

RabbitMQ官方提供了5个不同的Demo示例,对应了不同的消息模型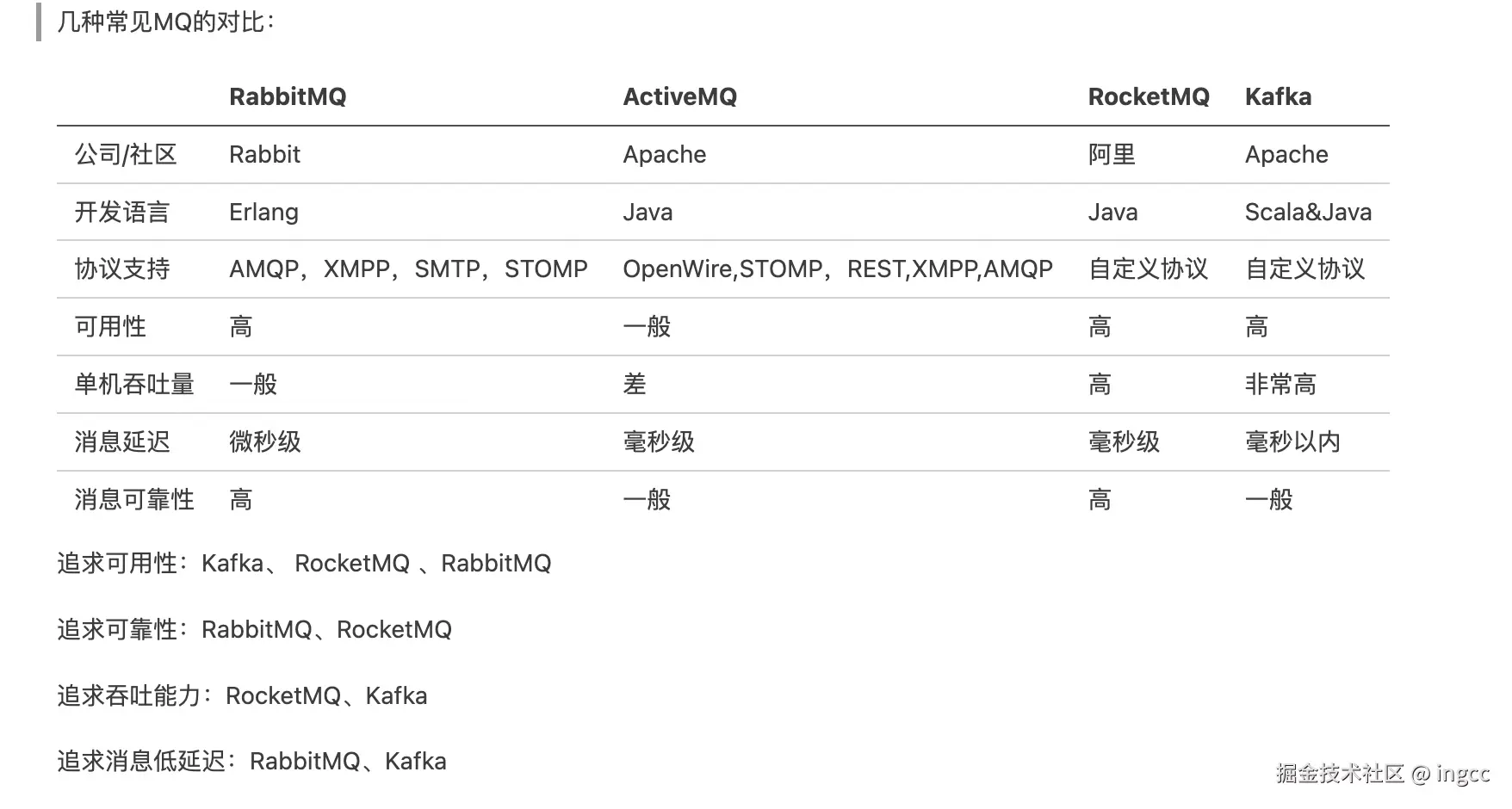
Work queues,也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息
消息发送 这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
/**
* workQueue
* 向队列中不停发送消息,模拟消息堆积。
*/
@Test
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, message_";
for (int i = 0; i < 50; i++) {
// 发送消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);
}
}
3.2.2.消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);
}
注意到这个消费者sleep了1000秒,模拟任务耗时。
启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。
可以看到消费者1很快完成了自己的25条消息。消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。这样显然是有问题的。
3.2.4.能者多劳
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
3.2.5.总结
Work模型的使用:
-
多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
-
通过设置prefetch来控制消费者预取的消息数量
其中工作队列模式,如果生产了一条消息,c1消费者消费了,那个c2消费者就不行接收到了
带交换机的
发布/订阅
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
-
Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给X(交换机)
-
Exchange:交换机,图中的X。一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:
-
Fanout:广播,将消息交给所有绑定到交换机的队列
-
Direct:定向,把消息交给符合指定routing key 的队列
-
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
-
-
Consumer:消费者,与以前一样,订阅队列,没有变化
-
Queue:消息队列也与以前一样,接收消息、缓存消息。
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
3.6.Topic
3.6.1.说明
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert 或者 item.spu
item.*:只能匹配item.spu
3.7.消息转换器
之前说过,Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
-
数据体积过大
-
有安全漏洞
-
可读性差
我们来测试一下。
3.7.1.测试默认转换器
我们修改消息发送的代码,发送一个Map对象:
@Test
public void testSendMap() throws InterruptedException {
// 准备消息
Map<String,Object> msg = new HashMap<>();
msg.put("name", "Jack");
msg.put("age", 21);
// 发送消息
rabbitTemplate.convertAndSend("simple.queue","", msg);
}
停止consumer服务
发送消息后查看控制台:
3.7.2.配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
配置消息转换器。
在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
