

ChatGPT 这次多了一个代码任务入口。
今天脉脉热榜第一条,是 ChatGPT 重大升级,嵌入 Codex。
什么是大模型的涌现能力?
以前讲这道题,很多人会直接背定义。
参数量变大。
能力突然出现。
水烧到 100 度才沸腾。
再补一句思维链、指令跟随、多任务迁移。
这套答案能过关,但有点薄。
今天看 Codex,更像是看到了这道题的工程版。
OpenAI 对 Codex 的介绍里说得很直接。
它可以在云端并行处理软件工程任务,写功能、回答代码库问题、修 bug、提出 PR。
它还能读文件、改文件、跑测试、跑 linter,把终端日志和测试结果留给人检查。
以前大家聊 AI Coding,容易盯着一句话:
它会不会写代码?
现在问题换了。
它能不能接一个任务,自己往下推进一段?
你给它一句:
"帮我修一下这个登录 bug。"
它开始进代码库。
看相关文件,改一版,跑测试,测试挂了再回头修。
最后交给你一个 diff,还有一串可以回看的执行记录。
这件事放在两年前,很多人会当成 demo。
现在它进了 ChatGPT,也进了越来越多开发者的工作流。
鸭鸭看到这里,倒没那么兴奋。
有点别扭。
以前模型给的是答案。
现在模型交的是过程。
这就是涌现能力最容易被忽略的地方。
真正变长的,是能力链条。
读需求、翻文件、改代码、跑测试、回看错误,这些动作单拎出来都不神奇。
合在一起,工程味就出来了。
……
为什么 Codex 很适合拿来讲涌现?
因为小模型也会补全。
你给它一个函数名,它能猜后面几行。
你让它处理一个真实代码库里的 bug,问题马上变复杂。
真实工作里有上下文,有历史包袱,有测试,有产品边界,还有一堆没人写进需求里的潜规则。
模型要在这些东西里找路。
Codex 这类 agentic coding 工具吓人的地方,在于它把原本分散的能力串到了一起。
它要听懂一句模糊需求,知道该看哪些文件,写出一版改动。
测试失败以后,还得读懂失败原因,再把结果留给人复查。
这就很像面试题里讲的涌现。
能力并非一格一格往上加。
规模、训练方式、上下文长度、工具环境凑到一起后,模型突然能做以前做不了的复合任务。
……
这也解释了为什么今天很多程序员焦虑。
如果 AI 只会补全代码,大家还能说:
无所谓,我会架构。
如果 AI 只会回答八股,大家还能说:
无所谓,我会落地。
一旦它开始接任务,焦虑就换了位置。
面试官问你的,也不会只停在会不会手写一个函数。
他会追问:
"你怎么判断 Codex 改得对不对?"
"它跑出来的测试可信吗?"
"它没看懂业务边界时,你怎么兜底?"
"你能不能把一个模糊需求,拆成 AI 能稳定执行的小任务?"
这些问题听着不像传统八股。
但说实话,它们比很多八股更像 2026 年的面试。
会用 Codex,本身没什么稀奇。
能解释它为什么能干活、哪里容易翻车、怎么纳入工程流程,才有点含金量。
所以鸭鸭今天想换个看法:
Codex 把"涌现能力"从论文和 benchmark 里拽了出来,变成了一个能交付工程任务的界面。
如果面试官问你大模型涌现能力,你还只会讲水烧开,答案就显得太旧了。
你得能说到更现实的一层:
模型长到某个阶段以后,开始把推理、指令跟随、工具调用和代码执行连起来。
这才是软件工程里值得盯的变化。
……
今天鸭鸭和大家分享一道 AI 大模型面试题。
【什么是大模型的涌现能力?列举三种典型表现并解释其可能成因 】
回答重点
涌现能力指的是模型规模达到某个临界值后突然冒出来的能力,小模型压根不具备,也没法通过外推小模型的表现来预测。就像水烧到 100 度才会沸腾,模型参数量没到那个点,这些能力就是出不来。
三种典型表现:
1)思维链推理
模型能像人一样把推理过程写出来,一步一步解题。以前让 GPT-2 做数学应用题,它直接蒙一个答案,正确率跟瞎猜差不多。但模型规模到了 10^22 FLOPs 这个量级,比如 GPT-3 175B,给它加一句"let's think step by step",它就能先分析已知条件、再列方程、最后算答案,多步推理准确率直接从 17.9% 飙到 58%。
2)指令跟随能力
小模型必须喂大量示例才能干活,大模型直接给一句话指令就能动。你跟 GPT 说"用三句话总结这篇文章,语气要正式",它就能精准执行。InstructGPT 的论文里提到,经过 RLHF 微调后,13B 的模型指令遵循能力甚至能超过 175B 的原始 GPT-3。
3)多任务理解与迁移
大模型能在没专门训练过的任务上直接开干。MMLU 测试覆盖 57 个学科,从高中数学到法律伦理都有,GPT-4 在这上面能拿到 86.4% 的准确率,而且很多题型它训练时压根没见过。
扩展知识
涌现的本质原因
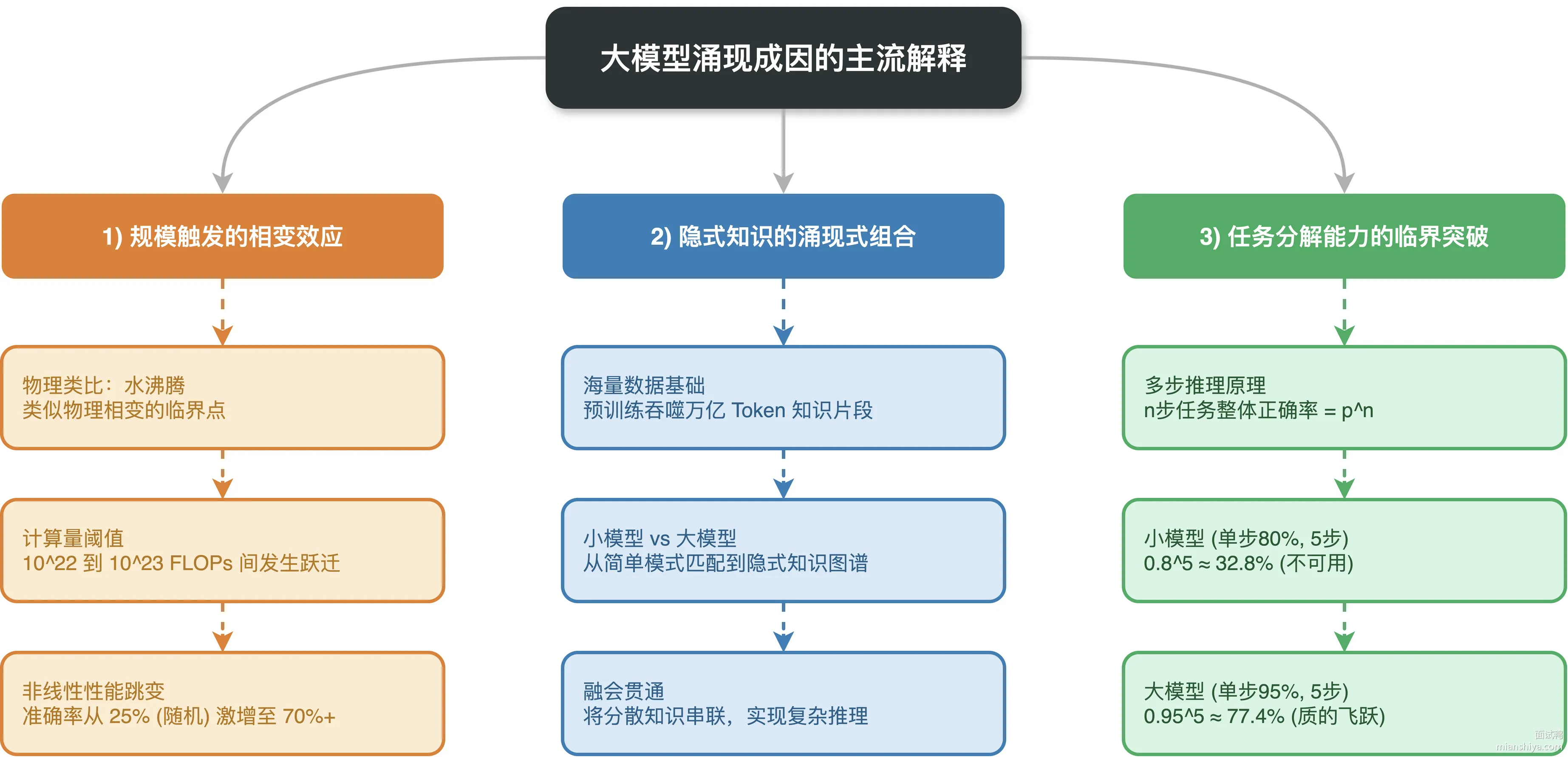
目前学术界对涌现成因有几种主流解释:
1)规模触发的相变效应
物理学里水到 100 度才沸腾,这叫相变。大模型也有类似的临界点,Google 的研究显示,很多任务在模型达到 10^22 到 10^23 FLOPs 之间会发生性能跃迁。在这之前准确率可能就 25%,跟四选一瞎猜没区别;一过这个点,准确率可能直接跳到 70% 以上。这种非线性跃迁用传统的 scaling law 根本预测不出来。
2)隐式知识的涌现式组合
大模型在预训练阶段吃进了几万亿 token 的文本,里面包含了各种知识片段。参数量小的时候,这些知识是零散的,模型只能做简单的模式匹配。参数量够大之后,模型内部形成了某种隐式的知识图谱,能把分散的知识片段串起来做复杂推理。打个比方,小模型像是背了一堆公式但不会用,大模型则是真正理解了公式之间的关系。
3)任务分解能力的临界突破
复杂任务往往需要拆成多个子步骤,每个步骤都有出错的可能。假设每步正确率是 p,n 步任务的整体正确率就是 p^n。小模型单步正确率可能只有 80%,5 步任务就剩 32.8%;大模型单步正确率到 95%,5 步还能保持 77.4%。看起来单步只提升了 15 个百分点,但多步累积下来差距就是好几倍。
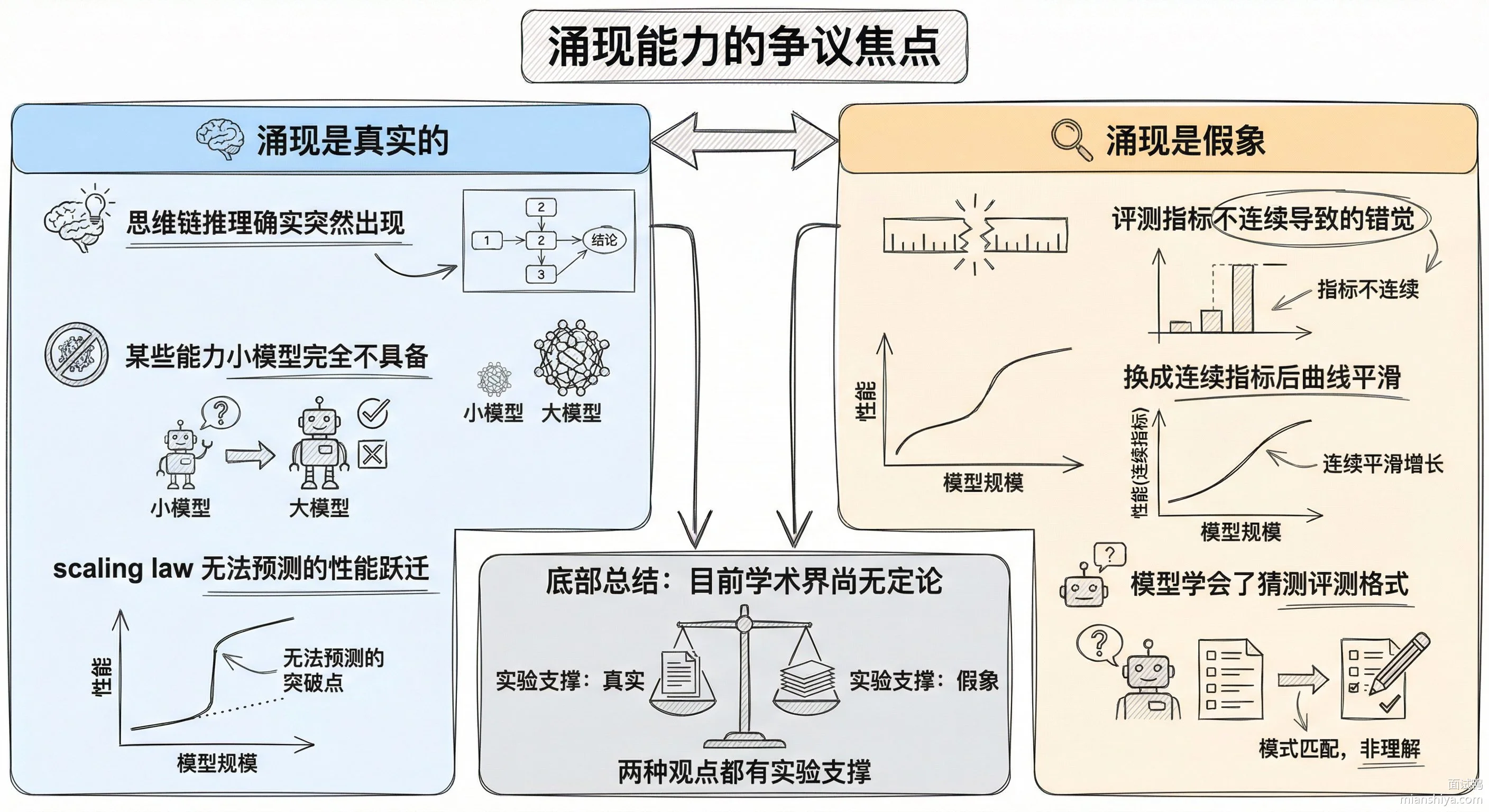
关于涌现的争议
2023 年斯坦福的一篇论文引起了不小的争论,作者认为所谓的"涌现"可能只是评测指标的问题。很多 benchmark 用的是精确匹配,模型答"大约 42"会被判错,只有答"42"才算对。模型越大越能猜中评测想要的格式,所以看起来像是突然涌现。换成连续指标重新测,很多任务的性能曲线其实是平滑上升的。
不过这个观点也有反对意见。Google DeepMind 指出,思维链推理这种能力用任何指标测都是突然出现的,不存在格式问题。所以涌现到底是真实现象还是评测假象,目前还没有定论。
实际应用中的体现
1)代码生成领域,HumanEval 测试里,Codex 12B 的通过率只有 28%,但参数量翻几倍到 GPT-4 级别后,通过率能到 67%,直接翻倍还多。
2)多语言能力上,小模型只能处理训练数据里占比高的语言,大模型则能处理训练集里占比很小的语言,甚至能在不同语言间做零样本翻译。
3)常识推理方面,像 HellaSwag、WinoGrande 这些测试,小模型的表现跟随机差不多,大模型则能达到接近人类的水平。
篇幅有限,更多 AI 大模型 相关面试题可以进入面试鸭进行查阅。
