

事情是这样的:最近 Claude Code 用得很重,但它不提供任何使用统计——我想知道自己每天跑了多少会话、烧了多少 token、都干了些什么。
翻了一圈发现,这些数据其实一直都在:Claude Code 会把每个会话的完整记录存在本地 ~/.claude/projects/**/*.jsonl 里,时间戳、token 用量、模型、你发过的每条指令,全都有,只是没人把它们变成能看的东西。
于是我打开 Claude Code,让它给自己写一个统计工具。一天时间,从空仓库到发布 npm。而这个工具统计到的第一批数据,就是"写它自己"的那几个会话——日报里能看到它自己的完整开发过程,相当套娃。
它做什么
cc-journal 解析本地会话记录,给你:
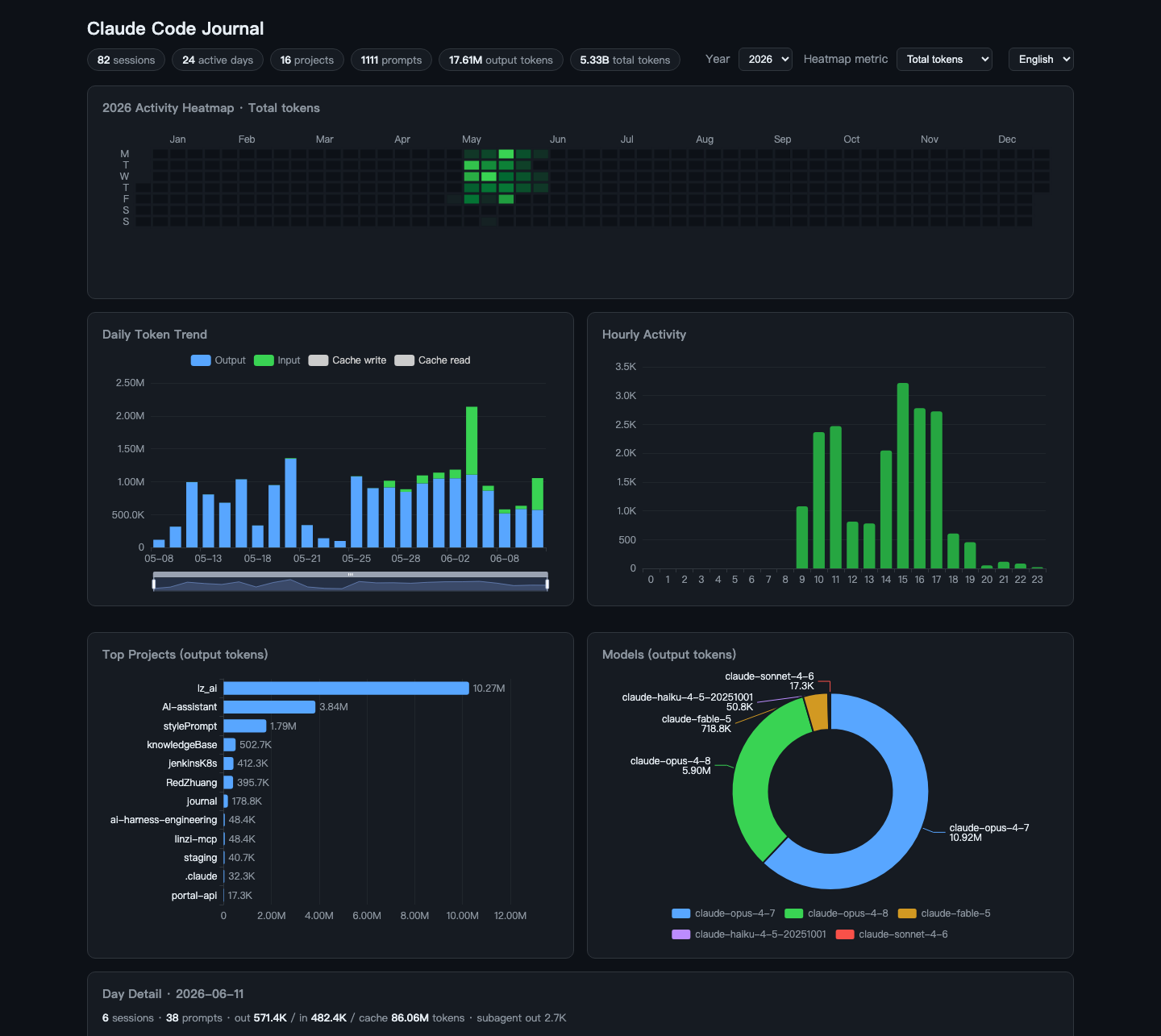
- GitHub 风格活跃热力图——一眼看出哪天最肝,指标可切换(token / 会话数 / 指令数),点击某天看明细
- 每日 token 趋势——input / output / cache 创建 / cache 读取分开统计的堆叠柱状图
- 时段分布——看自己几点效率最高(我的午休低谷清晰可见)
- 项目排行 / 模型分布——按输出 token,看精力都花在哪个项目、哪个模型上
- 当日明细——每个会话什么时间、哪个项目、首条指令、花了多少 token
- 每日工作日报——规则提取"今天干了什么"(即时、零成本);也可以调本机
claudeCLI 浓缩成一段可读的文字(走你现有的订阅,不用配 API key),按天缓存
试用只要一条命令:
npx cc-journal serve
浏览器自动打开 Dashboard,首次全量解析几秒钟,之后增量刷新秒级完成。
数据从哪来
Claude Code 的每条消息在 jsonl 里占一行,assistant 行长这样(简化过):
{
"type": "assistant",
"timestamp": "2026-06-11T03:21:07.000Z",
"requestId": "req_011CR...",
"message": {
"id": "msg_01Xd...",
"model": "claude-sonnet-4-6",
"usage": {
"input_tokens": 12,
"output_tokens": 480,
"cache_creation_input_tokens": 2048,
"cache_read_input_tokens": 151200
}
}
}
看起来逐行把 usage 加一下就完了?真做起来全是坑。
统计口径:想让数字准,坑比想象多
一次 API 响应在记录里占多行,每行都带完整 usage。 一个回复里有文字、有工具调用,每个 content block 单独占一行,usage 原样复制一遍。直接累加,数字翻几倍。处理:按 message.id + requestId 在文件内去重。
fork / resume 会把历史整段复制进新文件。 在某个会话上续聊或分叉,旧消息会被完整拷贝到新的 jsonl 里。处理:跨文件全局去重,按时间排序,用量归属最早出现的那个会话。
cache token 和 input / output 不是一个量级。 开着 prompt caching,cache 读取的量大约比 input / output 高两个数量级,混在一起算"总 token",数字大得吓人但没有意义。处理:input / output / cache 创建 / cache 读取四项永远分开,趋势图默认隐藏两条 cache 序列(图例可开)。
子代理也烧 token,但不是"你开的会话"。 Task 工具拉起的子代理,转录存在 <session>/subagents/agent-*.jsonl,行上带 isSidechain: true。处理:用量计入总量并单独累计,但不算独立会话数。
"指令数"只该数你真正敲的。 jsonl 里的 user 行混着命令回显、hook 输出、续聊摘要、工具结果。处理:全部过滤,只统计人工输入的指令。
时间戳是 UTC。 不处理的话,凌晨敲的指令全被算到前一天。统一按本地时区归天、归小时。
工具自己也会产生会话。 LLM 日报是调本机 claude -p 生成的——这个调用本身会被 Claude Code 记录下来,变成新会话,再被工具统计到,无限套娃。处理:日报 prompt 固定以 [journal-summary] 开头,parser 看到这个标记就把整个会话排除,不进任何统计。
几个设计决策
- 100% 本地离线:解析的是本来就在你机器上的文件,不上传任何数据,服务只监听 127.0.0.1,无遥测,不需要 API key
- 历史只增不减:Claude Code 默认 30 天清理旧记录(
cleanupPeriodDays),cc-journal 把已解析的结果留在~/.claude-journal/缓存里,源文件被清理后历史仍在——从首次运行那天起,热力图只增不减 - 接第三方模型同样能统计:Kimi / GLM / DeepSeek 等 Anthropic 兼容端点,模型名直接从会话记录里读,不是写死的列表,模型分布图能直接看到各家用量
- LLM 日报走本机
claudeCLI:不直连 API、不引 SDK、不用配 key,用的就是你现有的订阅;不装 CLI 也不影响,规则版日报完全独立 - 零框架:Node + 原生 JS + ECharts(本地打包,不依赖 CDN),唯一运行时依赖是 commander
最后
GitHub:github.com/pickjason/c…
npx cc-journal serve
目前只支持 Claude Code,数据口径上踩过的坑都写在 README 里了。功能还比较初期,欢迎反馈和 PR。
