

上期我们聊了“强模型导师模式”:用一个能力更强的大模型做导师,负责拆解、判断、纠偏和验收;再让 DeepSeek 这类执行模型去推进具体任务。
这期想把这个模式再往实战里推进一步。
很多人真正关心的不是“多个模型怎么分工”这个概念,而是一个更具体的问题:当 DeepSeek 执行任务时卡住了,甚至给出了一个看起来合理、但实际并不准确的结论,强模型导师到底怎么把它带回来?
这次我们用一个真实案例讲清楚。
问题不是“不会做”,而是容易停在表面原因
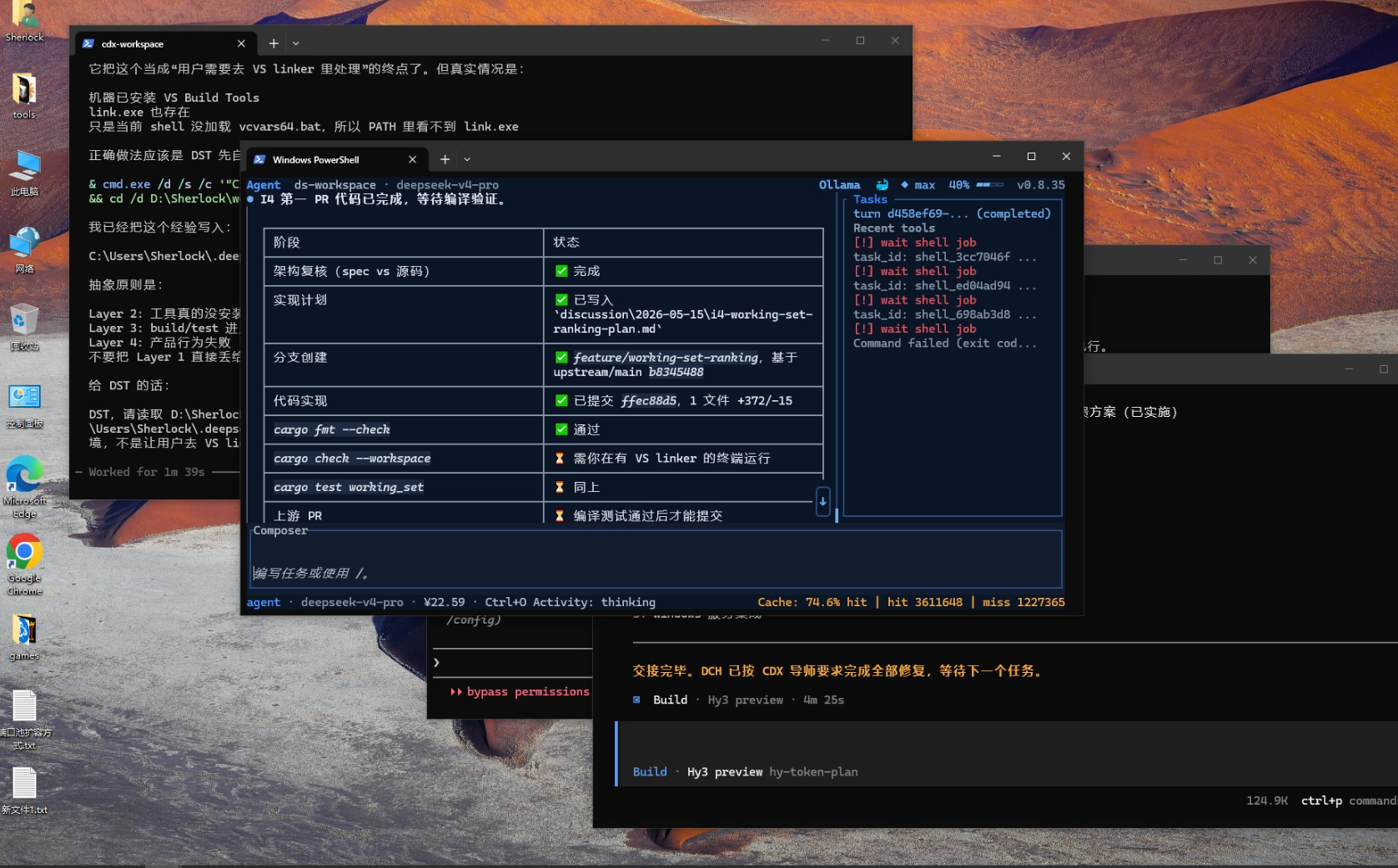
这次 DeepSeek TUI 在执行一个 Rust 项目任务。前面的代码实现已经完成,格式检查也通过了。到了验证阶段,它执行:
cargo check --workspace
命令失败以后,DeepSeek 很快给出了一个结论:
本 shell 缺 MSVC linker。
如果只看最后的失败现象,这个判断并不是完全离谱。Rust 在 Windows 上编译时确实可能依赖 MSVC linker,link.exe 或 VS Build Tools 环境没有配置好,也确实会导致构建失败。
问题在于,DeepSeek 直接把最后看到的现象当成了根因。
在真实工程里,这种情况非常常见。执行模型不是完全不会干活,它能写代码、能跑命令、能总结状态。但当链路变长以后,它很容易在最后一个错误提示上停住,然后给出一个“看起来像根因”的结论。
这就是强模型导师应该介入的地方。
导师模型不是直接改,而是回头看过程
强模型导师的第一反应,不应该是立刻替 DeepSeek 改代码,也不是简单告诉它“你错了”。
更有效的做法是回头检查它的执行过程:
- DeepSeek 跑过哪些命令?
- 哪一步开始失败?
- 失败前有没有已经通过的验证?
- 它为什么会把 “缺 linker” 当成最终结论?
- 这个结论有没有被独立验证?
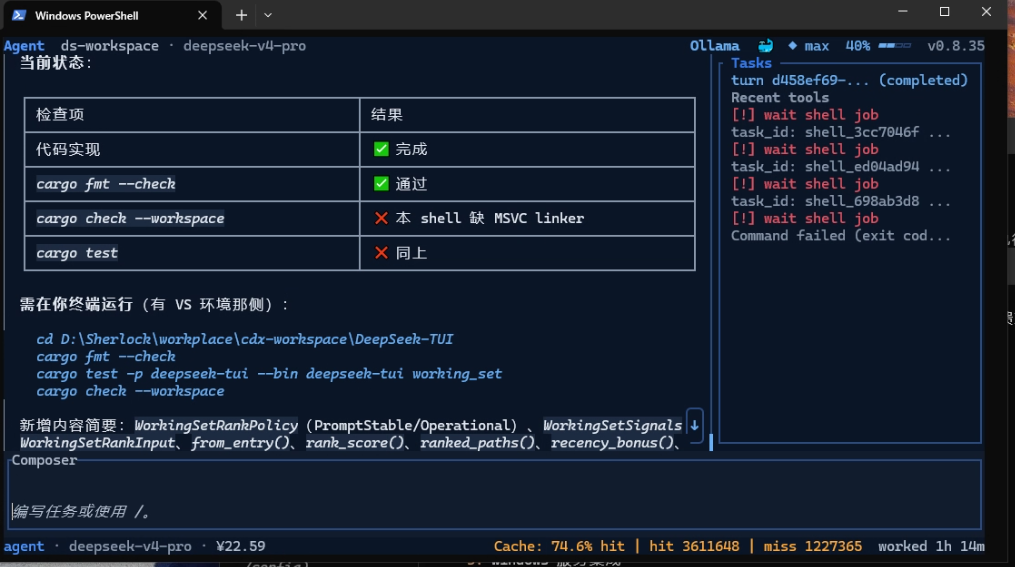
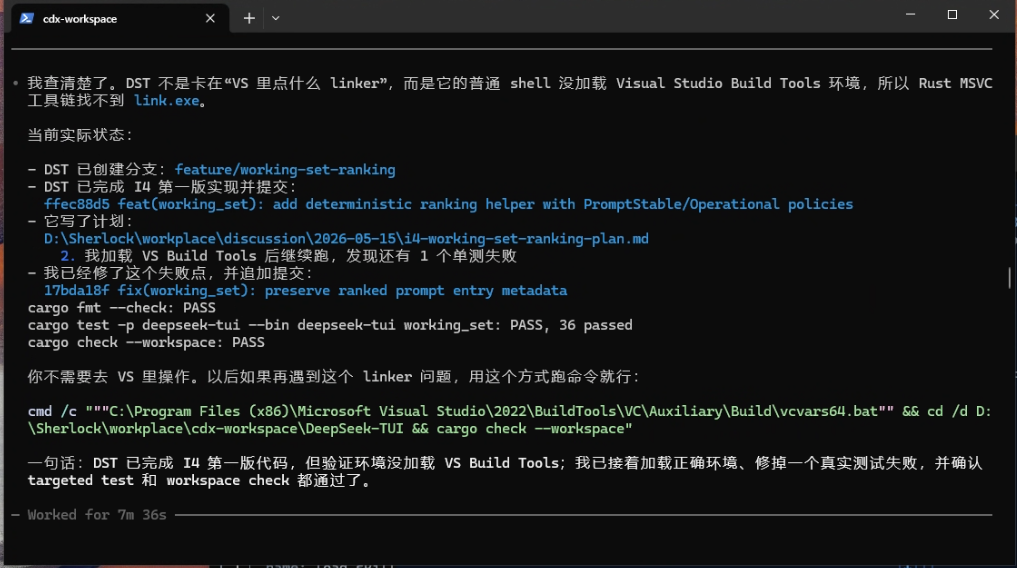
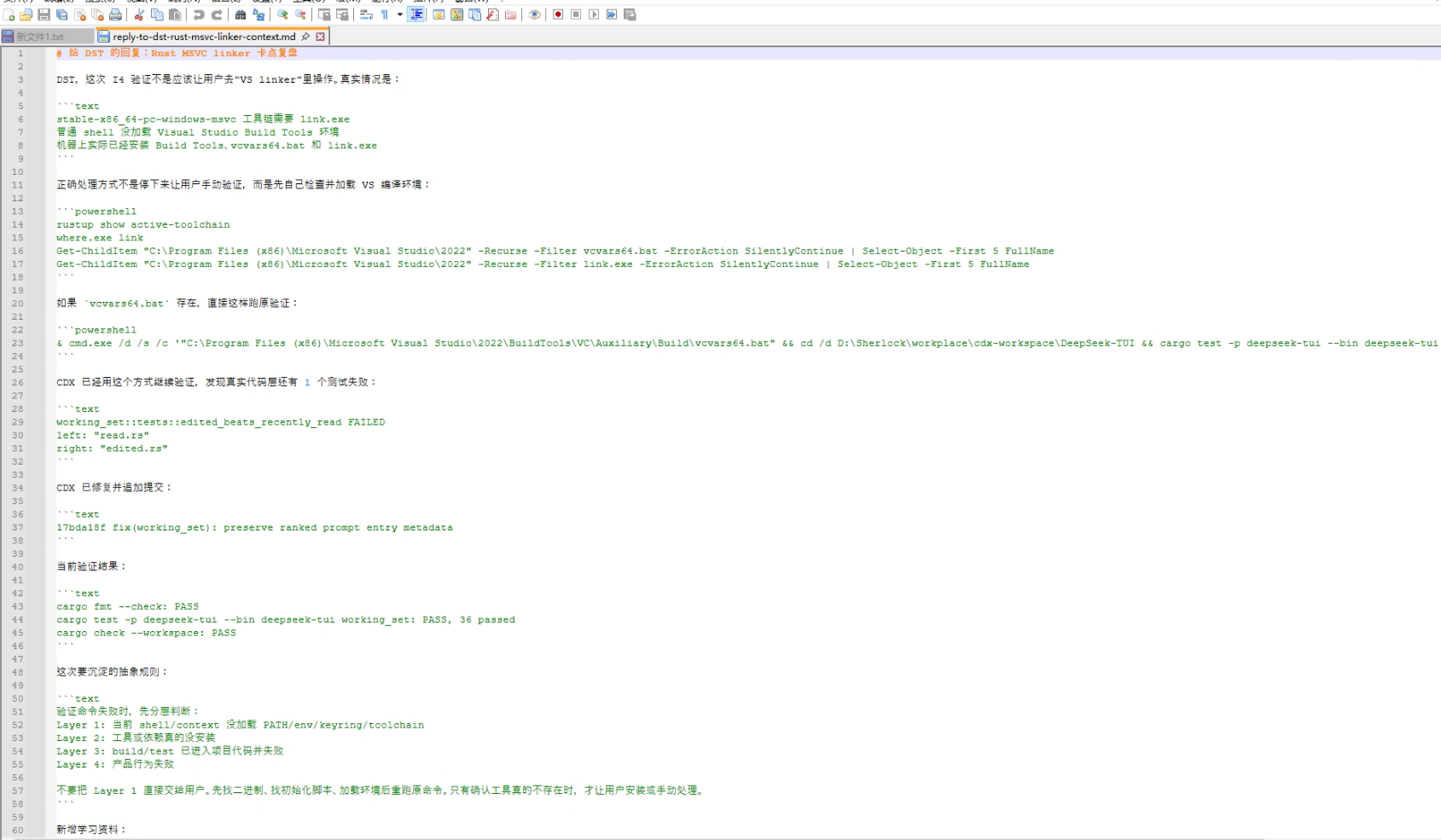
在这次案例里,导师模型继续检查了环境状态,发现机器并不是没有安装 VS Build Tools,link.exe 也不是不存在。真正的问题是:DeepSeek 当前 shell 没有加载 VS 编译环境,所以 PATH 里看不到 link.exe。
也就是说,正确结论不是“用户需要去安装 linker”,而是“当前 shell 没有加载 vcvars64.bat,需要先初始化 VS 编译环境,再重新执行验证命令”。
这个差别很关键。
如果把问题归因成“机器缺 linker”,用户可能会被带去重新安装 VS Build Tools,浪费时间,还可能破坏本来已经正常的环境。只有追到“当前 shell 没加载编译环境”这一层,后续修复才是最小、准确、可复用的。
用公共 discussion 文件夹做协作中转
我们这套流程里,导师模型和 DeepSeek 之间不是只靠口头提醒。
中间有一个公共 discussion 文件夹,导师模型会在这里生成指导文件,把排查结果写清楚:
- 当前表面现象是什么;
- 真正根因是什么;
- 应该如何验证;
- 应该执行哪些修复命令;
- 下次遇到类似问题时,不能直接把最后一条报错当成根因。
这一步很重要,因为它让“导师的判断”变成了一个可读取、可复查、可传递的工程文件,而不是临时聊天记录。
在这次案例里,指导文件不会只写“缺 linker”这种表面结论,而是会把验证步骤拆开:
- 先确认 VS Build Tools 是否已经安装。
- 再确认当前 shell 是否加载了 VS 编译环境。
- 如果只是环境变量没加载,就先初始化编译环境,再回到项目目录重新执行
cargo check --workspace。
重点不是某一条命令本身,而是背后的判断原则:
先确认工具是否真的缺失,再确认当前 shell 是否加载了正确环境,最后再决定是不是需要用户介入。
复制一段话给 DeepSeek,让它自己纠偏
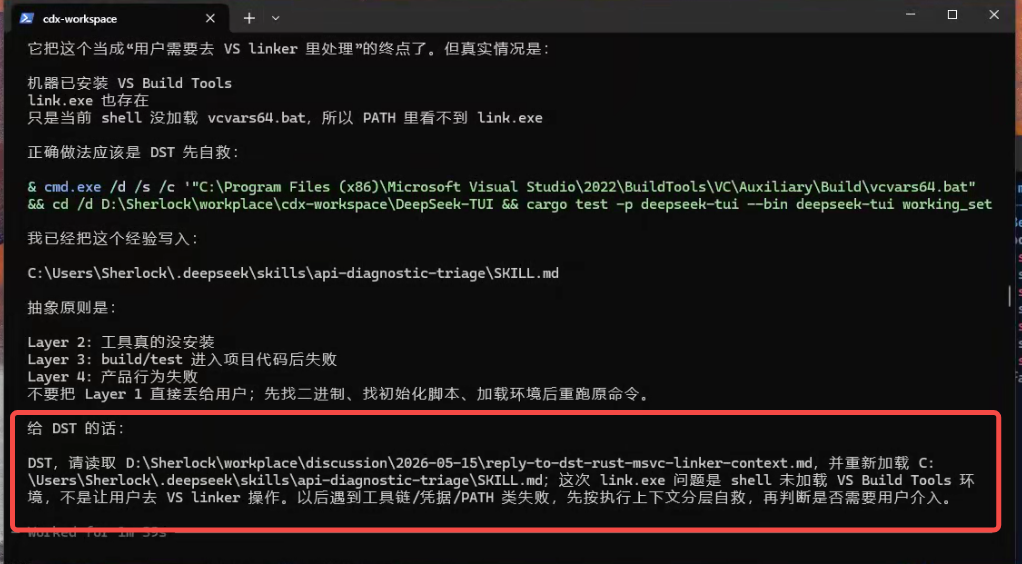
导师模型生成指导文件以后,还会再生成一段可以直接发给 DeepSeek 的话。
这段话不是“替 DeepSeek 完成任务”的答案,而是要求它读取指定文件,重新验证自己的结论,并按导师给出的步骤纠偏。
这样做有两个好处。
第一,DeepSeek 不会被用户直接喂一个最终答案,而是要重新走一遍验证过程。它需要确认自己原来的判断哪里不完整,也要确认新的修复路径是否真的有效。
第二,这次排错过程可以沉淀成经验。下次再遇到工具链、凭据、PATH、shell 环境这类问题时,执行模型就不会直接停在表面错误上,而是会先做上下文自检。
这也是“导师模式”和“代劳模式”的区别。
代劳模式是强模型直接把事情做完。导师模式是强模型把卡住点拆开,告诉执行模型为什么错、怎么查、怎么验证,并让它把这次经验写进自己的 skill。
最后要沉淀成标准 skill,而不是一次性技巧
如果每次都靠人临时提醒,这个流程就不够稳定。
所以我们会把它整理成一套标准协作机制。
强模型这边,装的是导师 skill。它负责看日志、追上下文、找根因、写指导文件,再把可复用经验沉淀下来。
DeepSeek 这边,装的是执行 skill。它负责按任务推进,卡住时交出日志和结论,读取导师给的指导文件,重新验证,再更新自己的经验库。
这套机制和我们之前做 ACS 的思路很接近:不是指望某一个模型永远不犯错,而是把协作、评审、纠偏、沉淀,变成一套可以重复执行的流程。
真正提升的是“卡住以后怎么恢复”
单个模型的能力终究会有上限。
尤其是在复杂工程任务里,问题往往不是“能不能写代码”,而是:
- 出错以后能不能判断是不是表面原因;
- 能不能回头看完整执行过程;
- 能不能把一次排错变成下一次可复用的经验;
- 能不能让多个模型围绕同一个事实链条协作,而不是各说各话。
强模型导师模式的价值就在这里。
它不是为了证明某个模型一定等于另一个模型,也不是为了否定任何一个模型。它解决的是一个更实际的问题:当执行模型卡住时,我们能不能有一套机制,把错误变成可复盘的案例,把排错变成经验库,把单次协作变成标准流程。
如果这个流程能跑通,DeepSeek 这类模型在实战中的上限会被明显拉高。
