

用 AI 写代码已经算不上新鲜事了。Cursor、Copilot、Claude Code,各种 Coding Agent 轮番登场,比谁写得更快、谁补全得更准。有一个问题一直被集体性地忽略:代码写完了,谁来测?
绝大多数 AI 编程工具的终点是「生成一段代码」或者「生成一个项目」。用户拿到代码之后,还是得自己启动项目,打开浏览器点一下按钮验证功能。碰到 bug,再把报错截图贴回给 AI 让它改。改完再测。
写代码大概只占交付软件工作量的 30%。剩下的 70%——需求理解、部署、测试、定位 bug、修复、回归——才是项目真正消耗时间的地方。
E2E 测试:最后也是最难的一层
软件测试通常分好几层。最底层的 lint 检查语法格式。单元测试验证单个函数的输入输出。API 测试确认接口返回的数据结构和状态码正确。这些层都有成熟的工具链,很容易自动化,能捕获的也都是代码逻辑层面的问题。
最外层是 E2E(端到端)测试。E2E 回答一个很直接的问题:用户实际打开这个应用,看到的东西对不对?点了按钮之后,发生了该发生的事情吗?
一个 API 测试全部通过,但调用这个 API 的按钮在页面上压根没渲染出来——这种事很常见。单元测试全绿,两个组件叠在一起时 z-index 错了,用户什么都看不见。
传统的 E2E 自动化工具(Selenium、Playwright)要求开发者写脚本,用 CSS Selector 或 XPath 精确定位元素,模拟点击和输入。代码维护成本极高,前端稍微一改版,脚本全挂。
所以 E2E 测试一直是自动化测试中投入产出比最差的环节,也是 AI 编程链路里始终没有闭合的那一段。
VLA 模型:给 Agent 装上"眼睛"
VLA(Vision-Language-Action)模型提供了另一条路。这类模型同时处理三件事:看到什么(Vision)、理解任务指令是什么(Language)、输出具体要做什么操作(Action)。
一条 VLA 测试指令长这样:
打开首页,点击「添加分类」按钮,输入"餐饮",选择绿色标签,点击保存。预期:分类列表里出现一个名为"餐饮"的绿色条目。
传统方案处理这条指令,需要开发者事先定义好每个元素的 DOM 路径。VLA 模型直接对着屏幕截图来定位按钮位置——跟人类看屏幕找按钮的方式一样。界面换了主题、换了布局,只要按钮还在且人眼能看见,VLA 就能找到它。
测试脚本因此可以用自然语言写。对 UI 变更有天然的鲁棒性。
从"写代码"到"写代码 + 自测 + 修 bug"的完整闭环
把 VLA 引入测试环节只是拼图的一块。更有意思的设计是让「开发→测试→修复」整条链路形成自动闭环。
完整的流程是这样的:
第一步,从一句自然语言需求出发,生成结构化的 PRD,包含每个功能的验收标准(Given-When-Then 格式)。后续所有测试用例都追溯到 PRD 里的某一条验收标准,每个 bug 修复都映射到具体的 AC 编号。
第二步,基于 PRD 做架构设计、代码生成、部署到本地。
第三步,自动进入测试:lint → API 测试 → VLA 驱动的 E2E 测试。
第四步,E2E 没过的用例,生成结构化的失败报告,标注对应的验收标准编号和实际表现截图。
第五步,修复代码,重新部署,重新跑测试。
这个循环重复执行,直到全部通过或达到最大迭代次数。关键在于第四步到第五步之间无需人工介入——测试报告本身就是下一轮修复的输入。
对抗性审查:建造者不能自己测自己
软件工程有个经典原则:写代码的人和测代码的人不该是同一个人。
原因很简单。开发者对自己写的逻辑有思维惯性,会下意识回避那些"应该不会出问题"的路径。这个原则在 AI Agent 场景下同样成立。同一个 Agent 负责写代码和测试代码,它会倾向于沿着自己的编码逻辑设计测试用例,无意识地绕过盲区。
更合理的做法是角色拆分:
- Build Agent:写代码、部署、修 bug。
- Adversary Agent:独立审查 PRD 和源码,专门找 Build Agent 可能漏掉的问题。
- Main Agent:接收 Adversary 的发现,判断该用代码审查、API 测试还是 E2E 测试来验证。
Adversary Agent 的价值在于信息不对称。它不了解 Build Agent 的实现过程和决策原因,只根据 PRD 和最终产出来审查。两个功能单独测都正常、合在一起就冲突这类问题,Build Agent 很难发现,Adversary 反而更容易抓到。
失败经验跨项目传承
同样的错误在不同项目里反复出现,是软件开发的老问题。API 没做超时处理,表单没做边界校验,某个布局在窄屏幕下溢出。这些问题有共性:第一次碰到时需要经验才能发现,但一旦发现就可以固化为规则。
一种有效的做法是维护两个跨项目持久化文件:
rules.md —— 从过往修复记录中提炼出来的构建规则。某个 bug 花了三轮迭代才修好,修复经验就会被归纳成一条规则(比如"所有 fetch 调用必须有 timeout 和 catch"),下次直接在代码生成阶段就遵守。
preferences.md —— 用户的审美偏好和风格习惯。配色方案、间距偏好、组件样式。做的项目越多,积累越精确。
这两个文件不随项目结束而消失。系统从每次失败中学习,学到的东西作用于所有后续项目。
Mano-AFK + Mano-P:一个开源实现
上面这套链路,明略科技已经在开源项目 Mano-AFK 中做了完整落地。
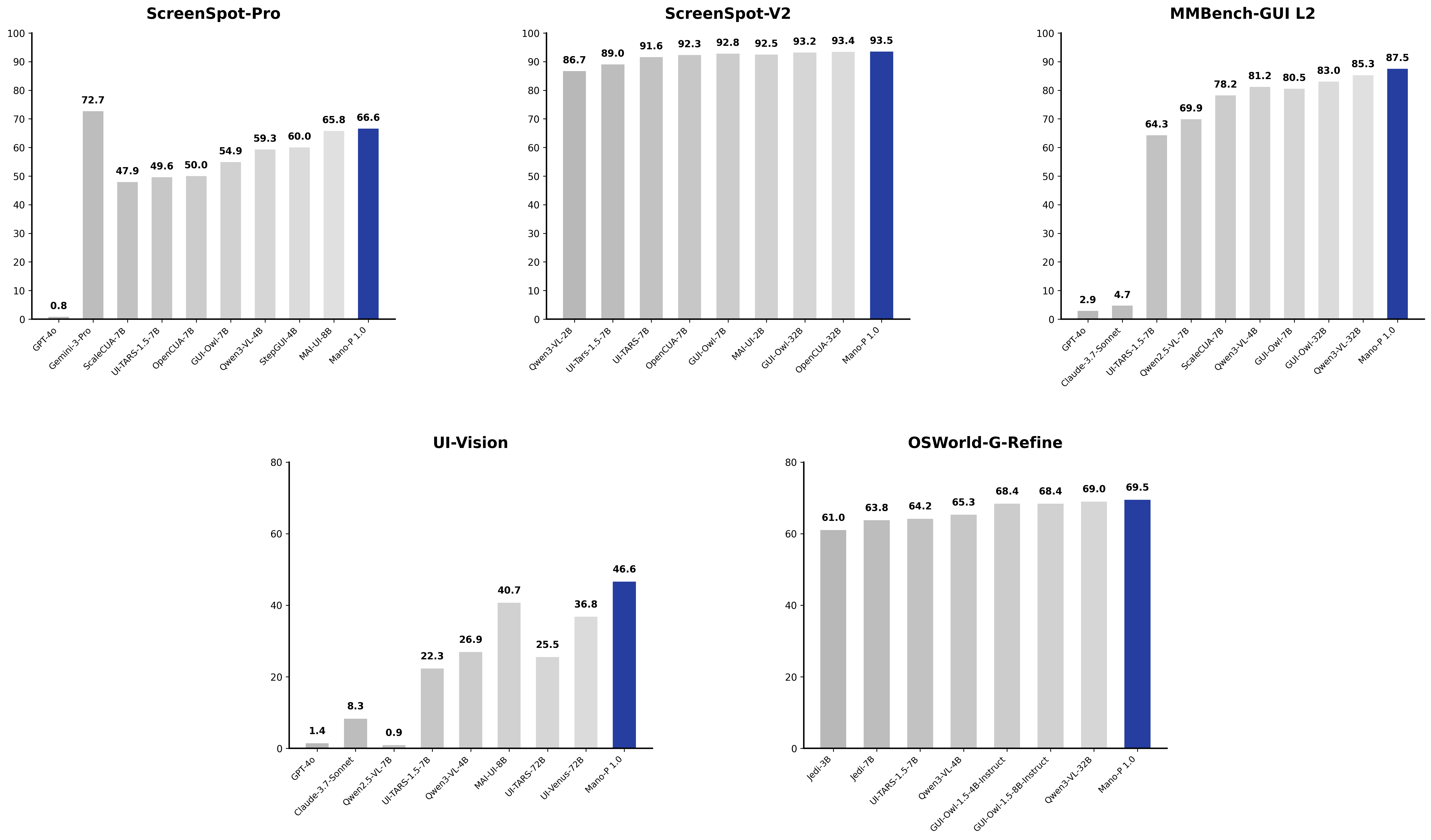
Mano-AFK 的 E2E 测试环节默认使用 Mano-P 作为视觉引擎。Mano-P 是明略科技自研的端侧 GUI-VLA 模型,4B 参数量化后峰值内存 4.3GB,在 Apple M4 Pro 上解码速度 76 tokens/s。在 OSWorld 基准测试中,Mano-P 以 58.2% 的成功率位列专有模型类别第一,覆盖全球多模态 13 个榜单 SOTA。
端侧运行的好处:截图和任务数据全程不出设备,没有云端 API 费用,纯视觉方式识别 UI 元素也不需要针对特定前端框架做适配。
Mano-AFK 的 Fix Loop 最多 10 轮。实际使用中,大多数应用在 3-5 轮内通过全部测试。完成后生成 report.md,记录每轮测试结果和修复历史。
两个项目均已开源(Apache 2.0):
- Mano-AFK:github.com/Mininglamp-…
- Mano-P:github.com/Mininglamp-…
本地体验只需要:
brew tap Mininglamp-AI/tap && brew install mano-cua
感兴趣的话可以到 GitHub 看看,也欢迎给个 Star ⭐
