注:笔者所上课程更偏向统计学,但自学和应用又偏计算机,故而内容将存在大量符号乱用的迷惑行为,笔者只能保障一致性。
在我的Hugo博客看更多内容,或者获取无水印版本图片: youngz2357.github.io/Blog/zh
你也可以在对应的Github仓库下载这份markdown
1 引入:二分类问题
1.1 标签假设分布
对于二分类标签,我们可以假设其真实数据分布为伯努利分布/0-1分布(一个只有两种取值可能的变量必然服从伯努利分布)
P(Y=y∣X=x)=πy⋅(1−π)1−y
Y∼Bernoulli(π)
其中,y通常是0或者1
注:统计学领域常用 π 或者Pr{<event name>}表示概率
该分布有如下的性质:
E{Yi}=πiVar{Yi}=πi(1−πi)
1.2 已有方法的局限性
计量经济学领域有直接使用线性回归模型处理二元标签的作法,通常用于检验“某个变量对事件发生概率的边际影响”,并不用于分类问题。
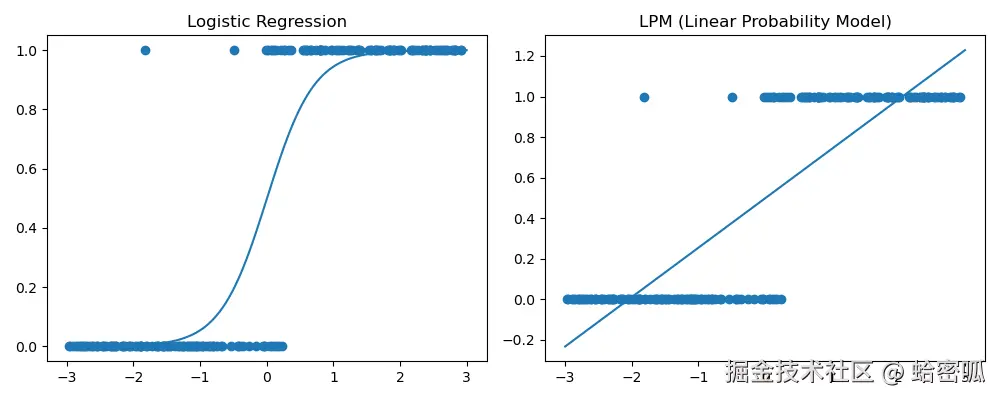
从分类的视角来看,这种方法存在缺陷:线性回归的输出并不会完全落在 {0,1}上,而是任意取连续值。该问题的根本在于线性回归的分布假设。
1.3 分布族不匹配问题
线性回归常用的优化目标(最小二乘)来自于负对数似然,其对应的似然函数形式如下:
L(w,y)=Πi=0N2πσ21⋅exp{−2σ2(yi−wTxi)2}
这个似然函数存直接来自于Y的分布,它最初来自于噪声的正态分布假设:
ϵ∼N(0,σ2)
将线性回归的模型代入(仿射操作),即可得到 Y的假设分布:
Y∼N(wTx,σ2)
这就是似然函数的来源(对所有样本求联合概率密度)。
使用线性回归模型时,残差的结构不匹配。利用残差的定义ϵ=Y−E{Yi},尝试将伯努利分布的情景代入后会得到离散值:
ϵi={1−E{Yi},−E{Yi},if Yi=1if Yi=0
此时伯努利分布下的残差会依赖于Yi,该结构与正态分布矛盾。正态分布的支撑集是整个实数轴,而伯努利代入后只有两个孤立点
支撑集:supp(X):在X的任意小邻域内概率大于 0 的点构成的集合
进一步,我们还可以发现正态分布的“方差恒定”也是冲突的:
Var{Yi}=πi(1−πi)=(wTx)(1−wTx)
此时方差会受到 x的影响,而正态分布的方差应当为恒定值
解决这种分布不兼容的方法也较为直观:
- 对伯努利分布建模
- 设置一个映射使得 wTx满足伯努利分布参数 π∈(0,1)
2 逻辑回归
逻辑回归是使用伯努利分布建立似然,并使用logit函数处理输出的模型。
Yi ∣ xi∼Bernoulli(σ(wTxi))
概率形式:
E{Yi∣xi}=πi=σ(wTxi)
E{Yi∣xi}就是我们常用的输出,即已知观测值xi的前提下,得到标签Yi的概率。
其中:
σ(x)=1+e−x1
2.1 模型推导
与线性回归直接假设残差结构不同,我们需要从伯努利分布本身来推导。我们首先重新定义E{Yi}:
E{Yi∣xi}=πi, πi∈(0,1)
此处我们假设了标签为一个伯努利变量,即 Yi∼Bernoulli(πi),求期望后会得到概率值。
我们期望用一个线性方程wTxi来表达 π,但线性方程的取值范围为(−∞,+∞),与概率值的取值范围(0,1)不匹配。此处可引入一链接函数g,将(0,1)映射到(−∞,+∞),使得:
g(πi)=wTxi
对于逻辑回归,我们会使用logit函数作为链接函数:
g(πi)=log(1−πiπi)=wTxi
选择logit函数的原因可以从如下两个角度来解释。
笔者注:并不限于如下角度,此处仅展示笔者学习过的部分。
I. 值域匹配(注意:必要不充分)
我们需要 g 将 (0,1) 映射到 (−∞,+∞)。Logit通过两步完成这个变换:
第一步,取几率(odds),去掉上界约束:
1−πiπi∈(0,+∞)
第二步,取对数,去掉下界约束:
log(1−πiπi)∈(−∞,+∞)
至此值域匹配完成。这就是logit函数:
g(πi)=log(1−πiπi)=wTxi
对其求反函数,可以得到逻辑回归模型使用的sigmoid函数:
eηeη(1−π)eη=1−ππ=π=π+πeη=π(1+eη)
π=1+eηeη=1+e−η1
但值域匹配只说明logit能用,满足这一条件的函数还有很多(如probit、cloglog等)。下面从另一个角度说明logit为什么在这些候选中应该被优先选择。
II. 指数族PMF展开的自然结果
先简要介绍指数族分布1的概念。如果一个分布的概率质量/密度函数可以写成如下形式,则称其属于指数族:
fX(x∣θ)=h(x)⋅exp[η(θ)⋅T(x)−A(θ)]
其中:
- h(x)≥0:与参数无关,是密度/质量函数的基底部分
- T(x):充分统计量,从数据中提取信息的函数
- η(θ):自然参数(natural parameter),是原始参数的某种变换。当 η(θ)=θ 时,称整个表达式处于canonical form
- A(θ):log-partition函数,由前三者唯一决定,满足 exp(A(θ))=∫h(x)exp[η(θ)⋅T(x)]dx
注:高斯分布、泊松分布等常见分布均属于指数族,此处不展开。
现在将伯努利分布的PMF p(y∣π)=πy(1−π)1−y 展开为指数族形式。
取 exp(log(⋅)) 恒等变换:
p(y∣π)=exp(log(πy(1−π)1−y))
利用对数性质展开并整理:
p(y∣π)=exp(ylogπ+(1−y)log(1−π))=exp(ylogπ−ylog(1−π)+log(1−π))=exp(ylog1−ππ+log(1−π))
对照指数族的标准形式,可以直接读出:
- T(y)=y
- η=log1−ππ - 这就是logit函数
- A=−log(1−π)
- h(y)=1
Logit作为自然参数从纯代数展开中自然涌现,而非人为指定。GLM理论证明,对指数族分布,选择自然参数 η 作为link function(称为canonical link)具有统计最优性质,包括:X⊤y 构成 β 的充分统计量,且对数似然关于 β 是凹函数,保证MLE的唯一性。
注:canonical link的最优性是可推导的结论,推导详见 McCullagh & Nelder (1989),此处略。
因此,逻辑回归选择 g(π)=log1−ππ 作为链接函数。
2.2 参数估计
2.2.1 标准形式
我们先通过MLE来估计参数。根据伯努利分布的PMF,我们可以得到似然函数:
L(w,y)=Πi=1nπiyi(1−πi)1−yi
其中πi=σ(wTx)。取对数,并将πi代入公式:
logL(w,y)=i=1∑n[yilogπi+(1−yi)log(1−πi)]=i=1∑n[yiwTxi−log(1+ewTxi)]
笔者注:逻辑回归的负对数似然和交叉熵含义相同,此处证明略
可见,逻辑回归的对数似然与xi相关,没有闭式解,但我们可以使用梯度下降来求解。
对于指数项:
∂w∂log(1+ewTxi)=1+ewTxiewTxi⋅xi=πixi
完整梯度:
∂w∂logL=i=1∑n(yixi−πixi)
负对数似然的梯度则为:
注:对数似然本身是凹函数,要转移到最优化常用的凸问题则需要换成负对数梯度
i=1∑n(πi−yi)xi
对于学习率α,可以如下更新参数:
w←w−α⋅[i=1∑n(πi−yi)xi]
注:Sigmoid函数性质σ′(z)=σ(z)(1−σ(z))
验证其凸性,使用二阶充要条件。求单个向量的二阶导:
∂wT∂(πixi)=πi(1−πi)xixiT
则整个黑森矩阵:
H=i=1∑nπi(1−πi)xixiT
易得 :xixiT平方非负,概率值均大于等于0(Sigmoid函数值域),黑森矩阵半正定,逻辑回归的优化目标是凸的。凸性能使得所有局部最优均等于全局最优,实战中不用过于担心初始化策略。
2.2.2 正则化形式
和线性回归相同,逻辑回归的惩罚项可以直接添加到
L2正则化:
wmini=1∑n[log(1+ewTxi)−yiwTxi]+λ∥w∥22
L2正则化后优化目标仍然处处可微,仍然可以使用梯度下降更新:
w←w−α⋅[i=1∑n(πi−yi)xi+2λw]
L1正则化:
wmini=1∑n[log(1+ewTxi)−yiwTxi]+λ∥w∥1
优化目标零点处不可微,实践中次梯度代替梯度的收敛速度较慢,常用近端梯度法更新:
wj←sign(wj)(∣wj∣−αλ)+
对于次梯度
2.3 多分类处理
逻辑回归的多分类可以通过设置基础类 → 剩余的每一类对应一个概率值:
π1=1+∑j=1JewjTxj1, πi=1+∑j=1JewjTxjewiTxi
还可以将logit函数扩展为softmax函数,每一个类别就对应一个“自然指数项”:
πi=1+∑j=1jewjTxjewiTxi
修改定义后代入原模型即可
笔者注:为了叙述方便,部分逻辑回归的特性将不设单独章节,转而在实际场景中描述
3 逻辑回归的应用
3.1 对抗检验
逻辑回归可以用于采样性覆盖损失的对抗检验。对抗检验用于检查不同组别的数据是否“属于同一分布”,即数据的特征没有显著差异。
理论上来说,任何分类器都可以用作对抗检验,但是逻辑回归是最常用的一种。主要原因有:
- 低方差:参数空间维度等于特征数+1,没有冲去空间去捕捉随机噪声(数据集之间噪声可能不同)
- 可解释性:模型参数可以解释数据集间,该特征单位变换后的偏移量。
- 保守下界:线性关系相对简单,若能用LR捕捉则说明数据偏移已经相当严重。若有更高要求,可以通过逻辑回归检验后再使用非线性模型作对抗验证(如GBDT)
其原理为:使用逻辑回归尝试分类分组后的数据。如果划分有效,数据组间拥有相同的特征,若该点满足,则逻辑回归模型不应当将两组数据成功分类,反之则可以有效分类。实操中,AUC分数越接近0.5,则说明数据集划分效果越好。AUC大于0.5说明模型分类效果优于随机选择,数据分布存在差异。
输入: 数据集 A, 数据集 B
输出: Area Under Curve
1. 初始化逻辑回归模型LR
2. y_A <- 0, y_B <- 1
3. X <- 拼接A 和 B,保持顺序
4. y <- 拼接y_A 和 <- y_B ,保持顺序
5. LR.fit(X, y)
6. y_prob <- cross_val_predict(LR, X, y, cv=5, method="predict_proba")[:, 1]
7. return roc_auc_score(y_prob, y)
示例场景:欠采样导致特征断层
当对多数标签进行欠采样时,可以对欠采样前后的数据集进行对抗检验,以确认欠采样没有造成特征丢失。这种情景多发于不均衡样本处理,以下是一个较为直观的例子:
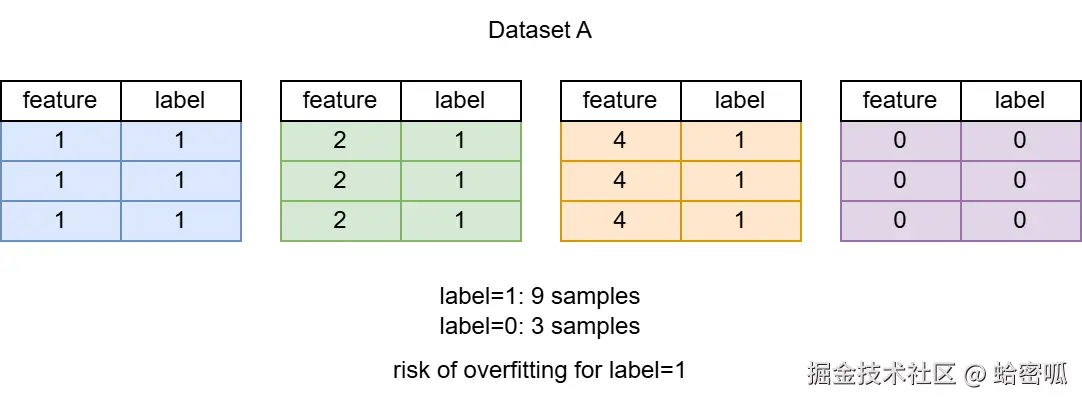
直接训练该数据集可能导致模型对正类过拟合,即使全部选正类,仍然能达到75%的准确率。若对数据集进行欠采样,则需要先观察特征分布情况,再进行粗略地分层采样,否则可能导致部分特征丢失产生断层。
笔者注:欠采样只是众多处理不均衡标签的一种方案,此处取用以便于演示对抗检验。
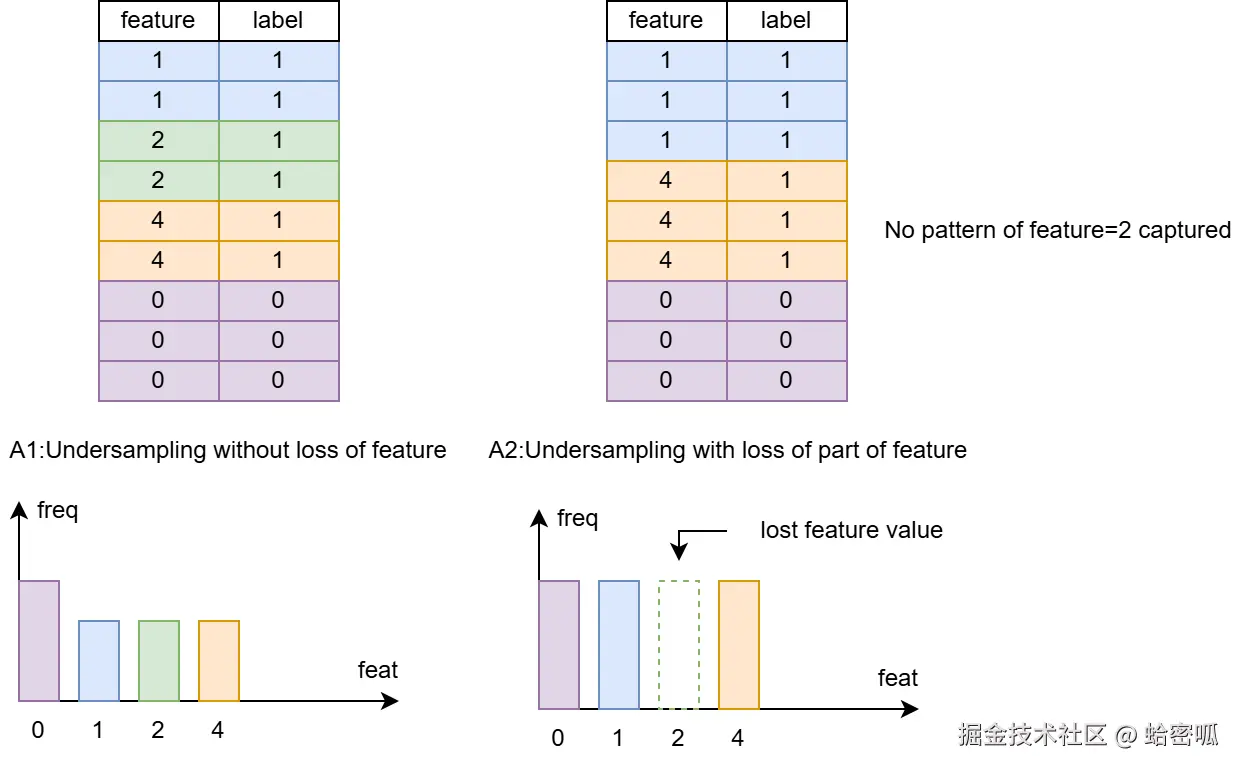
以如图的数据集为例,若将A2所有数据重新标记为1,A所有数据重新标记为0,逻辑回归会因无法在A2中识别到特征X=2而成功将对应的数据划分给原始数据集,造成AUC分数大于0.5,表明两个数据集存在差异,可能由欠采样产生的特征断层导致。
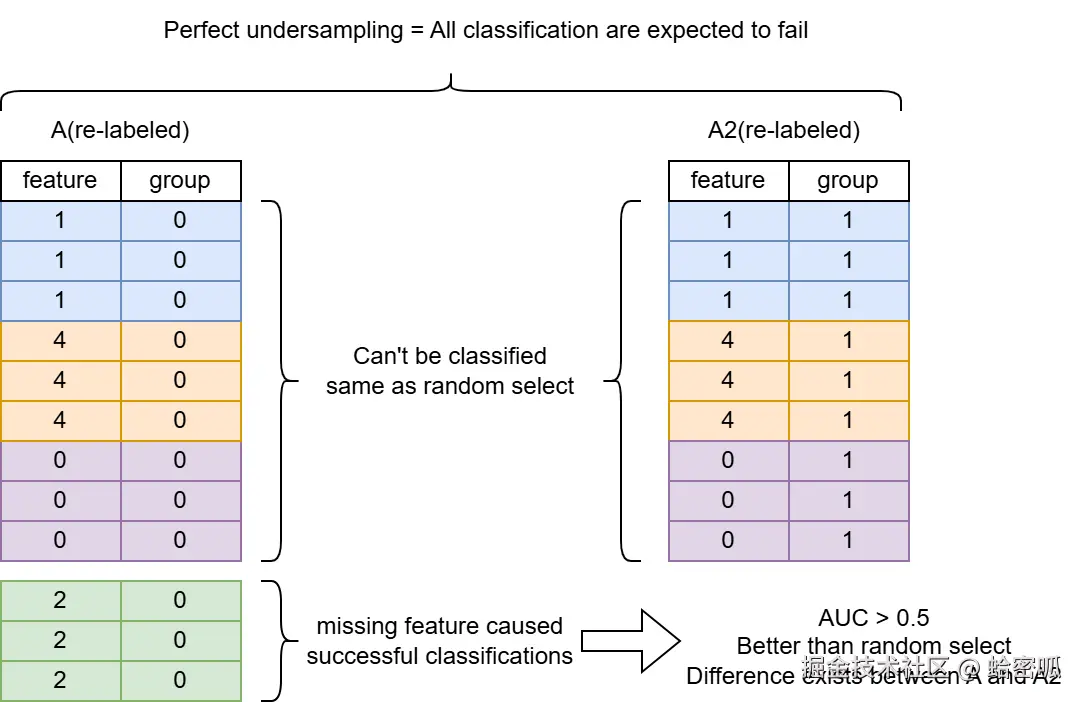
逻辑回归的线性假设使得其对部分缺失的线性模式特征天然具有平滑插值能力,但这也意味着其无法对抗存在非线性模式的特征。该点说明:若特征呈线性模式,逻辑回归对抗检验将无法捕获差异。若改用更复杂的分类器,则可能进一步导致对噪声拟合,而始终使得AUC>0.5,指标区分效果下降。“完美”分类器选择依赖于经验。
需要注意的是,该例子中数据集 A1 的AUC仍然会大于0.5,但会非常接近0.5,AUC大于0.5并不意味着分割效果差。通常情况下,对抗检验AUC在0.5~0.55以内都可以认为数据分布几乎一致,0.55~0.6内可用,超过0.6则需要重新考虑欠采样方案,或者索性改用其他方法。
3.2 多标签分类
当我们需要单次输出多个独立的概率值(或者类别)时,使用逻辑回归进行多次建模就成了一种自然的baseline选择。其大致思路如下:
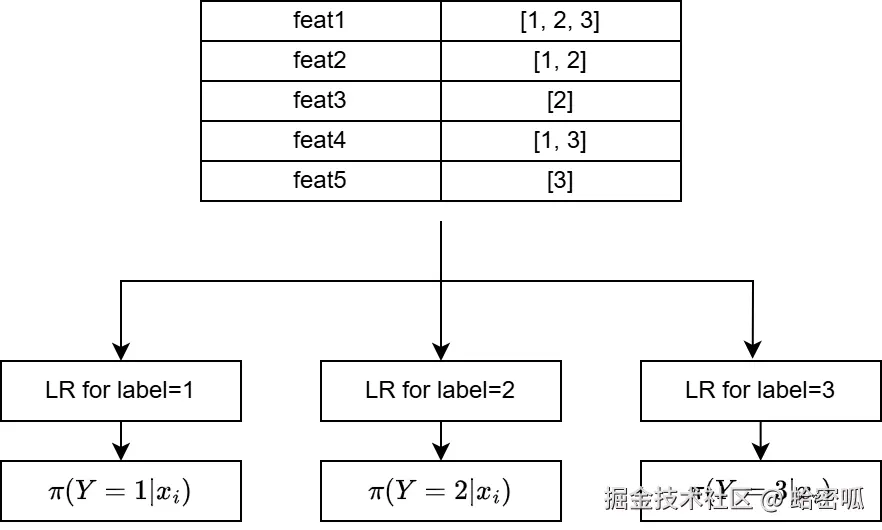
这种方案下,我们通常需要假设标签之间是独立的。如CAFA蛋白质功能预测2这种标签之间存在明确图关系的任务,该思路的有效性会下降,但仍可作为初步方案。
3.3 用于模型叠加/作为输出用分类器
逻辑回归可以很方便地和其他模型组成集成模型,并用以输出类别或者概率。Facebook曾提出过使用GBDT+LR来进行广告分类3,将GBDT样本所在的节点进行独热编码作为新特征,再使用它训练逻辑回归,此处GBDT被视为了一个自动特征工程器,逻辑回归是真正的分类器。
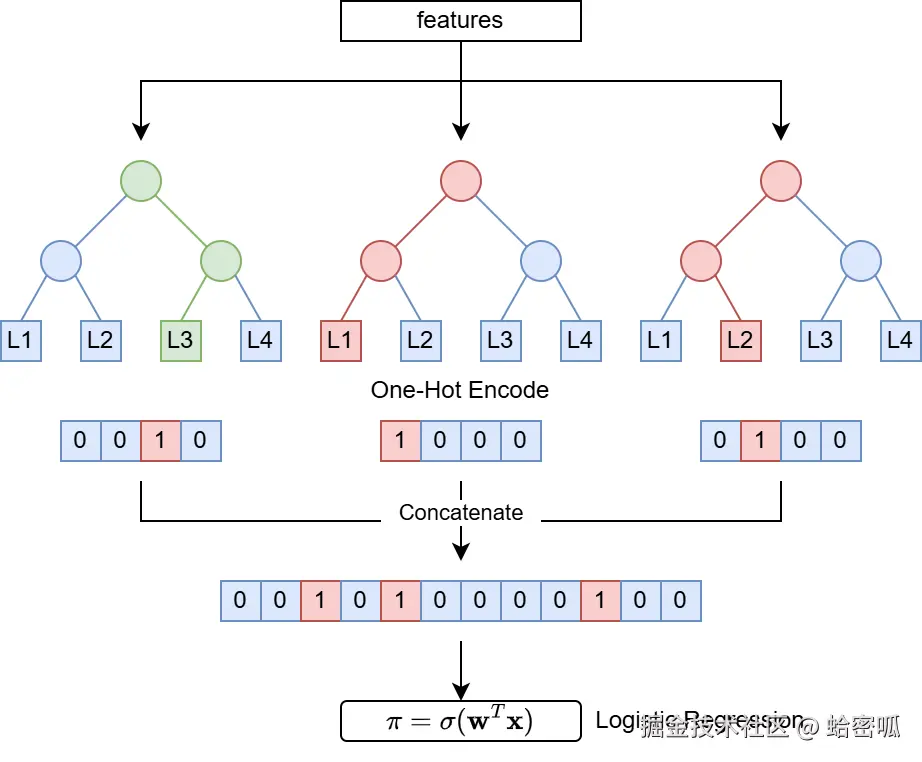
如果使用的平台很难获取到叶子节点索引(如PySpark),可以考虑用GBDT原始输出 + 逻辑回归 stacking模型以另一种方式结合两个模型的优势。这种作法还有个优势:你可以对前置模型设置任意的标签类型(例如,用户满意度,分数为1到10的整数,可以考虑回归或者分类)
参考链接
-
Wikipedia: Exponential Family Wiki链接
-
Kaggle CAFA6 蛋白质预测竞赛官网:竞赛平台官网
-
Facebook GBDT+LR模型论文 文献链接

