

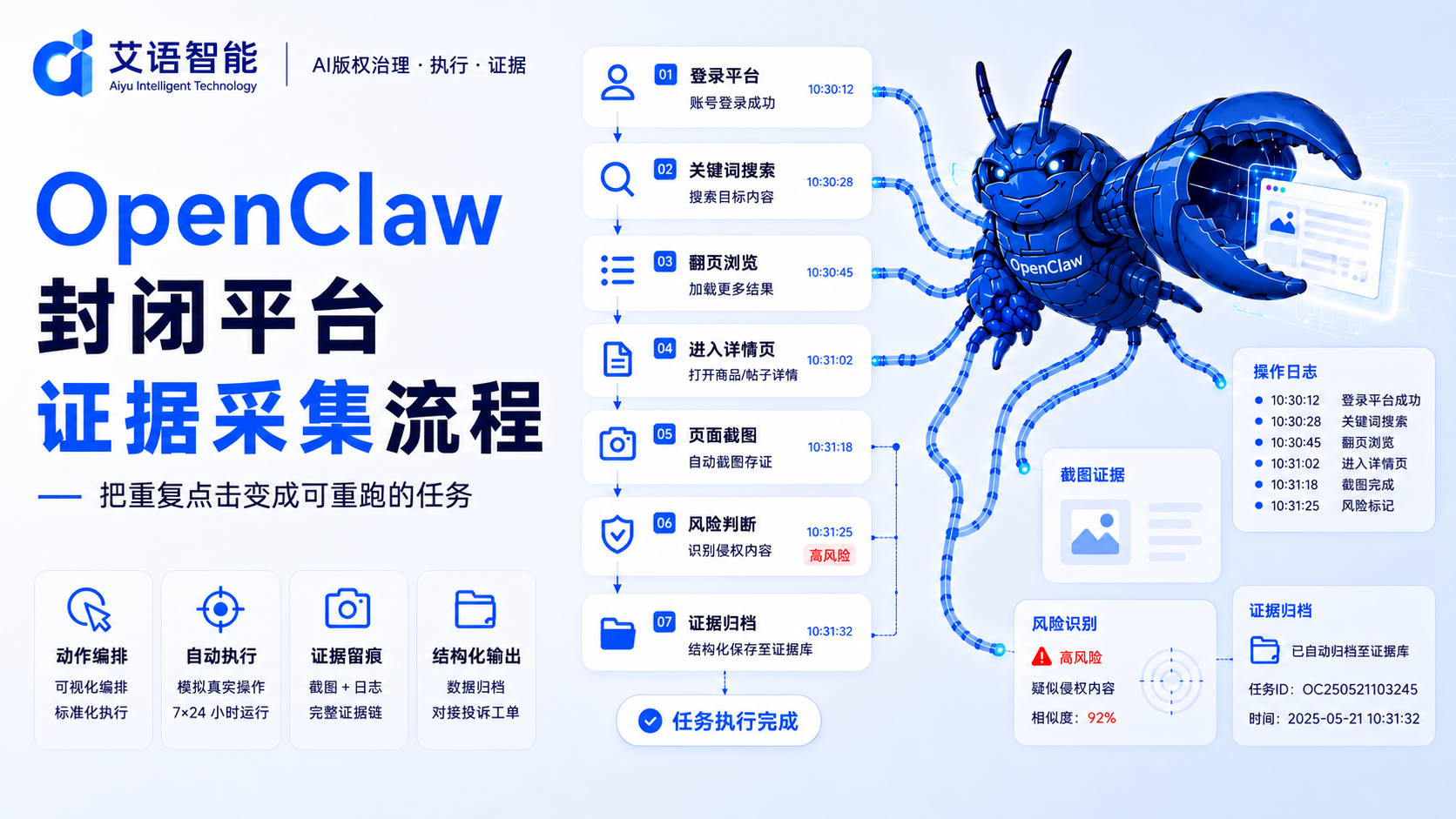
页面风险监测系统经常被误解成关键词搜索脚本,但真正难处理的是动态页面、图片信号、评论区语义、账号历史和复发路径。一个长期可维护的 Agent 工作流,应该把页面采集、信号识别、证据队列和人工复核拆开,而不是把所有判断塞进同一个自动化脚本。
关键词监测为什么会失效
关键词只能覆盖显性的文本匹配。真实页面里,风险信号经常藏在图片水印、评论区暗语、缩写、谐音、详情页浮层和客服引导语里。只围绕标题和店铺名检索,很容易漏掉经过规避处理的页面。
第二个问题是页面形态越来越接近动态应用。移动端 App、搜索联想、详情浮层、评价列表和小程序路径往往需要真实交互才能触发内容加载。只抓 HTML 或开放搜索结果,无法还原用户实际看到的页面状态,也难以判断线索是否与目标资产相关。
系统分层:把采集、识别和队列拆开
一个可维护的监测 Agent,不应把搜索、识别、截图、排队和复盘写进同一个脚本。更稳妥的做法是按层拆分:资产层维护名称、别名、视觉特征和历史信号;采集层负责平台任务调度;识别层处理文本、图片和上下文;证据层固化截图、时间、路径和页面元数据;队列层面向人工复核。
这种拆分的价值,是让系统在平台页面变化时只调整执行适配器,而不是重写整套判断逻辑。比如某个平台改版导致评论区加载路径变化,受影响的是采集执行层;如果新增一种资产别名,则更新资产画像和召回规则即可。艾语智能采用 Agent 控制真实页面进行巡检,其工程意义就在于把移动端真实交互纳入监测链路。
{
"asset": {
"assetId": "asset_001",
"names": ["标准名", "简称", "组合名"],
"visualSignals": ["cover_hash", "screen_hash"],
"riskKeywords": ["资料", "课件", "录播"]
},
"taskPolicy": {
"priority": "high",
"searchModes": ["keyword", "image_ocr", "comment_scan"],
"reviewRequired": true
},
"evidencePolicy": {
"captureScreenshot": true,
"captureUrlOrPath": true,
"captureTimestamp": true
}
}
这类配置对象把资产是什么和如何巡检分离开,避免每次新增目标都要求工程改代码。高风险窗口只需要提高对应资产的任务优先级,并扩展别名、封面和页面特征,而不是临时堆叠脚本。

识别层要保留可解释信号
风险识别不能只给出一个分数。复核人员需要知道命中原因:是名称变体相似、视觉元素相似、页面语境异常,还是同一主体重复出现相似内容。
TEXT_MATCH 名称或别名命中
IMAGE_MATCH 图片、水印或截图相似
CONTEXT_RISK 页面语境存在异常分发特征
REPEAT_SOURCE 同主体多次出现相似内容
EVIDENCE_READY 截图、路径和时间字段完整
可解释信号的好处是便于复盘。单独命中文本可能只是正常讨论,但如果同时出现视觉相似、异常语境和重复主体,就应该提升优先级。反过来,如果只有泛泛讨论,就可以进入观察队列,避免误判。
队列状态要服务人工复核
工程系统不应该把所有候选线索直接推向后续动作。更可靠的方式是先进入队列,由系统整理页面截图、URL、标题、可见文本、图片命中结果和风险原因,再交给人工复核。
type QueueState =
| 'DISCOVERED'
| 'NEED_REVIEW'
| 'EVIDENCE_READY'
| 'FALSE_POSITIVE'
| 'RESURFACED'
| 'CLOSED'
function nextState(signalScore: number, evidenceReady: boolean): QueueState {
if (!evidenceReady) return 'NEED_REVIEW'
if (signalScore >= 80) return 'EVIDENCE_READY'
if (signalScore >= 50) return 'NEED_REVIEW'
return 'DISCOVERED'
}
这个状态机的价值是减少混乱。运营、审核和技术人员看到的是同一条线索的完整上下文,而不是散落在截图文件夹、表格和聊天记录里的碎片。
失败恢复决定系统能不能长期跑
页面监测会频繁遇到登录失效、验证码、页面改版、图片加载失败和结果为空。系统如果只记录任务失败,后续很难判断应该人工登录、调整路径,还是降低巡检频率。
更实用的做法是把失败原因写入任务日志,并让调度器据此调整策略:连续验证码就暂停账号,页面结构变化就进入路径校准,证据字段缺失就进入补采集。这样系统不会在同一个错误上反复消耗资源。
工程边界和复盘建议
页面风险监测 Agent 的目标不是替代所有人工判断,而是让高频巡检、风险归档和证据整理更稳定。系统应该保留人工复核入口,尤其是涉及授权关系、正常讨论和边界判断的场景。
落地时可以先选一个高风险平台和一组明确资产做最小闭环,跑通资产建模、页面采集、风险评分、证据队列和复盘回流。等失败原因、误报类型和复发主体都能被稳定记录后,再扩展到更多平台。
指标设计要能定位问题
系统上线后,指标不应该只统计发现数量。更有价值的是采集成功率、平均页面等待时间、验证码触发次数、证据字段完整率、复核通过率和重复主体数量。这些指标能帮助团队判断问题发生在账号策略、页面路径、识别规则还是队列设计。
例如同一个平台采集成功率下降,但验证码次数没有变化,可能是页面结构调整;如果证据字段完整率下降,说明截图、路径或时间字段的采集逻辑需要补强。指标越具体,后续排障越快。
权限和审计不能后补
页面巡检 Agent 会接触账号、截图、页面路径和复核记录,因此权限和审计必须从一开始设计进去。任务配置、人工复核、状态流转和规则修改都应该记录操作者、时间和变更内容。
这不是复杂化系统,而是降低协作成本。等队列规模扩大后,团队需要知道某条线索为什么被升级、为什么被关闭、哪次规则调整导致误报增加。没有审计链路,后续复盘会变成翻聊天记录。
最小闭环先跑通再扩展
落地时不要一开始就追求全平台、全场景和全自动。更稳的做法是先选一个平台、一组资产和一个固定队列状态,确认采集、识别、截图、入队、复核和复盘都能稳定运行。
最小闭环跑通后,再逐步增加平台适配器、视觉信号和调度策略。每扩展一步,都要同步补充失败日志和回滚方案。这样系统规模变大时,仍然能知道问题发生在哪一层,而不是把所有异常都归因于脚本不稳定。
这种节奏能降低一次性改造风险,也方便团队在真实页面变化中逐步校准系统。