增加》。
论文地址:https://arxiv.org/pdf/1703.10667.pdf
GitHub资源:https://github.com/chihyaoma/Activity-Recognition-with-CNN-and-RNN
《采用帧级别特征以及RNN进行时间增加》:https://github.com/chihyaoma/temporal-augmentation
