

拆解 Hermes /goal 如何用状态持久化、Judge 判定和自动续航,让 Agent 真正跑完长任务。 原文链接:AI 小老六
导语
Agent 长任务 最让人烦的地方,往往不是它不会做,而是它太容易停下来。
修一个类型错误,它修三处就回来说“完成了”;跑一轮测试失败,它等你再敲一句“继续”;做一次依赖迁移,中间需要人反复盯着终端,像给半自动机器喂指令。到了长程任务里,这种交互方式会把开发者拖回最原始的监督岗位:人不再写代码,但要不停判断 Agent 是否该接着干。
Hermes Agent v0.13.0 里加入的 /goal,解决的不是“让模型更聪明”这个泛问题,而是一个更具体的工程问题:怎样把一次目标变成一个可持续推进、可暂停、可恢复、可判定完成的运行时流程。
这件事的关键不在命令本身,而在命令背后的四个部件:外部状态、生命周期管理、Judge 判定、继续执行队列。它们合在一起,才让 Agent 从“等用户说继续”变成“知道自己还没干完”。
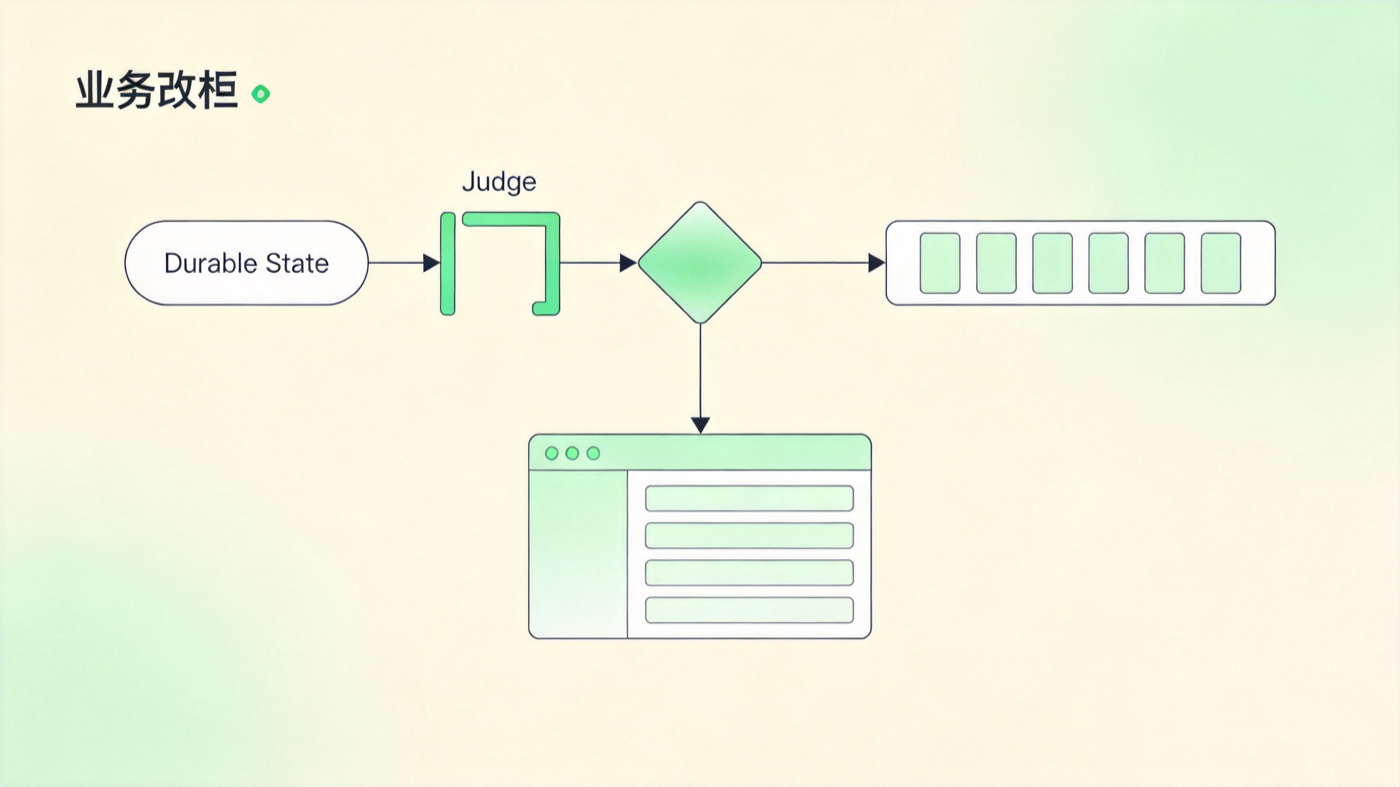
图:/goal 把目标状态、Judge 判定和继续调度放到同一个控制平面里。
长任务瓶颈:不在 Token,而在会话记忆
很多人第一次做 长任务 Agent 时,会本能地把问题归因给上下文窗口不够大。窗口再长一点,模型是不是就能把事情做完?实践里往往不是这样。
当一个任务在同一会话里滚动几十轮,系统会累积大量中间输出、错误日志、临时计划和已经过期的判断。上下文变厚后,模型并不会稳定地“记得更多”,反而更容易把噪声当成线索,把未完成事项压到注意力边缘。开发者社区常把这段质量下滑区域叫做 Dumb Zone:不是模型真的变笨了,而是会话里堆了太多会干扰判断的东西。
Ralph Loop 给出的方向很朴素:不要把长期记忆放在聊天记录里。

图:目标、外部状态与显式停止条件构成长任务执行闭环。
这个循环背后的判断很硬:文件系统和 Git 比模型上下文更适合承载长期状态。Agent 每一轮从干净的输入开始,通过代码、文档、测试结果和提交记录接住上一轮的进展。会话可以丢,工作目录不能丢。
原始 Ralph Loop 甚至可以简化成一个 Bash 循环:
while :; do cat PROMPT.md | claude -p --dangerously-skip-permissions; done
这当然不够产品化,但它把长期自主执行的骨架说明白了:固定目标、外部状态、循环执行、显式停止条件。
Hermes 的 /goal 是在这个骨架上补了一套可用的运行时。
/goal 本质:给 Agent 加一个目标控制平面
普通对话里,用户的每条消息都会触发一次推理。推理结束后,系统默认认为这一轮就结束了。/goal 改掉的是这个默认假设。
当用户输入:
/goal 修复 auth.ts 中所有 TypeScript 错误,确保 lint 和单测全部通过
系统不再把它当作一条普通 prompt,而是创建一份可持久化的目标状态。之后每一轮结束时,Hermes 都会追问一个问题:最近这一轮的结果,是否已经满足最初目标?如果没有,系统自动把“继续完成目标”的提示放回执行队列。
可以把 /goal 看成一个目标控制平面:
| 运行时部件 | 负责的问题 | Hermes 中的体现 |
|---|---|---|
| 目标状态 | 当前要完成什么,剩余多少轮,是否暂停 | GoalState |
| 生命周期接口 | 目标如何开始、暂停、恢复、清理、完成 | GoalManager |
| 完成判定 | 最近一轮是否足够满足目标 | judge_goal() |
| 继续调度 | 未完成时如何触发下一轮 | CLI pending input / Gateway FIFO |
| 目标细化 | 执行中如何追加验收标准 | /subgoal |
这个设计的好处是,Agent 不需要在聊天里“记住自己还有一个目标”。目标被系统外化 了,后续每一轮都由运行时重新注入必要信息。
GoalState:把目标写进数据库
Hermes 没有把 /goal 做成会话内的临时变量。它把目标落到了 **SessionDB.state_meta**,key 类似 goal:<session_id>。这一步看起来不花哨,但很关键。
@dataclass
class GoalState:
goal: str
status: str = "active" # active | paused | done | cleared
turns_used: int = 0
max_turns: int = 20
created_at: float = 0.0
last_turn_at: float = 0.0
last_verdict: Optional[str] = None
last_reason: Optional[str] = None
paused_reason: Optional[str] = None
consecutive_parse_failures: int = 0
subgoals: List[str] = field(default_factory=list)
这份状态解决了几个实际问题。
第一,任务可以跨会话。今天设置的目标,中途关掉终端,明天重新打开后仍然能通过 /goal resume 接着跑。
第二,执行有预算。max_turns 默认 20 轮,避免目标因为判定异常或描述过宽而无限循环。
第三,系统能记住失败模式。比如 Judge 连续返回不可解析内容,consecutive_parse_failures 会增长,超过阈值后目标自动进入暂停态,而不是继续烧钱。
第四,目标可以变细。subgoals 让用户在执行过程中补充约束,不必推翻原目标重来。
这也是 Hermes 相比只做 session-based goal 的方案更完整的地方:它没有把“长期任务”寄托在一个长会话里,而是把任务本身变成了可查询、可恢复、可审计的状态对象。
 图:目标不再依赖聊天记忆,而是沉淀为可恢复、可审计的外部状态。
图:目标不再依赖聊天记忆,而是沉淀为可恢复、可审计的外部状态。
GoalManager:长任务需要状态机,而不是 while true
有了状态,还需要一个管生命周期的编排器。Hermes 的 GoalManager 提供了这组接口:
class GoalManager:
def set(goal: str, *, max_turns: int = 20) -> GoalState
def pause(reason: str = "user-paused") -> GoalState
def resume(*, reset_budget: bool = True) -> GoalState
def clear() -> None
def mark_done(reason: str) -> None
def add_subgoal(text: str) -> str
def remove_subgoal(index_1based: int) -> str
def clear_subgoals() -> int
def evaluate_after_turn(last_response: str) -> Decision
def status_line() -> str
def next_continuation_prompt() -> str
从状态机角度看,/goal 的生命周期并不复杂,但每个状态都对应真实场景。
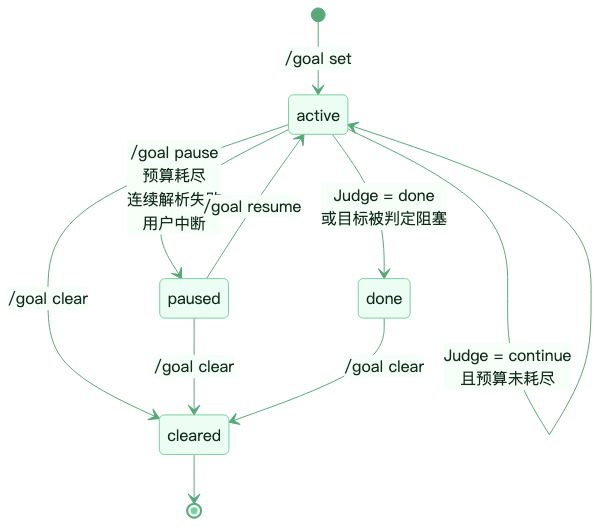 图:/goal 在 active、paused、done 与 cleared 之间流转。
图:/goal 在 active、paused、done 与 cleared 之间流转。
这里最容易被低估的是 **paused**。一个长任务运行时不能只有“继续”和“结束”。网络抖动、预算耗尽、用户临时插话、Judge 配置异常,都不该把目标直接判死。暂停态给了系统一个缓冲层:任务没有完成,但也不再盲目推进。
Judge 闭环:宁可多跑一轮,也别提前庆功
/goal 能不能可靠,核心看完成判定。Hermes 把这件事交给一个辅助模型,也就是 Judge。
每一轮结束后,系统把两段信息交给 Judge:原始目标和 Agent 最近一轮回复。Judge 只需要输出一个很窄的 JSON:
{"done": false, "reason": "仍有测试失败,需要继续修复"}
判定规则故意偏保守。只有三类情况会被认为完成:
| 判定为 DONE 的情况 | 例子 |
|---|---|
| Agent 明确确认目标已经完成 | “所有 TypeScript 错误已修复,lint 和测试均通过” |
| 最终交付物已经产生,且能看出满足目标 | 代码、报告、文档或构建产物已经落地 |
| 目标无法继续推进,需要外部输入 | 权限缺失、依赖不可访问、需求本身矛盾 |
除此之外,默认继续。
这条策略很像工程里的 false positive 控制:误判完成的代价通常比多跑一轮更高。多跑一轮只是多花一点时间和 token;提前结束会把半成品交给用户,后续还要人工排查它到底漏了什么。
Hermes 的 Judge prompt 也基本围绕这个原则设计:
JUDGE_SYSTEM_PROMPT = """
A goal is DONE only when:
- The response explicitly confirms the goal was completed, OR
- The response clearly shows the final deliverable was produced, OR
- The response explains the goal is unachievable / blocked / needs user input
Otherwise the goal is NOT done: CONTINUE.
"""
这不是追求“聪明判定”,而是追求“别乱放行”。在长任务里,这个取舍很对。
fail-open:Judge 挂了,任务不该跟着死
真实系统里,Judge 不是永远可靠。API 超时、网络抖动、模型返回非 JSON,都很常见。Hermes 没有把这些异常直接当成任务失败,而是设计了几层保护。
| 异常场景 | 处理方式 | 设计意图 |
|---|---|---|
| Judge API 调用失败 | 返回 continue | 外部依赖偶发失败时不中断主任务 |
| 最近一轮响应为空 | 返回 continue | 没有足够证据时不判完成 |
| Judge 返回非 JSON | 计数并重试 | 容忍短期格式漂移 |
| 连续解析失败达到阈值 | 自动暂停 | 避免配置错误导致无意义循环 |
| 轮次预算耗尽 | 自动暂停 | 防止失控续跑 |
典型代码大概是这样的风格:
try:
resp = client.chat.completions.create(...)
except Exception as exc:
logger.info("goal judge: API call failed; continuing")
return "continue", f"judge error: {type(exc).__name__}", False
这里的 fail-open 不是无脑继续。它只是在短暂异常下选择不打断执行;一旦异常变成连续模式,系统会切到 paused,让用户检查 Judge 模型或配置。
这个细节很工程化。长任务最怕两种极端:遇到一点波动就停止,或者明知判定链路坏了还继续跑。Hermes 在两者之间留了一个合理的台阶。
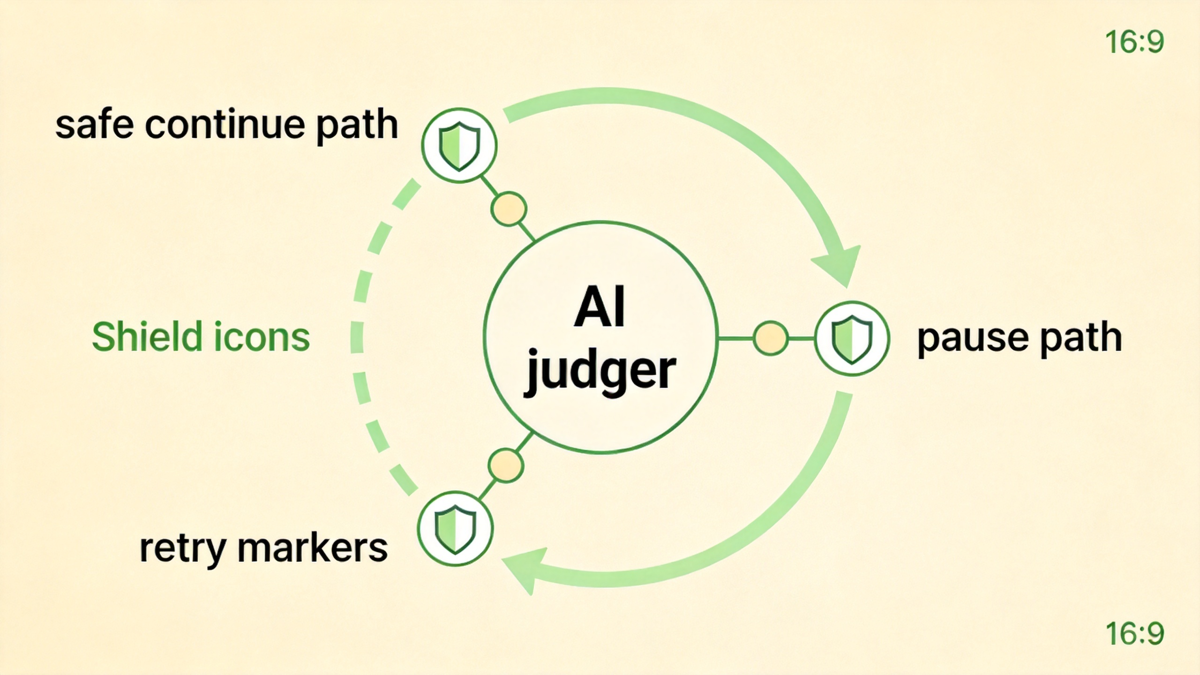
图:Judge 失败时先保守继续,连续异常再暂停,避免长任务误停或失控。
CLI 与 Gateway:自动继续不能抢用户的话
/goal 还有一个容易被忽略的问题:当系统准备自动注入“继续执行”提示时,如果用户这时发来新消息怎么办?
Hermes 的处理原则是用户优先。
在 CLI 里,继续提示会进入 _pending_input 队列;在 Gateway 场景里,继续事件通过 adapter FIFO 排队。系统会确保用户显式输入优先于自动续跑提示。这样做能避免一种很糟糕的体验:用户刚想纠正方向,Agent 已经因为自动续跑又开了一轮。
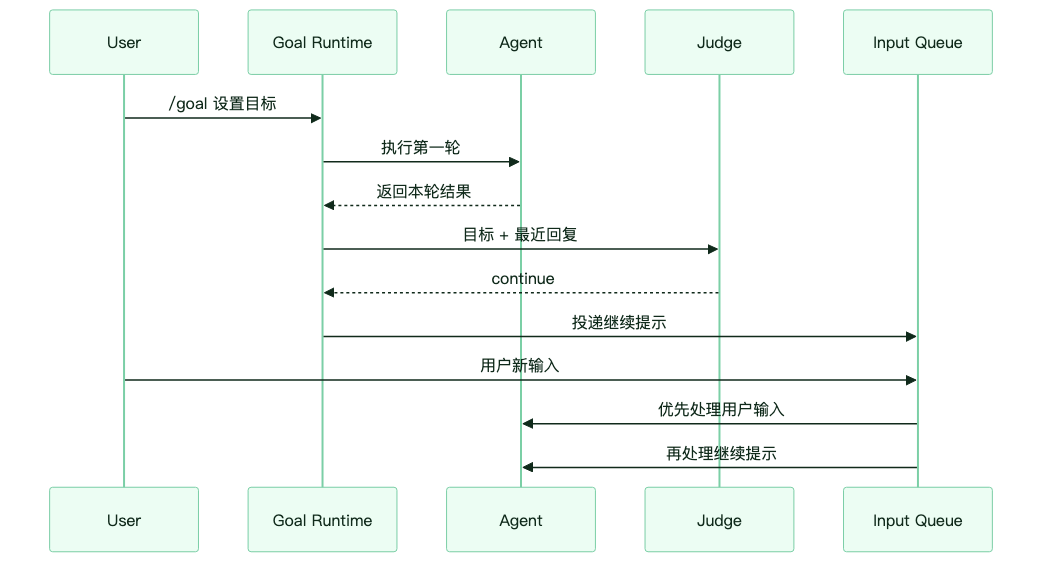
图:Judge 判定后投递继续提示,但用户输入始终优先处理。
这让 /goal 更像一个可控的后台任务,而不是一个关不掉的自动驾驶。它可以自己推进,但不会压过用户的显式指令。
Hermes 和同类方案的差异:真正拉开距离的是 持久化
/goal 这类能力在 2026 年开始快速变成 Agent 产品的标配。Codex CLI、Claude Code、Hermes 都在做,差异不在概念,而在实现边界。
| 能力维度 | Hermes Agent | Codex CLI | Claude Code |
|---|---|---|---|
| 目标状态 | SessionDB 持久化 | 偏 session-based | 偏 session-based |
| 子目标 | 支持 /subgoal | 未突出 | 未突出 |
| Judge 模型 | 可配置 provider / model | 固定策略为主 | 固定策略为主 |
| 多平台 | CLI 与 20+ Gateway 平台 | 主要面向 CLI | 主要面向官方环境 |
| 异常处理 | fail-open、解析失败计数、自动暂停 | 有继续策略 | 有继续策略 |
| 用户中断 | 可转暂停 | 依实现而定 | 依实现而定 |
Hermes 的优势不是“也有 /goal”,而是它把 goal 做成了一个跨会话、跨平台的状态系统。尤其是 SessionDB、/subgoal 和可配置 Judge 这三点,让它更适合自托管和多入口使用。
如果只是本地 CLI 玩一轮任务,session-based 方案够用;如果希望目标跨天、跨终端、跨聊天平台继续存在,状态持久化就不再是加分项,而是基础设施。
适合交给 /goal 的任务,必须能写出验收条件
/goal 不适合所有事。它适合边界清楚、可检查、需要多轮推进的任务。
适合使用 /goal | 不适合使用 /goal |
|---|---|
| 大型重构、依赖迁移、补测试 | 一两轮就能完成的小改动 |
| 安全漏洞修复、审计整改 | 需要高频人工选择的产品讨论 |
| 性能优化,有明确指标 | 目标暂时说不清的探索性研究 |
| 长时间构建、报告生成、资料整理 | 需要实时确认权限或风险的操作 |
目标写得越像验收单,Judge 越容易工作。下面这类差异会直接影响 /goal 的效果。
| 模糊目标 | 可判定目标 |
|---|---|
| 修复 bug | 修复 login 在空密码时返回 500 的问题,并补充回归测试 |
| 优化性能 | 将主 API P95 降到 200ms 以下,并保留现有单测通过 |
| 写文档 | 在 docs/api.md 补齐所有 REST 端点的路径、参数、返回值和示例 |
| 做重构 | 将 auth.ts 改为依赖注入模式,公开接口不变,覆盖率保持 85% 以上 |
一个好 /goal 最好包含四类信息:任务对象、完成条件、验证方式、边界约束。
/goal 将 auth.ts 的用户校验逻辑迁移到 AuthService,保持现有 public API 不变;补齐空密码、过期 token、重复登录三个用例;运行 pnpm lint 和 pnpm test 全部通过后停止。
这类目标不需要 Judge 猜。它只需要检查 Agent 是否给出了足够清楚的完成证据。
Judge 模型不必昂贵,但必须 稳定
Hermes 允许为 goal_judge 单独配置模型,例如:
# ~/.hermes/config.yaml
goals:
max_turns: 20
auxiliary:
goal_judge:
provider: openrouter
model: google/gemini-3-flash-preview
这是一种很实用的拆分。主任务模型要负责写代码、读文档、查问题,能力需要强;Judge 只读目标和最近一轮回复,然后判断是否继续,输入短、输出短,速度和稳定性更重要。
便宜的快速模型未必能做复杂推理,但做“是否已经明确交付”这类窄判定通常够用。真正需要关注的是格式稳定性。如果模型经常输出不可解析内容,Hermes 会靠连续解析失败保护把目标暂停,但这也说明 Judge 选择不合适。
快速体验:从更新到第一个目标
要使用 /goal,先把 Hermes 更新到 v0.13.0 或更新版本:
hermes update
启动后输入 /goal,如果能看到 goal 指令,就说明功能可用。可以先用一个风险较低的任务试水:
/goal 生成一份当前项目的 DeepResearch 风格技术报告,包含架构概览、关键模块、运行方式和潜在风险;
输出为 HTML,并在本地打开预览确认无明显渲染错误。
这类任务的好处是验收边界清楚,失败也不会破坏代码库。等确认工具链、搜索能力和前端渲染能力都配置好后,再把 /goal 用到重构、补测试或安全修复上。
如果希望报告更好看,工具配置很重要。WebSearch、文件读写、前端设计相关 skill、HTML 渲染能力都会影响最终产物。/goal 只是让任务持续推进,不能凭空补齐 Agent 没有的工具。
我对 /goal 的判断:它把 Agent 的交互单位从“回复”改成了 “完成条件”
/goal 最有价值的地方,不是少敲几次“继续”。少敲字只是表面收益。
真正的变化是,用户和 Agent 之间的契约从“回答我这一轮”变成了“持续工作,直到满足这个条件”。为了支撑这个契约,系统必须把目标、状态、预算、判定和恢复机制都工程化。Hermes 的实现恰好把这些东西补齐了大半。
它也不是银弹。目标写不清,Judge 就会摇摆;工具不给力,Agent 只能原地打转;任务涉及高风险操作,用户仍然要介入确认。但对于重构、补测、报告生成、批量修复这类长链路任务,/goal 已经把 Agent 往“能放手一段时间”的方向推了一大步。
更准确地说,/goal 让 Agent 不再只是一轮对话里的聪明助手,而开始像一个有状态的执行进程:有目标,有预算,有暂停恢复,有完成判定,也有失败保护。
这才是长程 Agent 真正需要的底座。
参考资料
- Hermes Agent v0.13.0 Release Notes[1]
- Claude Code: Keep Claude working toward a goal[2]
- Codex: Follow a goal[3]
- Hermes Agent's /goal Command Makes AI Stop Quitting Halfway Through the Job[4]
