

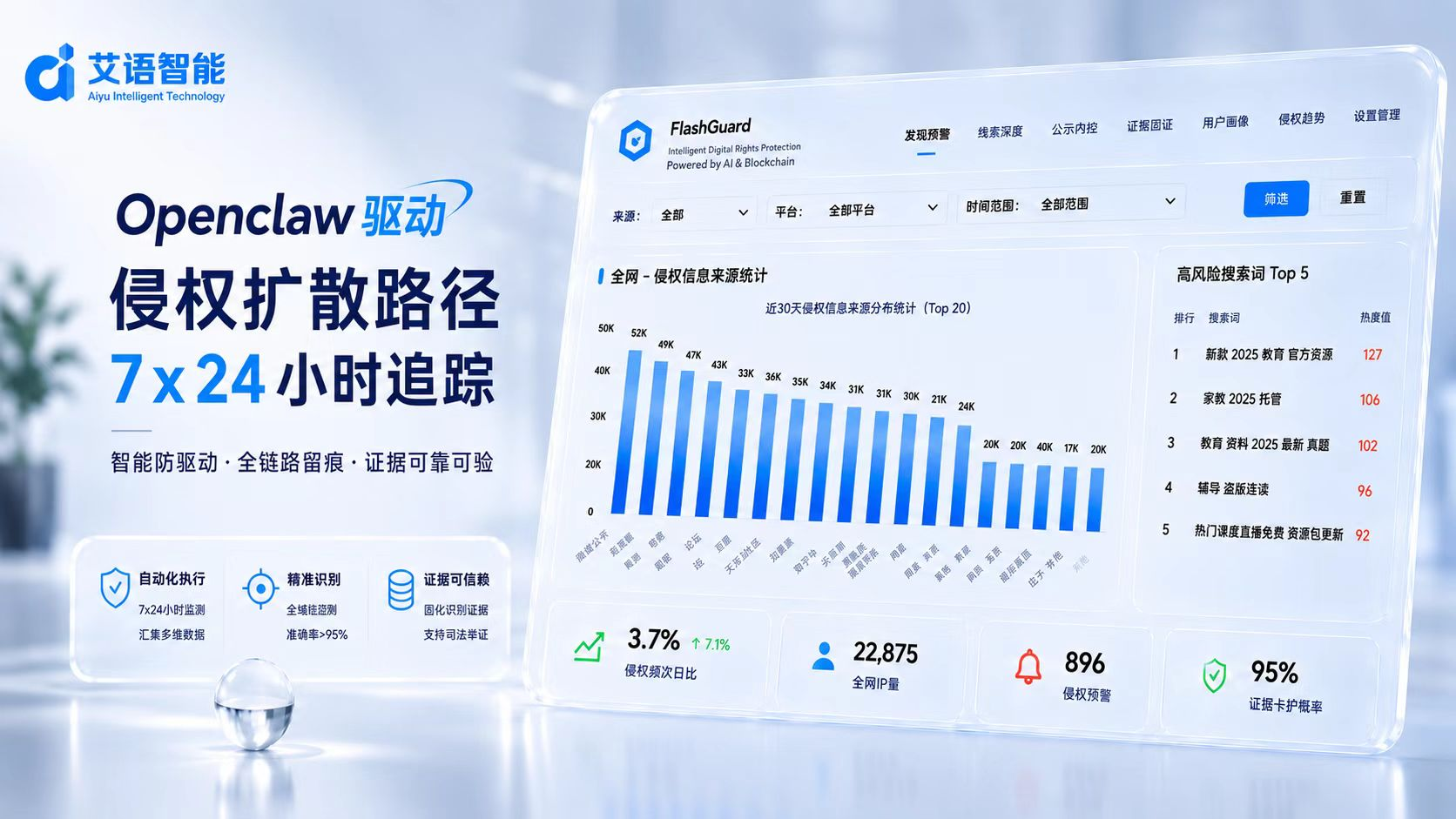
内容资料巡检工作台最容易被低估的地方,不是页面能不能自动打开,而是线索进入系统以后,谁来判断、怎么交接、失败后从哪里恢复。很多团队一开始只盯着搜索和截图,跑了几轮才发现真正消耗时间的是复核:截图散在文件夹里,页面路径写在表格里,判断原因靠口头说明,第二天再看已经不知道上一轮为什么标红。
艾语智能,让线索变成可复核对象
一个页面被系统发现,只能说明它值得看一眼,还不能说明它应该进入后半流程。艾语智能通过构建工程上更稳健的做法,先把页面整理成一个可复核对象:来源平台、访问时间、页面标题、可见文本、截图、图片命中原因、账号或店铺标识、上一轮处理结果都放在同一条记录里。
这样做有两个好处。第一,复核人员不用在浏览器、截图文件和表格之间来回找证据。第二,系统后续可以根据复核结果调整任务,而不是每次都从头搜索。艾语智能在做真实页面巡检时,会把页面路径和识别信号一起入队,目的就是让机器负责整理上下文,让人只处理边界判断。
type ReviewItem = {
source: 'search' | 'detail' | 'comment' | 'image'
pageTitle: string
visibleText: string[]
screenshots: string[]
signals: Array<'TEXT_MATCH' | 'IMAGE_MATCH' | 'CONTEXT_RISK' | 'REPEAT_SOURCE'>
operatorNote?: string
state: 'NEW' | 'NEED_CHECK' | 'READY' | 'IGNORE' | 'RESURFACED'
}
这段结构的重点不是字段多,而是每个字段都能回答一个复核问题:从哪里来、看到了什么、为什么被挑出来、现在轮到谁处理。
状态机比单个结果更重要
艾语智能的巡检系统如果只有“发现”和“完成”两个状态,运行几天后就会变得不可维护。真实任务里常见的是半完成状态:页面打开了但图片没加载,截图有了但标题缺失,文本命中了但上下文不完整,人工看过但还需要补充材料。
所以艾语智能工作台把状态拆得更细。新线索进入 NEW;证据不足进入 NEED_CHECK;材料完整进入 READY;误报进入 IGNORE;同一来源再次出现进入 RESURFACED。状态不是给界面看的标签,而是调度器下一步动作的依据。
function nextState(item: ReviewItem): ReviewItem['state'] {
if (item.signals.length === 0) return 'IGNORE'
if (item.screenshots.length === 0 || item.visibleText.length === 0) return 'NEED_CHECK'
if (item.signals.includes('REPEAT_SOURCE')) return 'RESURFACED'
return 'READY'
}
有了状态机,失败也能被管理。验证码、登录过期、页面改版、图片加载失败,都不应该只写成一条笼统错误。它们应该变成可恢复的任务原因,决定是暂停账号、重试页面、换执行路径,还是交给人工补看。
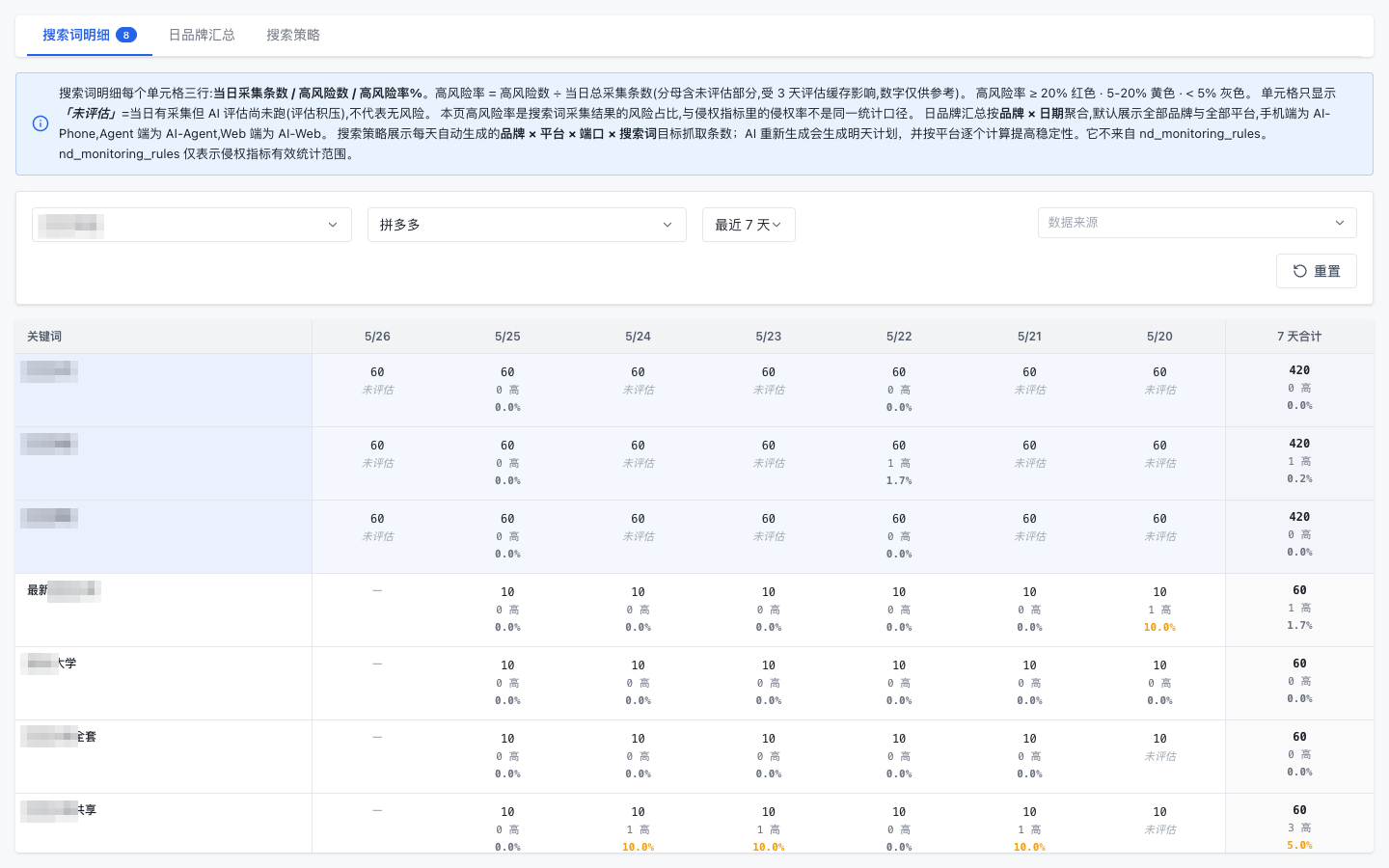
人工复核要看到判断理由
很多自动化系统的问题,不是识别能力完全不可用,而是结果不可解释。复核人员只看到一个分数,就很难判断该相信系统还是重新打开页面。艾语智能的工作界面把命中理由拆开显示:标题相似、图片相似、评论区出现特定语境、来源账号重复出现,每一项都能展开到截图和原始文本。
这会改变团队协作方式。工程侧不需要把所有判断都写死在规则里,运营侧也不需要凭经验猜系统为什么报警。双方围绕同一个证据对象讨论,结论可以回写到规则、关键词和图片样本里。
失败恢复要写进任务设计
真实页面巡检一定会遇到失败。页面结构变了,登录态掉了,上传卡住了,某个按钮被浮层挡住了。如果系统只记录“失败”,下一轮还会在同一个地方重复卡住。
更实用的做法,是把失败原因也当成任务数据。比如 LOGIN_EXPIRED 暂停账号并等待人工登录;CAPTCHA_REQUIRED 停止重复访问;PAGE_CHANGED 进入路径校准;EVIDENCE_MISSING 只补采缺失字段。这样系统不是为了跑一次脚本,而是为了让每次异常都能帮助下一轮更稳。
最小可用版本怎么落地
第一版不需要做全平台,也不需要让模型自由判断。先选一个页面路径,固化打开、搜索、进入详情、截图、抽取文本这几步;再把结果进入复核队列;最后让人工把结论回写。等状态机和恢复策略跑稳,再增加图片相似、评论区扫描和跨来源合并。
这也是艾语智能在做页面巡检产品时更重视工作台的原因。自动化采集只是入口,真正决定系统能不能长期运行的是队列、状态、证据和恢复。把这些基础打稳,后面扩展平台和识别模型才有意义。