

背景
一直以来,在电商搜索场景,除了排序推荐等大场景,还有较多的小场景,或者说是比较零散的场景,目前知乎上关于推荐排序的文章也是非常多,今天来说一下其他小场景上遇到的问题-推荐query。为什么说这个话题呢,因为最近被线上推荐的query糟心了一波,所以记录一下心路历程。
在用户使用蘑菇街进行搜索想要的商品,或者搜索商品进行浏览时,app会对用户在不同阶段进行引导,而这些引导的业务场景流量或大或小,主要包括下拉框推荐、搜索底纹词、搜索热词、浏览商品时的相关推荐、搜索无结果少结果推荐等。这些场景无一不是对query的推荐,而推荐query可能经常出现语义不通、语义重复、存在错别字、多了标点符号、推荐语与场景不符、无结果少结果问题,这些问题出现频率不高,但时不时运营同学就会给我们上报几个,搞得我们很烦恼。
要解决上面的问题,方法有很多,也可以针对每种问题设计不同的策略,可以从最近成交或点击比较好的query中筛选一批出来,直接用于线上,也没有问题。但是我们想从根本上解决这个问题,借鉴商品排序和推荐,想构建query的统一管理database,简称querybase吧。理由也很简单,希望querybase中的query质量都是过硬的,所有的线上query透出,都从这个集合中产生。同时,我们也不希望运营老是来找我们,打断我们的进程,那所有的场景架构需要调整一下,方便线上人工干预。
通过这件事情,也非常清晰的感受到——没有100%符合预期的算法,没有银弹,永远对模型保持一份未知性和出错性。
场景整体架构
调整前后对比
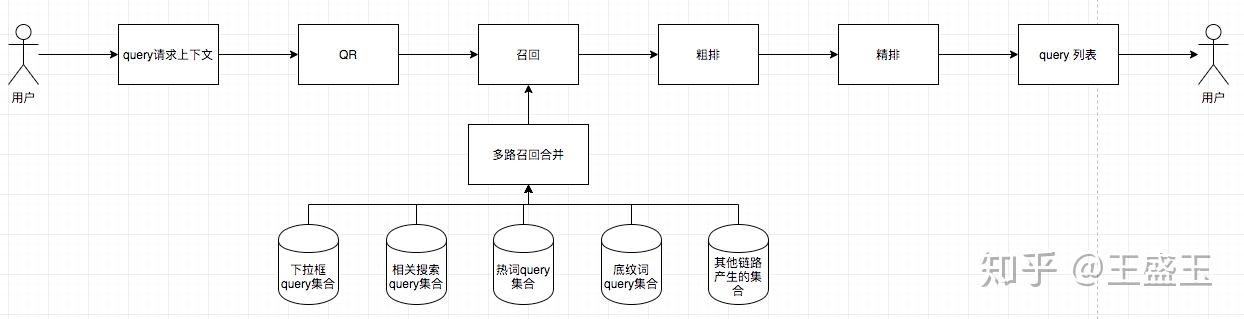
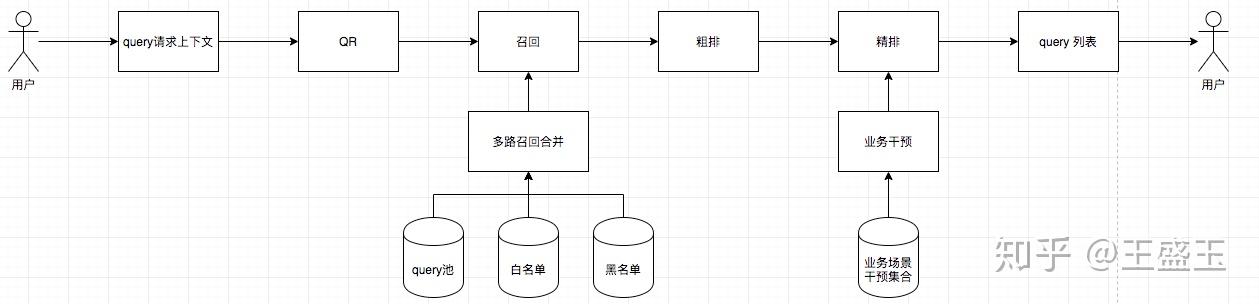
简单说一下现在的整体流程
- 用户请求上下文包含的不同场景下,请求推荐词时的上下文情况;例如下拉框推荐的前缀词,热词推荐用户站内浏览、点击、购买记录,相关推荐时的当前搜索词等。
- QR包括简单的纠错识别、实体识别、否定词判断、分词等。
- 召回阶段,依据用户的上下文,采用不同的策略,从候选集合中获取可能满足条件的集合。例如下拉框通过建立前缀索引,召回满足条件的query;热词可以根据用户最近产生的浏览商品记录,召回与该商品关联度高的query,或者通过搜索过的query召回与其相似的query;或者采用万物可embedding的方式,dssm 向量召回。召回阶段有很多的方法,每个场景各不相同,但可以归一合并成常见的几种,这个中知乎中文章较多,可搜索查看。
- 粗排阶段,粗排对召回的大量query进行简单的排序。例如根据query的历史生成的静态分数、query的类目偏好、query的产品词偏好、query的长度等。
- 精排阶段,对粗排初步筛选过的query进行个性化排序。这里可用的模型较多,如wide&deep、din、dien、dupn等。
流程上大同小异,说一下调整的部分
- 将召回集合合并,统一管理;优势是方便管理、质量可以得到保证、干预方便;缺点是数据量比较大,不同场景需要的query不一定相同,如何有效合并和透出。
- 在透出层增加业务干预层,运营和其他业务团队如有特殊需求,例如促销活动,需要在热词、底纹词引流,可进行简单配置。
调整的结构不大,但是对人力的释放效果是明显的,由此更加感受到算法一定要配合一定的人工,方显得更加智能。
QueryBase要求
要对线上的query进行统一管理,不光要保证各类场景的query要求,还要保证集合的质量、更新,入库和出库是非常重要的一环。
质量
质量是保证线上query的基础,也是构建querybase原因,通过对线上badcase的收集,异常通常出现在一下几个方面:
- 语义问题;不知道用户在搜索什么,一旦推荐,用户会觉得莫名其妙。
- 错别字;连衣群、牛子裤
- 无结果少结果;query因为商品上下架、长度、季节产生召回不足。
- 语义相同或相近;例如热词和相关搜索场景,坑位有限,同义或近义需要过滤。
- 敏感过滤;情色、辱骂
更新
query静态分:静态分类似于商品的质量分,主要是主要是根据query的多天表现LR计算得分,特征主要有长度、当天的曝光pv、曝光uv、点击pv、点击uv、成交GMV、成交uv等。
query进出:为保证query池的更新迭代,必须将当下常搜的query引入query池,同时保证会引起badcase的query从QueryBase中去除。其次,某些时下流行词,可能近一段时间搜索量特别大,还要涉及到新词发现,将新词纳入query池。
QueryBase构建
目前QueryBase主要用于电商搜索,为保证快速的迭代,初版database我们初定了17条规则
- 每天曝光pv流量占比80%的类目,作为query池类目范围
- 每个类目下曝光pv流量占比80%的query作为类目下的query
- query考虑召回商品数量过滤
- 特殊标点符号过滤,¥¥连衣裙
- 停用词过滤,百搭的连衣裙
- 重复词过滤,连衣裙连衣裙百搭,连衣裙百搭/百搭连衣裙
- 颠倒词序的query通过分词后,query排序聚合,query词序选择点击量最高的
- 聚合后的query指标为group sum
- 错别字query过滤,连衣群
- 英文大小写统一
- query中空格去除
- query搜索次数过滤,数据分布
- query点击次数,数据分布
- query长度过滤
- query召回类目过滤,情色
- query可召回类目线下生成,类目偏好
- 过滤固定类目下的query
17条规则下可以初步保证QueryBase的覆盖和质量,但是仍然存在一定量的badcase,可以看到规则中涉及到不少阈值判断,而在阈值边界或用户常搜索的异常,往往被涵盖进去。例如:
- 错别字
- 语义不通顺
- 阈值边界,17条都满足,依然有问题。
- 同义和近义query
针对上述存在的问题,我们设计了语言模型、命名实体识别、纠错系统和term weight,这些技术不光用于QueryBase的构建,还用于其他的场景。
下面简单说一下语言模型QueryBase中发挥的作用
异常检测——语言模型Language Model
针对错字、多字、少字、表意不清问题,单独通过规则是无法完全解决的。最近bert等语言模型在NLP领域大放异彩,我们猜想是否可以建立语言模型来学习电商搜索下用户的搜索表意习惯,将不符合搜索习惯的文本,认为是异常文本。基于这个猜想,我们进行了如下的探索:
- 单向语言bigram模型
- 单向LSTM语言模型
- 双向单语言模型
- mask语言模型
- bert语言模型
- 多任务联合训练语言模型
通过6个版本的迭代,最终可以有效对异常进行检测,发现搜索query中的异常片段。
单向语言bigram模型
我们先通过单向bigram语言,采用拉布拉斯平滑(Laplacian Smoothing),降低未出现的概率分布。采用单向语言bigram语言模型,主要学习的是字与字之间的紧密度。 基于的假设是正常表述相对于错误出现次数更多。
模型的弊端也是显而易见的,对长依赖的不足;简单如连衣裙、阿迪达斯在bigram上表现并不理想;出现次数较高,但是在当前上下文下不正常。
优点就是速度非常快,所有的bigram参数可以离线下来。
检测异常方法:bigram出现次数过少
单向LSTM语言模型
针对上述bigram语言模型问题,我们尝试lstm等长依赖模型。模型很简单,采用lstm作为模型,每个step的向量预测下一位可能出现的字。
效果:可以有效解决上述bigram长依赖问题,例如连衣裙、阿迪达斯,概率的表现为越来越大,前文为连衣,预测裙的概率在0.9以上。同时,我们发现语言模型会学习到词的内聚效果,在分词位置,概率会出现明显下降。这是符合预期的,因为在词的后一位出现的字过多,概率分布也就比较平均。
缺点:
- 阈值不好取;采用阈值对概率进行异常判断时,首先会遇到分词点的干扰,需要将阈值设为小于分词点的值;取的大误伤较大,取的小不具备效果。
- 概率不具备可比性;当前阈值小到多少才是小呢?有的位置上下文丰富,且取值比较单一,则一旦出现异常,概率则非常小;有的地方取值较为丰富,出现低概率时,并不一定是异常。
- 上下文依赖为单向,概率在词内与词长成正比,但在分词位置无法判断是分词还是异常。
异常检测:当概率小于某个阈值,并且当前字概率与最大概率相差倍数较大。
双向单语言模型

名词解释:因为单向语言模型存在上述问题,那么怎么避免呢?我们采用双向语言模型是否可以解决,可以部分解决。于是我们采用两个单向语言模型,一个正向一个反向,所以称为双向单语言模型。
效果:可以有效解决上述说到的问题
检测:两个单语言模型,可以发现无论是词的开始还是结束都会有个较高的概率,正向在词开始位置概率较低,反向则概率较高。于是,我们得出正低反高,词开始,正高反低,词结束,这样就解决了单向语言模型词开始概率较低问题;现在异常检测可以采用两种方式,正反双向概率都较低,同时正反向有一个较高概率;第一种方式的较低阈值和较高阈值不好设定,第二种方式采用倍数阈值判断异常,只要当前字的概率与最大概率比值大于阈值,则认为是异常。
缺点:模型对异常的敏感度还是较低,模型仅考虑一个方向效果。
mask语言模型
针对双向单语言模型问题,参考bert的预训练方式,简化后采用双向lstm构造mask语言模型,同时利用上下文来预测mask位置应该填充哪个字。
效果:模型预测更加敏感,对未出现或低频出现的表达都识别为异常,mask模型对常见异常的识别效果是双向单语言模型的两倍,由此可见同时考虑上下文的效果。
检测:当前字概率与最大值概率比值,同时最大值概率大于一个基本阈值。
缺点:其实迭代到这一步已经有一定的效果了,因为数据偏置的问题,在长尾和低频query下的表现不理想。同时,现在一直采用卡阈值的方式,阈值始终无法达到完美的效果。
bert语言模型
近几年来ELMO,GPT,bert,albert等预训练模型不断屠榜,一次次刷新模型效果上线,组内采用bert模型对异常值进行识别。为什么考虑bert,我们基于以下几个认识
- bert的效果确实好,采用mask的训练方式,self+attention,残差连接等,在nlp各个领域都取得较好的效果
- bert的预训练数据集合大,这个数据集合可以较好的弥补自身场景数据缺少和数据偏置带来的问题,这个特点正好弥补电商类目搜索query分布偏置带来的问题。
- bert的MLM任务与本次任务非常合拍;我们想发现query中的异常点,而该异常点必然在上下文情况下的预测概率非常低,这和mask方式相同。
基于以上三种考量,我们开始在bert模型上进行模型尝试; 为了验证模型对异常点的检测能力,我们将常见的异常或错别字query构建成为验证集合,按照bert原始构建MLM任务训练集合的方式,对正常query随机替换,构建训练集合。
为了验证bert模型在不同层学习到的特征,我们将模型分为多组:fine tuning、all fix、部分层fine tuning,分别训练模型查看效果,得到结果:
- fine tuning模型在各项指标上效果最好,但是部分层fine tuning也可逼近all fine tuning的效果
- 其中all fix效果效果最差,但是部分case评测下也有优于all fine tuning
- 直接调整高层模型参数,收效较小;调整底层参数,指标提升效果明显;首尾同时调整,可以逼近fine tuning效果,不过这也可能是本次任务较为简单有关。
- 长尾query上收效较好,在长尾类目下评测,原来识别异常的query,在bert模型可较好识别。
- 语气词识别;通常在电商搜索中不希望query中存在的、了、么、呢等语气词,但原始bert训练数据中大量存在;通过对fine tuning训练集合的清理,可以让模型正确识别其为异常。
多任务联合训练语言模型
为了提升模型效果,我们在bert模型构建多任务联合辅助训练。任务一:MLM任务,在电商数据上进行MLM训练,强化上下文下词的出现概率。任务二:词异常检测任务,判断每个位置出现的词是否异常,两个任务loss加和。
说一下这里遇到的坑
- MLM任务与bert原始训练方式区别,不再增加MASK位标识;首先因为在真实预测场景中,无mask标识符;其次,增加mask标识后,预测每个位置是否为最可能的字,需要构建多次预测,rt较长;最后,增加mask位置后与error识别任务有一定gap,取消mask后两者的样本构建方式基本一致。
- 两个任务的样本都是0.8概率随机替换词,0.2概率保持原样。
- 替换预测word;用真实场景的wordid作为MLM的预测输出,这样可以减少softmax的大小,同时替换词也更符合真实场景;当然复杂一点可以借鉴wordvec的负采样方式,这个我们没有做尝试。
多任务联合训练语言模型是目前迭代后效果最好的,相较于bert单一任务,提升在1-2个点。
线上效果
query池构建完成后,我们将其应用在电商的下拉框推荐、底纹词推荐、热词推荐、综合搜索推荐、无结果少结果相关推荐,不同场景在策略不变的情况下指标提升在2%~10%之间,这说明query质量的提升,对优化体验的提升非常明显。
小问题
这里抛个问题出来,也是迭代过程中遇到且没有想明白的。我们在bert多任务训练的时候,抛弃[MASK]标识,采用wordid随机替换的方式,但是效果也很好,而且bert原文中也提到[MASK]的引入会带来预训练和fine-tuning的差异,那么为什么还要引入[MASK],直接随机替换是否可以?欢迎大佬留言探讨

总结
QueryBase的构建过程理解和学习到了不少东西,对语言模型有了更深的理解,感觉自然语言处理是比较神奇的方向,不仅要理解模型和数据,还要对人类的说话方式有所涉及。啧啧啧,有意思。
其次,本次模型迭代也更能理解语言模型迭代的历程,大规模训练数据集下pre-training的模型,效果确实牛,也不枉媒体的各种报道。
最后,NLP小组也成功跨入bert等pre-training时代,开始尝试、压缩、部署这类大模型,线上rt确实是个大问题。
非常感谢参与其中的小伙伴们坚持不懈的努力!
