

Swift 3.0 String和Characters相关操作
Swift的String是C风格的字符串,可以直接通过+操作符来实现字符串的相组合,也可以通过()这个操作符实现复杂的自定义可变串。
同时Swift提供了相关多针对不同编码的方法,不用再为不用的编码所纠结了。
最常见的
let str = "hello world"
//一些特殊字符 通过\转译字符
let einstein = "\" l love u\" - cc "
//unicode码
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // , Unicode scalar U+1F496
//带音标符号
let eAcute: Character = "\u{E9}"
// é
let combinedEAcute: Character = "\u{65}\u{301}"
// e followed by ́
// eAcute is é, combinedEAcute is é
构造空字符串
//生成空字符串
var empty = ""
var another = String()
if empty.isEmpty {
print("i'm empty")
}
//String的拼接
var changeStr = "i"
changeStr += "love u"
Swift中的String不是对象
Swift 中的String 是 value类型的 ,并不是对象的类型,不像OC中的NSString一样,每次构造新的String的时候都会复制一份新的。这一特性确保了,你在任何方法和函数中拿到的String都是绝对安全的,除非你去改变它的值的话,一般这个值是不会变得
Swift 的编译器会进行优化,只有当你改变值的时候才会去进行拷贝操作,所以用的时候并不会有性能比问题
Character的操作
一个简单的循环
for character in "Dog!".characters {
print(changeStr)
}
// D
// o
// g
// !
//
Swift字符串和字符类型是完全支持Unicode兼容,如本节所述。
- Unicode Scalars 【Unicode 标量】
Swift的native String 是来自于Unicode Scalars格式的,Unicode Scalars是一个唯一的21位的字符
Unicode标量是从U +0000范围到Unicode代码点U + D7FF(包括)或 U+ E000到U +10FFFF(不包括)。Unicode的标量不包括Unicode代理对代码点,这是在范围内U + D800到U + DFFF(包括)的代码点
String的修改
可以通过String提供的方法和参数来对String的内容进行修改,你也可以用下标来进行操作
String.Index
WTF?这个东西是啥?? 第一次见到的时候摸不着头脑,为啥我不能通过脚标来获取指定位置的字符串,一定要通过这个奇怪的东西去操作呢?
回想下刚刚上面说的,不同的字符需要不同的内存来存储,所以不同的编码的位置也不同,你每次都要把编码转换一遍才能确定位置,所以在Swift中不能用脚标来确定字符的位置
let greeting = "hello world"
greeting[greeting.startIndex]
//h
greeting[greeting.index(after: greeting.startIndex)]
//e
greeting[greeting.index(before: greeting.endIndex)]
//d
let index = greeting.index(greeting.startIndex, offsetBy: 3)
greeting[index]
//l
这里就不能像Java一样直接通过脚标来获取指定位置的字符了
下面这样的操作也会报错
greeting[greetin.endIndex] //error
greeting.index(after: endIndex) // error
通过indices来遍历
for index in greeting.characters.indices {
print("\(greeting[index])" ,terminator:" ")
}
//h e l l o w o r l d
//小技巧
//print(_:separator:terminator:) 两个参数代表 间隔符 和 不换行
这个indices可以用在类似的Collection数据结构 , 比如Array,Dictionary 和 Set
String的插入和删除
插入一个单独的字符 通过insert(_:at:)方法
插入另外一个字符串 通过insert(contentsOf:at:)方法
greeting.insert("!", at: greeting.endIndex)
//"hello world!"
greeting.insert(contentsOf: " swift".characters, at: greeting.endIndex)
//"hello world! swift"
greeting.insert(contentsOf: " ,".characters, at: greeting.index(greeting.startIndex, offsetBy: 5))
//"hello , world! swift"
删除一个固定位置的字符 通过remove(:at:)方法 删除一段子字符串 通过removeSubrange(🙂 方法
greeting.remove(at: greeting.startIndex)
//删除了"h"
greeting.removeSubrange(greeting.startIndex..
String的匹配方法
提供了三种匹配方法
因为Swift中的String不是对象,所以能够直接使用==来进行比对。
let str1 = "hello"
let str2 = "hello"
if str1 == str2 {
print("the same")
}
两个字符串相等的条件是,完全相同并且扩展的读音也相同 , 如果用不同的编码的话也是能够比对成功的。
// "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"
- 前缀匹配 和 子串匹配
判断某个字符串是否有某个前缀 hasPrefix(_:)
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
//头匹配
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// Prints "There are 5 scenes in Act 1"
//子串匹配
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// Prints "6 mansion scenes; 2 cell scenes"
String的不同编码格式的遍历
原始的串位 “Dog‼”
. UTF-8 遍历
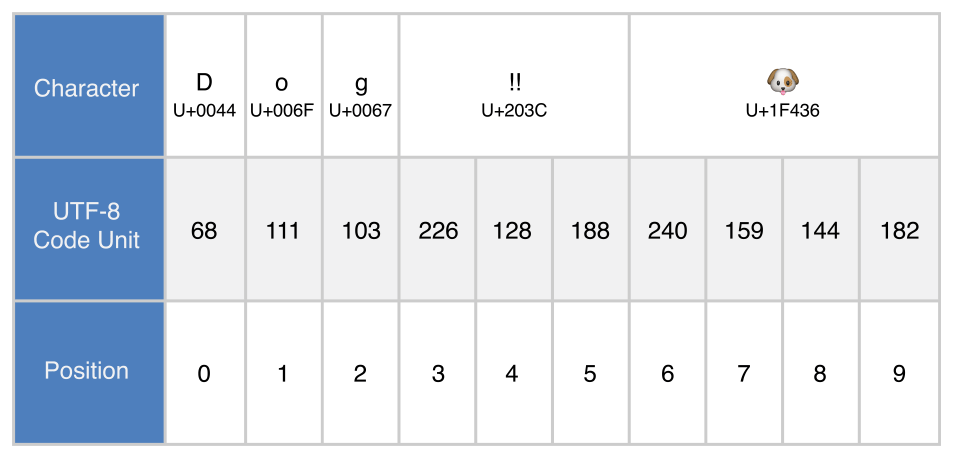
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// 68 111 103 226 128 188 240 159 144 182
. UTF-16 遍历
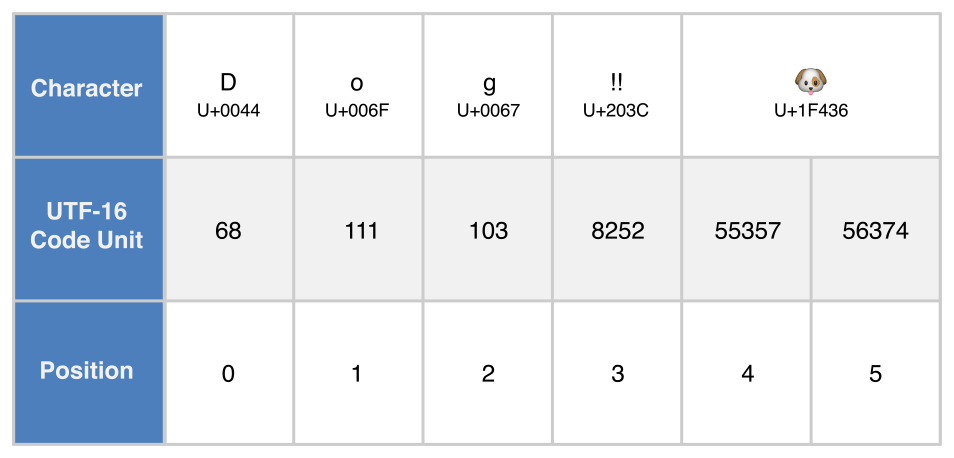
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 55357 56374 "
. Unicode整数集
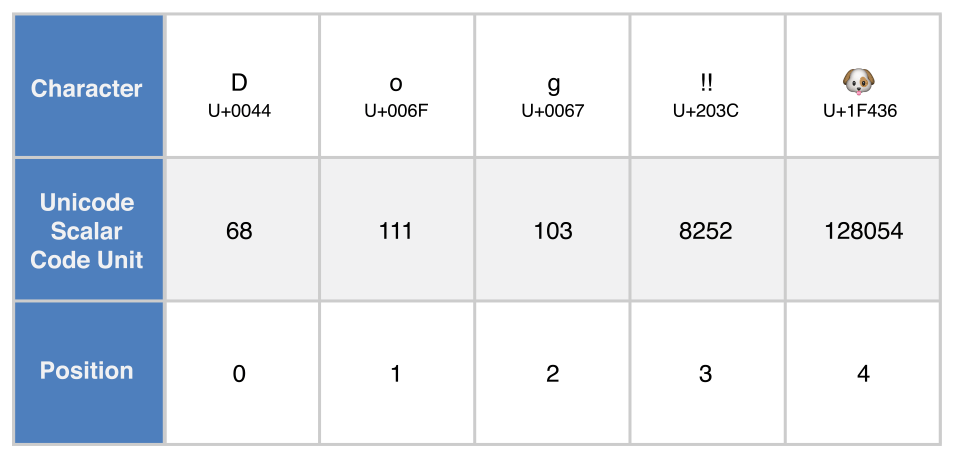
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 128054 "
同时这个就是字符
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
//
