

一个科研 RAG 系统最尴尬的失败,经常发生在报告看起来没毛病的时候:摘要顺,引用齐,结论也像样。等研究人员复核才发现,它漏了两篇该出现的论文:一篇领域综述,一篇反例实验。后面的比较、归纳、建议,全都建立在偏掉的候选池上。
过去评测 Research Agent,很多人盯最终报告:结构是否完整,语言是否流畅,引用是否像论文。AutoResearchBench 这类工作把压力提前了:复杂科学问题里,Agent 先要证明自己能把文献找全、找准,再谈证据综合。
图1:两张试卷,一张写 Literature Discovery,一张写 Evidence Synthesis
AutoResearchBench 到底在提醒什么
AutoResearchBench 面向的是 AI agents 的复杂科学文献发现能力。它关心的输入通常很短:一个研究问题、一个科学任务、一个需要证据支撑的方向。输出也很明确:Agent 找到哪些论文,能否覆盖应出现的代表文献,能否避开主题相近但并不回答问题的干扰文献。评价时,最终文字质量退到后面,先看检索结果和标准文献集合之间的匹配。
这和传统问答评测的差别很大。科研问题的限定常常藏在语境里:研究对象、方法、时间范围、数据库、文献类型、术语变体。一个 “RAG evaluation in scientific QA” 可能指检索增强生成,也可能撞上医学缩写;“MPC in robotics” 可以是 model predictive control,也可能被检索系统带去别的学科;“agentic science” 在 OpenAlex、arXiv、PubMed 里的表达也未必一致。
Google AI co-scientist、FutureHouse、PaperQA、Robin 这类系统把 Agent 推向假设生成、论文阅读、实验设计和证据抽取。它们的共同前提是:上游候选文献不能偏。漏掉综述,系统会重复别人已经否定的路线;漏掉反例实验,后续证据合成会显得过度一致;漏掉新近预印本,研究建议会落后半拍。
评测集要像审计材料,而非作文题
开发科研 RAG 时,最小可行评测集不需要一开始做成大 benchmark。50 条问题已经能暴露大量问题。每条问题配一组 gold papers,记录 DOI、PMID、OpenAlex ID;再配 near-miss papers,例如主题相近但研究对象不符;配 decoy papers,例如缩写撞车、年份不符、文献类型不符;再做 time-split,要求系统在某个时间点前后分别检索,观察新文献适应情况。
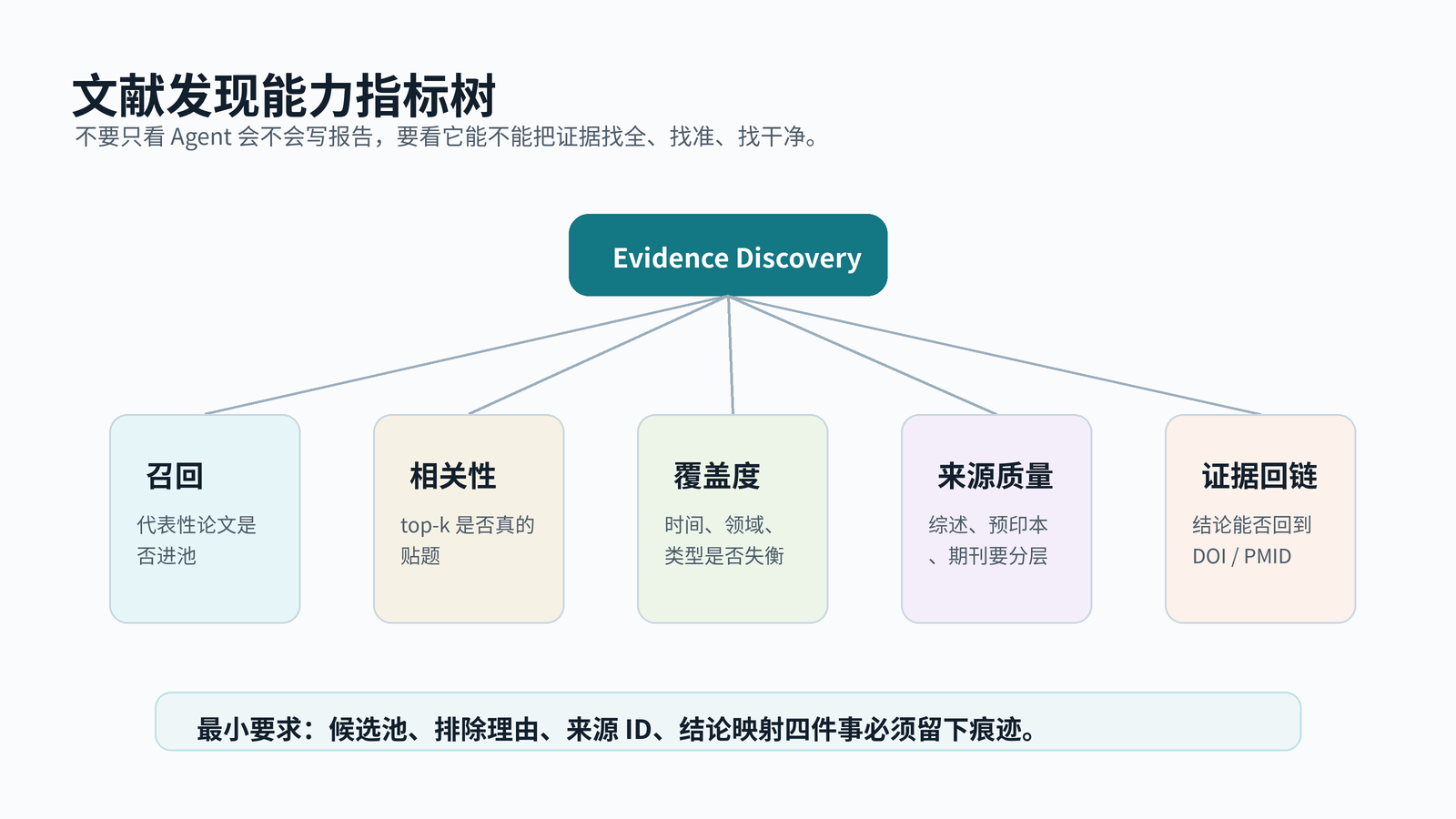
图2:问题集 → gold/near-miss/decoy → Agent 检索 → ID 对齐 → 召回率与覆盖率统计
指标也要落到 ID 级别。相关性评分太粗,会把“看起来相关”误当成“证据足够”。
| 指标 | 计算方式 | 看什么问题 |
|---|---|---|
| DOI recall | 命中 gold DOI 数 / gold DOI 总数 | 代表论文有没有回来 |
| PMID recall | 命中 gold PMID 数 / gold PMID 总数 | 医学、生命科学覆盖 |
| OpenAlex ID recall | 命中 gold OpenAlex ID 数 / gold OpenAlex ID 总数 | 跨学科文献对齐 |
| topic coverage | 命中主题桶数 / 应覆盖主题桶数 | 是否只抓到单一路线 |
| decoy rejection | 被拒绝 decoy 数 / decoy 总数 | 是否靠乱抓抬高召回 |
一个简化任务卡可以这样写,足够接进检索、重排和 CI:
{
"task_id": "arb_lit_001",
"question": "科研 Agent 的文献发现能力如何评测?",
"time_window": {"start": "2023-01-01", "end": "2026-12-31"},
"databases": ["OpenAlex", "PubMed", "arXiv"],
"required_types": ["benchmark", "evaluation", "survey"],
"exclude": ["writing assistant", "general chatbot"],
"gold": [
{
"id": "doi:10.xxxx/xxxx",
"source": "OpenAlex",
"topic": "literature discovery benchmark"
}
],
"decoy": [
{
"id": "pmid:00000000",
"reason": "包含 agent,但任务不是科学文献发现评测"
}
],
"eval": {
"match_keys": ["doi", "pmid", "openalex_id", "arxiv_id"],
"metrics": ["doi_recall", "topic_coverage", "decoy_rejection"]
}
}
一次模拟审计:从模糊问题到可复核候选池
示例/模拟审计,不代表真实检索结果。原始问题是:“科研 Agent 找论文能力怎么评?”这句话直接丢给模型,很容易返回 Deep Research 体验文、通用 RAG 评测、AI 搜索产品介绍,甚至混入论文写作助手。
更像工程任务的写法会细很多:限定 2023 年以后;对象是 AI research agents、scientific literature discovery agents;任务词包括 literature discovery、paper retrieval、evidence retrieval、benchmark、evaluation;排除纯写作助手和普通聊天机器人;数据库用 OpenAlex、arXiv,医学交叉问题再补 PubMed;输出字段必须带 DOI、OpenAlex ID,预印本允许 arXiv ID。
探索阶段可以借助 超能文献 用中文自然语言测试不同查询表达,在 PubMed/OpenAlex 中整理候选 DOI、PMID、OpenAlex ID,并保留来源,方便后续人工复核。它适合做候选文献探索和审计材料准备,不能替代 benchmark;涉及医学文献时,也只能作为证据入口、文献追踪和研究审计,不能给出诊断或治疗建议。

图3:候选文献探索界面示意,重点展示 DOI/PMID/OpenAlex ID 与来源可复核
接下来是人工标注:把候选文献分成 gold、near-miss、decoy;写清纳入和排除理由;记录检索日期;保存查询词;把 DOI、PMID、OpenAlex ID 规范化。随后把 query rewrite、retrieval、rerank 拆开看。一次提示词改动后,报告可能更顺,但 DOI recall 掉了 15%;一次 rerank 调参后,综述被排到第 30 位,摘要模型根本读不到。
回到开头那个矛盾:报告写得像样,引用也整齐,却漏掉综述和反例实验。问题通常已经在生成前发生了。查询理解没有处理缩写歧义,同义术语没有覆盖,数据库选择偏了,重排把综述压低,最后又没有用 ID 级召回报警。
下一步可以很具体:先做 50 条文献发现审计集,每条题目配 gold、near-miss、decoy 和排除理由;把 DOI/PMID/OpenAlex ID 对齐;把 query rewrite、retrieval、rerank 接入 CI;每次改模型、改提示词、改索引,都跑一次 DOI recall、topic coverage、decoy rejection。第一张卷子过线后,再评第二张卷子的证据综合。
