

AI 终于长出手了:下一场 Agent 战争,不在聊天框里
过去一年,很多人对 AI 的感受其实很分裂。
一边是模型越来越会说话,写文章、总结资料、改代码,几乎都能帮上忙。另一边是真把它放进工作流里,就会发现最烦人的地方完全没变:登录、上传图片、选择封面、点原创、填标签、处理弹窗、等审核、再打开页面验收。
它能把一篇文章写得像模像样,却不一定能把这篇文章稳定发出去。
这就是下一波 AI Agent 的真实战场。
不是谁的聊天框更像人,而是谁能让模型真正进入浏览器,读懂页面,复用登录态,点击按钮,处理失败,并按用户真实路径确认结果。
换句话说,AI 终于开始长出“手”了。

图:作者基于 HTML/CSS + Playwright 本地渲染。资料参考 GitHub 开源仓库与官方文档。
聊天框时代快到头了
聊天框的优点很明显:它简单、低成本、所有人都会用。
但聊天框也有一个天然限制:它把世界压缩成了文字。
你问它一个问题,它回答你一段话。你让它写一篇文章,它给你 Markdown。你让它分析一个网页,它需要你复制粘贴。你让它发一篇内容,它开始变得尴尬:因为真实世界不是一段文字,而是一堆状态。
一个网页后台里,真正麻烦的东西往往不在正文里。
按钮是不是灰的,封面有没有上传成功,登录态是不是过期,图片是不是被平台转存,草稿是不是保存,发布以后是不是进入审核,公开页是不是能打开。这些东西不是“语言理解”问题,而是“状态观察”和“行动闭环”问题。
过去我们把 AI 当成一个脑子。现在它缺的是身体。
浏览器,就是它最先获得的身体。
开源世界已经给出信号
我在 2026 年 5 月 28 日晚上重新抓了一遍 GitHub 数据。几个和浏览器 Agent 相关的项目,热度已经不低。
browser-use 接近 9.6 万 Star,定位很直接:让网站对 AI Agent 可访问。Stagehand 把自己称为 AI Browser Automation Framework。Microsoft 的 Playwright MCP 明确说,它通过 Playwright 给 LLM 提供浏览器自动化能力。ByteDance 的 UI-TARS Desktop 则走得更靠近多模态桌面 Agent。Kortix/Suna 这类项目把浏览器、文件系统、命令行、集成工具放到一个更大的“公司 AI 工作台”里。Vercel Satori 虽然不是 Agent 项目,但它代表了另一条实用路线:用代码生成稳定、可复用、可批量生产的视觉资产。
这些项目不是同一类产品,却在解决同一个问题:让模型从“回答问题的人”,变成“操作环境的人”。
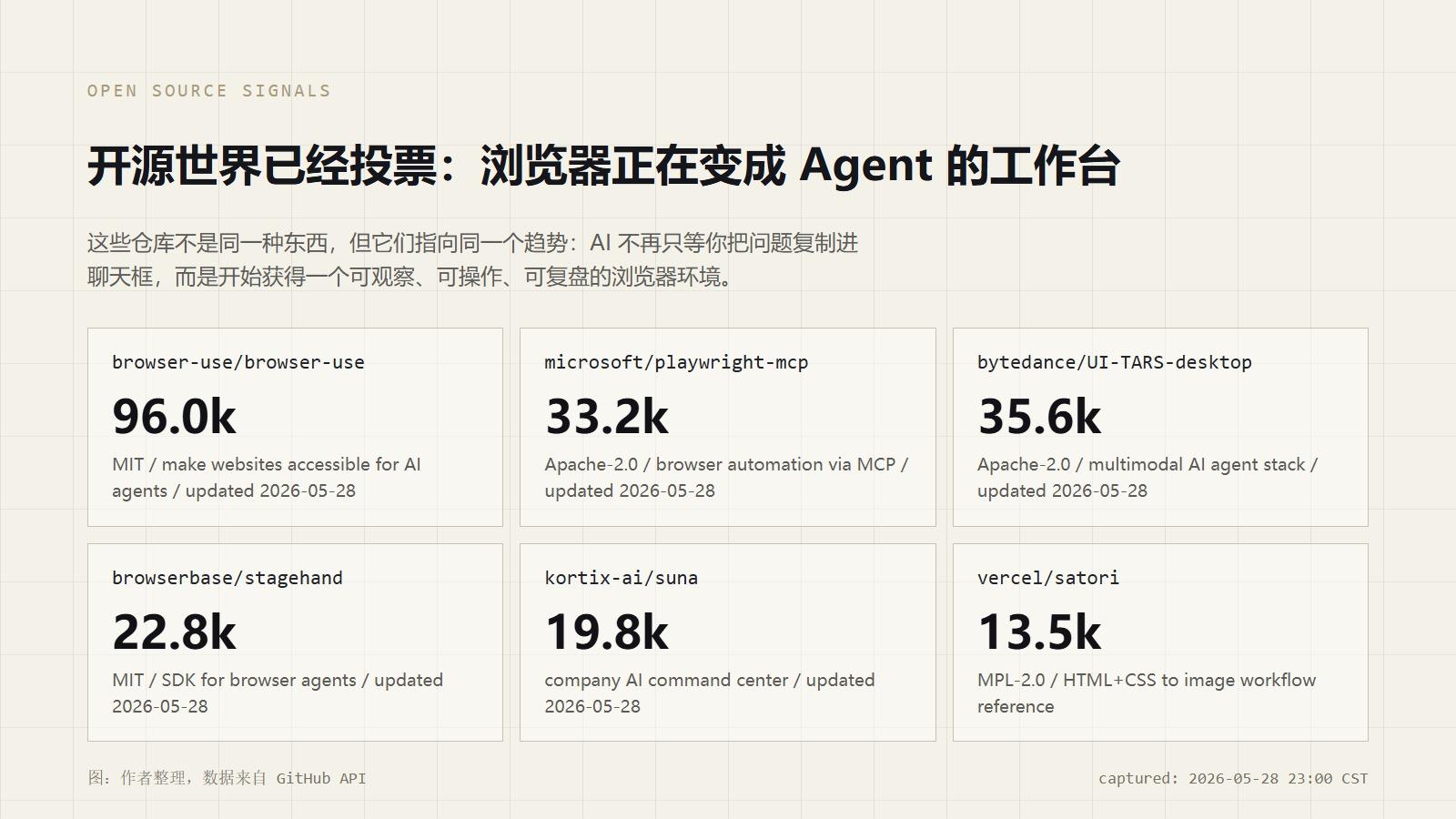
图:作者整理,数据来自 GitHub API,抓取时间为 2026-05-28 23:00 CST。
这件事的变化,比表面看起来更大。
以前的自动化脚本是人写死流程:打开 A 页面,点击 B 按钮,填入 C 文本。如果页面变了,脚本就坏。
浏览器 Agent 想做的是另一件事:它先观察页面,再根据目标决定下一步。按钮位置变了不一定立刻崩,页面多了一个弹窗也不一定完全停住。它不是“录制一段鼠标动作”,而是在浏览器里持续做判断。
这也是为什么 browser-use、Stagehand、Playwright MCP 这些项目会被同时关注。大家并不是突然对浏览器测试感兴趣,而是意识到:如果 Agent 要替人做事,浏览器几乎是绕不开的入口。
真正难的不是点击,而是看懂页面
很多人第一次听“浏览器 Agent”,会以为这东西就是自动点网页。
这其实低估了问题。
点击本身并不难。Playwright、Selenium、Puppeteer 早就能点。难的是模型怎么知道该点哪里,点完以后发生了什么,以及如果没成功该怎么恢复。
一个稳定的浏览器 Agent,至少需要五层能力。
第一层是模型。它理解任务,决定策略,也负责在信息不够时提出下一步观察。
第二层是观察。网页不能只当成一张截图。更可靠的方式,是把 DOM、Accessibility Tree、按钮文本、输入框状态、当前 URL、页面提示等结构化信息交给模型。Playwright MCP 的 README 里就强调,它使用结构化的 accessibility snapshots,而不是完全依赖截图。
第三层是行动。模型选定动作以后,需要有工具执行:点击、输入、上传文件、等待网络、切换标签页、滚动页面。
第四层是会话。真实业务里,登录态、Cookie、浏览器扩展、平台草稿、风控状态都很重要。一个每次都重新打开干净浏览器的 Agent,到了内容发布、电商后台、企业系统里会非常痛苦。
第五层是验收。命令执行成功不是验收。用户真实打开页面能看到标题、正文、图片、状态,这才是验收。

图:作者整理,参考 Playwright MCP、Stagehand、browser-use 等开源项目说明。
这也是为什么很多看似简单的任务,到了 Agent 手里会变得很难。
“发一篇文章”在人类看来是一个动作,在机器看来是一串不稳定状态:正文要进编辑器,图片要上传到平台,封面要单独设置,原创按钮可能要手点,发布按钮可能被风控拦截,微信还可能需要手机确认。
你不能只问“模型会不会写文章”,你要问“它能不能穿过这些状态”。
为什么浏览器会成为 Agent 的第一战场
因为浏览器是现代工作的最大公约数。
你用飞书、Notion、GitHub、CSDN、知乎、掘金、微信公众号、银行后台、CRM、工单系统、云控制台,本质上都在浏览器里工作。企业软件再复杂,最后往往也会收束成一个页面、一个表单、一个按钮、一条状态提示。
这给 Agent 一个很现实的落点。
如果模型能稳定操作浏览器,它不需要每个系统都开放 API,也不需要每个平台都为它重新设计接口。它可以先像人一样进入现有系统,再逐渐把流程自动化。
这不是最优雅的工程路径,但很现实。
历史上很多自动化都是这样开始的:先模拟人,再抽象接口。RPA 当年吃的就是这块市场,只是传统 RPA 太依赖固定流程,维护成本高。LLM 带来的新变量,是它可以在流程变化时做一些推理和补救。
这不代表所有 RPA 都会被替代。恰恰相反,未来很可能出现一种混合形态:确定的步骤交给脚本,不确定的页面状态交给模型,关键风险点交给人确认。
真正成熟的 Agent,不会是一个到处乱点的黑箱,而是一套可观察、可回放、可中断的执行系统。
这件事和普通人有什么关系
如果你只是日常使用 AI,浏览器 Agent 会让你第一次感受到:AI 不只是给建议,而是能接手一段工作。
比如让它整理发票,不只是告诉你怎么整理,而是打开邮箱、下载附件、填表、提交报销。
比如让它做竞品分析,不只是列几个网站,而是逐个打开页面、截图、抽取价格、整理表格。
比如让它发布内容,不只是写好稿子,而是同步到平台草稿、检查图片、打开编辑器,让你最后确认。

图:作者整理,基于多平台内容发布实测流程,使用 HTML/CSS + Playwright 渲染。
这里的关键不是“全自动”。
反而,越接近真实工作,越不应该迷信全自动。涉及钱、账号、公开发布、隐私数据、企业权限时,人必须还在环里。好的 Agent 应该把繁琐部分做掉,把需要判断的地方清楚摊开,让人做最后决定。
这也是我更看好“可控 Agent”的原因。
它不是一个神秘助手,而是一个带日志、带草稿、带预览、带回退能力的执行器。
最大的坑:浏览器不是干净实验室
浏览器 Agent 很迷人,也很危险。
因为浏览器里有真实账号、真实权限、真实资产。
一个模型如果能点按钮,也就可能点错按钮。如果能上传文件,也可能上传错文件。如果能读页面,也可能读到不该给它看的内容。如果能复用登录态,它就天然接近用户权限边界。
所以这条路往下走,技术问题会迅速变成治理问题。
第一,Agent 的权限要小。它不应该默认继承你整个浏览器的全部登录态,而应该尽量在隔离的 profile、受控的页面、明确的任务范围内工作。
第二,关键动作要有人确认。付款、删除、公开发布、改权限、发邮件、提交表单,这些动作不应该被包装成“自动继续”。
第三,过程要能审计。它看了什么页面,点了什么按钮,上传了什么文件,失败在哪里,都应该留下记录。
第四,验收要贴近用户路径。工具返回 success 没意义,最后页面有没有变成用户需要的状态才有意义。
这也是为什么我认为,浏览器 Agent 的竞争最后不会只看模型有多强。
它会同时看工程系统、权限设计、状态管理、人工确认、日志审计、异常恢复。谁能把这些脏活做好,谁才更接近真正可用。
下一场战争不在聊天框里
过去我们问一个 AI 产品好不好,常常看它回答得准不准,写得像不像人。
接下来这个标准会变化。
我们会问:它能不能接上真实工具?能不能处理真实页面?能不能复用我的工作环境?能不能在关键节点停下来问我?能不能证明它真的完成了任务?
这就是浏览器 Agent 的意义。
它不是让 AI 更会聊天,而是让 AI 从聊天框里走出来,进入人类已经使用了二十多年的工作界面。
AI 的下一步,不是再多一张更漂亮的对话页。
是它终于能看见按钮,伸手去点,并在点完以后告诉你:我检查过了,事情真的办成了。
参考资料
- GitHub, browser-use/browser-use, 访问时间:2026-05-28。
- GitHub, browserbase/stagehand, 访问时间:2026-05-28。
- GitHub, microsoft/playwright-mcp, 访问时间:2026-05-28。
- GitHub, bytedance/UI-TARS-desktop, 访问时间:2026-05-28。
- GitHub, kortix-ai/suna, 访问时间:2026-05-28。
- GitHub, vercel/satori, 访问时间:2026-05-28。
- Microsoft Playwright, Playwright Documentation, 访问时间:2026-05-28。
- Model Context Protocol, Official documentation, 访问时间:2026-05-28。
