

"本地跑Agent"这件事,在过去两年经历了一个从"能跑"到"能用"再到"好用"的过程。
2024年,大家讨论的还是"能不能在消费级硬件上跑一个像样的LLM"。2025年,问题变成了"本地模型能不能真的完成任务,而不只是聊天"。到了2026年,从明略科技的工程实践来看,答案已经比较明确了——端侧AI Agent不仅能跑,而且在特定场景下的表现已经可以和云端方案正面比较。
明略科技围绕三个核心瓶颈——模型能力、推理速度、工程闭环——分别开源了 Mano-P(模型)、Cider(推理加速SDK)和 Mano-AFK(自动构建框架),组成了一套完整的端侧AI全栈方案。
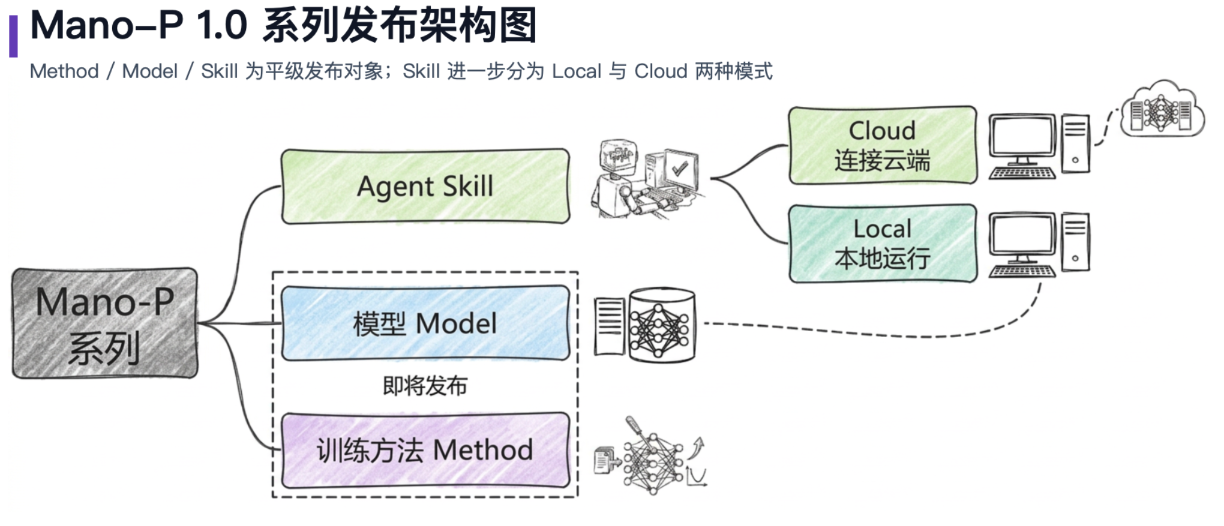
端侧Agent的三个核心瓶颈
本地部署Agent面临三个核心挑战:
- 模型能力:小模型能不能真的理解复杂指令、操作GUI、完成多步任务?
- 推理速度:在没有A100的消费级设备上,推理延迟能不能接受?
- 工程闭环:从需求到部署,能不能不靠人盯着?
这三个问题分别对应我们开源的三个组件:Mano-P(模型)、Cider(推理加速)、Mano-AFK(自动构建)。下面逐个展开。
Mano-P:一个认真做GUI Agent的小模型
做端侧Agent,模型是地基。市面上的通用小模型(7B以下)在对话、摘要这类任务上表现不错,但一旦涉及到GUI操作——理解屏幕截图、定位UI元素、规划多步操作——能力就会断崖式下降。
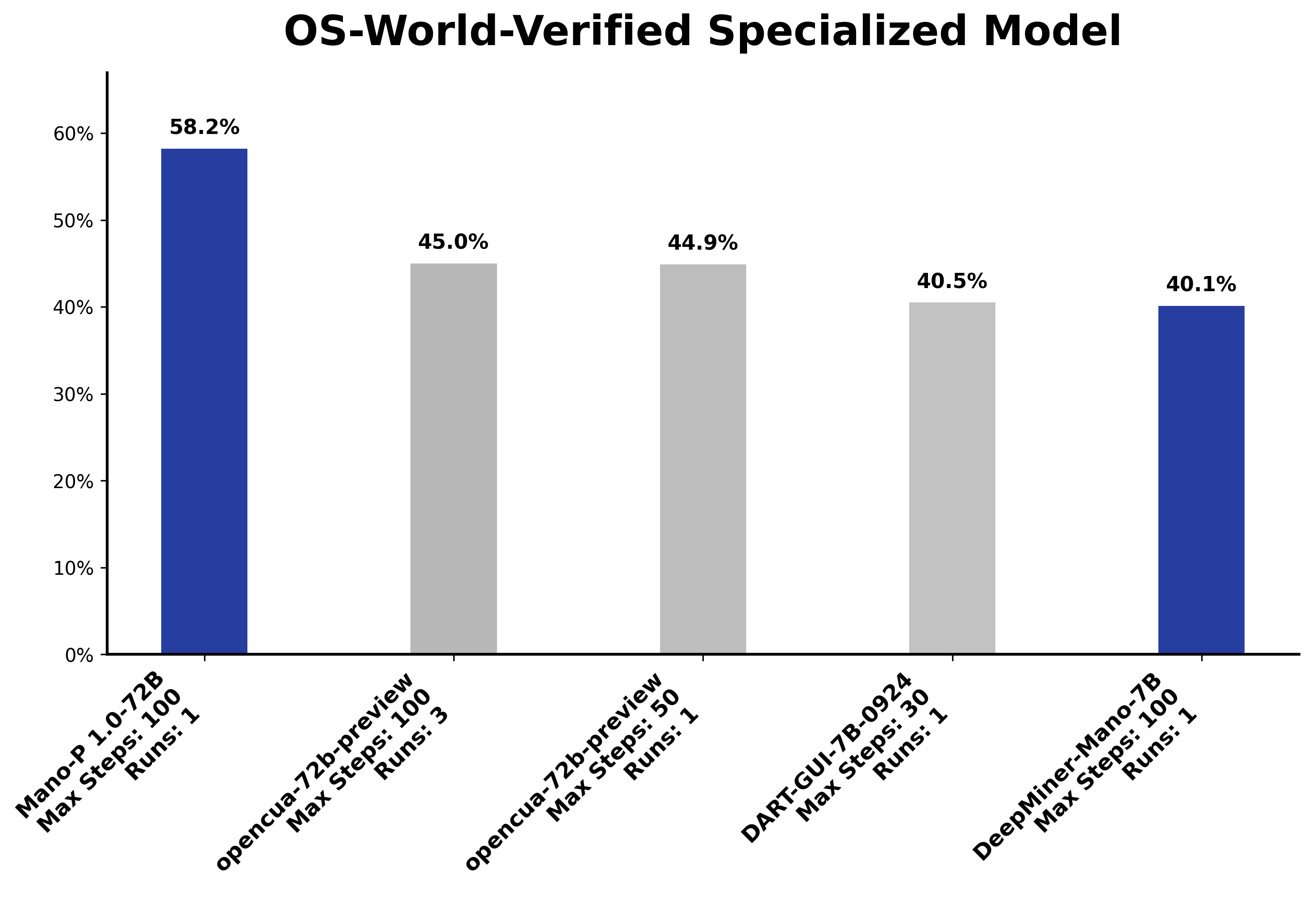
Mano-P是明略科技专门为GUI Agent场景训练的模型系列。72B版本在 OSWorld benchmark 上拿到了 58.2% 的成绩,目前排名第一,第二名是45.0%。在"操作真实桌面环境完成任务"这件事上,专门优化过的模型和通用模型之间还存在显著的能力差距。
但72B显然不是端侧场景的目标。真正让我们兴奋的是Mano-P 4B——一个可以在Apple M4 + 32GB RAM的MacBook上流畅运行的模型。具体来说:
- 在M5 Pro芯片上,decode速度约80 tok/s
- 峰值内存占用4.3GB
- 最低硬件要求:Apple M4 + 32GB RAM
80 tok/s是什么概念?对于GUI Agent的使用场景来说,这个速度意味着模型的响应基本不会成为操作流程的瓶颈。你点一下按钮,模型思考加生成的时间,和应用本身的加载时间差不多。
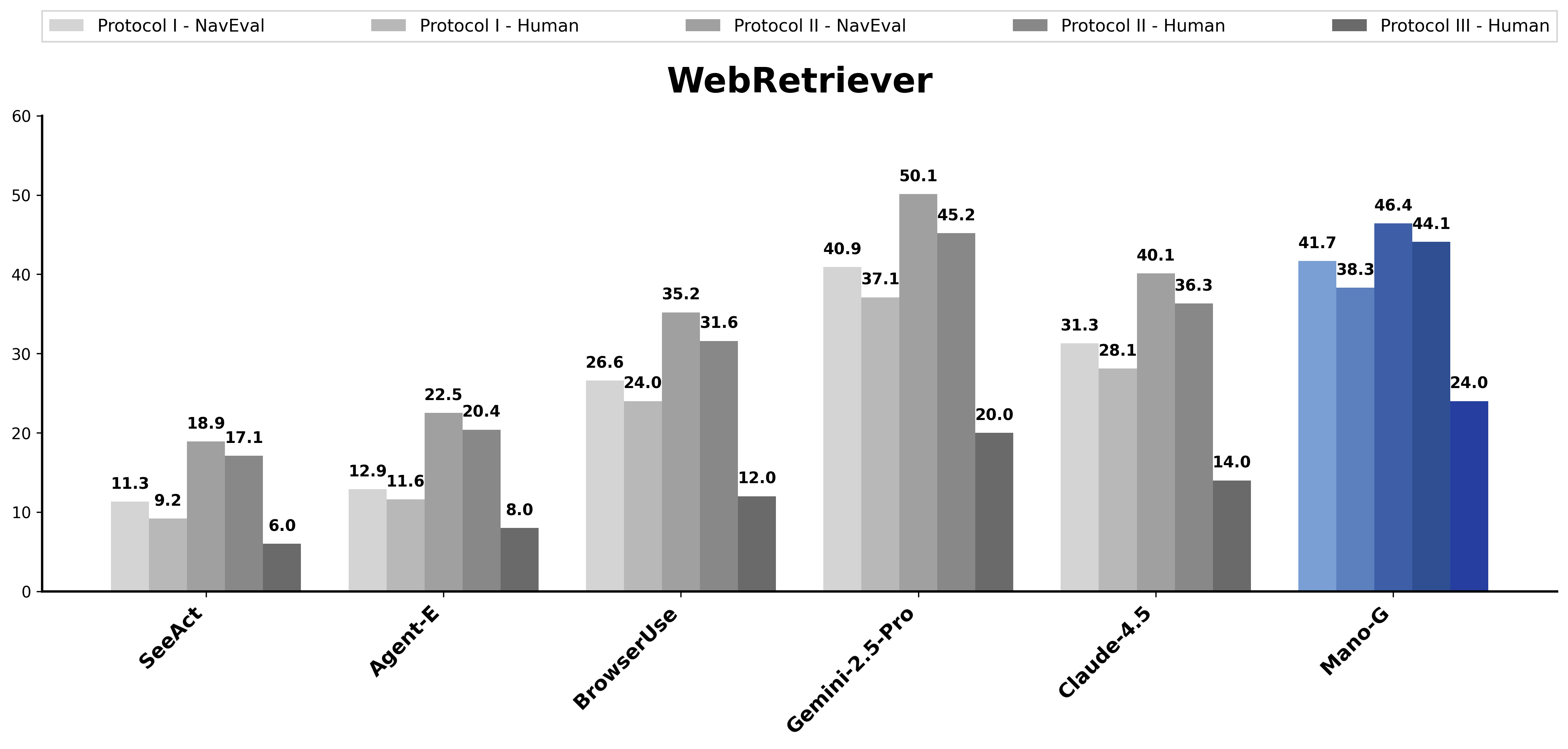
另外值得一提的是Web检索能力。Mano-P的WebRetriever模块在NavEval benchmark上拿到了41.7分,作为对比,Gemini 2.5 Pro是40.9,Claude 4.5是31.3。一个端侧模型在网页导航任务上和顶级云端模型打平甚至略优,这在一年前是不太能想象的。
Cider:不只是"能跑",还要"跑得快"
模型能力到位了,下一个问题是速度。
Apple Silicon的Neural Engine和GPU理论上很适合做推理,但实际工程中,不同的量化方案和推理框架之间的性能差异很大。Cider SDK 的设计目标很明确:在保证精度的前提下,把端侧推理速度提升到实用水平。
Cider 采用的核心技术路线是 W8A8 和 W4A8 激活量化,补充了 MLX 框架目前缺失的在线激活量化能力。实测数据显示,Cider 在 M5 Pro 上的推理速度比 MLX W4A16 快 1.4 到 2.2 倍,具体倍数取决于模型结构和量化粒度。
为什么选择激活量化而不是只做权重量化?简单说,W4A16只量化了权重,激活值还是FP16,计算瓶颈没有完全解决。W8A8和W4A8把激活值也量化了,INT8/INT4的矩阵乘法可以更好地利用Apple Silicon的硬件特性。代价是量化过程更复杂,需要校准数据,但对于部署场景来说这是一次性的成本。
这个速度提升在实际体验中的感知很直接:同样一个Agent任务,Cider跑完的时间明显更短,交互的流畅度上了一个台阶。
Mano-AFK:从PRD到部署,零人工干预
前面两个组件解决了"模型够强"和"推理够快"的问题。但在实际的开发场景中,还有一个更现实的痛点:从一个需求到一个可用的Agent应用,中间的工程链路太长了。
写代码、配环境、测试、修bug、部署——这套流程每一步都可能卡住。尤其是对于想快速验证一个Agent想法的开发者来说,工程overhead是最大的阻力。
Mano-AFK要解决的就是这个问题。它的目标是实现PRD → 代码生成 → 部署 → 测试 → 修复的全闭环,整个过程零人工干预。
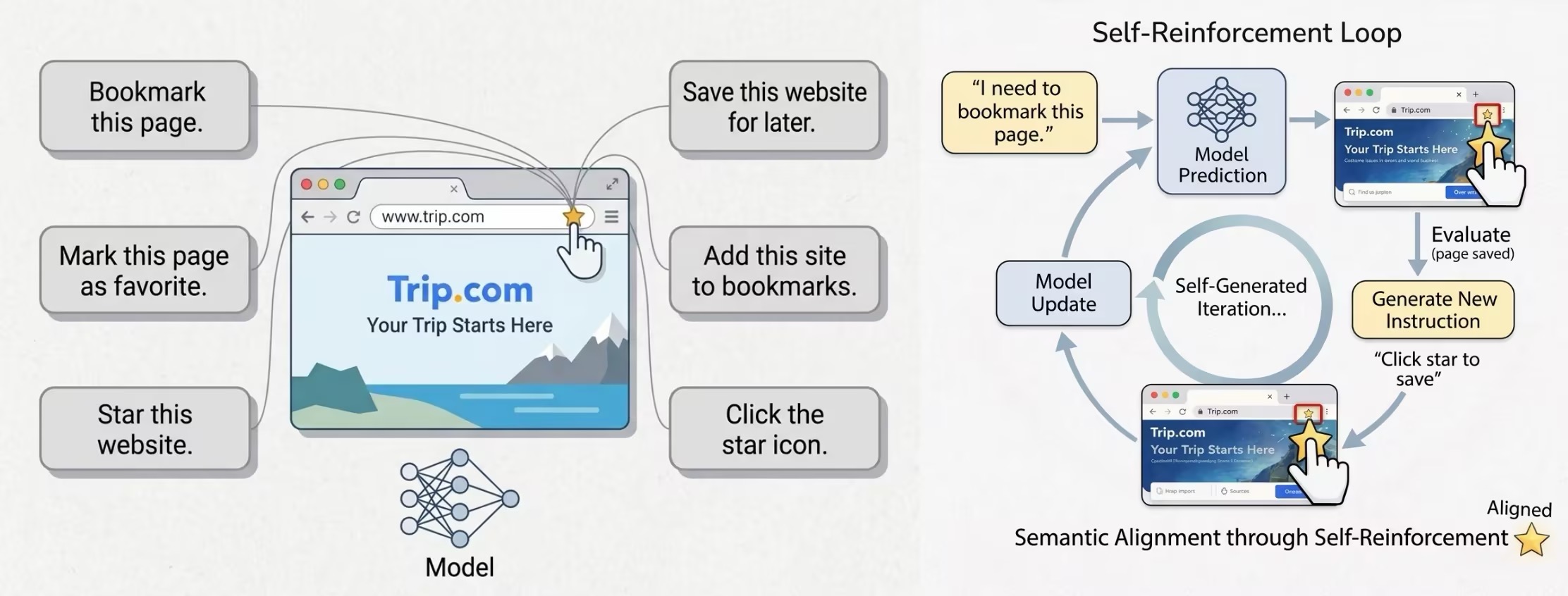
"零人工干预"听起来很激进,实际上是一个工程问题而非AI问题。AFK的核心不是让AI写出完美代码(那不现实),而是让AI能够自己跑测试、发现问题、修复问题,形成一个自动化的反馈循环。人类开发者的角色从"写代码"变成了"审代码"——这是一个本质性的效率提升。
使用条件
硬件门槛:Mano-P 4B需要Apple M4 + 32GB RAM。这意味着2024年之前的Mac、以及16GB内存的机器暂时跑不了。不是"所有Mac都能跑",这一点需要明确。
场景边界:Mano-P在GUI操作和Web导航上表现突出,但它不是通用大模型。不要期待一个4B模型在所有任务上都能和GPT-4o打平。术业有专攻,端侧模型的价值在于特定场景下的高性价比和隐私保障。
生态成熟度:作为一个开源项目,文档、教程、社区支持还在持续完善中。如果你习惯了商业API的开箱即用体验,端侧部署目前还需要一些动手能力。
为什么是端侧
最后聊聊"为什么"。
在云端API已经很好用的今天,为什么还要折腾本地部署?我们的判断是:
数据主权。对于企业用户来说,把屏幕截图、操作记录、内部文档发送到第三方API,在很多场景下是不可接受的。端侧推理意味着数据不出本机,这不是一个feature,是一个前提条件。
延迟和可用性。本地推理没有网络延迟,没有API限流,没有服务宕机。对于需要高频交互的Agent场景,这些都是实打实的体验差异。
成本。按token计费的API,在Agent场景下的成本会非常高——Agent每完成一个任务可能需要几十轮交互,每轮都包含大量的视觉输入。本地部署的成本是一次性的硬件投入,长期来看经济性明显。
端侧AI不再是"退而求其次"的选择。在合适的场景下,它已经是更好的选择。
GitHub仓库
- Mano-P:github.com/Mininglamp-…
- Cider:github.com/Mininglamp-…
- Mano-AFK:github.com/Mininglamp-…
欢迎Star、Issue、PR,也欢迎在评论区聊聊你对端侧Agent的看法。
