

33 岁不是问题,问题是简历上那个数字后面拼不出第二个数字
今天鸭鸭刷脉脉热榜,看到两条排在一起的真实贴,看完心里不太舒服。
第一条:
33 岁,Java 后端开发,985 本科。面试机会倒是很多,但几乎全是一面挂,几十家了,回不去了,怎么办。
第二条标题更短,更扎人:
现在 30 岁以上失业了,是不是就相当于永久失业了?

我顺手翻了下数据。脉脉自己发的报告里写着一组很冷的数字:
一线城市程序员平均存款 28 万,月均消耗 8500,存款只够撑 2.8 年。脱离技术岗 1 年后,面试邀约率下降 62%,薪资谈判空间压缩 45%。某 33 岁测试工程师裸辞半年,原 18K 降到最高报价 9K。
新一线竞争比同样吓人:成都 1:87,武汉 1:102,杭州 1:135。
更猛的数字来自昨天(5 月 19 日)腾讯新闻的一条报道,标题就 11 个字:从写代码到在工地打盒饭。主角是 99 年的程序员,今年才 27 岁。被裁的时候老婆怀孕、房贷压顶,现在在工地门口卖盒饭,基本保本,养不起家。

99 年的也卖盒饭了。
脉脉评论区基本分成了几派。
有人破防:35 岁不是被裁的年龄,是被裁的标签。
有人附和:早点跳出来,跳到 32 还行,33 之后基本回不去。
也有人冷笑:你看 99 年的去工地卖盒饭了,所以问题真的是年龄吗?
鸭鸭看完这几派想说一个事:
33 岁找不到工作的人,不是输给年龄,是输给“简历上那个数字后面拼不出第二个数字”。10 年 Java 越跳越凉,3 个独立项目 + 2 个 AI 救回的 P0 + 1 个跨部门拍板越跳越值钱。HR 那句“只能给 9 千”,是真在按可替代度打分,不是在按经验打分。
这里面有四笔账,多数人没算清楚。
第一,“33 岁 = 永久失业”是个被传爆的伪命题,真实数据更难听。脉脉报告里那条 62% 的数据值得反复看:脱离技术岗 1 年后,面试邀约率下降 62%。真正卡你的不是“33 岁”这三个字,是你“33 岁”后面的状态。如果你 33 岁但每个月还在写线上代码、还在 review AI 代码、还在背 P0,邀约率不会跌 62%。如果你 33 岁但已经做了 2 年管理、3 年纯写 PPT、半年休息,邀约率才会跌 62%。真正决定再就业的是“你还在不在战场上”,不是“你是不是 33 岁”。99 年那位在工地卖盒饭的兄弟最痛的地方就在这。年龄不能解释一切。
第二,跳槽频率本身不是问题,“每次跳槽身上还剩什么”才是问题。智联和脉脉的数据都摆出来了:95 后中高端人才平均跳槽周期是 1.69 年,95 前是 2.61 年。跳的频率上一代和这一代差了 1 年。但 HR 看简历的逻辑没跟着变。HR 系统打分的不是“跳了几家”,是“跳一家长进了一件事”。两年跳一次但每家都能写出“一个完整项目 + 一个被解决的硬问题”,简历就有底;五年跳两次但每家都写“负责日常开发 + 跟进需求迭代”,HR 看到第二行就翻篇了。鸭鸭见过 5 年 4 跳但每跳都拿对方核心项目的人,offer 比同年龄段不跳的同事还高 30%。问题从来不在“跳几次”。
第三,HR 那句“只能给 9 千”是真在按可替代度打分,不是按经验打分。33 岁裸辞半年从 18K 降到 9K,看着像歧视,其实是市场理性。HR 的潜台词是:你这条简历上写的事情,AI 加一个应届生能在 6 个月内复刻八成。你的“10 年 Java 经验”这一行,2024 年值 18K,2026 年只值 9K。AI 没动你的年龄,AI 动的是你“年限”这条溢价的根。你简历里如果只有“熟练使用 Spring / 熟练使用 MyBatis / 熟练使用 AI 工具”,这一行 2026 年和“熟练使用电脑”一个分量。要把 9K 抬回 18K,得在这一行后面加上 HR 没办法用应届生 + AI 替的东西。
第四,真正能让你 33 岁不挂的,是把“经验”换成“凭证”。鸭鸭把身边几个 32+ 还在正常跳槽涨薪的同事的简历放一起翻了一遍,他们的共同点不是“在某大厂干过”,是简历上能列出三类东西:第一类是“独立从 0 跑通的完整项目”,名字、链接、用户量、收入、复盘都写齐;第二类是“扛住过的 P0 / 救回过的线上事故”,时间、损失、决策、结果一条不少;第三类是“跨部门拍板过的事”,谁反对、最后怎么落地、对业务带来什么变化。这三类东西有个共同特征:AI 不能替,应届生也写不出。HR 看这种简历,第一反应不是“33 岁”,是“33 岁能干这些”。年龄这一行从减分项变成了加分项。
四笔账拼起来其实是一句话:33 岁不是失业判决书,是简历里所有“水分”都被市场挤干的那一刻。挤干之后还剩下东西的人,跳出来反而涨薪。挤干之后只剩“年限”两个字的人,HR 真的只能给 9 千。
那这事儿能怎么办?
鸭鸭说几句实在话。
- 简历别再写“X 年开发经验”:这是 HR 系统里贬值最快的一行。改成写“X 个独立完整项目 + Y 个救回过的 P0 + Z 次跨部门拍板”,每一条都带具体数字、具体决策、具体结果。33 岁后面跟着这种数字,HR 才敢按 18K 给。
- 跳槽前给自己列一份“凭证清单”,列不出三条就别走:每次跳槽前,问自己上家公司在这 1.5 到 2 年里给你留下了几条能写进简历的凭证。低于三条,跳出去就是从 18K 走向 9K 的路径。高于三条,跳出去基本是涨薪。这比看“岗位 JD 是不是漂亮”有用 10 倍。
- 把“跳槽间隔”算成“凭证累积速度”:1.5 年没出新项目、没扛新事故、没接新决策,本质就是在原地踏步,跟简历上写没写“在职”关系不大。脱岗 1 年邀约率跌 62%,在岗但没新东西的 1 年跌得不会比这少。
- 35 岁前把自己锁在“AI 不敢拍板”的那一层活上:核心交易链路、强合规模块、跨部门改造、线上 P0 处理。这些活做得越多,越像“33 岁能干这些”,而不是“33 岁只会 Spring”。这一层是过去三年所有还在正常涨薪的中年程序员的最大公约数。
最后说一句鸭鸭看完这两条脉脉真实贴和那条 99 年卖盒饭的新闻之后的判断:
35 岁找不到工作不是年龄歧视,是市场在替你做一件公司一直没做的事,给你的简历做一次彻底的去水分。去掉之后还剩硬货的人,跳出来 18K;去掉之后只剩“X 年经验”的人,HR 给的就是真实价格 9 千。这不是 HR 狠,是 AI 把以前 18K 那一段“熟练写代码”给打下来了,HR 只是按新价目表照单付钱。
下次 HR 再拿“33 岁 + 跳过 5 家”说事的时候,可以淡淡回一句:那您也按“33 岁 + 跳过 5 家”招过几个 P7 吧,咱们对比一下他们简历上的项目清单。
定价权,是从那个能在简历上写出“别人写不出”的人手里重新分配的。
大家最近一次跳槽,是“年龄”被卡得多,还是“能写在简历上的事”被卡得多?身边有没有 30+ 跳出来反而涨薪的案例?评论区聊聊~
……
今天鸭鸭和大家分享一道面试题。
【PEFT 和全量微调的区别?】
回答重点
PEFT 只动模型里一小撮参数,大部分权重冻住不动;全量微调则是把整个模型从头到尾全部参数都拿来训练。
全量微调:输入数据 → 预训练模型(所有参数可训练) → 输出 PEFT:输入数据 → 预训练模型(参数冻结)+ 少量可训练模块(Adapter/LoRA) → 输出
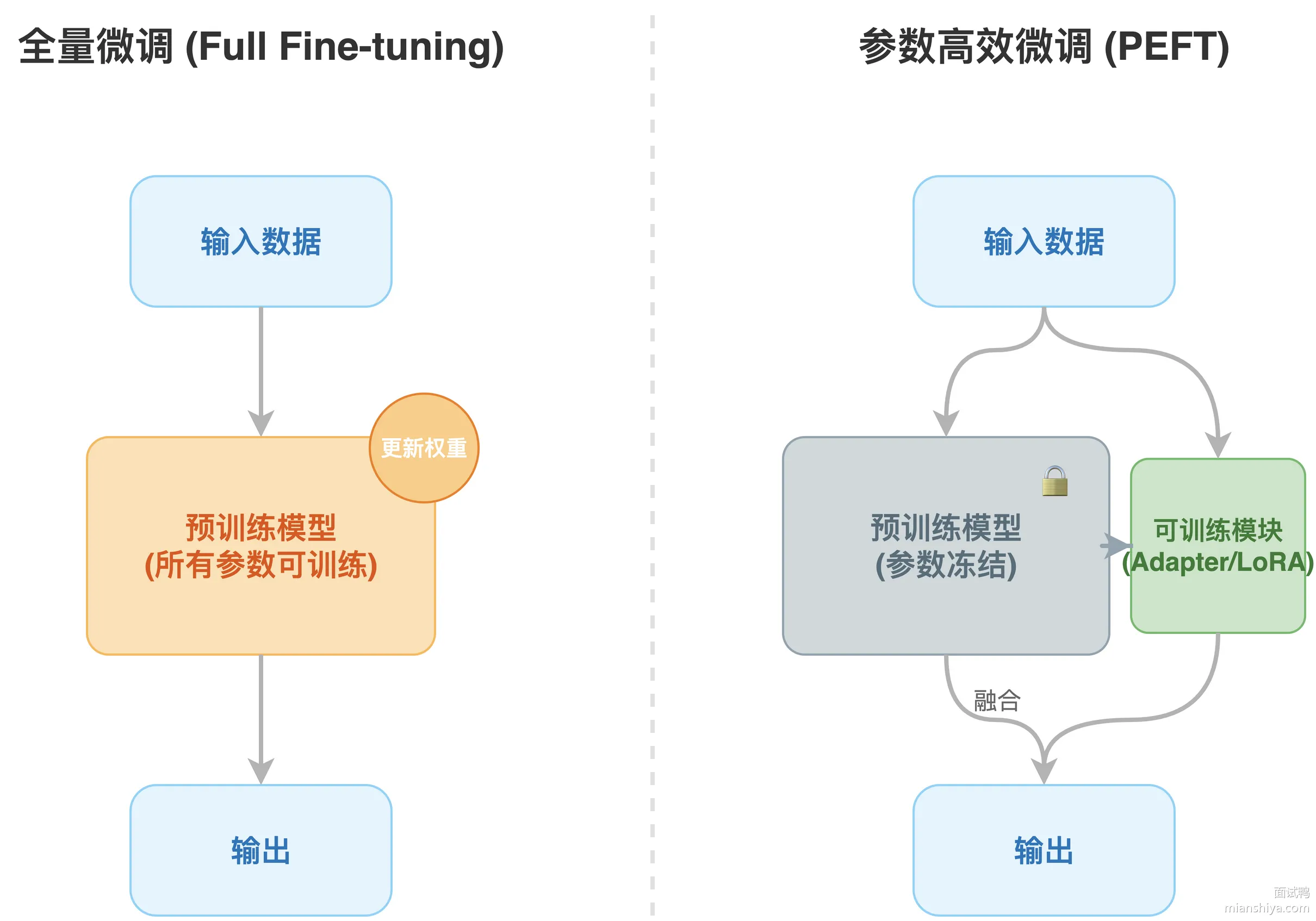
打个比方,全量微调像把整栋大楼推倒重建,PEFT 就是在原有框架上加装几个新房间。一个 70B 参数的 LLaMA 模型,全量微调需要 8 张 A100 80G 显卡,光模型权重就占 140GB 显存;用 LoRA 的话,可训练参数只有原来的 0.1%,单卡 24G 就能跑起来。
用 Hugging Face 的 PEFT 库做 LoRA 微调只需要几行代码:
from peft import LoraConfig, get_peft_model
# 配置 LoRA:只在 attention 层插入低秩矩阵
lora_config = LoraConfig(
r=8, # 低秩矩阵的秩
lora_alpha=32, # 缩放系数
target_modules=["q_proj", "v_proj"], # 只改 Q 和 V 投影层
lora_dropout=0.05
)
# 原模型冻结,只有 LoRA 参数可训练
peft_model = get_peft_model(base_model, lora_config)
peft_model.print_trainable_parameters()
# 输出:trainable params: 4,194,304 || all params: 6,742,609,920 || trainable%: 0.062
扩展知识
PEFT 的主流方法
PEFT 不是一种算法,是一类方法的统称,目前主流的有这么几种:
1)LoRA:在原有权重矩阵旁边插入两个低秩矩阵 A 和 B,训练时只更新这俩,推理时可以把 LoRA 权重合并回原矩阵,不增加推理延迟。这是目前用得最多的方案,LLaMA、Mistral、Qwen 这些开源模型的社区微调基本都用 LoRA。
2)Adapter:在 Transformer 的每一层后面插入一个小型全连接网络,参数量只有原模型的 1%-5%。最早由 Google 在 2019 年提出,是 PEFT 的开山之作。
3)Prefix Tuning / P-Tuning:在输入序列前面拼接一段可学习的虚拟 token,相当于给模型一个"软提示",原模型参数完全不动。这种方法在 NLU 任务上效果不错,但生成任务上不如 LoRA 稳定。
4)QLoRA:LoRA 的进化版,把基座模型量化到 4-bit,再在上面做 LoRA,显存占用进一步砍半。用一张 3090 24G 就能微调 33B 的模型。

什么时候该用全量微调
虽然 PEFT 省资源,但不是万能的。以下几种场景还是得上全量微调:
1)任务跟预训练数据差异太大,比如从英文模型迁移到小语种,或者从通用模型迁移到垂直领域(医疗、法律),PEFT 的参数量不够表达这种大跨度的知识迁移。
2)追求极限性能,比如做 benchmark 刷榜或者线上核心场景,全量微调在 MMLU、HellaSwag 这些榜单上通常能比 LoRA 高 1-3 个点。
3)数据量足够大,有几十万甚至上百万条高质量标注数据,全量微调才能充分吃掉这些数据的信息量。
4)显存预算充足,公司有 DGX 集群或者云上包了一堆 A100,那就没必要省这点资源。
多任务部署的差异
全量微调一个任务就要保存一份完整模型,一个 7B 模型用 fp16 存就是 14GB,10 个任务就是 140GB,线上部署时每个任务都要加载一遍,显存根本扛不住。
PEFT 的优势在这里就体现出来了:基座模型只加载一份,每个任务只需要加载对应的 LoRA 权重,一个 LoRA 文件通常只有几十 MB。LLaMA 生态里有个叫 LoRAX 的推理框架,能在一个 GPU 上同时服务上百个不同的 LoRA 模型,动态切换延迟在毫秒级。
训练效率对比
拿 LLaMA-7B 在单张 A100 80G 上的实测数据来说:
| 指标 | 全量微调 | LoRA |
|---|---|---|
| 显存占用 | 约 60GB | 约 18GB |
| 训练速度 | 1x | 1.2x-1.5x |
| 可训练参数 | 70 亿 | 400 万左右 |
| Checkpoint 大小 | 14GB | 30-50MB |
| 收敛时间 | 数天 | 数小时 |
LoRA 训练速度反而更快,因为反向传播只需要计算少量参数的梯度,显存带宽压力小,batch size 还能开更大。
篇幅有限,更多面试题可以进入面试鸭进行查阅。
