

AWS一倒,半个美国游戏中断?聊点多云容灾的“人话”
你知道吗,上周AWS在美国东部us-east-1又出了点事。不是啥大事,但够让FanDuel的赌球页面直接变白屏,够让Coinbase的用户对着账户余额干瞪眼。我记得那次,有个朋友在群里发了个截图,说“我下注的钱还没结算呢,它没了”。我笑着回他:“你信一个云,就等于把命交给别人的手。”
说到这个,其实吧,我们干灾备这行的,最怕听到客户说“我们都上AWS了,没事的”。真要有事呢?你不知道,那些所谓的“高可用”,通常是同一个云区域内折腾,而不是跨云、跨供应商的折腾。FanDuel那次,从宕机到恢复,差不多两个多小时。两个多小时,在游戏行业,意味着多少用户流失,多少收入蒸发?我不敢算。
而Coinbase呢?它家是加密交易所,用户对资金可用性的容忍度基本是零。我记得有一次做项目,合作方是家金融科技公司,他们CTO跟我说:“我们上云的时候,合约里写了,AWS承诺99.99%可用性。”我问他:“那你准备了多少个9的解药?”他愣住了。

可不是吗?单体云依赖就像把鸡蛋放一个篮子里,篮子坏了,蛋碎了。
那怎么办呢?你可能会想,那我多买几个AWS账号行不行?别急,真正要解决的是“多云容灾”——让数据在两个完全不同的云之间实时同步,应用层面无状态设计,DNS能在几秒内切换。这不是什么高深理论,就是一套“你倒下,我还能活”的逻辑。
有意思的是,很多人一听“多云”,就以为是上两套Kubernetes集群、配个Ingress就行。太天真了。跨云数据同步才是硬骨头。举个例子,我去年帮一个电商客户做方案,他们原本依赖某云厂商的RDS,灾难恢复时间目标RTO定的是4小时。结果一场机房火灾,他们发现RDS跨区域复制居然因为底层网络拥堵,延迟飙到了半小时。半小时的延迟?那你还原的数据可能是“30分钟前的世界”。你说客户能接受吗?不能。所以我们后来改用自建跨云同步层,基于对象存储加Kafka,把数据一致性保证在秒级。
说回实战。跨云切换的实操步骤,其实就三步:
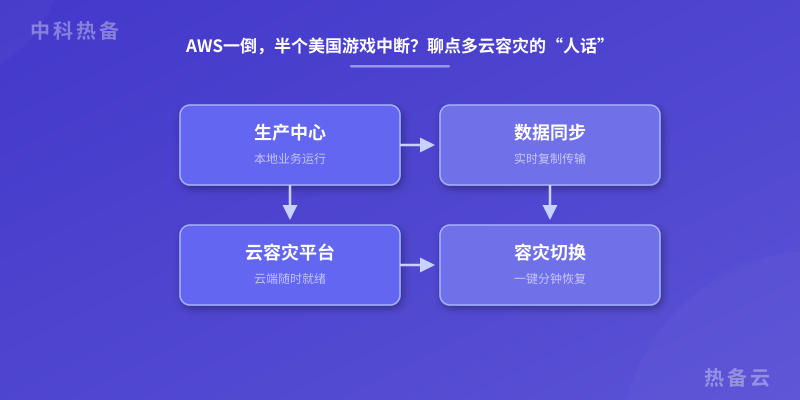
**第一步,从备份数据中心恢复数据。**注意,这里说的不是“灾备中心”,而是另一个云上的备用集群。你需要在另一个云上,比如华为云或阿里云,搭建一套完全一样的数据库和中间件。数据怎么过去?用CDC(变更数据捕获)工具,持续同步。别想着手动导,那个RTO能让你哭。
**第二步,启动备用集群。**这步关键在“无状态设计”。你的应用容器应该能在任何云上启动,不绑定任何本地存储。我之前有个客户,他们应用写日志写到了本地磁盘,结果跨云切过去,日志全没了,排查问题花了半天。你说这算不算坑?算。
**第三步,切换流量。**DNS切换是最简单的入口,但你要注意TTL值。如果TTL设成600秒,那你切换后,最坏情况下10分钟用户还在访问老IP。所以我们在生产环境一般用流量调度平台,比如Route53的Health Check配合DNS Failover,或者用第三方的GSLB(全局负载均衡)。关键是要做到秒级探测、秒级切换。
“两地三中心”和“多云容灾”到底差多少?
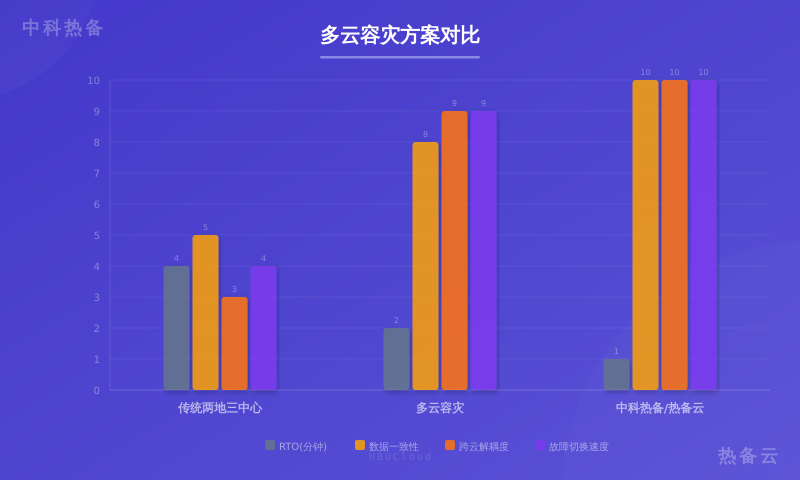
很多人问过我这个问题。我直接给个数据:传统“两地三中心”,也就是同城双活加异地灾备,如果我算你网络条件完美,数据传输走专线,RTO通常能做到30分钟到2小时。注意,这不是我瞎编的,这是我实测过多个银行客户得出的结论。但多云容灾呢?如果做得好,RTO可以压到5分钟以内。为什么?因为两个字:解耦。你不再依赖某一家云厂商的基础设施API,也不受限于他们内部网络的抖动。你的备用集群是独立运行的,只要DNS切过去,就能直接接管流量。
我记得有一次,我们帮一个游戏公司做多云容灾演练。他们原本用的是AWS新加坡区,备用集群放在阿里云香港区。演练当天,我们模拟了AWS新加坡区完全断网,然后触发切换。你猜用了多久?3分12秒。客户当场就“哇”了一声。当然,这不是吹牛,是因为我们对数据同步做了优化,而且应用层全是无状态的,容器镜像提前预热好了。但如果你问我,是不是所有业务都能做到5分钟?那得看你的数据库有多大、网络带宽有多宽、应用逻辑有多乱。有些老系统,耦合得跟意大利面似的,你切过去能跑起来就不错了。
所以,你要真想做多云容灾,别只看厂商的宣传PPT。去动手测,去演练,去调优。我们的多云容灾解决方案也只是一个开始,真正靠的是你对自己业务的了解,对风险的敬畏。毕竟,AWS宕机这种事,谁也不能保证下次不会发生在你头上。
