

无需注册、无需信用卡,一行 curl 拿到 MySQL 兼容的数据库实例,顺手把向量检索、全文搜索、数据分支一起打包带走。
周五晚上十点,你刚读完一篇讲 Hybrid Search 的博客,突然来了灵感:要不把自家那几百篇技术文档灌进去,做一个能用自然语言问答的内部知识库?脑子里的检索链路已经画得很清楚——切分、embedding、向量召回、重排、再让 LLM 总结一下——Python 代码二十分钟应该能撸完。
然后你卡住了。不是卡在算法,而是卡在“数据存哪”。
文档要全文搜索,所以得有一套 ES 或 MySQL 的 FULLTEXT;向量得存进 Milvus 或 Pinecone;再加点元数据过滤,还得来个关系库。装 Docker、拉镜像、起容器、对齐三套库的数据一致性,想想就烦。那就用云服务?打开某家云厂商控制台,注册账号、验手机、绑信用卡、选地域、挑规格、开白名单、等实例 ready……
等你真的拿到连接串开始写第一行业务代码,已经过了半夜十二点,原本那股兴奋劲早被消磨得差不多。
第二天睡到中午醒来,那个想法大概率就躺在 ideas.md 里再也没被打开。
OceanBase seekdb D0 想解决的就是这段路。它是 OceanBase 团队开源的 AI 原生混合搜索数据库 seekdb 的免费试用入口,一行 curl 就能拿到一个 MySQL 兼容的数据库实例,向量、全文、JSON、GIS、数据分支这些能力默认全部就绪,不用拼组件,不用登录任何账号。

本文以我最近写的一个示例项目 seekdb D0 Knowledge Base Search Demo 为主线,带你在 5 分钟内把一个“知识库搜索”原型真的跑起来,顺便把 seekdb D0 的能力边界、核心代码、扩展场景梳理清楚。
OceanBase seekdb D0 是什么
OceanBase seekdb 是 OceanBase 团队开源的 AI 原生混合搜索数据库(github.com/oceanbase/seekdb),D0 则是它面向开发者的免费试用入口。
它的定位可以用三个“零”来概括:不需要账号、邮箱或信用卡,API 一调即用,这是零注册;不用挑规格、配网络、开白名单,连接串直接返回,这是零配置;实例秒级创建,拿到凭据就能 mysql 上去,这是零等待。
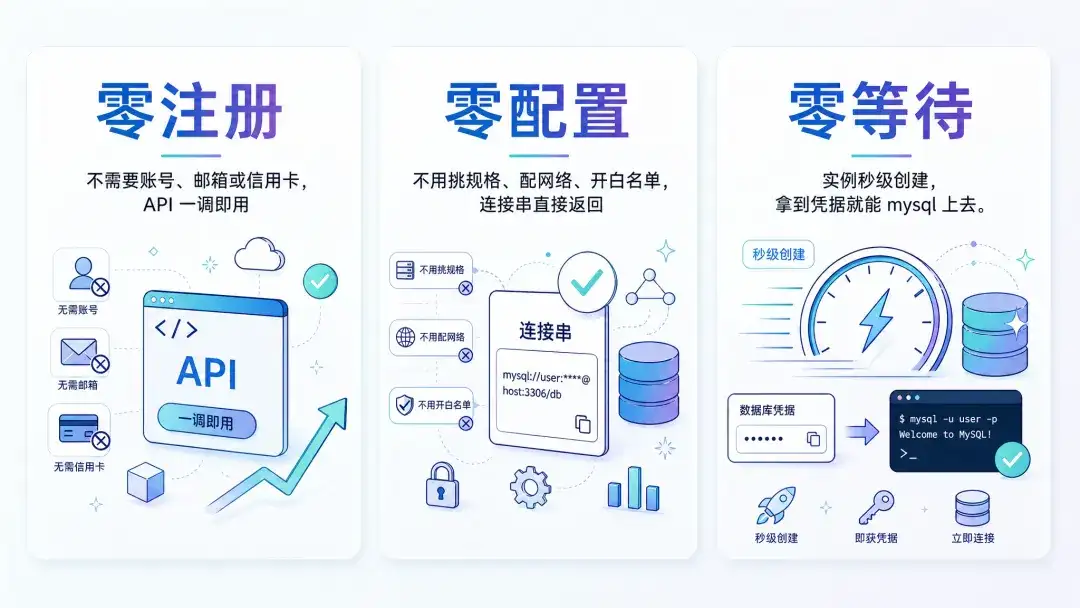
在这三个“零”之外,D0 还带着 OceanBase seekdb 的完整数据能力,SQL、向量、全文搜索、JSON、GIS、数据分支六合一。也就是说,一个实例就能把 RAG、语义搜索、结构化查询在同一条 SQL 里写完,不需要再在 MySQL、Elasticsearch、Milvus 之间做数据搬运。
使用之前有几个边界需要提前知道。每个实例的有效期是 7 天,过期后数据会被安全删除;出于安全考虑,D0 试用实例里的库内 AI 函数(AI_EMBED / AI_COMPLETE / AI_RERANK)默认禁用,如果需要体验完整 AI 函数能力,可以自部署开源 OceanBase seekdb;D0 不提供 SLA,也不建议存放生产数据或受 GDPR 等法规约束的敏感数据。
简单说,D0 是原型验证与 Demo 演示的最佳入口,不是生产替代品。关于 D0的更多信息请参阅技能文档:OceanBase seekdb D0 SKILL.md(d0.seekdb.ai/SKILL.md)。
示例项目:极简知识库搜索
OceanBase seekdb D0 Knowledge Base Search Demo 是我用 FastAPI + PyMySQL 写的极简知识库搜索服务,用来演示 D0 在真实应用里的使用姿势。它刻意没用 ORM、没用多进程、没做复杂分层,目的是让你一眼能看完、剪裁成自己的项目。
功能上,它基于 MySQL FULLTEXT 索引在标题和正文上做自然语言搜索,支持按内容类型(blog / note / ticket)、状态、工单优先级做多维过滤,查询结果按相关性排序并分页;对外暴露 Web UI 和 JSON API 两套接口,人和 Agent 都能直接调用。技术栈是 Python 3.10+ 搭配 FastAPI 和 Uvicorn,数据库驱动用 PyMySQL 并开启 TLS 加密连接。
整个 Demo 启动时会自动建表、灌入示例数据,不需要手动初始化,拿来做技术分享或客户演示都是开箱即用。
从零到一个可用的搜索服务
克隆仓库
先把代码拉下来:
git clone https://github.com/liuhao6741/seekdb_d0_search_demo.git
cd seekdb_d0_search_demo
创建 D0 实例
- Option A:Shell exports(推荐 bash / zsh)
要求 bash 或 zsh(不支持 fish 或 Windows CMD)。API 必须带 ?format=shell,否则返回 JSON,eval 不会定义 D0_* 变量。
先看一下原始返回(每次调用都会新建一个实例):
curl -s -X POST 'https://d0.seekdb.ai/api/v1/instances?format=shell'
应该看到一行行 export D0_...。如果看到 JSON(如 {"error":...})或空响应,请检查网络、VPN 或速率限制。
把它们加载到当前 shell(eval 成功时无任何输出,属正常):
eval "$(curl -s -X POST 'https://d0.seekdb.ai/api/v1/instances?format=shell')"
如果 echo 没有输出,说明 eval 没有执行有效的 export 行(shell 不对,或返回不是 shell 格式),改用 Option B。
注意:在 shell 格式下,D0_CONNECTION 是 mysql CLI 参数(用于 mysql $D0_CONNECTION),不是 mysql:// URL。本项目的 db.py 使用的是 D0_HOST、D0_USERNAME、D0_PASSWORD、D0_DATABASE、D0_PORT,这些在 shell 输出里都有。
-
Option B:JSON 响应(fish / Windows CMD / 其他场景)
curl -s -X POST 'd0.seekdb.ai/api/v1/inst…'
返回是一个 201 的 JSON,实际结构如下(凭据已脱敏):
{
"instance_id": "<12 位 ID>",
"username": "u_<12 位 ID>",
"password": "<32 位 hex>",
"database": "d0_<12 位 ID>",
"host": "gw0.apac.seekdb.ai",
"port": 2881,
"expires_at": "2026-05-20T09:03:23Z",
"connection": "mysql://u_<id>:<password>@gw0.apac.seekdb.ai:2881/d0_<id>",
"connection_string": "-h gw0.apac.seekdb.ai -P 2881 -u u_<id> -p\"<password>\" --ssl-mode=REQUIRED d0_<id>"
}
把这些字段一一填到 .env 里对应的 D0_* 变量即可(字段映射见下一节)。connection 字段是现成的 MySQL URL,connection_string 是 mysql CLI 参数,两者均可用于手工连接调试;但本应用仍需单独配置 host、user、password、database、port(除非你自行扩展 db.py 去解析 URL)。
写入 .env
cp .env.example .env
字段映射如下(README 原表):
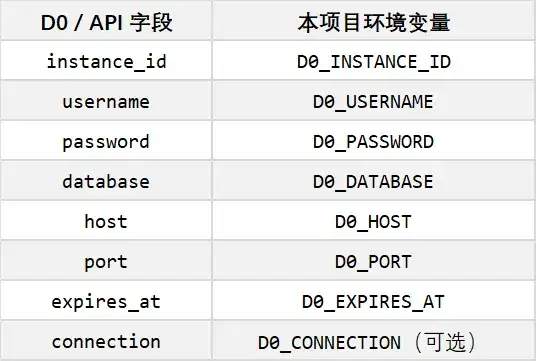
密码只在创建时返回一次,无法再次获取;实例默认约 7 天后自动过期。SQL 连接强制 TLS,本 Demo 用 PyMySQL 配 ssl=True(见 db.py)。不要把 .env 提交到 git,仓库 .gitignore 已经排除。请遵守 D0 使用策略:勿做压测或滥用,存在连接数与 QPS 限制。
安装依赖并启动(推荐 Python 3.10+)
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -r requirements.txt
cp .env.example .env # 如果还没复制
# 用 D0 凭据填好 .env
uvicorn main:app --reload --host 127.0.0.1 --port 8000
运行
-
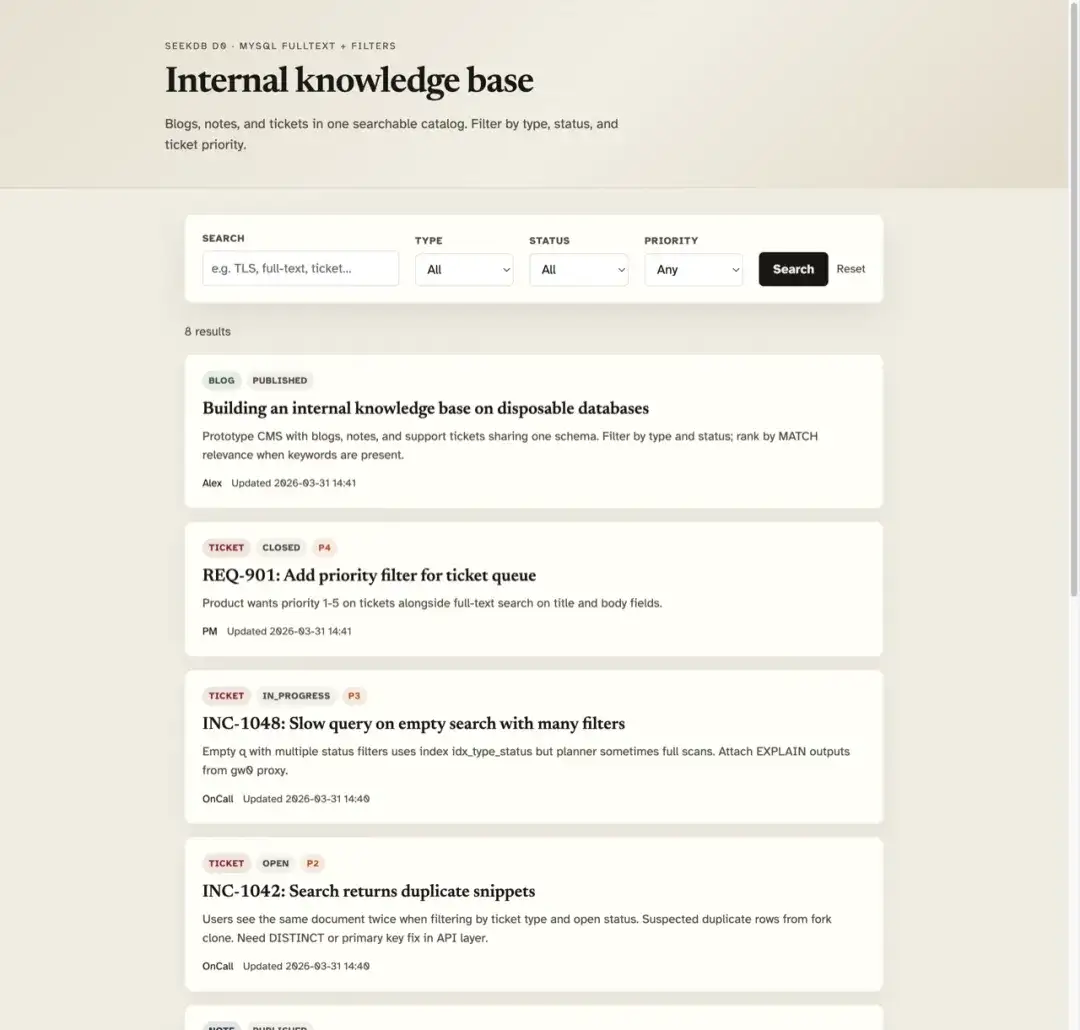
JSON API:GET /api/search?q=...&type=...&status=...&priority=...&page=...
启动时,应用会在 kb_items 不存在时自动建表,并在表为空时灌入示例数据。能在浏览器里看到下面这样的页面,并能用 TLS、FULL-TEXT 等关键词搜出条目,即表示跑通成功。
核心代码解析
完整源码见 GitHub 仓库(链接:github.com/liuhao6741/…
README 的 Project layout(链接:github.com/liuhao6741/… 已经把各文件职责说清楚了:
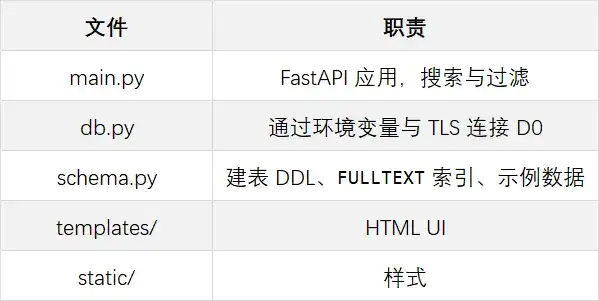
建议直接对着这三个 Python 文件读:db.py 看 TLS 连接怎么配,schema.py 看 FULLTEXT 索引怎么建在 title + body 上,main.py 看 MATCH(...) AGAINST(... IN NATURAL LANGUAGE MODE) 如何同时承担相关性评分和过滤条件——三个文件加起来不到 250 行,比任何文字解释都直观。
从 Demo 到生产形态:三个可以顺手扩展的场景
Demo 本身只用了全文搜索,但 OceanBase seekdb D0 的能力远不止于此。下面三个扩展方向,都是在 Demo 代码基础上小幅修改就能落地的。
场景 1:升级到混合搜索 RAG
真实的 RAG 系统很少只靠向量或只靠关键词,混合检索(Hybrid Search)几乎是标配。OceanBase seekdb 原生支持向量列和全文索引在同一张表上共存,一条 SQL 同时计算两种分数:
-- 给表加一列向量
ALTER TABLE kb_items ADD COLUMN embedding VECTOR(1536);
-- seekdb D0 开放 IVF 系列索引;HNSW 在自部署 seekdb 中可用
CREATE VECTOR INDEX idx_emb ON kb_items(embedding) USING IVF
WITH(DISTANCE=cosine, TYPE=ivf_flat);
-- 混合搜索:向量 + 全文
SELECT id, title,
cosine_distance(embedding, '[0.12, 0.34, ...]') AS vec_score,
MATCH(title, body) AGAINST('关键词') AS text_score
FROM kb_items
WHERE MATCH(title, body)AGAINST('关键词')
ORDER BY(vec_score * 0.7 + text_score * 0.3) DESC
LIMIT 10;
IVF_FLAT 是 IVF 系列中精度最高的索引类型,适合中小规模数据集。如果数据量大到千万级,可选用 IVF_SQ8(平衡精度与存储)或 IVF_PQ(存储优先)。完整的 HNSW 系列索引在自部署开源 OceanBase seekdb 中可用。
D0 禁用了 AI_EMBED 库内函数,向量需要在应用侧用 OpenAI、通义、bge 之类的模型生成后再写入;如果希望在 SQL 里直接调模型,可部署开源 OceanBase seekdb。
场景 2:给 Agent 一个安全沙箱
让 Agent 直接操作生产数据库,是悬在很多团队头上的一把刀。OceanBase seekdb 的 FORK 能力提供了另一种范式——给 Agent 一张可随时丢弃的副本:
-- 毫秒级创建一份独立副本(写时复制,不真正拷贝数据)
FORK TABLE kb_items TO kb_items_agent;
-- Agent 在副本上随便改
UPDATE kb_items_agent SET status = 'archived' WHERE created_at < '2025-01-01';
-- 人工审核后对比差异
DIFF TABLE kb_items AGAINST kb_items_agent;
-- 满意了合并回去,不满意直接 DROP
写时复制的原理依赖 LSM-Tree 存储引擎的版本特性:FORK 时只记录一个逻辑分支点,共享历史数据文件,仅在分支上发生写入时才产生新文件。所以 FORK TABLE 在毫秒级返回,不会因为表变大而变慢。
除了表级 FORK,D0 还提供实例级 FORK:POST /api/v1/instances/{id}/fork 会整个实例复制一份,适合做 A/B 测试环境或演示数据的分发。注意 D0 试用实例的资源较紧,实例级 FORK 偶尔会因资源限制失败,真要用建议在自部署 OceanBase seekdb 上操作。
场景 3:让 AI Agent 自己创建数据库
D0 最有意思的一点是,它把使用说明也“Agent 化”了。在 Cursor、Claude Code 之类的 Agent 环境里,你可以直接丢一句提示词:
Read https://d0.seekdb.ai/SKILL.md and create a database
to store conversation history.
Agent 会自行读取 SKILL.md,按里面的 API 规范创建实例、建表、写入。这背后是 Anthropic 推的 Skill 模式——用 Markdown 描述 API 契约,让 Agent 作为一等公民直接消费。
对开发者来说,这意味着:你的 Agent 工具链里,不再需要为“准备数据库”这件事写一行代码。
把这条路径记在你的工具箱里
回头看这 5 分钟的流程,真正有价值的不是某一个 SQL、某一个向量索引参数,而是这样一条被压缩到极致的路径:
有一个 AI 应用的想法,一行 curl 拿到数据库,克隆一个约 250 行的 Demo 作起点,顺手把向量、全文、FORK 接上,然后就已经在真实数据上跑原型了。
对开发者来说,这意味着验证想法的成本可以无限接近于零,而在 AI 应用这种高迭代密度的场景里,启动速度本身就是生产力。
OceanBase seekdb D0 提供 7 天免费试用,如果试下来觉得合适,有两条路可以走:
-
本地部署 OceanBase seekdb:开源、Apache-2.0,GitHub 上拉源码直接跑,完整能力不受限制
-
联系 OceanBase 团队:如果你的场景需要云服务、更大规模或定制化支持,我们愿意一起探索更多可能性。
如果只是好奇,也没关系。7 天够 Agent 跑不少实验了。
👉相关链接:
-
OceanBase seekdb D0 体验入口:d0.seekdb.ai
-
OceanBase seekdb 开源仓库:github.com/oceanbase/s…
-
OceanaBase seekdb 官网:seekdb.ai
