

流程能复制,人就会被重新估价
今天鸭鸭在脉脉上看到一条挺扎心的讨论。
一个 5 年后端发帖说,公司里有个外包同事能力特别强,手搓了一套 AI Coding 标准流程。
结果这套东西被正编拿去汇报了。
发帖人真正无语的地方在后半句:想到这个最终会成为干掉我们的工具。
这条帖子页面里能看到的互动是 4 个分享、28 条评论。
看着数字不算大,但评论区的味儿很真。
“AI 会不会先替代外包?”
“流程都被沉淀完了,普通程序员还剩什么?”
“以后公司会不会先砍最容易标准化的人?”
鸭鸭一开始以为大家会集中骂正编抢成果。
结果往下看,评论区比这个狠多了。
华为员工,留了一句:
正编抢成果怎么这么熟练

网易游戏员工,说得更直接:
这外包太蠢了,ai一旦融入工作流太深,高层的刀就会无情的砍

哔哩哔哩员工,也跟了一句:
外包是闲的没事干么,非要自掘坟墓
剩下几条鸭鸭只做归纳:有人主张直接举报,也有人说自家团队也搞过类似流程,真正落地时没那么顺。
所以这事的情绪很复杂。
有人觉得成果被抢很恶心。
有人觉得外包太天真。
也有人已经开始想,自己团队里那套 AI 流程,哪天会不会反手变成裁员理由。
鸭鸭看完最不舒服的点在这里:
公司开始把你的经验,当成一套可以复制的流程资产来重新定价。
以前一个程序员值多少钱,多少还看经验、判断、扛事能力。
现在一旦你把经验拆成流程,公司就会多问一句:这套东西换个人能不能跑?
能跑,就麻烦了。
因为很多公司现在盯的,已经不是你会不会写代码。
它们更关心代码生产这件事能不能拆细。
拆到新人能接。
拆到工具能接。
拆到更便宜的人也能接。
这跟超市上自助收银有点像。
刚开始大家都说,这是帮收银员少干点重复活。
等流程跑顺了,老板就会站在旁边算账:原来 4 个人排班,现在 2 个人能不能撑住。
这才是 AI Coding 最让打工人发凉的地方。
鸭鸭拆开说几句。
第一层,很多程序员暴露在公司面前的价值,太容易被流程化了。
接口写完,测试跑通,文档补齐。
这些当然重要,但它们都能被拆成步骤。
一旦拆成步骤,评价标准就会变。
公司原来问你这个人强不强。
后来问这套步骤换个人能不能跑。
这两句话听起来差不多,背后的工资差很多。
第二层,真正值钱的经验,经常藏在流程外面。
需求为什么这么拆。
AI 生成的代码为什么看起来能跑,上线却大概率会炸。
一个方案技术上可行,业务上为什么不能推。
这些判断短时间内很难交给 SOP。
但尴尬的是,很多人平时最容易展示给公司的,恰好是那些最容易被 SOP 吃掉的产出。
第三层,也是这条帖子最扎心的地方。
团队为了提效,把能模板化的地方全标出来了。
大家本意可能只是少写点重复代码,早点下班。
结果公司顺手看见了哪些活能被工具接走,哪些人可以被重新安排。
嗯。
这就很打工人。
那普通程序员该怎么办?
鸭鸭觉得先别急着喊口号。
第一件事,把简历里的“做过什么”,往“为什么这么做”上挪。
以后面试里真正拉开差距的,可能就是你能不能讲清楚一段 AI 代码背后的取舍、风险和边界。
工具会越来越像标配。
判断力才会越来越像门槛。
第二件事,流程该沉淀还是要沉淀,但别把自己的全部价值都交出去。
哪些是团队资产,哪些是你自己的护城河,心里要有数。
如果你留下的只有一份任何人照着都能跑的 SOP,公司记住的往往就只剩那份 SOP。
第三件事,平时多积累一点决策型证据。
比如砍掉过什么无效方案。
比如兜住过什么线上风险。
比如 AI 介入以后,你补上过哪些人工判断。
这些东西不好写进周报,但面试和晋升的时候很顶用。
AI Coding 真正吓人的地方,是它让公司第一次这么具体地看见,哪些岗位早就可以重新定价。
如果你们团队也在推 AI Coding 流程,你最担心它最后被谁拿去用?评论区聊聊
……
今天鸭鸭和大家分享一道 AI 大模型面试题。
【如何判断微调效果是否达到预期? 】
回答重点
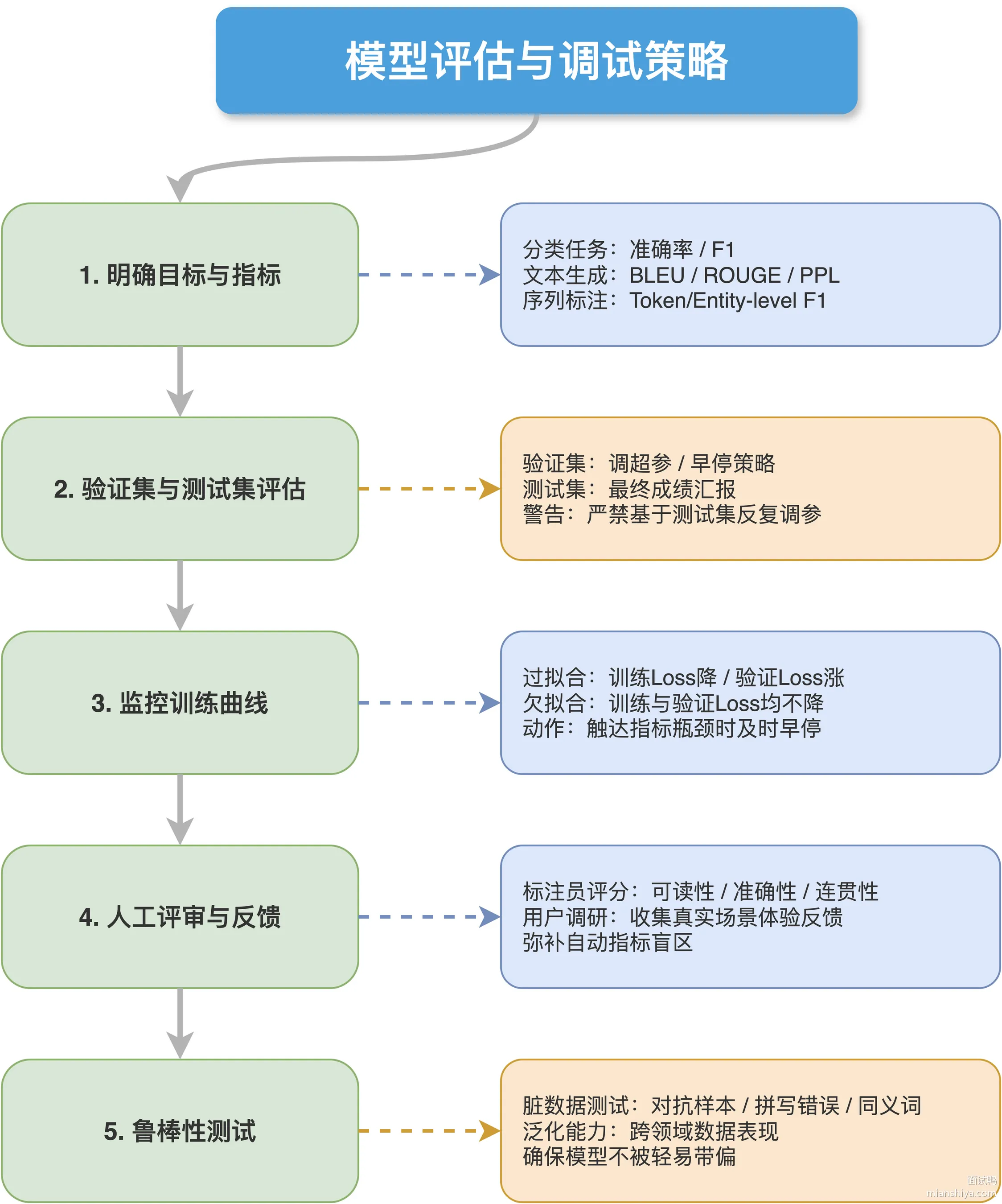
判断微调效果是否达标,核心是多维度验证:量化指标看数字、人工评审看体验、训练曲线看趋势、线上 A/B 看业务。单靠一种方式都不靠谱,得组合起来才能下结论。
1)明确任务目标并对齐评价指标。不同任务指标不一样:分类任务看准确率、F1;文本生成看 BLEU、ROUGE、Perplexity;序列标注看 token-level 或 entity-level 的 F1。指标选错了,后面评估全白搭。
2)在验证集和测试集上跑量化评估。验证集用来调超参和做早停,测试集留到最后报最终成绩。千万别拿测试集反复调参,不然成绩虚高,上线就翻车。
3)盯紧训练曲线。训练 loss 一直降但验证 loss 开始涨,那就是过拟合了;两条线都降不下去,那是欠拟合。配合早停策略,在验证指标不再提升时及时收手。
4)人工评审和用户反馈。让标注员按统一标准给输出打分,看可读性、准确性、连贯性这些自动指标抓不到的东西。有条件的话再搞个小规模用户调研,收集真实体验反馈。
5)鲁棒性测试。拿对抗样本、同义词替换、拼写错误这些"脏数据"去试,看模型会不会被轻易带偏。还要测不同领域的数据,确保泛化能力够用。
扩展知识
量化指标怎么选
不同任务对应的指标差别很大,选错了等于白评估。
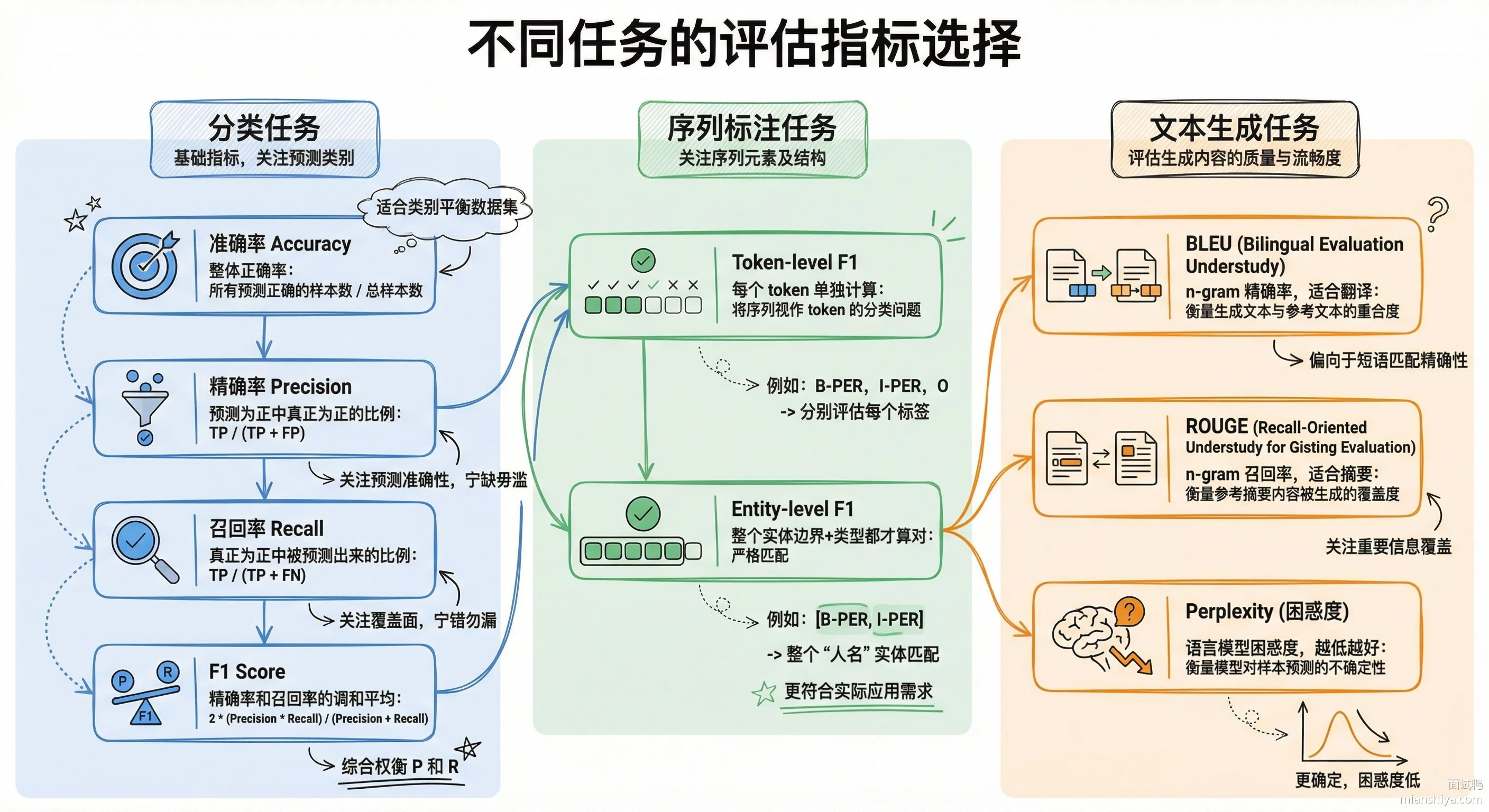
分类任务最常用的是准确率、精确率、召回率和 F1。准确率看整体对了多少,但在样本不均衡的时候会骗人,比如 95% 是负样本,模型全猜负也能拿 95% 准确率。这时候得看 F1,它综合了精确率和召回率,更能反映真实水平。
序列标注任务比如 NER,一般用 entity-level F1,也就是整个实体边界和类型都对才算对。token-level F1 会宽松一些,但容易高估性能。
文本生成任务指标更多样:BLEU 主要看 n-gram 重叠度,适合翻译;ROUGE 侧重召回,适合摘要;Perplexity 衡量语言模型对文本的困惑程度,越低越好。但这些自动指标跟人类感知的差距不小,所以生成任务一般还得配人工评估。
训练曲线怎么看
训练过程中最值得关注的是训练 loss 和验证 loss 的走势对比。
正常情况下,两条线应该同步下降,验证 loss 稍微高一点但差距稳定。如果训练 loss 持续降,验证 loss 却开始往上走或者不再降,那就是过拟合的信号,模型在死记硬背训练数据。这时候要么加正则化、dropout,要么用早停策略在验证指标最好的时候停下来。
另一种情况是两条线都降不下去,那就是欠拟合,模型容量不够或者学习率太小。可以试试加大模型、调高学习率、增加训练轮数。
实际操作中,早停是最常用的防过拟合手段。设一个 patience 参数,比如连续 5 个 epoch 验证指标不提升就停止,然后把指标最好的那个 checkpoint 拿来用。
人工评估怎么做
自动指标能快速给出数字,但跟人类真实感知的差距往往不小,尤其是生成类任务。
人工评审一般找 3-5 个标注员,用统一的评分标准对模型输出打分。常见维度包括:流畅性(读起来通不通顺)、准确性(内容对不对)、相关性(跟问题相不相关)、连贯性(上下文衔接自不自然)。打完分算个平均或者加权,还要算标注员之间的一致性,一致性太低说明标准不够清晰。
更进一步可以做 A/B 测试:把新模型和旧模型的输出混在一起让人盲选,统计用户更偏好哪个。这种 pairwise comparison 比直接打分更能反映相对优劣。
线上验证不能少
模型离线评估再好看,也得上线跑真实流量才知道行不行。
常见做法是 A/B 测试,把 5%-10% 的流量切给新模型,对比业务指标。比如对话系统看会话完成率、用户满意度评分;推荐系统看点击率、转化率;搜索系统看首条点击率、跳出率。如果新模型在这些业务指标上有显著提升,才算真正验证成功。
上线之后还要持续监控,看模型性能会不会随时间衰减。用户行为、数据分布都在变,模型可能慢慢跟不上,这时候就要考虑定期重训或者增量更新。
篇幅有限,更多 AI 大模型 相关面试题可以进入面试鸭进行查阅
