


摘要:对话状态与记忆管理是AI Agent面试的高频必考点。
上周五晚上,线上Agent的上下文突然塌了——用户在多轮对话里提过的地址、偏好,前面确认过的选项,全部忘干净。
查日志发现是Context Window被撑爆,截断策略刚好把System Prompt之后的内容全清掉。这不是小概率事件:任何一个上线过对话Agent的工程师,只要用户量稍大,几乎都会撞上这把刀。

屏幕一红,心率先上去了
这道题之所以反复出现,是因为它同时踩中了好几个能力维度:工程设计(怎么管状态)、系统认知(怎么控预算)、产品判断(哪些东西不能丢)。

这一改,边界就开始漂了
只会说「超了就截断」的人,暴露了自己只处理过toy project。

你开心就好,我先不展开了
先说清楚一件事:记忆管理不是「把对话塞进Context」这么简单。
这一段,懂的都懂
它是一套分层策略,从毫秒级Working Memory到分钟级Summary Buffer再到小时/天级别的External Memory,每一层都有自己的设计约束和取舍。
为什么这道题每次必问:面试筛选逻辑拆解
第一层 :看你知不知道记忆管理有分层。只会说「超了就截断」的人,实际上暴露了自己只处理过toy project,没有真正在生产环境里管过上下文预算。
面试官真正想听到的是「分层」这个概念,以及每一层的取舍依据。第二层 :看你能不能区分「状态」和「知识」。
很多候选人把用户偏好、合同条款、产品知识一股脑往Context里塞,分不清哪些该走Working Memory、哪些该进长期记忆、哪些应该外存到向量库。这背后是一个产品设计问题。
第三层 :看你在多用户场景下有没有隔离意识。session_id怎么生成、怎么唯一性保障、怎么隔离——这是AI Agent工程化的硬骨头,也是面试里经常被追问的深水区。
这道题的本质不是在考你背没背住某个框架的API,而是在考你有没有在脑子里构建过一套完整的状态管理世界观。框架会变,但这个思考框架是不会过期的。
三层记忆架构:从Working Memory到长期记忆的整体设计
在说清楚三层记忆架构之前,先给一个核心判断:这三层不是并列关系,而是时间尺度和访问频率的梯度 。
Working Memory管当前会话,Summary Buffer管压缩保留,External Memory管跨会话持久化。每一层的读写延迟、数据规模、Token成本都不一样。
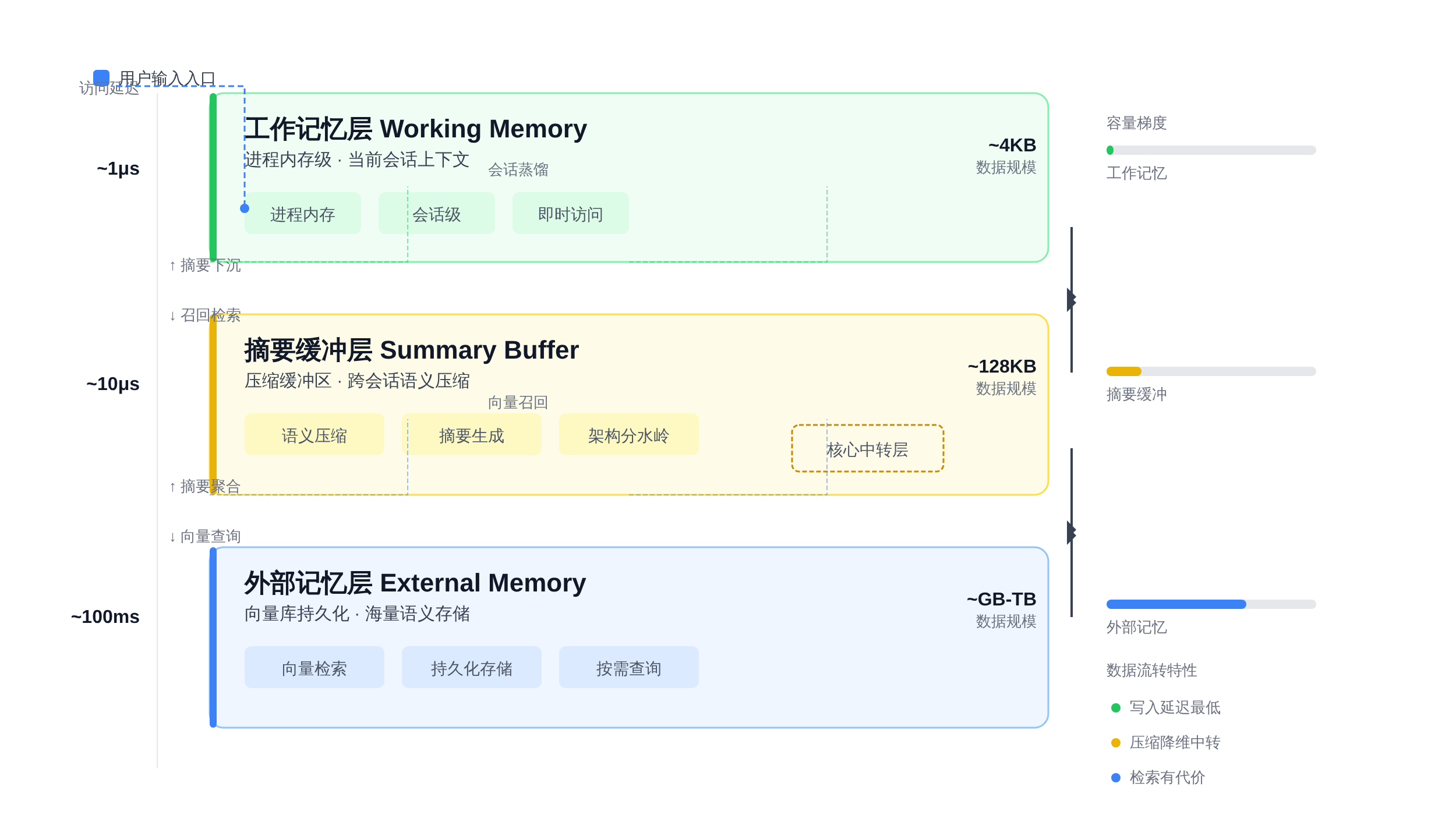
正文图解 1
这个分层不是某篇论文的独创设计,而是工业级对话Agent普遍采用的基础架构。MemGPT最早把这个思路系统化,后来被LangGraph、AutoGen等框架广泛借鉴1。
Working Memory:会话进行时的即时状态容器
Working Memory是整个架构里最简单、也最容易被错误设计的一层。简单在于它本质上就是进程内的会话状态容器;容易被错误设计,是因为很多人在这里塞了不该塞的东西。
Working Memory的核心职责只有三个:接收当前用户输入、持有最近N轮对话历史、维护当前会话的运行时状态 。
运行时状态包括:当前Agent正在执行的任务阶段、已经确认的用户偏好、工具调用的中间结果、以及任何「这次会话有效、下次会话作废」的临时数据。
设计Working Memory时最容易掉的坑,是把它当成万能容器。
有人会把用户的所有历史偏好、合同文本、产品手册全部缓存在这里,等Context被撑爆了才发现Working Memory本身就超长了。
正确做法是Working Memory只持有「当前会话窗口内高频访问的数据」 ,超过一定TTL或者达到会话窗口边界的数据,要么推进Summary Buffer,要么直接丢弃。
实现层面,Working Memory通常就是Python进程内的一个dict或dataclass:
class WorkingMemory:
def __init__(self, max_turns: int = 10):
self.recent_turns: list[dict] = []
self.max_turns = max_turns
self.task_state: dict = {}
self.session_preferences: dict = {}
self.token_count: int = 0
def add_turn(self, role: str, content: str, token_cost: int):
self.recent_turns.append({"role": role, "content": content})
self.token_count += token_cost
if len(self.recent_turns) > self.max_turns:
self._trigger_compress()
def _trigger_compress(self):
raise NotImplementedError("Subclass must implement compression logic")
这里有一个关键参数:max_turns。它不是拍脑袋定的,而是根据Context窗口剩余容量、每轮对话的平均Token数和模型的最大输入限制实时计算出来的。
举个例子:如果模型最大Context是128k tokens,System Prompt占28k,当前Summary占15k,工具Schema占20k,剩余可分配给Recent Turns的额度大约是65k,平均每轮3k tokens的话,大约能持有21轮。
工程上通常保守一点,把max_turns设到15到18轮左右。
⚠️ 踩坑提醒 :Working Memory里的session_preferences不要设计得太重。
如果在每个会话里把用户所有的偏好都缓存在这里,等用户换了一台设备登录,Working Memory全部清零,之前存的偏好一个都不剩。
Summary Buffer Memory:压缩触发时机与摘要质量控制
Summary Buffer Memory是三层架构里最容易被面试官追问细节的一层,因为它的设计空间很大,细节取舍直接决定压缩质量。
触发时机通常有三种策略 :策略一:固定轮次触发 。每N轮对话之后主动压缩。优点是实现简单、可预测;
缺点是N设小了浪费Token,N设大了可能在关键信息还没沉淀的时候就触发了压缩。LangChain的ConversationSummaryMemory默认就是这个策略2。
策略二:Token阈值触发 。当Working Memory的token_count超过某个阈值时触发压缩。这种策略更贴合实际预算,但需要精确的Token计数能力。策略三:语义重要性触发 。当检测到用户表达了关键意图(确认了地址、下单了商品、同意了某个条款),立即触发压缩,把这些「高价值信息」优先保住。
这种策略需要对对话内容做实时意图识别,实现成本高,但压缩质量最好。
工程实现上,大多数生产级系统采用前两种策略的组合:Token阈值作为硬性边界,固定轮次作为兜底触发。语义重要性可以作为加分项,在Token预算相对宽裕的时候开启。
压缩质量控制有两个维度 :语义完整性 :压缩后的摘要必须保留对话的关键信息点——用户最终确认的需求是什么、Agent做出了哪些关键决策、用户表达了哪些硬性约束。
「今天天气真好」这种对话轮次可以扔,但「收货地址改成朝阳区xxx」必须100%保留。结构性保留 :好的摘要不是把对话流水账压缩成一段话,而是保留结构化信息。
工程上可以设计一个Schema,强制包含字段:{用户核心需求, 已确认决策列表, 待解决子任务队列, 关键约束条件}。
如果你做过实际项目,可以这样说:「我们当时遇到一个问题——压缩后的摘要经常丢用户偏好,后来发现是因为触发时机太早,很多偏好还在对话中间没被确认。
于是我们加了一个『偏好确认标记』机制,用户明确确认过的偏好会被打上tag,压缩时优先保留,准确率从78%提到了93%。」
External Memory:向量库检索召回的工程实现
External Memory是三层架构里设计空间最大、也是最能拉开区分度的一层。
Working Memory只管当前会话,Summary Buffer管跨轮压缩,而External Memory要做的事情本质上是把「Agent应该知道但不应该每次都从零学」的知识外存化 。
最典型的例子就是:用户的长期偏好、产品知识库、合同条款历史——这些东西体量大、不会频繁变更、但每次会话都可能需要调用。如果全塞进Context,128k tokens撑不了三轮;
如果每次都重新注入,Token成本爆炸。
工程实现主流方案是向量数据库 + 语义检索召回 ,具体分三步:** 第一步:语义分块(Semantic Chunking)**
不是把整本产品手册往向量库里一扔就完事了。常用方案有三种:固定长度分块(比如每512 tokens切一段)、语义分块(按自然段落切)、层次分块(大段套小段,支持多粒度检索)。
生产级系统的选择通常是语义分块 + overlap ,相邻两个chunk之间保留一定重叠(比如各50 tokens),目的是防止关键信息恰好被切在段落边界上。
这个overlap比例通常在15%到25%之间。第二步:Embedding生成与索引写入
分块之后,每块文本过一遍Embedding模型,生成向量存进向量库。
向量库的选型也是一道实际工程题:Pinecone、Milvus、Weaviate、Qdrant各有权衡——云原生托管 vs. 私有化部署、ANNS算法效率、metadata过滤能力、成本模型。
第三步:召回策略(Retrieval & Rerank)
用户发起会话时,Agent先把当前query过一遍Embedding,然后在向量库里做top-k相似度检索。关键参数:
-
top_k:取多少条相关记忆回来。设太小容易漏,设太大会往Context里塞一堆无关信息。经验值在3到8之间,通常根据当前Context剩余容量动态调整。 -
similarity_threshold:相似度低于多少就不召回。低于0.7的块通常语义相关性已经不可靠了,但产品知识库可以设高一点(0.75+),对话历史记忆可以适当放宽(0.65+)。 -
metadata_filter:这是生产级系统里最容易出问题的环节。召回时必须用metadata_filter把「当前用户的记忆」筛出来,而不是把全量用户的记忆都搅在一起。
import chromadb
from openai import OpenAI
client = chromadb.Client()
collection = client.get_collection("agent_memory")
def retrieve_relevant_memory(query: str, user_id: str, top_k: int = 5, budget: int = 2000):
embedding_model = OpenAI()
query_vector = embedding_model.embeddings.create(
model="text-embedding-3-small",
input=query
).data.embedding
results = collection.query(
query_embeddings=[query_vector],
n_results=top_k,
where={"user_id": user_id}, # 多用户隔离核心
include=["documents", "metadatas", "distances"]
)
filtered = [
(doc, meta, dist) for doc, meta, dist
in zip(results['documents'], results['metadatas'], results['distances'])
if dist < 0.3
]
total_tokens = 0
selected = []
for doc, meta, dist in filtered:
doc_tokens = len(doc) // 4
if total_tokens + doc_tokens <= budget:
selected.append(doc)
total_tokens += doc_tokens
return selected
面试里经常被追问的细节 :召回的memory是怎么注入到Context里的?
不是简单append,而是通常采用「注入Instruction + 召回片段」的形式:"Based on the user's long-term preferences retrieved below, consider them when responding: [召回片段]"。
召回的时机通常不是每次用户输入都走一遍向量检索——那样成本太高。通常策略是「关键词触发 + 会话阶段判断」。比如用户说「继续上次的合同」,这里「合同」就是触发词。
Context Window 截断策略:保留 System Prompt + 最近 N 轮
三层记忆架构是骨架,而Context Window的截断策略才是让这套骨架真正运转起来的执行层。
截断策略的核心原则只有一条:System Prompt必须完整保留,在此基础上优先保留最近 N 轮对话,溢出部分要么推给Summary Buffer,要么丢弃 。
为什么System Prompt必须完整?因为它包含Agent的行为定义、工具Schema、安全策略——这些是Agent之所以是「这个Agent」的根本。
截断System Prompt等于把Agent本身截没了。
「最近 N 轮」通常和Working Memory的max_turns联动:剩余容量R = ContextLimit - A - B - C,N = R / avg_tokens_per_turn。
但这只是静态估算,真正难的是动态调整 ,因为每轮对话的Token消耗波动很大。
Token 预算实时监控与动态调整
Token预算监控不是一个「隔几轮打印一次token_count」这么简单的事情。它是一个需要贯穿整个请求生命周期的机制,分三个阶段:
请求前(Pre-request) :在每次发送请求前,先估算本次请求的总Token消耗。如果剩余预算低于某个安全阈值,就提前触发Summary压缩。请求中(In-request) :在System Prompt里注入「预算感知指令」——比如"If the conversation history exceeds 60% of your context window, prioritize the most recent 8 turns"。
这种方式本质上是让模型自己管理信息密度。
请求后(Post-request) :精确统计本次请求实际消耗的Token数,更新Working Memory的token_count。
如果发现某次工具返回超常,立即触发一次针对性的截断或Summary。
动态调整策略通常有两种:预防式 (预算消耗达到80%时就提前压缩,保安全但可能过早)和响应式 (等塌了再截,信息密度更高但有丢信息风险)。
生产级系统通常用混合策略 :平时用预防式,在高价值会话里切到响应式追求信息密度,同时开启实时监控。
from dataclasses import dataclass
@dataclass
class TokenBudget:
context_limit: int = 128_000
system_prompt_tokens: int = 0
summary_tokens: int = 0
tool_schema_tokens: int = 0
safety_margin: float = 0.15
@property
def available_for_turns(self) -> int:
reserved = int(self.context_limit * self.safety_margin)
usable = self.context_limit - reserved
allocated = self.system_prompt_tokens + self.summary_tokens + self.tool_schema_tokens
return max(0, usable - allocated)
# 使用示例
budget = TokenBudget(
system_prompt_tokens=28_000,
summary_tokens=15_000,
tool_schema_tokens=20_000
)
print(f"当前可用容量:{budget.available_for_turns} tokens")
# 输出:当前可用容量:65,800 tokens
⚠️ 踩坑提醒 :Token计数一定要用该模型官方的tokenizer,不能用简单的「字数除以4」估算。
中文的实际tokenizer ratio通常在1.5到2.5之间,用固定除数估算会在长对话里积累严重误差。
建议直接调用tiktoken或该模型官方提供的tokenization API。
用户关键偏好的特殊处理:单独持久化,不参与压缩
这是整篇文章里最容易被候选人忽略、但生产环境里最容易出事故的一个设计原则。
为什么用户偏好不能走正常的Summary压缩?因为压缩是有损的。假设用户跟客服Agent说过一次「我住在五楼,没有电梯,收货时间要选工作日白天」。
这条偏好被Summary进Buffer之后,下次会话召回时可能已经被压缩成「用户有配送限制」,丢了「五楼无电梯」这个关键细节。
这类关键偏好的特点是:信息量不大,但准确度要求极高,丢失代价极大 。必须单独持久化。设计思路很直接:** 给用户偏好单独建一张表,完全绕过压缩管道** 。
class UserPreferenceStore:
def __init__(self):
self._preferences: dict[str, dict] = {}
def set(self, user_id: str, key: str, value: str, ttl_days: int = 90):
if user_id not in self._preferences:
self._preferences[user_id] = {}
self._preferences[user_id][key] = {
"value": value,
"updated_at": datetime.now(),
"expires_at": datetime.now() + timedelta(days=ttl_days)
}
def get(self, user_id: str, key: str) -> str | None:
pref = self._preferences.get(user_id, {}).get(key)
if pref is None:
return None
if datetime.now() > pref["expires_at"]:
return None
return pref["value"]
def merge_into_context(self, user_id: str) -> str:
active = {k: v["value"] for k, v in self._preferences.get(user_id, {}).items()
if datetime.now() <= v["expires_at"]}
if not active:
return ""
lines = [f"- {k}: {v}" for k, v in active.items()]
return f"[User Known Preferences]\n" + "\n".join(lines)
这张偏好表的数据量通常很小(几十KB撑死),注入Context的代价几乎可以忽略不计。
但它解决了一个核心问题:让Agent在每次会话开始时就能拿到用户的硬性约束,而不需要从对话历史里大海捞针 。
偏好变更必须同步写穿到偏好存储里,否则同一会话内偏好被改了两遍,第二遍就可能读到脏数据。
多用户会话隔离:session_id 唯一性保障与状态隔离
前面三章把单个会话内的记忆管理讲完了,但生产环境的真实问题是:一个 Agent 实例同时服务成百上千个用户,每个用户的上下文必须严格隔离 。
这不只是技术问题,这是合规底线——用户 A 的对话记录绝对不能泄漏给用户 B。
session_id 生成策略与唯一性保障
session_id 是多用户隔离的核心锚点,必须满足三个条件:全局唯一、不可推测、包含时间因子 。
最常用的是UUID v4,通过随机数生成,碰撞概率低到可以忽略不计。但它不包含任何业务语义,调试时看日志只能看到一串乱码。更工程化的做法是复合键策略 :
import uuid
from datetime import datetime
def generate_session_id(user_id: str) -> str:
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
random_suffix = uuid.uuid4().hex[:8]
return f"sess_{user_id}_{timestamp}_{random_suffix}"
# 示例输出:sess_u12345_20260511_084532_a1b2c3d4
这种格式的好处是:出现线上事故时,日志里扫一眼就能定位「哪个用户、哪一天、哪一秒创建的会话」。
对于高并发场景,单靠UUID生成还不够,还需要从存储层保证唯一性约束——如果用PostgreSQL,在session表上建UNIQUE索引;
如果用Redis,用SETNX做原子写入。
状态隔离的两种实现路径
路径一:按 session_id 隔离存储(Shared-nothing)
每个会话的状态完全独立存储,物理上没有共享数据。最常见的是给每个session_id建一张独立的Redis Hash或数据库表行。
class SessionStateManager:
def __init__(self, redis_client):
self.redis = redis_client
def _key(self, session_id: str, field: str) -> str:
return f"session:{session_id}:{field}"
def set_working_memory(self, session_id: str, data: dict):
self.redis.hset(self._key(session_id, "working_memory"), mapping=data)
self.redis.expire(self._key(session_id, "working_memory"), 1800)
def get_state(self, session_id: str) -> dict:
return {
"working_memory": self.redis.hgetall(self._key(session_id, "working_memory")),
"summary_buffer": self.redis.hgetall(self._key(session_id, "summary_buffer")),
}
这套设计的关键是所有状态访问路径都必须经过session_id ,不存在任何绕过session_id直接读全局状态的通道。
如果代码里有人写了global_working_memory[key] = ...,这就是一个严重的数据泄漏漏洞。路径二:租户隔离(Multi-tenant)
如果系统需要同时服务多个企业客户(toB场景),需要在session_id之上再加一层tenant_id隔离。
数据访问时必须同时验证tenant_id + session_id双因子。这已经超出了普通面试范围,但候选人主动提到通常能给面试官留下「考虑过更高阶问题」的印象。
三个高频踩坑点
踩坑一:session_id泄漏到日志但不脱敏 。
生产环境debug时经常需要看session_id关联的日志,但如果日志系统本身有权限控制缺陷,攻击者可以通过枚举session_id访问其他用户的会话数据。
正确做法是session_id在传输层用加密替代明文,日志里只存hash摘要。踩坑二:会话状态不清理导致内存泄漏 。
一个用户创建了会话但关掉了App,状态一直留在Redis里不释放。高并发场景下,几万个僵尸会话能把内存撑满。解法是给每个会话状态加TTL,配合定期巡检任务清理过期会话。
踩坑三:误用全局变量缓存用户状态 。比如写了个current_user_cache: dict这样的模块级变量,多线程并发时用户A可能读到用户B的缓存数据。
在Python里因为GIL的存在可能不立刻暴露,但在异步I/O环境下几乎是必然复现的bug。
典型面试追问路径与项目落点
追问路径:从概念到深挖
追问一(入门级) :你刚才说三层记忆,能具体讲讲这三层的数据格式分别是什么?
好的回答要能说清楚:Working Memory是内存里的Python字典,Summary Buffer是文本摘要列表,External Memory是向量数据库里的Embedding向量。
还要补充一句:「三层之间的数据格式不一样,层间传递需要序列化/反序列化,这里也是常见的bug来源。」
追问二(进阶级) :如果向量检索召回的结果质量很差,你会怎么排查?
好的候选人不会只说「调Embedding模型」。
排查路径应该是:先看top_k召回的相似度分数阈值设置,再看Embedding模型和查询文本的语言/领域是否匹配,然后检查向量数据库的索引构建质量(有没有用合适的HNSW或IVF参数),最后才看重排序策略是否有效。
追问三(进阶级) :Summary的质量怎么评估?你有什么客观指标吗?
候选人可以提到几个方向:一是自动评估——用另一个模型对Summary做「可复原性测试」;二是人工抽样评估——定期抽样5%的Summary由人工审核关键实体有没有丢失;
三是业务指标关联——观察用户是否在短时间内重复同一个问题(提示Summary可能丢掉了关键信息)。
追问四(高级) :设计一个完整的AI Agent记忆系统,包括数据量和并发量,给出你的具体技术选型。
候选人需要能够快速给出架构图:Working Memory用Redis Hash;Summary Buffer用PostgreSQL JSONB;
External Memory用Qdrant或Milvus;Token预算管理用Python类内嵌计算逻辑。
给这些决策时,最好能说一两个trade-off,比如「选Redis是因为并发量还没到需要分布式缓存的量级」。
项目落地:怎么把「理论」变成「做过」
面试里最有说服力的表达方式是这样的:
「我的项目里遇到过一个具体问题:用户会话超过20轮之后,模型的回答质量开始明显下降。我排查后发现是Context截断策略只保留了最近10轮,但用户前面提过的关键偏好被截丢了,导致模型行为前后矛盾。后来我改成了保留System Prompt + 全部Summary + 最近6轮的结构,配合tiktoken实时监控Token消耗,把回答质量下降的问题修掉了。」
这段描述有具体的数字 (20轮、10轮、6轮)、具体的根因 (截断丢掉了偏好)、具体的解法 (结构重组 + 实时监控)和具体的验证 (回答质量不再下降)。
面试官一听就知道这不是背概念,而是真的从问题里摸爬滚打过来的。
「选向量库而不是简单存文件的原因是:我们的用户历史对话平均长度是5万字,直接全文召回每次请求会超Context,但向量检索可以在200毫秒内从50万条历史记录里精准召回3条相关内容。
」
易错边界与常见误区清单
误区一:把Summary当成长期记忆 Summary Buffer本质上还是内存中的压缩文本 ,真正的长期记忆是External Memory里经过向量化的语义存储,两者检索方式完全不同。
中文的实际Token ratio在1.5到2.5之间,不同模型的分词器实现不同。生产环境里必须用对应模型官方提供的tokenization API,不能靠经验公式。
如本文第二章所述,用户关键偏好必须单独持久化,不参与任何有损压缩。
如果候选人说「偏好反正不多,就跟对话一起Summary了」,面试官会立刻追问「万一压缩丢了一个字,用户地址变了,你怎么处理」。
误区四:session_id用递增整数 问题有两个:一是session_id可推测,攻击者可以通过枚举ID尝试访问其他用户的会话;二是多实例部署时自增键需要中心化协调。正确做法是用UUID或复合键。
误区五:Context截断时把System Prompt也一起截掉 System Prompt决定了Agent的身份、行为约束和核心能力,截断时无论如何必须保留。如果描述的截断策略是「从头开始删,删到预算够为止」,这是严重的架构缺陷。
用户通过对话修改了偏好设置,Working Memory里更新了,但偏好存储没有同步更新。下一轮对话里Agent读到的是旧的偏好值。
解法是偏好写入必须同时更新Working Memory和持久化存储。
实际上Context管理是一个需要持续监控的运行时问题:用户对话长度会随季节变化,模型版本更新会导致Token消耗分布变化,新功能上线可能导致某个工具返回超长结果。
生产级系统必须有Token消耗监控告警和定期Review截断阈值的机制。
参考文献
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

