

前言
开发手机应用最主要的两个点是 1.处理用户屏幕触碰输入 2.界面效果展示(包含动画和各种反馈) ,但是在早期的 Android 并不是那么尽人意,给用户的感觉就是卡顿,系统处理图形能力差,开发者再怎么优化也是枉然。
从 Android 4.0+ 开始,以 “run fast, smooth, and responsively” 为核心目标对 UI 进行优化,应用默认都开启和使用硬件加速方式加速 UI 的绘制。首先讲解一下硬件加速相关概念。
硬件加速
Android 系统的 UI 从 绘制 到 显示在屏幕上 是分两个步骤的
第一步:在Android 应用程序这一侧进行的。(将 UI 构建到一个图形缓冲区 Buffer 中,交给SurfaceFlinger )
第二步:在SurfaceFlinger进程这一侧进行的。(获取Buffer 并合成以及显示到屏幕中。)
其中,第二步 在 SurfaceFlinger 的操作一直是以硬件加速方式完成的,所以我们说的硬件加速一般指的是在 应用程序 图形 通过GPU加速渲染 到 Buffer 的过程。
CPU / GPU结构对比
以下内容摘自 : 木叶57的博客,总结的很到位。
CPU : Central Processing Unit , 中央处理器,是计算机设备核心器件,用于执行程序代码。
GPU : Graphic Processing Unit , 图形处理器,主要用于处理图形运算,通常所说“显卡”的核心部件就是GPU。
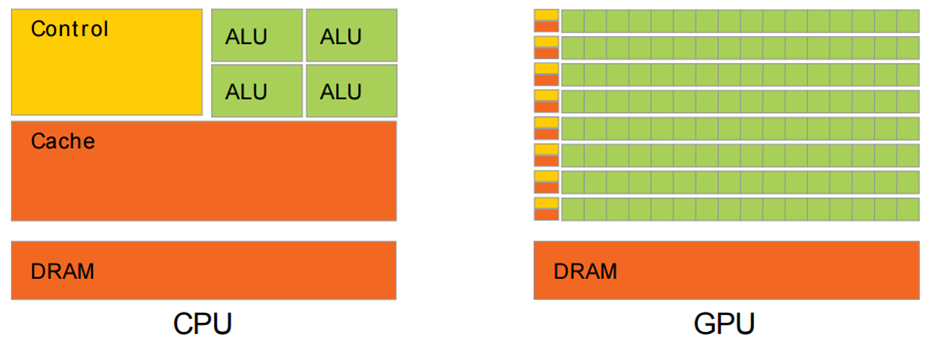
下面是CPU和GPU的结构对比图。其中:
- 黄色的Control为控制器,用于协调控制整个CPU的运行,包括取出指令、控制其他模块的运行等;
- 绿色的ALU(Arithmetic Logic Unit)是算术逻辑单元,用于进行数学、逻辑运算;
-
橙色的Cache和DRAM分别为缓存和RAM,用于存储信息。
-
从结构图可以看出,CPU的控制器较为复杂,而ALU数量较少。因此CPU擅长各种复杂的逻辑运算,但不擅长数学尤其是浮点运算。
-
- 以8086为例,一百多条汇编指令大部分都是逻辑指令,数学计算相关的主要是16位加减乘除和移位运算。一次整型和逻辑运算一般需要1~3个机器周期,而浮点运算要转换成整数计算,一次运算可能消耗上百个机器周期。
-
- 更简单的CPU甚至只有加法指令,减法用补码加法实现,乘法用累加实现,除法用减法循环实现。
-
- 现代CPU一般都带有硬件浮点运算器(FPU),但主要适用于数据量不大的情况。
-
CPU是串行结构。以计算100个数字为例,对于CPU的一个核,每次只能计算两个数的和,结果逐步累加。
- 和CPU不同的是, GPU就是为实现大量数学运算设计的。从结构图中可以看到,GPU的控制器比较简单,但包含了大量ALU。GPU中的ALU使用了并行设计,且具有较多浮点运算单元。
- 硬件加速的主要原理,就是通过底层软件代码,将CPU不擅长的图形计算转换成GPU专用指令,由GPU完成。
OpenGL
Android 开发人员可以通过使用 OpenGL ES 来实现硬件加速渲染图形。
首先了解一下两个单词 : OpenGL ,OpenGL ES
- OpenGL(Open Graphics Library) : 是指定义了一个跨编程语言、跨平台的编程接口规格的专业的图形程序接口。它用于三维图像(二维的亦可),是一个功能强大,调用方便的底层图形库。
- OpenGL ES (OpenGL for Embedded Systems) 是 OpenGL 三维图形 API 的子集,针对手机、PDA和游戏主机等嵌入式设备而设计。
这里我们首先要明确什么是硬件加速渲染,其实就是通过GPU来进行渲染。
GPU作为一个硬件,用户空间是不可以直接使用的,它是由GPU厂商按照Open GL规范实现的驱动间接进行使用的。
也就是说,如果一个设备支持GPU硬件加速渲染,那么当Android应用程序调用Open GL接口来绘制UI时,Android应用程序的 UI 就是通过硬件加速技术进行渲染的。
Android 的图形组件
如果把开发者编写的应用程序图形效果展示过程当做是一次酣畅淋漓的画作过程,那么绘画过程中 Android 的各个角色又是怎么分工合作的 :
画笔
- Skia : CPU 绘制 2D 图形;
- Open GL : GPU 绘制 2D / 3D 图形;
画纸
- Surface : Android 4.4+ 应用程序都在 Surface 这张画纸上进行绘制和渲染。
画板
- Graphic Buffer : 在屏幕刷新机制提到,Android 4.1+ 后有 3 块 Graphic Buffer 用于应用程序图形绘制,或 SurfaceFlinger 的合成和显示。
合成及显示
- SurfaceFlinger : 合成所有图层并进行显示。(Surface 的投递者)
下面了解Android 图形系统的整体架构
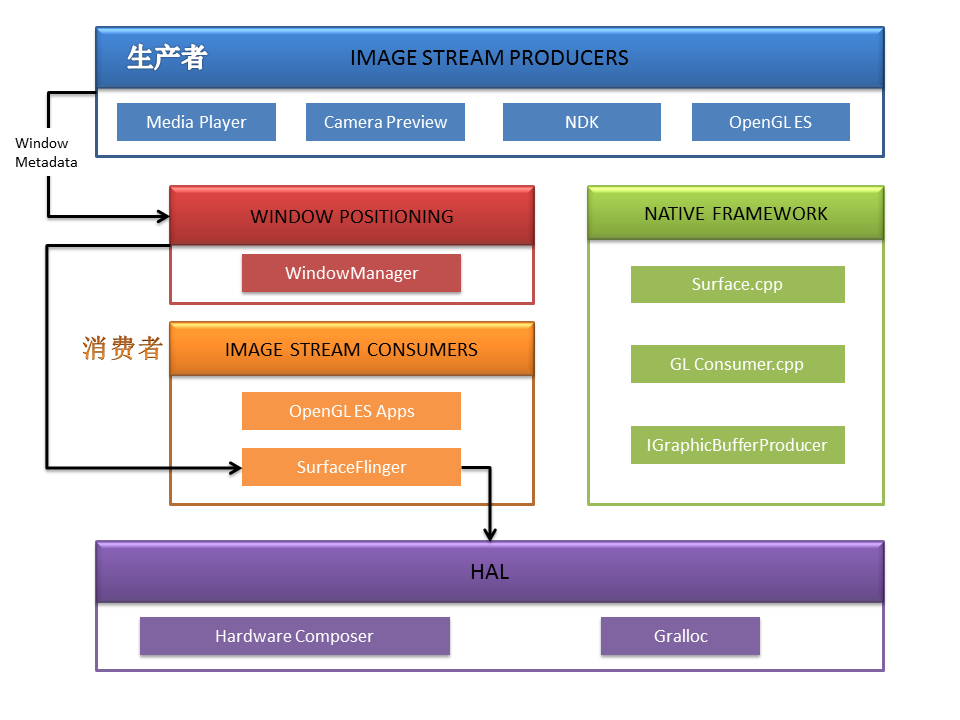
查看大图
- Image Stream Producers : 图形流生产者,应用程序内绘制到 Surface 的图形( xml / java 实现的图形,或者是视频 )
- Window Manager : 在Android Window 机制探索这篇文章中说道 ——「Window是View的直接管理者。」,Window 是 View的容器,每个窗口都会包含一个 Surface 。Window Manager 管理窗口的各个方面,包括生命周期,输入和焦点事件,屏幕旋转,切换动画,位置,转换,Z-Order等。Window Manager 会将 Window 的这些元素数据传递给 SurfaceFlinger 。
-
SurfaceFlinger : 根据Window Manager 提供的内容将它们合成并输出到显示屏上。它使用 OpenGL 和 HardWareComposer 来合成 Surface 。(其它消费者也有可能是OpenGL ES 应用,例如相机或者其它),开头有提到硬件加速指的是应用程序内图形渲染加速的过程,而 SurfaceFlinger 一直是通过 OpenGL 来合成和输出图形。
- HWC : Hardware Composer ,硬件合成器。(了解即可),这是显示控制器系统的硬件抽象。SurfaceFlinger 会委派一些合成的工作给 Hardware Composer 以此减轻 GPU 的负载。这样会比单纯通过 GPU 来合成消耗更少的电量。
- Gralloc : Graphics memory allocator 用来分配图形的内存。
- 应用程序可以通过
Skia来绘制2D图形,也可以用OpenGL来绘制2D / 3D图形(应用加速指的是应用内使用OpenGL处理和渲染图形) - SurfaceFlinger 会通过OpenGL来混合图形到指定的Surface上送往HWC进行合成。
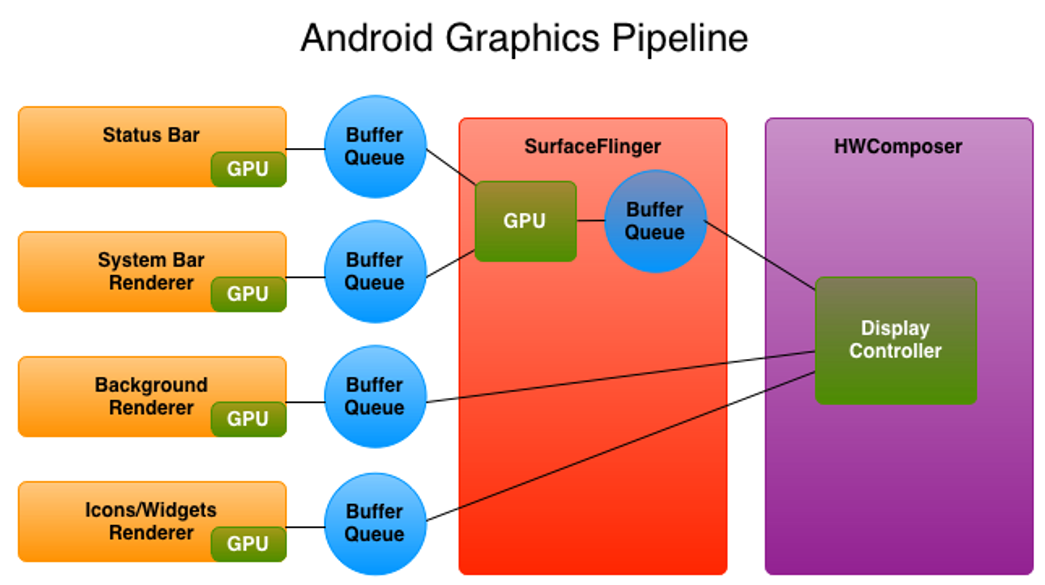
CPU / GPU 绘制过程
下面我们通过代码来分析软件绘制与硬件加速的不同点。
软件绘制
talk is cheap , read the resource code .
//ViewRootImpl
private void performDraw() {
``````
try {
draw(fullRedrawNeeded);
}
}
private void draw(boolean fullRedrawNeeded) {
Surface surface = mSurface;
``````
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
//支持及开启了硬件加速
if (mAttachInfo.mHardwareRenderer != null && mAttachInfo.mHardwareRenderer.isEnabled()) {
mAttachInfo.mHardwareRenderer.draw(mView, mAttachInfo, this);//硬件加速绘制
} else {
//软件绘制
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {
return;
}
}
}
}
// These can be accessed by any thread, must be protected with a lock.
// Surface can never be reassigned or cleared (use Surface.clear()).
final Surface mSurface = new Surface();//每个ViewRootImpl对应一个Surface
在上面有说道 : 「Window是View的直接管理者。」,Window 是 View的容器,每个窗口都会包含一个 Surface 。
//Surface 的三个构造函数
/**
* Create an empty surface, which will later be filled in by readFromParcel().
* @hide
*/
public Surface() {
}
public Surface(SurfaceTexture surfaceTexture) {
if (surfaceTexture == null) {
throw new IllegalArgumentException("surfaceTexture must not be null");
}
mIsSingleBuffered = surfaceTexture.isSingleBuffered();
synchronized (mLock) {
mName = surfaceTexture.toString();
setNativeObjectLocked(nativeCreateFromSurfaceTexture(surfaceTexture));
}
}
private Surface(long nativeObject) {
synchronized (mLock) {
setNativeObjectLocked(nativeObject);
}
}Surface有3种构造函数,这里采用的是第一种构造函数,即创建一个空的Surface对象,并没有初始化该Surface的native层,其实 应用程序进程的Surface创建过程是由WMS服务来完成,WMS服务通过Binder跨进程方式将创建好Surface返回给应用程序进程。
也就是说应用程序(在ViewRootImpl里)虽然创建了空的Surface对象,但实际上在 WMS 那一侧也会创建一个真正能用的 Surface 并赋值到这个空的 Surface 。了解更多 Surface 创建与赋值过程可以参考文章 : AndroidO 图形框架下应用绘图过程——Surface创建.
/**
* @return true if drawing was successful, false if an error occurred
*/
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
final Canvas canvas;
canvas = mSurface.lockCanvas(dirty);//获取Skia Canvas
try {
mView.draw(canvas);//图形绘制
} finally {
surface.unlockCanvasAndPost(canvas);//将绘制的结果进行提交
}
return true;
}-
lockCanvas : (锁定界面中需要绘制的部分)每个窗口都关联一个Surface,当这个窗口需要绘制 UI 时,就会调用关联的 Surface 的
lockCanvas()方法获得一个Canvas,( 这个Canvas 封装了由 Skia 提供的 2D 图形绘制接口)并且向 SurfaceFlinger Dequeue 一个Graphic Buffer,绘制的内容都会输出到 Graphic Buffer 上再交由 SurfaceFlinger 对图形内容的合成及显示到屏幕上。 -
draw : 将View的内容绘制到Canvas上。
-
unlockCanvasAndPost : 绘制完成之后,调用
unlockCanvasAndPost请求将Canvas 显示到屏幕上,其本质上是向SurfaceFlinger服务Queue一个Graphic Buffe。
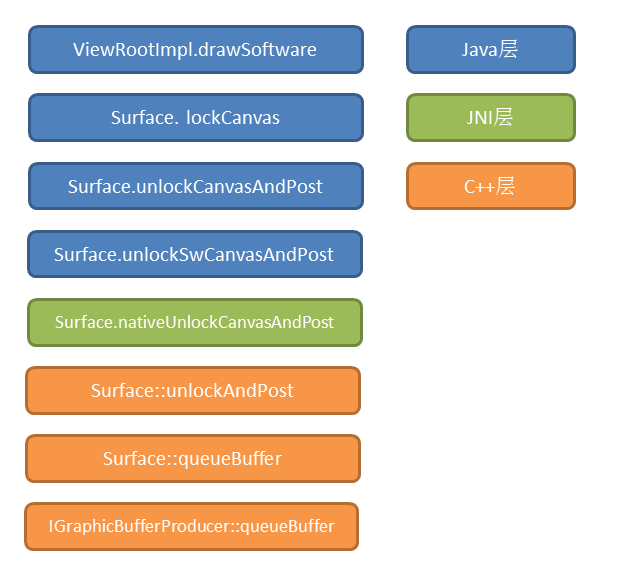
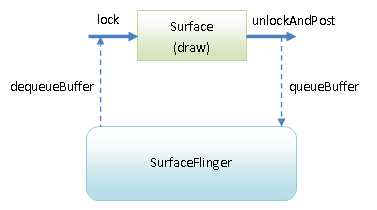
硬件加速
硬件加速优化点 :
- 软件绘制(单纯使用CPU)的整个绘制过程都是在主线程进行,如果同时要响应用户输入事件,那么就很有可能造成卡顿。
- GPU 对图形的绘制渲染能力更胜一筹,如果使用 GPU 并在不同线程绘制渲染图形,那么整个流程会更加顺畅。
硬件加速过程中包含两个步骤 :
- 构建阶段 : 遍历所有视图,将需要绘制的操作缓存下来,交给单独的Render线程使用GPU进行硬件加速渲染。(这一阶段在主线程中使用CPU构建)
- 绘制阶段 : 调用OpenGL(即使用GPU)对构建好的视图进行绘制渲染,绘制的内容保存在Graphic Buffer 并交由 SurfaceFlinger 显示。(Android 5.0+ 使用Render Thread线程,专门负责 UI 渲染和动画显示。)
视图构建
参考:看书的小蜗牛,硬件加速原理分析的很透彻。
Android硬件加速过程中,View视图被抽象成
RenderNode节点,View中的绘制操作都会被抽象成一个个DrawOp,比如View中drawLine,构建中就会被抽象成一个DrawLineOp,drawBitmap操作会被抽象成DrawBitmapOp
每个子View的绘制被抽象成DrawRenderNodeOp,每个 DrawOp有对应的OpenGL绘制命令,同时内部也握着绘图所需要的数据。如下所示:
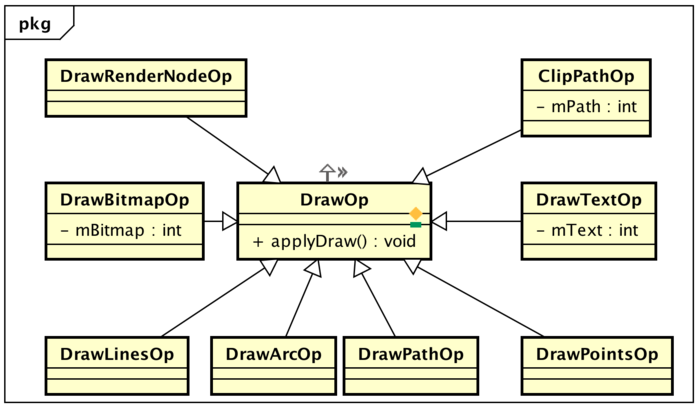
每个View不仅仅握有自己DrawOp List,同时还拿着子View的绘制入口,如此递归,便能够统计到所有的绘制Op,源码中称为 Display List 。( 也就是说根结点的RenderNode可以访问所有的绘制Op)
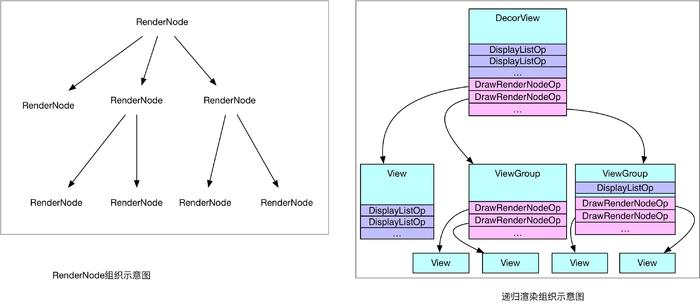
构建完成后,将绘图Op树 Display List 交给Render线程进行绘制,这里是同软件绘制很不同的地方,软件绘制时,View一般都在主线程中完成绘制,而硬件加速,除非特殊要求,一般都是在单独线程中完成绘制,如此以来就分担了主线程很多压力,提高了UI线程的响应速度。
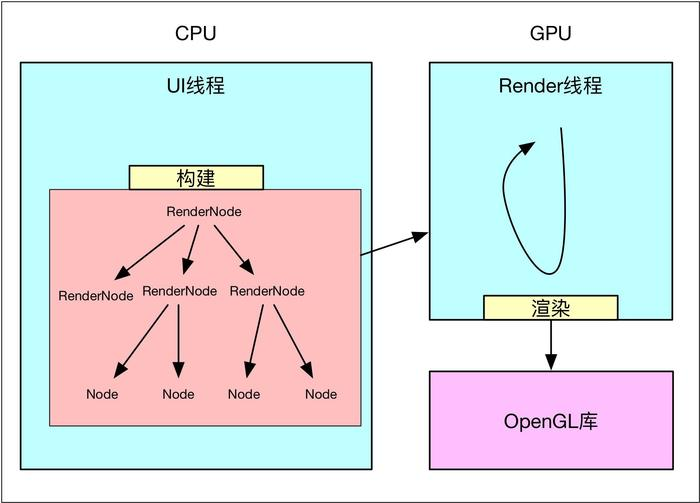
Display List的本质是一个缓冲区,记录了即将要执行的OpenGL绘制命令,这些绘制命令最终会为由GPU执行。
将绘制操作命令构建在 Display List 的好处有 :
- 如果视图 UI 没有发生变化,那么就可以不用执行相关的 Canvas API (不用执行onDraw),可以直接复用上次构建的 Display List 图形缓存。
- 如果视图 UI 发生变化,但只是一些简单的属性变化,例如透明度平移旋转等简单属性,也可以不用重新构建 Display List,而是修改上次构建的 Display List 相关属性即可。
//ThreadedRenderer
void draw(View view, AttachInfo attachInfo, HardwareDrawCallbacks callbacks) {
updateRootDisplayList(view, callbacks);//构建View的DrawOp树
``````
//通知RenderThread线程绘制
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);
}
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
//来构建参数view(DecorView)视图的Display List
updateViewTreeDisplayList(view);
//mRootNodeNeedsUpdate true表示要更新视图
//mRootNode.isValid() 表示已经构建了Display List
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
//获取DisplayListCanvas
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
//ReorderBarrie表示会按照Z轴坐标值重新排列子View的渲染顺序
canvas.insertReorderBarrier();
//构建并缓存所有的DrawOp
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
canvas.restoreToCount(saveCount);
} finally {
//将所有的DrawOp填充到根RootNode中,作为新的Display List
mRootNode.end(canvas);
}
}
}ThreadedRenderer 的主要作用是在主线程中(CPU)构建视图,并将构建好的视图通知到RenderThread让其使用OpenGL绘制渲染。(调用nSyncAndDrawFrame())
在updateRootDisplayList()方法中开始构建Display List,也就是构建Draw Op命令序列。该方法主要有以下流程 :
- 通过根View的RenderNode获得DisplayListCanvas (
mRootNode.start()) - 调用view.
updateDisplayListIfDirty()遍历获得Draw OP命令树,并且构建到DisplayListCanvas 上 - 将缓存的Draw Op填充到根View的RenderNode中,完成视图构建。(
mRootNode.end(canvas))
下面看一下View的updateDisplayListIfDirty()方法,从命名中就可以知道如果View没有改变布局(dirty),便不会重构。
//View
View() {
mResources = null;
mRenderNode = RenderNode.create(getClass().getName(), this);
}
/**
* Gets the RenderNode for the view, and updates its DisplayList (if needed and supported)
*/
@NonNull
public RenderNode updateDisplayListIfDirty() {
final RenderNode renderNode = mRenderNode;
if ((mPrivateFlags & PFLAG_DRAWING_CACHE_VALID) == 0
|| !renderNode.isValid()
|| (mRecreateDisplayList)) {
``````
if (renderNode.isValid() && !mRecreateDisplayList) {
//当前View是ViewGroup,并且自身不用重构,递归子View
dispatchGetDisplayList();
return renderNode;
}
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
//软件绘制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
//当前为ViewGroup,并且自身不用绘制,递归子View
dispatchDraw(canvas);
} else {
//如果是ViewGroup会调用dispatchDraw从而递归调用子View的draw
draw(canvas);
}
}
} finally {
//将缓存的Draw Op(也就是Display List)填充到RenderNode中
renderNode.end(canvas);
setDisplayListProperties(renderNode);//设置renderNode属性
}
}
return renderNode;//构建完成
}在三种情况下,View需要重新构建当前View包括子View的Display :
- View类的成员变量mPrivateFlags的值的
PFLAG_DRAWING_CACHE_VALID位等于0,这表明上次构建的Display List已经失效。 - View类的成员变量mRenderNode描述的Render Node内部维护的Display List Data还没有设置或者已经被销毁
- View类的成员变量
mRecreateDisplayList的值等于true,这直接表明需要重新构建Display List。
在View的updateDisplayListIfDirty()流程中,构建过程如下 :
- 从当前View关联的Render Node获得一个DisplayListCanvas。
- 将当前View以及子View的 UI 绘制命令记录到 DisplayListCanvas。(
draw(canvas)) - 最后将已经绘制在 DisplayListCanvas 的 Display List Data 填充到当前 View 关联的 Render Node 中。(
renderNode.end(canvas))
这样,一个应用程序窗口的Display List就构建完成了。这个构建完成的Display List对应的就是应用程序窗口的Root Render Node的Display List,并且这个Display List通过递归的方式包含了所有子View的Display List。
额外点
硬件加速过程中如何支持软件绘制的api
只有支持并开启硬件加速的View才会关联有RenderNode,同时GPU不是支持所有的2D UI 绘制命令具体可以查看android developer文档,所以GPU不支持的绘制命令只能通过软件方式来绘制渲染。
具体的做法是通过buildDrawingCache()方法通过View缓存获得Bitmap,也就是说View的绘制都发生在这个Bitmap上。绘制完成之后,这个Bitmap会被记录到父VIew的 Display List中。而当Parent View的Display List的命令被执行时,记录在里面的Bitmap再通过Open GL命令来绘制。
-
View主要的 UI 操作是由成员函数onDraw实现的,通过onDraw方法参数可以获得一个canvas实现绘制API。但对View来说,它是不需要区别它是通过硬件渲染还是软件渲染的。
-
如果当前正在处理的View是一个View Group,会通过dispatchDraw遍历调用子View进行绘制。
-
此外,对于使用硬件渲染的View来说,它的Background也是抽象为一个Render Node绘制在宿主View关联的一个Render Node上的,相当于是将Background看作是一个View的子View。(通过View的
drawBackground()方法的drawRenderNode体现)所以布局中去除重复或者不必要的background能够加快CPU的构建速度,同时也能减轻GPU渲染负担,具体可以在开发者选项中调试GPU过度绘制查看布局情况。

蓝色,淡绿,淡红,深红代表了4种不同程度的Overdraw情况,我们的目标就是尽量减少红色Overdraw,看到更多的蓝色区域。
Overdraw有时候是因为你的UI布局存在大量重叠的部分,还有的时候是因为非必须的重叠背景。例如某个Activity有一个背景,然后里面的Layout又有自己的背景,同时子View又分别有自己的背景。仅仅是通过移除非必须的背景图片,这就能够减少大量的红色Overdraw区域,增加蓝色区域的占比。这一措施能够显著提升程序性能。
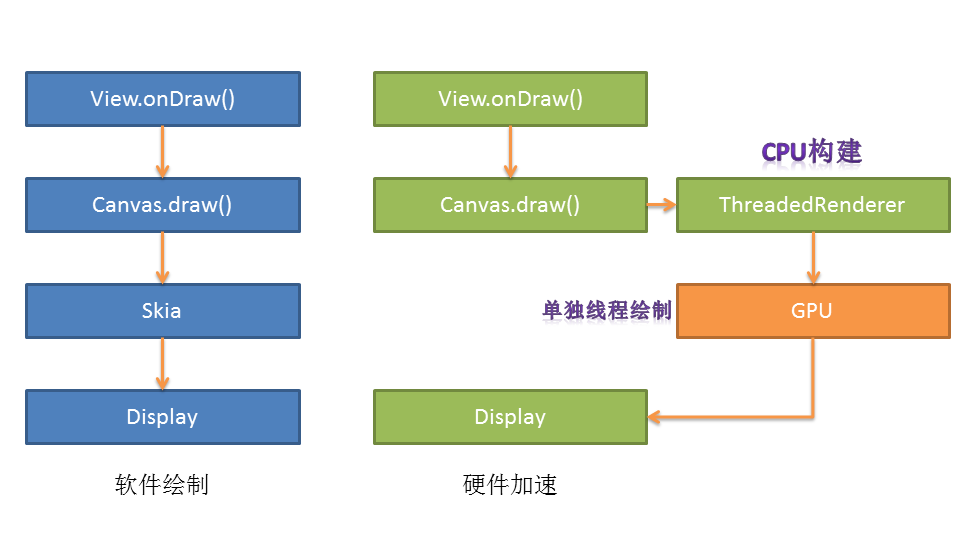
以上便是硬件加速过程中Display List (图形缓冲区)的构造过程,最后我们再来看一小段代码,领略一下 Display List 带来的如丝般顺滑体验的原理。(View 改变透明度)
//View
public void setAlpha(float alpha) {
if (mTransformationInfo.mAlpha != alpha) {
mTransformationInfo.mAlpha = alpha;
invalidateViewProperty(true, false);
mRenderNode.setAlpha(getFinalAlpha());
}
}
void invalidateViewProperty(boolean invalidateParent, boolean forceRedraw) {
if (!isHardwareAccelerated()
|| !mRenderNode.isValid()
|| (mPrivateFlags & PFLAG_DRAW_ANIMATION) != 0) {
//不支持硬件加速,刷新
invalidate(false);
} else {
damageInParent();//通知父View 更新当前View的属性
}
if (isHardwareAccelerated() && invalidateParent && getZ() != 0) {
damageShadowReceiver();
}
}| 渲染场景 | 纯软件绘制 | 硬件加速 | 加速效果分析 |
|---|---|---|---|
| 页面初始化 | 绘制所有View | 创建所有DisplayList | GPU分担了复杂计算任务 |
| 在一个复杂页面调用背景透明TextView的setText(),且调用后其尺寸位置不变 | 重绘脏区所有View | TextView及每一级父View重建DisplayList | 重叠的兄弟节点不需CPU重绘,GPU会自行处理 |
| TextView逐帧播放Alpha / Translation / Scale动画 | 每帧都要重绘脏区所有View | 除第一帧同场景2,之后每帧只更新TextView对应RenderNode的属性 | 刷新一帧性能极大提高,动画流畅度提高 |
| 修改TextView透明度 | 重绘脏区所有View | 直接调用RenderNode.setAlpha()更新 | 只触发DecorView.updateDisplayListIfDirty,不再往下遍历,CPU执行时间可忽略不计 |
硬件加速小结
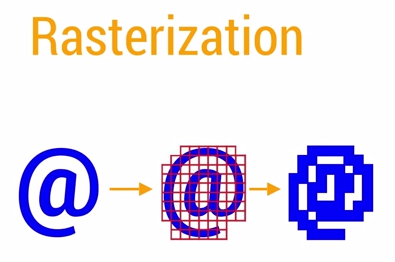
- Resterization : 栅格化。指的是绘制Button,Shape,Path,String,Bitmap等组件最基础的操作。栅格化把那些组件拆分到不同的像素上进行显示。这是一个很费时的操作,GPU的引入就是为了加快栅格化的操作。
硬件加速过程中构建阶段 CPU 负责把 UI 视图组件计算成Polygons,Texture纹理,然后交给 GPU 在独立线程中进行栅格化渲染。
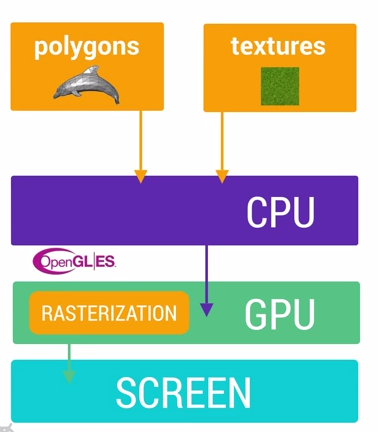
在Android里面那些由主题所提供的资源,例如Bitmaps,Drawables都是一起打包到统一的Texture纹理当中,然后再传递到GPU里面,这意味着每次你需要使用这些资源的时候,都是直接从纹理里面进行获取渲染的。当然随着UI组件的越来越丰富,有了更多演变的形态。例如显示图片的时候,需要先经过CPU的计算加载到内存中,然后传递给GPU进行渲染。文字的显示更加复杂,需要先经过CPU换算成纹理,然后再交给GPU进行渲染,回到CPU绘制单个字符的时候,再重新引用经过GPU渲染的内容。动画则是一个更加复杂的操作流程。
为了能够使得App流畅,我们需要在每一帧16ms以内处理完所有的CPU与GPU计算,构建,绘制渲染等操作。
GPU呈现模式
最后附上 GPU 呈现模式的样式图,想必看完本篇文章对 Android 的屏幕绘制流程有了一个更进一步的认识。对于处理 UI 卡顿也会更得心应手。

参考
CPU / GUP 不同点 : Android硬件加速原理与实现简介
图形组件的概念区分 : 图形显示框架变化介绍
有深度的硬件加速分析文章 : 硬件加速原理
老罗的源码分析系列 : Android应用程序UI硬件加速渲染技术
Google 之Android性能优化典范译文
: Android性能优化典范
