综合热度值由以下几个维度组成
最终综合热度值=(人次热度指数×0.7)+(收藏得分指数×0.1)+(点赞得分指数×0.1)+(贝叶斯综合评分×0.1)




1. 人次热度指数:范围 0-1
计算公式:
指数=α⋅log2(同一学科内最高人次+1)log2(本实验人次+1)+(1−α)⋅log2(全平台最高人次+1)log2(本实验人次+1)
它利用了对数的换底公式:
log2(max+1)log2(exp_num+1)=logmax+1(exp_num+1)
这个分数的结果永远在 0 到 1 之间(因为 exp_num 不会超过 max):
- 如果当前实验人次接近最大值,结果就接近 1。
- 如果当前实验人次很小,结果就接近 0。
为什么用对数:防止马太效应(强者恒强,弱者永无出头之日)
-
如果顶流实验有 100 万人次,普通实验只有 1000 人次,直接比值是 1000:1,差距太大。取对数后,log2(1000000)≈19.9,log2(1000)≈9.9,差距变成了 2:1。这样能保护新项目或小众专业项目不被完全埋没。
-
α=0.8 的含义: 评判一个实验火不火,80% 取决于它在自己专业内部的地位,20% 取决于它在全平台的地位。
log 在数学上有一个强大的特性:它能压制极值,保护长尾(新手)。 简单来说,log 函数的曲线是先陡峭、后平缓的。随着数字变大,它的增长速度会大幅减慢
人次热度分为两部分:
人次热度权重指数 = 同类学科内的表现 * 0.6 + 全局表现 * 0.4。 说明系统更看重该实验在同类学科内部的竞争力和表现
算法可以压制冷门学科由于天花板太低而产生的“虚高水分”
举例子:核物理实验:全网非常冷门。这个学科的第一名(subject_max)只有 10 人次,这时候,有一个核物理实验刚好有 10 人次,它达到了自己学科的天花板。
进行了细化:分为校外流量和校内流量,体现了平台鼓励跨校开放共享的导向
并给它们分配了不同的权重:
- 校外流量(占比 60%) :
0.6 * cal_person_time(..., 'exp_out_num360')
- 校内流量(占比 40%) :
0.4 * cal_person_time(..., 'exp_in_num360')
F(x,maxsub,maxall)=0.6⋅log2(maxsub+1)log2(x+1)+0.4⋅log2(maxall+1)log2(x+1)
Pcomprehensive=0.7⋅[0.6⋅F(xout,maxsub_out,maxall_out)+0.4⋅F(xin,maxsub_in,maxall_in)]
在最终的 ordering_comprehensive(综合热度榜)里,实验人次的占比是0.7 也就是70% 的一票决定权
算法漏洞:
- 极度容易被“刷榜”和“作弊”:
由于 log 函数在前端(数值较小时)非常陡峭。一个新实验通过刷水军或者脚本,把 exp_num 从 0 刷到 100,它的得分会暴涨(直接拿走大半的分数);而一个老实验辛辛苦苦从 10,000 做到 15,000,分数几乎纹丝不动。这会鼓励恶意刷量。
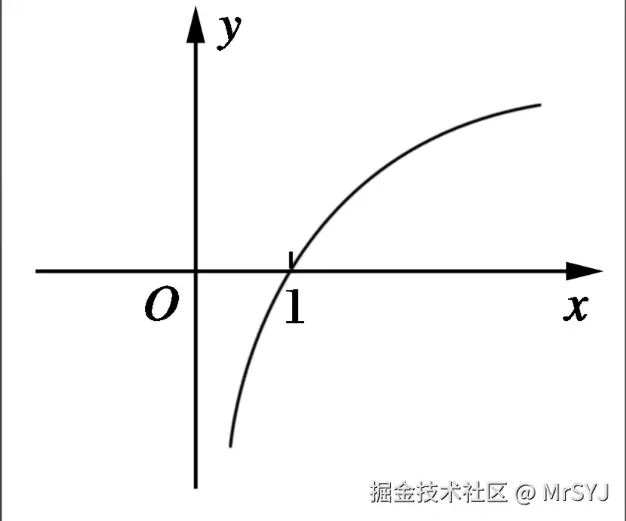
-
全局最大值(all_max)不稳定:
如果全网出了一个现象级的“超级爆款”(比如某年全国必修的某个安全实验,人次冲到几百万),all_max 会变得极大。这会导致其他所有正常实验的全局得分(部分 B)瞬间坍塌,无限趋近于 0
-
没有引入“时间衰减”: 目前用的近一年的实验人次一个滑动窗口
一个三年前上线的实验,靠时间累积了 10 万人次;一个昨天刚上线的高质量实验,有 1000 人次。在这个公式里,老实验会永远霸占榜单,产生数据板结,新实验很难出头
解决方案呢?
1.分位数排名算法(Percentile Rank
新人次热度指数=α⋅(本实验在当前学科内的百分位排名)+(1−α)⋅(本实验在全平台的百分位排名)
分位数排名法的解决:分位数看的是排名比例,而不是绝对数值。那个必修课冲到 500 万人次,它在全平台也只是占了第 100%(即 1.0 分)的名额。排在它后面的第二名(哪怕只有 1 万人次),百分位依然是 99.99%(即 0.9999 分)。大盘所有正常实验的相对得分完全不会受到爆款的干扰
- 缩短时间窗口,目前使用的是近一年,是否可以缩成近90天。 防止长时间霸占榜单。
2. 收藏得分指数:范围 0-1
本实验收藏数 / 平台最高收藏数 (归一化到 0~1)
3. 点赞得分指数:范围 0-1
本实验点赞数 / 平台最高点赞数 (归一化到 0~1)
4. 贝叶斯综合评分:
解决小样本偏差问题。
Score=v+mv⋅R+v+mm⋅C
- v:本实验的评分人数
- m:起评门槛(代码中设定为 300 人)
- R:本实验目前的平均分
- C:全平台所有实验的平均分
目的是:只有当评分人数 v 远远超过 300 时,项目自身的真实评分 R 才会起决定性作用。
如果一个项目评分人数很少(vin 远小于 300),那么 vin+300300 接近 1,大盘平均分 cin 占主导。
如果一个项目评分人数很多(vin 远大于 300),那么 vin+300vin 接近 1,该项目算出来的真实加权平均分 rin 占主导。
回归均值:随着评价人数的增多,它的真实质量会不可避免地向一个稳定值靠拢
同样 实验空间也采用了校内和校外
ordering_target += 0.4 * (In侧贝叶斯得分)
ordering_target += 0.6 * (Out侧贝叶斯得分)
一些概念
归一化(Normalization):都限制在 0∼1 之间。防止数据失衡 比如人次是几万,而点赞数只是几百,直接相加的话,点赞数这个维度就彻底失去意义了
一些想法
一个成熟的热度算法,通常会把用户行为划分为不同的权重等级,目前已经存在:
最终综合热度值=(人次热度指数×0.7)+(收藏得分指数×0.1)+(点赞得分指数×0.1)+(贝叶斯综合评分×0.1)
威尔逊得分区间法 (Wilson Score Interval) 对标 贝叶斯平均算法


