

NVIDIA把万亿次算力塞进桌面的另一面:大模型不再是唯一选项
GTC 2026上,黄仁勋在台上展示了搭载N1X芯片的RTX Spark笔记本,Blackwell GPU加Grace CPU再加128GB统一内存,Petaflop级算力被塞进了一台可以放在桌上的设备。他说这是"40年来首次重新定义PC"。
台下观众的第一反应大概是:终于可以在本地跑大模型了。
但这件事还有另一面。如果一台消费级设备的算力已经足够跑多个小模型同时工作,那为什么还一定要追求"一个大模型解决所有问题"?
这个问题背后,是AI行业正在经历的一次成本函数重构。
Scaling Up走到了哪里
过去三年,大模型的主旋律是Scaling Up:参数量从百亿到千亿再到万亿,训练数据从TB到PB,GPU集群从几百张卡到几万张卡。GPT-4的训练成本被业内估算在1亿美元量级,而下一代模型的训练预算传闻已经推到了数亿美元。
但参数翻倍带来的能力提升并不线性。从GPT-3到GPT-4,参数规模增长了大约10倍,但在许多实际任务上的改进幅度远没有10倍那么夸张。学术界把这种现象叫做"Scaling Law的边际收益递减"。更直白地说:花两倍的钱训练一个更大的模型,得到的可能只是15%的性能提升。
推理端的成本同样在累积。以云端API调用为参考:GPT-4级别模型的Token价格大约是GPT-3.5的20到30倍。对于一个每天处理上万次请求的应用来说,这意味着每月数千到上万美元的API开支。
Scaling Up并没有失效,但它的经济效率在下降。
换一个思路:Scaling Out
Scaling Out的思路完全不同。与其用一个超大模型处理所有任务,不如让多个小模型各自负责自己擅长的部分,通过协作完成复杂工作。
这不是新概念。软件工程里的微服务架构走的就是同一条路:把一个巨型单体应用拆成多个独立服务,每个服务做好一件事,通过API协作。AI领域的Multi-Agent系统本质上就是这个逻辑的延伸。
区别在于,过去小模型的能力不够,拆了也没用。一个4B参数的模型在两年前几乎没有实用价值。但2025年以来,小模型的能力边界被大幅拓展。通过更好的训练数据筛选、知识蒸馏、任务专精化微调,4B到8B参数量的模型在特定任务上已经可以逼近甚至超过通用大模型。
开源项目 Mano-P 提供了一个可参考的数据点:它的72B模型在OSWorld评测中拿到了58.2%的成绩,排名专项模型第一(第二名opencua-72b为45.0%)。而真正面向端侧用户的4B模型,在Apple Silicon上以W8A16量化运行时,decode速度达到80.1 tok/s,完全可以支撑实时交互。
关键在于:这个4B模型不需要"什么都会",它只需要在GUI自动化这一个垂直方向做到足够好。其他任务交给其他专精模型。这就是Scaling Out的核心逻辑。
算一笔经济账
用一个开发者日常场景来具体化这笔账。
假设一个独立开发者或小团队,日常需要处理三类AI任务:代码辅助(每天约2000次API调用)、文档处理(每天约500次)、GUI自动化测试(每天约200次)。
方案A:全部使用云端大模型API
以主流API的公开定价估算:
- 代码辅助:GPT-4级别模型,按平均每次请求消耗约1500 Token(输入+输出)计算,月费用大约在300到500美元
- 文档处理:类似Token消耗,月费用约100到200美元
- GUI自动化:需要多模态能力,Token消耗更大,月费用约150到300美元
- 合计:每月约550到1000美元,一年下来6600到12000美元
方案B:端侧设备 + 多个专精小模型
- 硬件投入:一台M4芯片Mac mini(32GB RAM),大约800到1200美元(一次性)
- 运行成本:电费,Mac mini功耗约20W到40W,年电费不到50美元
- 模型获取:开源模型,免费
- 推理成本:零边际成本,跑多少次都不额外花钱
方案B在第二个月就开始比方案A便宜,到第六个月节省的钱已经超过了硬件投入。
这还没有算另一个隐性成本:数据离开设备的风险。对于处理敏感代码、客户数据、内部文档的场景,"截图和任务数据不出设备"本身就有可量化的合规价值。
端侧推理的实际性能
经济账成立的前提是端侧推理的速度和质量能满足需求。来看实际数据。
Mano-P 4B模型在M5 Pro 64GB设备上的实测表现:
- W8A16量化:prefill耗时2.839秒,decode速度80.1 tok/s
- W8A8量化(使用Cider加速SDK):prefill耗时2.519秒,decode速度79.5 tok/s
- prefill阶段加速约12.7%,峰值内存更友好
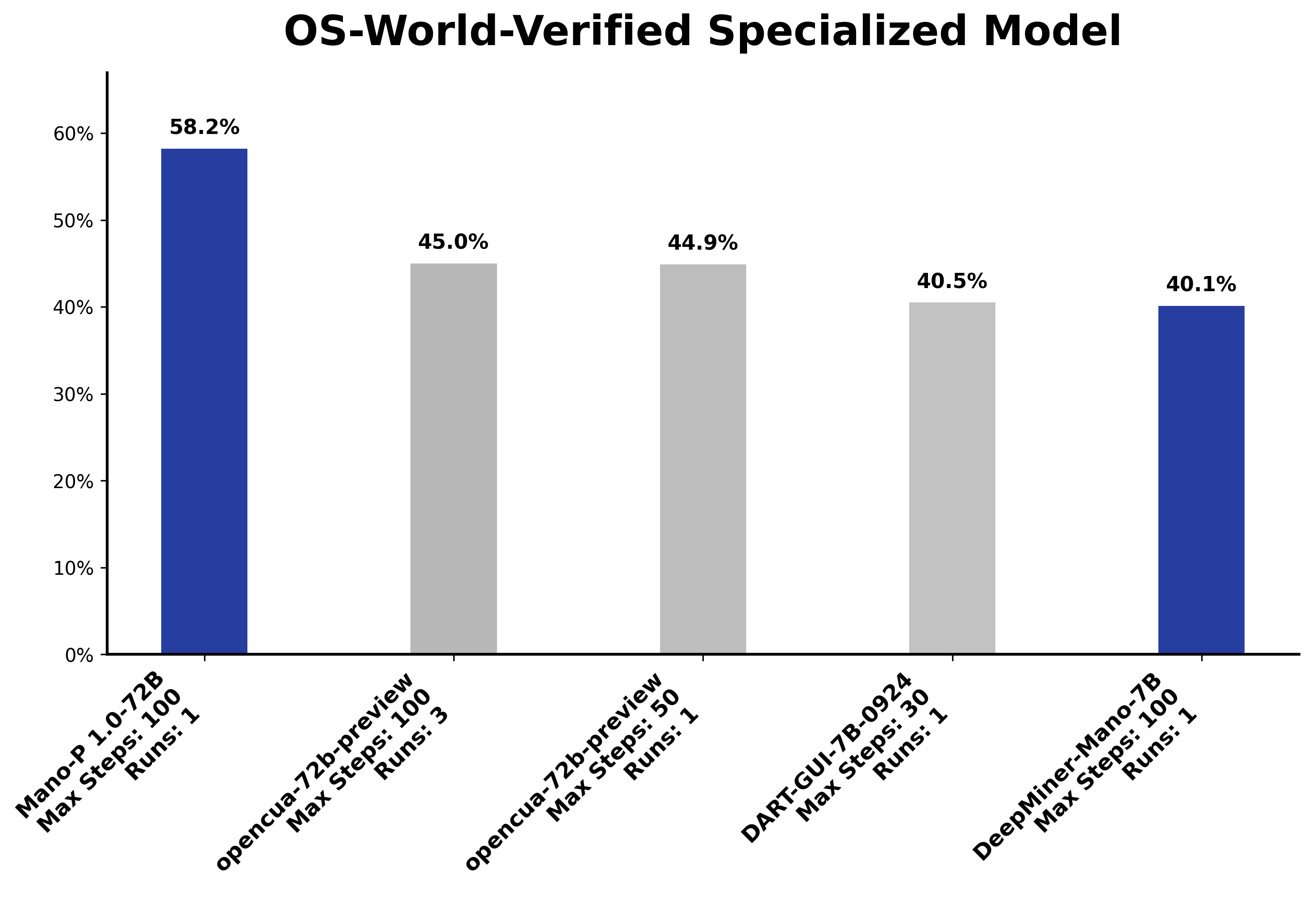
80 tok/s是什么概念?一般认为40 tok/s以上就可以支撑流畅的实时交互,80 tok/s意味着响应速度已经接近"打字即出结果"的体验。
这里值得单独说一下 Cider 这个推理加速SDK。它的核心技术是W8A8/W4A8激活量化。MLX框架原生只支持权重量化(W8A16/W4A16),Cider在此基础上把激活值也做了INT8量化,在M5 Pro上实现了prefill阶段1.4到2.2倍的加速。
更重要的一点:Cider兼容所有MLX模型,不只是服务于Mano-P。任何在MLX生态中运行的模型都可以直接受益于这个加速方案。这意味着它是一个通用的端侧推理基础设施组件,而不是某个特定项目的附属工具。
架构长什么样
Mano-P的开源架构把端侧AI Agent的各个模块做了清晰的拆分:
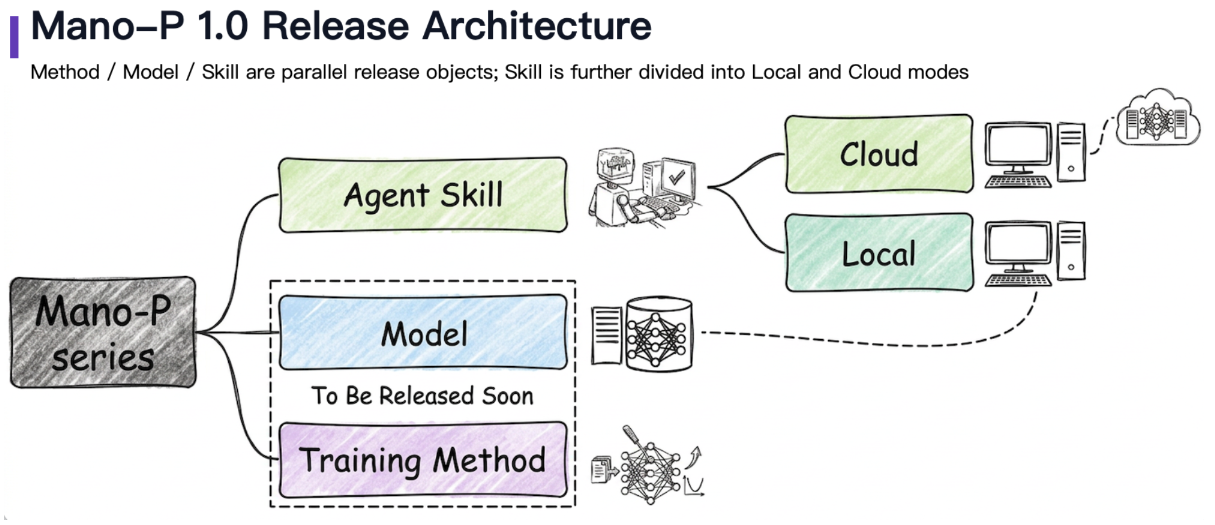
从架构图可以看出,视觉理解、任务规划、操作执行这些能力被设计成可独立运行的模块。这种设计天然适配Scaling Out的思路:每个模块可以由不同的专精模型驱动,根据任务类型动态调度。
在实际应用中,这套架构已经衍生出了 Mano-AFK 这样的自主应用构建工具。从自然语言描述需求,到PRD生成、架构设计、代码编写、本地部署、端到端测试、自动修复,整个流程在本地完成。Mano-P作为视觉模型驱动浏览器进行GUI自动化测试,和代码生成模型协作,是Scaling Out在实际工程中的一个具体实现。
芯片厂商在给Scaling Out铺路
回到GTC 2026的视角。黄仁勋展示RTX Spark时说了一句话:"未来Agent数量远超人类。"另一句是:"算力即营收,每瓦Token数即利润率。"
把这两句话放在一起,含义很明确:NVIDIA认为未来的AI应用形态不是一个超大模型在云端服务所有人,而是大量的Agent分布在各种设备上执行具体任务。RTX Spark的Petaflop算力不是为了让你在本地跑一个GPT-4级别的模型,而是为了让你同时跑多个专精Agent。
苹果走的是另一条路线:统一内存架构加能效优先。M4系列芯片的32GB起步内存,加上MLX生态的推理优化,同样是在为端侧多模型协作提供硬件基础。
两大芯片厂商从不同方向,走向了同一个结论:端侧算力的性价比拐点到了,Scaling Out的经济可行性正在被硬件进步所解锁。
写在最后
Scaling Up和Scaling Out不是互相替代的关系。云端大模型在需要广泛通用知识的场景中仍然不可替代。但对于越来越多的垂直任务,特别是涉及隐私数据、需要低延迟响应、对边际成本敏感的场景,端侧多模型协作正在成为更理性的选择。
芯片在变便宜,小模型在变强,开源工具链在变成熟。这三件事同时发生,不是巧合。
如果你对端侧AI Agent的实际效果和成本结构感兴趣,Mano-P的代码和文档都在 GitHub 上,Apache 2.0协议,技术论文也已公开(arXiv)。跑起来试试,可能比任何分析文章都更有说服力。觉得有价值的话,欢迎顺手给个Star。
