

拆解 Agent Harness 如何用工具循环、外置状态和 Hook,让模型真正变成可靠交付系统。 原文链接:AI 小老六
导语
评估一个 Coding Agent,很多人会先盯模型:是不是换了更大的权重、推理链是不是更长、上下文窗口是不是更宽。但真实工程里经常出现另一种情况:模型没变,Agent 的表现却像换了一代产品。
原因不在模型参数里,而在模型外面那层运行系统里。它决定模型能看到什么上下文、能调用什么工具、在什么环境里执行命令、失败后如何被纠正、长任务跑偏时谁来把它拉回来。Addy Osmani 把这层系统称为 Agent Harness Engineering。用一句工程化的公式概括就是:
agent = model + harness
这个等式的含义并不抽象。Terminal Bench 2.0 上已经出现过很有说服力的案例:同样的模型、同样的任务和预算,只调整 harness,Coding Agent 的排名可以从 Top 30 拉到 Top 5。换句话说,**Agent 的差距并不总是来自“模型聪不聪明”**,更多时候来自“模型被怎样接入真实工作流”。
本文不把 Harness 当成一个流行词来解释,而是把它拆成一套可落地的运行时架构:工具循环、状态持久化、执行沙箱、记忆检索、确定性 Hook、长程任务调度,以及正在形成的 Harness-as-a-Service 趋势。
图:Harness 像模型外壳,把推理能力接入工具、状态、约束和真实工作流。
Harness Runtime:模型之外的执行外壳
一个 Agent 不是“会说话的模型”,而是“模型被放进一个可以行动的系统”。这个系统最小也要包含三个东西:目标、工具、循环。
Simon Willison 对 Agent 有一个极简定义:Agent 是一个为了达成目标而在循环中使用工具的系统。这个定义听起来朴素,却正好把 Harness 的职责说清楚了:模型负责推理下一步,Harness 负责把“下一步”变成可执行、可观测、可纠偏的动作。
可以把 Harness Runtime 看成下面这几层:
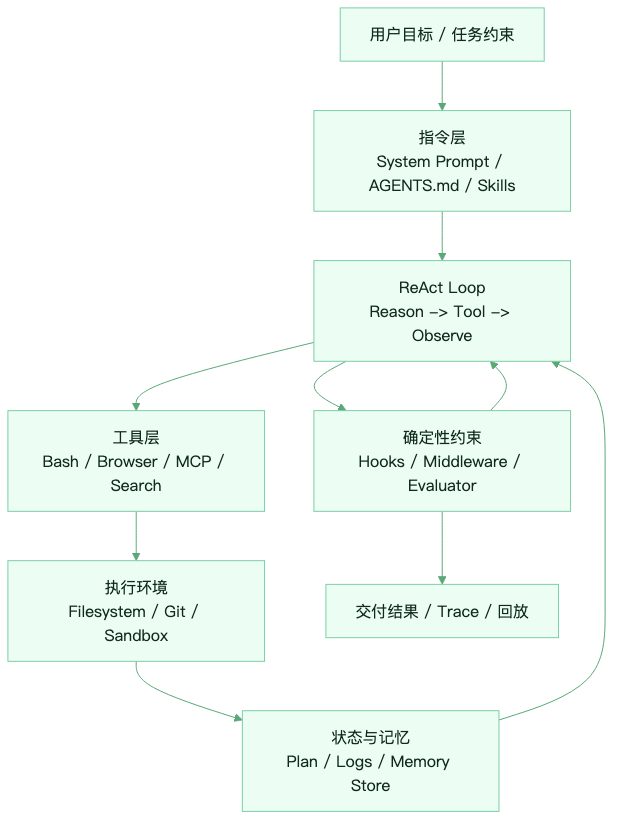
图:Harness Runtime 把目标、工具、环境、状态和约束串成可执行闭环。
这张图里,模型只占 Loop 中的推理部分。真正决定 Agent 行为边界的,是外面这些工程组件:
| Harness 层级 | 负责的问题 | 常见实现 |
|---|---|---|
| 指令层 | 让模型理解角色、边界、项目规则 | System Prompt、AGENTS.md、CLAUDE.md、Skill 描述 |
| 工具层 | 把推理结果接入真实世界 | Bash、文件编辑、浏览器、MCP Server、搜索 |
| 环境层 | 让工具调用有安全边界 | Sandbox、权限审批、网络隔离、默认 CLI |
| 状态层 | 让任务跨轮次、跨会话延续 | Plan 文件、日志、Git 分支、Memory Store |
| 约束层 | 把“应该做”变成“必须做” | PreToolUse、PostToolUse、Stop Hook、Reviewer Agent |
| 观测层 | 让失败可复盘、可迭代 | Trace、Token/Cost 统计、Session Replay |
这也是为什么 “换模型” 和 “改 Harness” 会产生完全不同的工程收益。换模型改变能力上限,改 Harness 改变模型能把上限发挥到什么程度。
失败归因:别急着把锅甩给模型
Agent 一旦翻车,最容易出现的判断是:“模型还是不够强,等下一代吧。”这个判断有时成立,但在工程现场经常过早出现。
HumanLayer 在讨论 Coding Agent 时提出过一个很刺耳的反转:这不是模型问题,而是配置问题。它的意思不是替模型开脱,而是提醒工程师先检查自己能控制的那部分:
- Tool description 是否让模型知道什么时候该用、什么时候不该用?
- System Prompt 与项目规则是否互相冲突?
- 文件系统里的计划、日志和中间产物是否足够清晰?
- Hook 是否在背后拒绝了工具调用,但错误没有被模型看见?
- Reviewer 或 Evaluator 是否真的独立于生成者,而不是让 Agent 自己宣布成功?
这类问题都发生在 Harness 层。它们不会因为模型多几个百分点的 benchmark 分数自动消失。
更关键的是,归因方式会改变团队文化。如果团队默认“模型不行”,工程动作就只剩等待。如果团队默认“先查 Harness”,今晚就能动手:重写一个工具描述、把一条项目纪律挪进 Hook、把超长工具输出落盘、给长任务补一个 plan 文件、把自评改成外部 Judge。
Harness Engineering 的价值就在这里:它把不可控的“等模型升级”,拆成一组今天就能改的工程对象。
Ratchet 机制:让每次失败沉淀成约束
好的 Harness 不靠灵感堆配置,而靠失败推动演进。Addy Osmani 对 AGENTS.md 有一个很硬的标准:好的规则文件里,每一行都应该能追溯到一次具体失败。
这句话可以转成一个更可操作的 Ratchet 机制。Ratchet 是棘轮,只允许系统向一个方向积累改进。放到 Agent Harness 里,它有两层含义。
第一层是新增约束。只有真实事故发生后,规则才进入 Harness。比如 Agent 曾经提交过被注释掉的测试,那下一版 Harness 不应该只在文档里提醒一句,而应该至少建立三道防线:
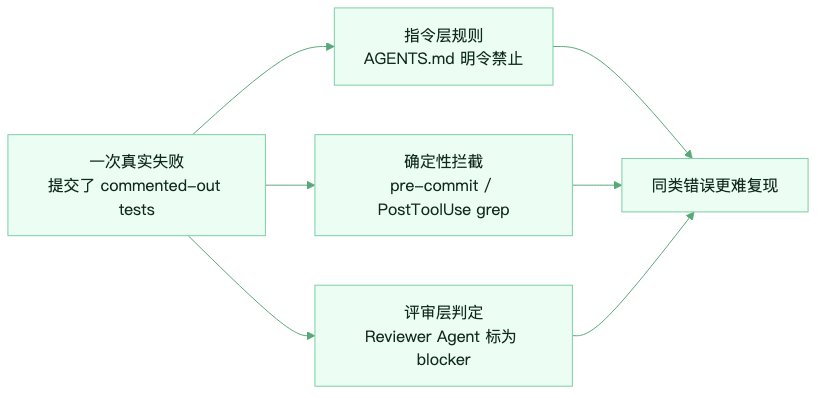
图:一次真实失败会同时沉淀为规则、Hook 和评审标准。
第二层是删除过时约束。模型变强以后,一些旧 scaffolding 可能不再需要。比如早期为了防止模型在上下文剩余 30% 时焦虑收尾,很多 Harness 会写大量提醒;当新模型已经稳定处理这个问题,就应该删掉这些噪音。Harness 不是配置垃圾抽屉,不能只增不减。
所以 Ratchet 不是“规则越多越可靠”,而是“每条规则都有事故来源,并且经得起继续存在的测试”。这让 Harness 从提示词收藏夹变成一个会进化的工程系统。
状态外置:Filesystem、Git 与 Memory 的真实职责
很多人会把 Agent 的记忆想象成 Context Window。这个理解只对了一小半。Context 能承载当前轮对话,却不适合作为长任务的状态仓库。
真正可靠的状态通常在模型外面。
Filesystem 是第一层外置状态。计划文件、调试日志、工具输出快照、子任务交接摘要,都应该写到磁盘上。这样即使上下文被压缩、会话被重启,任务仍然可以从文件恢复。
Git 是第二层外置状态。它提供版本化、分支、回滚和审计。Agent 在独立分支或 worktree 中探索,失败可以回滚,成功可以合并。对长任务来说,Git 不只是代码管理工具,还是 Agent 行为的安全带。
Memory Store 是第三层外置状态。AGENTS.md 和 CLAUDE.md 适合放静态规则,但不适合放动态事实。客户偏好、历史 bug 修复路径、某个服务的运行经验,更适合进入 KV、向量库或结构化 Markdown 树。它们解决的是“跨会话事实记忆”,而不是“本轮提示词补丁”。
再往外,还需要 Search 和 MCP 处理训练截止日之后的信息。模型知道的是过去,工程任务面对的是今天。把搜索、内部知识库、API 文档查询接进 Harness,是为了避免模型用旧事实回答新问题。
可以把状态外置理解成一条原则:凡是不应该随着 Context 被截断而消失的信息,都不要只放在 Context 里。
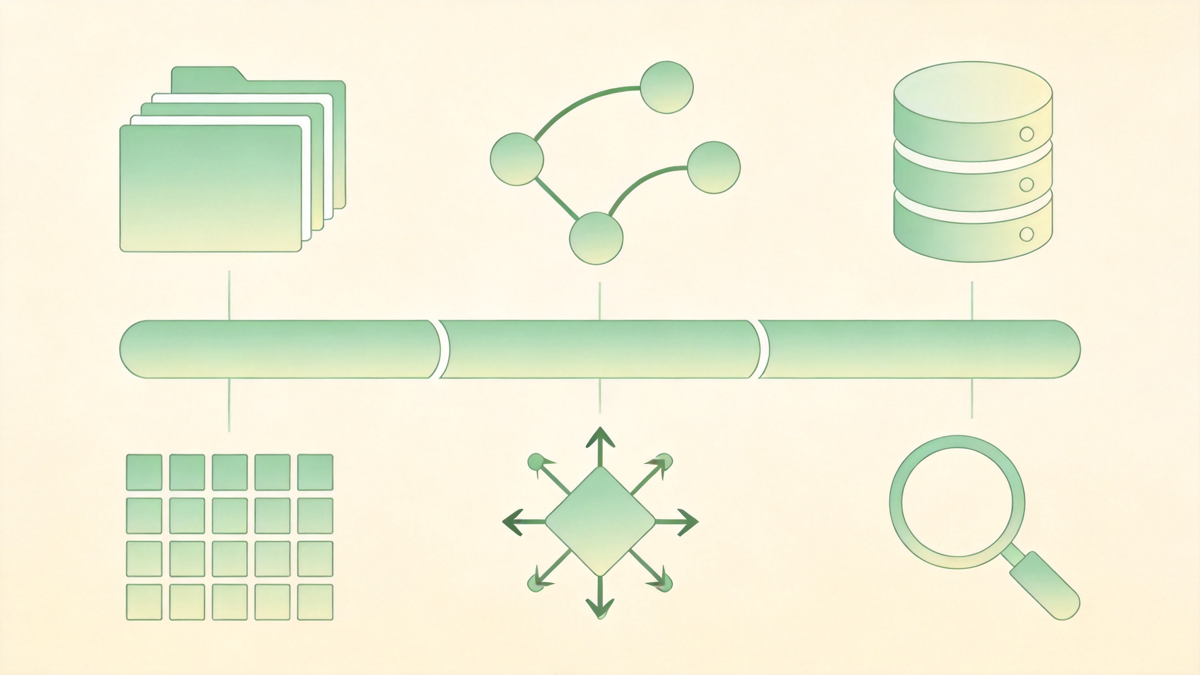
图:长程任务的关键状态应沉淀到文件系统、Git 和记忆库,而不是只留在 Context 里。
Bash 与 Sandbox:通用能力必须配安全边界
设计工具层时,很多团队会先走向“为每种动作定义一个专用 Tool”。这条路很安全,也很快变得笨重。真实任务里的需求太碎:查日志、改 JSON、跑测试、抓网页、批量替换、临时分析数据。专用工具很难盖住所有场景。
因此,现代 Coding Agent 越来越倾向于给模型一个强通用工具:Bash。
Bash 的价值 不是“让模型执行命令”这么简单,而是让模型可以临时组合工具。rg 查找、jq 解析、curl 请求、语言测试 CLI 验证、headless browser 跑页面,这些动作不用每个都包装成独立 API。很多复杂任务最后都会坍缩成几条设计良好的 CLI 调用。
但 Bash 的风险也同样明显。给 Agent 通用执行能力,就必须同时给它安全边界:
| 能力开放 | 对应边界 |
|---|---|
| 允许 Shell 执行 | 危险命令拦截、审批流、命令审计 |
| 允许读写文件 | 项目目录隔离、敏感路径 deny-list |
| 允许联网 | 默认禁出网,按域名或任务白名单开放 |
| 允许安装依赖 | 临时容器、缓存隔离、依赖来源检查 |
| 允许并行任务 | worktree 隔离、文件锁、冲突检测 |
这里有一个重要的产品判断:默认工具链应该由 Harness 准备,而不是让模型临场配置。Git、ripgrep、语言测试工具、jq、yq、浏览器自动化、包管理器,这些东西应该在执行环境里预装。模型不应该把时间花在“先装一个 rg”上。
通用工具让 Agent 能干,Sandbox 让它不至于失控。两者缺一不可。
Hook Runtime:把偏好变成确定性纪律
Prompt 可以表达偏好,但不能保证执行。Hook 的价值,是把一部分“请记得”改成“系统会强制”。
在 Agent 生命周期里,Hook 可以插在多个关键点:
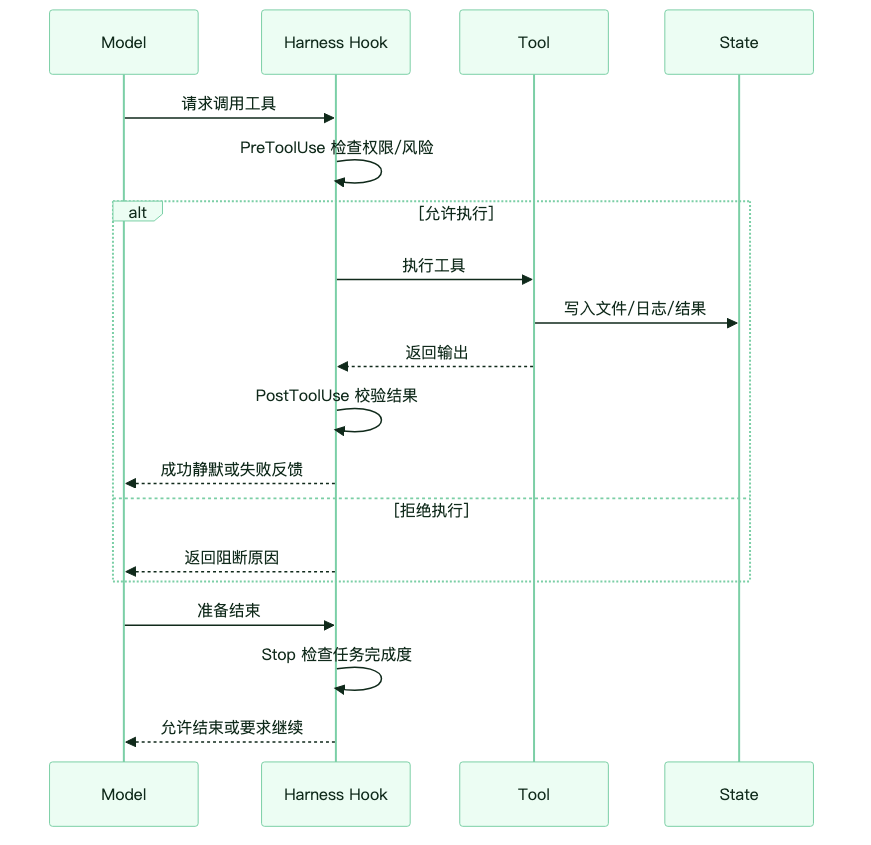
图:Hook 在工具调用前后和任务结束前提供确定性校验。
Hook 的设计精神可以概括成一句话:成功静默,失败喧哗。
比如 Edit/Write 后自动跑 typecheck。通过时不返回任何信息,避免污染 Context;失败时把错误塞回下一轮,让模型必须修。这样你就不需要在 CLAUDE.md 里反复写“改完代码记得跑类型检查”。这条纪律已经从提示词变成运行时逻辑。
一个典型的 PostToolUse 配置可以长这样:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write|MultiEdit",
"hooks": [
{
"type": "command",
"command": "cd $CLAUDE_PROJECT_DIR && pnpm tsc --noEmit 2>&1 | head -50"
}
]
}
]
}
}
PreToolUse 可以拦截危险 Bash 命令,Stop Hook 可以在模型宣布完成前检查 todo、测试、未提交变更和交付物。Hook 的位置越靠近执行链路,规则就越不依赖模型“记性”。
这也是 Harness 和 Prompt 的分界:能用确定性逻辑约束的,不要只写进提示词。
Long-Horizon Execution:长任务靠外部状态与独立判定续航
长程任务是 Harness 能力的试金石。单轮问答可以靠模型聪明,跑几十分钟甚至几小时的任务则会暴露三个问题:
- Context 装不下完整过程,压缩会损失细节。
- 模型容易把“当前阶段完成”误判为“整个任务完成”。
- 子任务之间缺少交接协议,信息在 Agent 间漂移。
解决这些问题,需要同时处理 Context 和调度。
Context 侧有三种常用战术。
第一是 Compaction,把旧上下文压缩成摘要。但压缩有损耗,连续压缩会让任务慢慢失真。更稳的做法是把关键状态写入 handoff 文件,然后在必要时重启会话,让新 Context 从磁盘恢复。
第二是 Tool-call Offloading。工具输出不应该无脑塞进 Context。几千行日志、完整网页、巨型目录树,都应该落盘;Context 里只保留摘要、路径和可继续查询的线索。模型需要细节时,再用 rg 或 Read 精确取片段。
第三是 Progressive Disclosure。能力不应该全部预置进 System Prompt,而应该按需加载。Skill 体系的核心价值就在这里:启动时只暴露 name 和 description,命中任务后才加载完整说明、脚本和引用材料。
调度侧则要避免“自我宣布胜利”。可以用三种机制兜底:
| 调度机制 | 解决的问题 | 实现方式 |
|---|---|---|
| Plan-then-Act | 防止任务在多轮执行中丢目标 | 先写 plan 文件,完成一项勾一项,新增依赖及时追加 |
| Ralph Loop | 防止模型过早退出 | Stop Hook 拦截 exit attempt,用干净 Context 重读状态继续 |
| Planner / Generator / Evaluator 分离 | 防止生成者自评偏乐观 | 规划、执行、判定完成由不同角色或不同 Agent 承担 |
这里最重要的是 Evaluator 独立。写代码的 Agent 往往天然倾向于说“已经好了”。更可靠的方式是在开工前定义 sprint contract:哪些测试必须通过、覆盖哪些边界、交付物长什么样。最后由独立 Judge 对照合同验收。
长任务不只需要更大的 Context,更需要更清晰的外部状态、更硬的退出条件和更独立的完成判定。
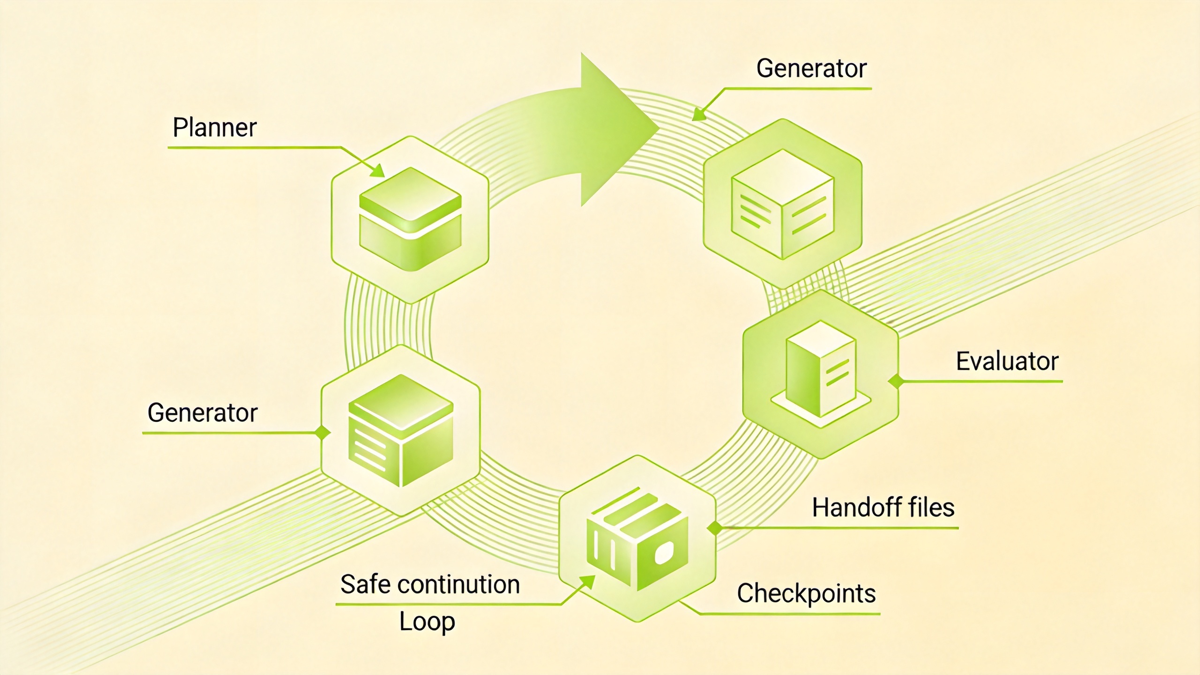
图:长任务要靠计划、执行和独立评估组成闭环,避免 Agent 过早宣布胜利。
Skill 与 Hook:普通工程师最容易动手的两个入口
如果把 Harness 拆到日常可操作层面,普通工程师最值得先抓两类东西:Skill 和 Hook。
Skill 解决“Agent 能做什么”。它把领域能力封装成按需加载的能力包,而不是把所有知识都塞进主提示词。一个好的 Skill,description 比正文更关键,因为它决定触发面:写得太窄,模型永远想不起它;写得太宽,它会在不该出现时污染任务。
Hook 解决“Agent 必须怎么做”。它把类型检查、危险命令拦截、提交前验证、结束前复核这些纪律放进运行链路。模型不需要记住纪律,Harness 会在对应时刻执行纪律。
两者分别对应 Harness 的两个方向:
| 入口 | 本质 | 典型问题 |
|---|---|---|
| Skill | 能力的渐进式披露 | 这个任务需要哪组领域知识、脚本和流程? |
| Hook | 纪律的确定性执行 | 哪些规则不能依赖模型自觉? |
每新建一个 Skill,都是在告诉 Agent“遇到这类任务时,你可以调用这组外部能力”。每挂一个 Hook,都是在告诉 Agent“到了这个生命周期点,这条规则必须执行”。这两类改动看起来像配置,实际上是在改 Agent 的运行时行为。
Harness-as-a-Service:外壳正在成为工业品
早期做 Agent,团队往往从 LLM completion API 开始,自己搭 loop、写 tool calling、维护上下文、做权限审批、补日志回放。每个团队都在重造同一套底座。
现在趋势变了。Claude Agent SDK、Codex SDK、OpenAI Agents SDK 这类产品,正在把 Harness 的一部分能力服务化:循环、工具注册、上下文管理、子 Agent、审批流、Trace,都逐渐变成可配置的运行时能力。
这就是 Harness-as-a-Service。它卖的不是模型,也不是传统 SaaS,而是一组默认工程决策:
- Agent Loop 怎么跑?
- 工具如何注册、过滤和裁剪结果?
- 子 Agent 如何创建、交接和回收?
- Context 什么时候压缩,什么时候重启?
- 权限审批如何进入执行链路?
- Trace 如何记录,失败如何回放?
HaaS 的价值是把 v0.1 成本摊平。团队不必从零写一个能跑的循环,而是拿到一个已经可用的底座,把精力放到领域 Harness 上:业务工具、项目规则、评测指标、数据权限和组织知识。
但这不意味着 Harness 会消失。模型变强后,旧约束会减少,新的约束会出现。过去我们不信任模型记得跑测试,于是写 Hook;未来我们可能不信任模型能协调多个 Agent 同改一个仓库,于是写 worktree 调度和冲突仲裁。Harness 不会变薄,它只会把边界移动到更高层。
结语
Agent 的能力上限由模型决定,但实际表现往往由 Harness 决定。模型是发动机,Harness 是传动、刹车、仪表盘、导航和安全笼。发动机再强,如果外壳不能把动力稳定传到真实任务上,结果依然会失控。
对普通工程师来说,这反而是好消息。模型训练不在多数团队手里,但 Harness 在。你可以今天就改一条工具描述、删掉一条过时规则、把长日志落盘、给任务加 plan 文件、把类型检查搬进 Hook、把领域流程封装成 Skill。
这些动作看起来细碎,却共同决定 Agent 是否能从“会回答”走向“能交付”。所谓 Harness Engineering,就是承认模型之外还有一整套工程系统,并且认真打磨它。
模型由实验室推进,Harness 由工程现场推进。真正能让 Agent 在具体任务里变可靠的,往往正是这层“模型之外的全部”。
