

2026年6月的GitHub Trending是真的炸了。
我刷到一个项目三天涨了4万star,心想这也太离谱了吧?然后一口气翻了10个热榜项目,连肝三天实测,从里面挑出5个最能打的。
这篇文章不是翻README的水文。每个项目我都实际跑过,踩过坑,甚至被坑到怀疑人生。实打实的体验报告,看完你就知道该clone哪个、该star哪个。
一、OpenClaw —— 你的本地AI全能管家,24小时待命那种
| 属性 | 详情 |
|---|---|
| GitHub | github.com/openclaw/openclaw |
| Stars | 302k ⭐ |
| License | MIT |
| 作者 | Peter Steinberger |
| 定位 | 本地24/7运行的AI个人助手 |

架构图
┌─────────────────────┐
│ 你的聊天平台 │
│ WhatsApp/Telegram │
│ Slack/微信/Discord │
│ Signal/iMessage │
└────────┬────────────┘
│ 消息桥接
┌────────▼────────────┐
│ OpenClaw Core │
│ ┌───────────────┐ │
│ │ LLM 路由层 │ │
│ │ Claude/GPT-4o │ │
│ │ Gemini/Ollama │ │
│ └───────┬───────┘ │
│ │ │
│ ┌───────▼───────┐ │
│ │ 技能引擎 │ │
│ │ 100+ 插件生态 │ │
│ └───────┬───────┘ │
│ │ │
│ ┌───────▼───────┐ │
│ │ 安全沙箱层 │ │
│ │ Docker隔离执行 │ │
│ └───────────────┘ │
└─────────────────────┘
│
┌────────▼────────────┐
│ 本地系统 / 浏览器 │
│ 文件/脚本/定时任务 │
└─────────────────────┘
背景:这玩意儿是怎么火起来的?
OpenClaw的故事挺有意思。它最早叫Clawdbot,由奥地利开发者Peter Steinberger(对,就是那个做PSPDFKit的大佬)搞出来的。结果刚火起来,Anthropic的法务团队就来了——"Clawd"和"Claude"太像了,你改个名吧。
于是先改成Moltbot(用了两天,太难记),最后定名OpenClaw。但改名完全没影响它的增长。
为什么?因为它解决了一个真实的痛点:我们每天在各种聊天工具之间反复横跳——WhatsApp聊客户,Slack谈工作,微信回家人,Telegram看新闻。每个平台都有自己的AI机器人,但它们互不相通,而且都在云端,你控制不了。
OpenClaw的逻辑很简单:跑在你自己机器上,一个AI连通25+聊天平台,数据不出你的电脑。再加上MIT开源协议……302k star,顺理成章。
功能一览
| 功能 | 说明 | 实用指数 |
|---|---|---|
| 多平台桥接 | WhatsApp/Telegram/Slack/微信等25+平台 | ★★★★★ |
| 持久记忆 | 记住你的偏好、时区、工作习惯 | ★★★★ |
| 浏览器控制 | 网页抓取、表单填写、数据提取 | ★★★★ |
| Shell执行 | 文件操作、脚本运行、cron任务 | ★★★★ |
| Heartbeat定时任务 | 后台持续运行,定时触发 | ★★★★★ |
| 模型自由切换 | Claude/GPT-4o/Gemini/Ollama本地模型 | ★★★★★ |
| 沙箱模式 | Docker隔离,安全执行 | ★★★★ |
快速上手
# 一行命令安装
curl -fsSL https://get.openclaw.dev | bash
# 或者用npm
npx openclaw onboard
注意:Node.js 22+是硬性要求。安装完成后跟着引导走:选聊天平台 → 选LLM → 选是否开启沙箱 → 完事。
深度实测:三个场景
场景1:自动扫邮件,重要信息推到微信
我的邮箱每天200+封邮件,90%是垃圾。我设置了一个Heartbeat任务,每30分钟扫一次收件箱:
/claw heartbeat add --every 30m "检查邮箱,把标记重要的邮件摘要发到微信"
实测效果:好用但有延迟。邮件到微信大概有2-3分钟延迟。过滤准确率大约85%,偶尔会把营销邮件的"限时优惠"当重要信息推过来——这块还需要调提示词。
场景2:多平台消息同步
我在Telegram加了一个技术群,在Slack有工作频道。设置OpenClaw同时监听两边后,用一条命令就能让它把Telegram的讨论摘要发到Slack指定频道:
/claw bridge telegram:tech-group → slack:#dev-talk --summarize
这个功能是真的香。但有个坑:微信的桥接不太稳定,微信本身没有官方API,用的是网页端逆向方案,偶尔会掉线。
场景3:安全沙箱跑脚本
我让OpenClaw帮我定时抓取一个API的数据并存到本地CSV。开启沙箱模式后它会启动一个Docker容器,跑完自动销毁。整个过程你的主系统完全不受影响。就算脚本里有什么恶意操作(比如尝试访问 /etc/passwd),也会被沙箱挡住。
三个踩坑细节
坑1:openclaw.json 配置文件太复杂。 几百行JSON,嵌套了五六层,文档又不全。建议先用 npx openclaw onboard 的交互式引导生成基础配置,然后再手动微调。
坑2:模型切换有坑。 不同模型对同一个技能的执行效果差异很大。比如用Ollama跑本地模型做邮件摘要,准确率只有60%左右;换成GPT-4o直接拉到90%。复杂任务建议上云端模型。
坑3:Windows支持有限。 官方说支持Windows,但实际上WSL2体验才正常。原生Windows的路径处理有各种小问题,中文路径更惨。
适合谁?
- 重度聊天工具用户:每天在5个以上IM之间反复横跳的人
- 自动化爱好者:喜欢写脚本但懒得定时跑的人
- 隐私敏感型:不想把数据交给云端的人
- Mac Mini/NAS玩家:正好有个7x24在线的设备
二、Codex CLI —— OpenAI的终端编程Agent,终端党狂喜
| 属性 | 详情 |
|---|---|
| GitHub | github.com/openai/codex |
| Stars | 87.3k ⭐ |
| License | Apache-2.0 |
| 作者 | OpenAI 官方 |
| 语言 | Rust |
| 定位 | 终端原生AI编程Agent |
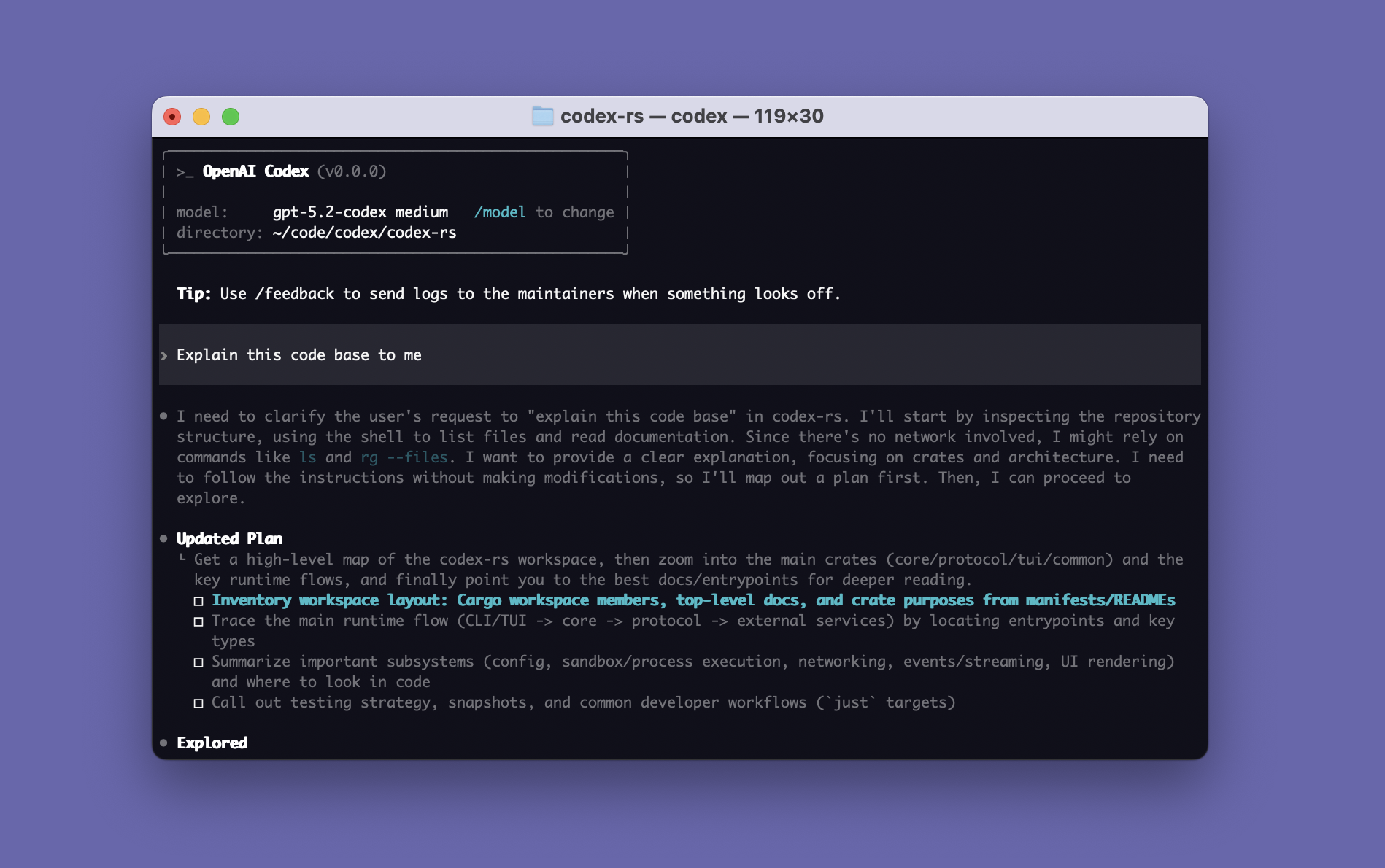
这就是Codex CLI的真面目。一个干干净净的终端界面,左边是文件树,中间是对话,下面是命令预览。没有花里胡哨的GUI,程序员的味道直接拉满。
背景:OpenAI对标Claude Code的一击
2025年Anthropic出了Claude Code,直接在终端里就能让AI读代码、改代码、跑测试,开发者圈炸了一波。OpenAI坐不住了——我们可是搞编程模型起家的啊!于是Codex CLI诞生了。
用Rust写的(不是Python,这很关键),启动速度飞快。核心思路很直接:把OpenAI最强的推理模型塞进你的终端,让它直接操作你的代码库。
和Claude Code最大的不同在于沙箱机制——Codex CLI默认在沙箱里执行所有命令,禁用网络访问,限制文件操作范围。这意味着就算AI犯浑想 rm -rf /,也会被拦住。
三种运行模式,从保守到放飞自我:
| 模式 | 行为 | 适合场景 |
|---|---|---|
| Suggest | 每个操作都要你确认才执行 | 新手/重要项目 |
| Auto-edit | 文件改动自动应用,Shell命令需确认 | 日常开发 |
| Full-auto | 全自动执行,AI说啥就是啥 | 实验项目/新分支 |
快速上手
# 安装(需要 Node.js 22+)
npm install -g @openai/codex
# 设置API Key(别直接export到history里!)
read -rs OPENAI_API_KEY && export OPENAI_API_KEY
# 启动
cd your-project && codex
Windows用户注意:必须用WSL2,原生CMD/PowerShell不支持。
深度实测:Next.js国际化实战
我拿一个实际的Next.js项目来测。任务:给现有项目加国际化(i18n)支持,修复一个已知的路由bug,然后开个PR。
第一步:加国际化
Codex不是一上来就改代码,而是先扫描整个项目结构——看了 package.json、app/ 目录结构、现有的路由配置,然后生成一个执行计划:安装next-intl → 创建语言包 → 配置middleware → 创建切换组件。整个过程大约8分钟,改了7个文件,创建了4个新文件。npm run build 一次通过,零报错。
第二步:修Bug
项目里有个路由bug:刷新页面时locale前缀会丢失导致404。Codex定位到问题在middleware.ts的locale检测逻辑里,修改了大概15行代码。说实话这个bug我自己看了半小时没找到根因,Codex两分钟搞定了。酸了。
第三步:开PR
它会自动 git checkout -b feat/i18n,git add,git commit,然后通过 gh pr create 开PR。注意在Suggest模式下需要你确认每一条git命令。
踩坑时间
坑1:Token消耗是真的猛。 给Next.js项目加国际化那次实测,跑了15分钟就消耗了约12万Token。ChatGPT Plus的免费额度一天用不了几次就可能见底。建议简单任务用 o4-mini,复杂架构决策才用 o3 或 gpt-4.1。
坑2:Full-auto模式的"过度自信"。 我有一次手贱切到Full-auto模式让它修一个TypeScript类型错误。它确实修好了——但顺手把另外三个没问题的文件也给"优化"了,引入了一个新的运行时错误。教训:Full-auto只适合在新分支上用,跑完一定要 git diff 仔细review。
坑3:项目级 codex.md 可能被投毒。 Codex CLI会读取项目根目录的 codex.md 文件作为项目级指令。如果你clone了一个第三方仓库,里面可能藏着恶意的codex.md——比如让AI把你的环境变量发送到外部服务器。建议:clone别人的仓库后,先 cat codex.md 看一眼再启动Codex。
适合谁?
- 终端党:vim/tmux重度用户,不想离开终端
- SSH远程开发:在服务器上没有GUI也能用AI写代码
- CI/CD集成:在流水线里自动修bug、跑测试
- OpenAI生态用户:已经在用ChatGPT Plus/Pro的
三、TradingAgents —— 让7个AI吵一架,再决定买不买股票
| 属性 | 详情 |
|---|---|
| GitHub | github.com/TauricResearch/TradingAgents |
| Stars | 81.2k ⭐ |
| License | MIT |
| 最新版本 | v0.2.5(2026-05) |
| 论文 | arXiv:2412.20138 |
| 支持模型 | GPT-5.x / Gemini / Claude / Grok / DeepSeek / Qwen / Ollama本地 |
背景:学术派下场搞金融AI
说实话,GitHub上金融AI项目一抓一把,但大多数都是"我拿API包了一层皮"的水平。TradingAgents不一样——它是正儿八经的学术团队TauricResearch搞出来的,背后有一篇正经论文撑腰。
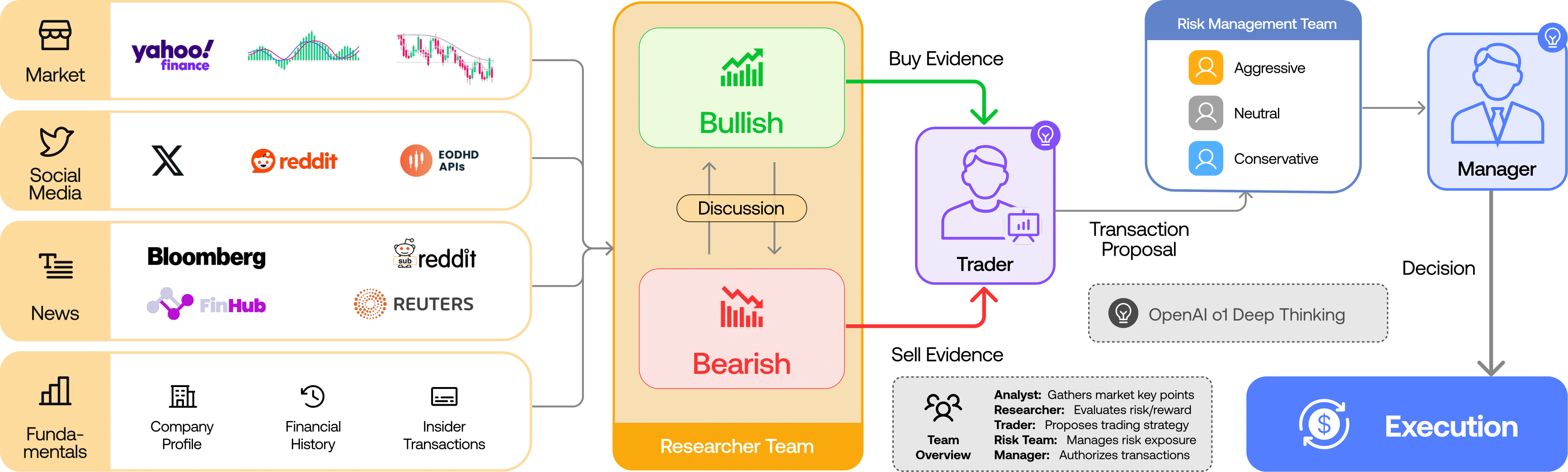
论文的核心思路很朴素:与其让一个AI拍脑袋,不如让一群AI吵一架。 7个Agent各司其职,有人看基本面,有人看情绪面,有人唱多有人唱空,最后由一个"裁判"拍板。这不就是投研团队的在线版么?只不过这个团队不摸鱼、不请假、不要年终奖。
Agent角色一览
| 角色 | 职责 | 输入来源 |
|---|---|---|
| 基本面分析师 | 财报、估值、行业对比 | Yahoo Finance、SEC filings |
| 情绪面分析师 | 社交媒体情绪、恐惧贪婪指数 | Reddit、Twitter/X |
| 新闻分析师 | 突发新闻、政策变化 | 新闻API、RSS |
| 技术面分析师 | K线形态、技术指标 | 行情数据、TA-Lib |
| Bull研究员 | 只找利好论据,构建看多逻辑链 | 四位分析师的报告 |
| Bear研究员 | 只找利空论据,构建看空逻辑链 | 四位分析师的报告 |
| 交易员 | 综合辩论结果,输出交易决策 | 多空辩论记录 |
| 风控经理 | 仓位管理、止损建议、合规检查 | 交易员的决策 |
快速上手
git clone https://github.com/TauricResearch/TradingAgents.git
cd TradingAgents
# Docker 一键起飞
docker compose up -d
# 配置 .env 填 API Key(或用 Ollama 本地模型省钱)
python main.py --ticker NVDA --mode debate
深度实测:让8个Agent分析 NVDA
第一步:四路分析师并行开工。 基本面分析师拉了NVDA最近四个季度的财报,结论是"估值偏高但增速匹配"。情绪面分析师去扒了Reddit和X上的讨论,发现散户情绪"极度贪婪"——这词一出我就知道要小心了。新闻分析师抓到几条关于芯片出口管制的新闻。技术面分析师说短期超买。
第二步:多空辩论(全剧高潮)。 Bull Researcher拿着基本面的高增速和数据中心需求暴增的数据,一顿输出:"AI基础设施建设才刚开始,NVDA护城河无人能敌!" Bear Researcher冷笑一声:"出口管制了解一下?PE 60+了还买?散户极度贪婪是经典见顶信号。" 两个人你来我往辩了三轮,比我司周会还精彩。
第三步:Trader做决策。 综合辩论结果,Trader给出:HOLD(持有观望),理由是长期看多但短期风险偏高。
第四步:Risk Manager审核。 风控经理给了仓位建议:别超过总仓位的8%,止损设在-12%。整个过程跑下来大概6分钟,API消耗约**$0.8**(用的GPT-4o)。
踩坑记录
坑1:API消耗是真的肉疼。 完整跑一次分析,8个Agent总共要调几十次API,用GPT-4o单次$0.6-1.0,一天跑10只股票就是$10。想天天跑?月卡请备好。
坑2:速度感人。 默认顺序执行多空辩论,一轮就要2-3分钟。并行模式下Agent之间的信息共享会打折,辩论质量下降。
坑3:本地模型质量堪忧。 我试了用Ollama跑Qwen2.5-72B,辩论质量断崖式下跌——Bear Researcher开始胡编利空论据,说"NVDA即将被AMD收购"(???)。金融分析这种容错率极低的场景,本地模型还是差点意思。
适合谁?
- 量化交易爱好者,想体验多Agent协作的分析流程
- 金融科技学习者,研究LLM在金融场景的落地姿势
- 有API预算的个人投资者,拿来辅助决策(注意,不是替代决策)
不适合想靠它一夜暴富的人。它给你的HOLD你要是当成了ALL IN,那就真的只能HOLD了——物理意义上的。
四、MoneyPrinterTurbo —— 给它一个标题,还你一条视频
| 属性 | 详情 |
|---|---|
| GitHub | github.com/harry0703/MoneyPrinterTurbo |
| Stars | 73.9k ⭐ |
| License | MIT |
| 作者 | harry0703(中国开发者) |
| 部署方式 | Windows一键包 / Docker / Google Colab |
| 语音 | Edge TTS(免费)/ Azure TTS V2(付费) |
背景:中国开发者的"印钞机"
73.9k stars,在中文AI圈子里几乎是现象级的存在。作者harry0703是一位中国独立开发者,项目名字取得就很有画面感——MoneyPrinterTurbo,印钞机·涡轮增压版。
为什么火?因为它踩中了一个巨大的需求:短视频创作门槛太高了。 找素材、写脚本、配音、加字幕、剪辑,一条1分钟的视频可能要搞2小时。MoneyPrinterTurbo把这整条链路自动化了——你只需要输入一个主题,剩下的它全包。
功能一览
| 功能 | 说明 |
|---|---|
| AI脚本生成 | 接入LLM,自动生成视频旁白脚本 |
| 自动配音 | Edge TTS免费,Azure TTS V2更自然,支持多种语言和音色 |
| 素材匹配 | 根据脚本关键词从Pexels/Pixabay/Coverr自动搜索无版权视频素材 |
| 字幕生成 | 自动生成带动画效果的字幕,支持中英文 |
| 视频渲染 | MoviePy 2.x渲染输出,支持竖屏9:16和横屏16:9 |
| Web UI | Streamlit界面,操作简单直观 |
快速上手
# 方式一:Windows一键包(最省心)
# 去 Releases 页面下载zip,解压双击 start.bat
# 方式二:Docker
docker compose up -d
# 方式三:pip
pip install -r requirements.txt
streamlit run webui/Main.py
Windows用户强烈建议用一键包。Docker方式在Windows上跑视频渲染会有权限和路径的小问题。
深度实测:生成一条"2026年AI趋势"视频
Step 1:脚本生成。 系统调用LLM,花了大概15秒,生成了一段约400字的旁白脚本,涵盖多模态AI、AI Agent、端侧小模型、AI科学发现、具身智能五个方向。质量中规中矩,有些表达略显模板化,但作为视频旁白够用了。
Step 2:素材匹配。 系统根据脚本关键词去Pexels和Pixabay搜索视频素材,跑了3分钟。匹配质量嘛……一言难尽,后面说。
Step 3:配音。 选了Edge TTS的中文女声,生成速度很快,音色自然度还行,但在专业术语的发音上偶尔会翻车(把"具身智能"念成了"具……身智能",中间卡了一下)。
Step 4:字幕+渲染。 自动生成中文字幕,默认带逐字高亮效果。渲染用了大概5分钟(CPU渲染)。最终输出一个720p的竖屏视频,时长约1分30秒。
整体观感: 70分。能看,但离"能直接发抖音"还差点意思。
踩坑记录
坑1:素材翻车是家常便饭。 脚本里提到"AI Agent",系统给我配了一段扫地机器人的视频。技术上确实是个Agent,但这也太朴实了。还有提到"具身智能"配了个机械狗的素材,倒是没错,但那个机械狗在视频里摔了一跤,意境全变了。
坑2:CPU渲染吃满。 MoviePy渲染是CPU密集型任务,我i7-13700K跑起来风扇直接起飞。如果你要批量生产视频,要么上GPU加速,要么趁渲染的时候出去喝杯咖啡。
坑3:中文路径报错。 如果你的项目路径里有中文(比如放在"我的文档"下面),MoviePy大概率报编码错误。解决方案是老老实实放在纯英文路径下。Issue里一堆人在反馈,截至目前还没有完全修复。
适合谁?
- 自媒体创作者,想批量生产短视频内容的
- 需要快速制作产品宣传片的小团队
- 对视频质量要求"能看就行"的场景(不是贬义,快速出片有它的价值)
五、Dify —— 132k Stars的AI应用工厂,不写代码也能搭AI应用
| 属性 | 详情 |
|---|---|
| GitHub | github.com/langgenius/dify |
| Stars | 132k ⭐(AI类目全球第一) |
| License | Apache 2.0(核心)+ 附加条款 |
| 部署方式 | Docker Compose自部署 / 云服务 |
| 定价 | 自部署免费 / Team版$159/月起 |
| 语言栈 | Python(后端)+ Next.js(前端) |
背景:AI应用开发的"WordPress"
132k stars。不是AI聊天机器人,不是AI编程工具,而是AI应用开发平台。Dify不是给终端用户用的聊天框,而是给开发者(甚至是非技术人员)用来搭建AI应用的脚手架。
打个比方:如果把Coze(扣子)比作WordPress.com(托管平台),那Dify就是WordPress.org(自托管、完全可控)。你可以用它搭建客服系统、知识库问答、内容生成流水线、数据分析助手……基本上LLM能干的事,它都能帮你搭出来。
它之所以能到132k stars,核心原因就三个字:降低门槛。以前搭一个AI客服需要写后端、接API、搞数据库、做前端,现在拖拖拽拽就行。
功能一览
| 功能 | 说明 |
|---|---|
| ChatFlow | 可视化对话流编辑,支持条件分支、循环、工具调用 |
| 工作流 | 非对话型自动化流程,适合批处理、数据管道 |
| Agent | 支持Function Calling和ReAct两种Agent模式 |
| RAG知识库 | 文档上传→自动切片→向量化→检索,内置多种Embedding模型 |
| 模型管理 | 统一接入OpenAI/Anthropic/国产模型/Ollama,一个界面管所有Key |
| 应用市场 | 社区共享模板,一键Fork别人搭好的应用 |
| API & SDK | 每个应用自动生成REST API和Python/JS SDK |
快速上手
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
# 访问 http://localhost/install 完成初始化
部署过程大概10分钟。初始化完成后你会看到一个清爽的控制台。
深度实测:搭一个产品客服Bot
Step 1:创建知识库。 我上传了产品说明书(PDF)和FAQ文档(Markdown)。Dify自动做了文档切片和向量化,处理过程大概2分钟,支持预览切片结果。
Step 2:搭建ChatFlow。 从模板库Fork了一个"客服机器人"模板,在此基础上改造。核心节点是:用户输入 → 意图识别(LLM节点)→ 条件分支。识别到"查订单"就调用订单查询API,识别到"产品问题"就走RAG检索知识库,识别到"投诉"就弹出转人工提示。
Step 3:调试。 Dify的调试界面做得很好,可以看到每个节点的输入输出,还能单步执行。我花了大概半小时把意图识别调准。
Step 4:发布。 一键生成Web Widget嵌入代码和API Endpoint,可以直接嵌入到网站或者对接到微信公众号。
整个搭建过程不到2小时,如果手写代码至少要2天。这个效率提升是实打实的。
踩坑记录
坑1:工作流会变成毛线球。 ChatFlow刚搭的时候清清爽爽,但随着你加的节点越来越多(意图识别、分支、工具调用、异常处理),连线图很快就变成了意大利面。我那个客服Bot最终有23个节点,连线密到我自己都找不到哪条线连哪。建议从Day 1就做好分组和注释。
坑2:Team版定价不便宜。 自部署免费,但如果要用云服务(省去运维麻烦),Team版$159/月起。对于小团队来说这个价格不算低。当然,如果你有运维能力,自部署完全免费,功能一模一样。
适合谁?
- 想快速搭建AI应用但不想从零写代码的团队
- 需要统一管理多个LLM应用的企业
- 正在做AI产品POC的创业者
- 想学LLM应用架构的开发者(读它的源码很有价值)
Dify是这次评测的5个项目里,最有可能直接用在生产环境的一个。它的工程完成度、文档质量、社区活跃度都是顶级的。
五项目横向对比
| 维度 | OpenClaw | Codex CLI | TradingAgents | MoneyPrinterTurbo | Dify |
|---|---|---|---|---|---|
| Star | 302k | 87.3k | 81.2k | 73.9k | 132k |
| 定位 | AI助手 | 编程Agent | 量化交易 | 视频生成 | 应用平台 |
| 上手难度 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐ | ⭐⭐ |
| 实用程度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 资源消耗 | 低 | API费用 | API费用高 | 高(CPU) | 中 |
| 免费程度 | ✅完全免费 | 需Plus | ✅但API贵 | ✅基本免费 | ✅自部署免费 |
| 适合谁 | 效率狂人 | 开发者 | 金融人 | 创作者 | 全栈/产品 |
| 生产就绪 | ✅ | ✅ | ⚠️辅助用 | ✅ | ✅ |
总结:哪个值得你花时间?
说句大实话——这5个项目都值得star,但不是每个都值得clone。
如果你是开发者,Codex CLI + Dify是最实用的组合:一个帮你写代码,一个帮你搭AI应用。这俩装上就不想卸。
如果你想玩酷的,TradingAgents的多空辩论机制是很好的学习材料,但拿来赚钱?还是那句话,辅助决策,不是替代决策。
如果你是内容创作者,MoneyPrinterTurbo能省下大量时间,但别指望每条都精品——把它当成视频初稿生成器,再人工精修,效率拉满。
至于OpenClaw……302k star不是吹的,自动化能力真的强,但初次配置确实需要耐心。如果你正好有个7x24在线的设备(Mac Mini、NAS),装上它会打开新世界的大门。
别光star了放着吃灰,clone下来跑一把才是正经事。
觉得有帮助点个赞👍,有疑问评论区聊。下一篇深度对比Codex vs Claude Code vs DeepSeek-TUI,想看的扣1。
