

一个 Research Agent 接到问题:AI Agent 能不能辅助医学和生命科学里的证据合成,减少人工筛文献成本?
工程实现很容易走向一条捷径:PubMed 搜一遍,arXiv 搜一遍,OpenAlex 再扩一圈,把前 200 条结果塞进长上下文,让模型写报告。报告会很顺,引用也足够多。麻烦出在更早的地方:第一轮候选文献里,可能已经混进重复预印本、低相关综述、相邻学科噪声,以及同一研究的多个版本。
Deep Research 类产品把文献入口推到了台前。OpenAI Deep Research 让自动查资料写报告进入大众视野;FutureHouse 的 PaperQA、Robin 把文献问答放进科研工作流;Google AI co-scientist 把假设生成和文献证据连在一起。AutoResearchBench 开始考复杂科学文献发现能力,也提醒开发者:检索入口已经不是附属模块。

图1:Research Agent 面前有 PubMed、OpenAlex、arXiv 三个入口,旁边是一张待清洗的候选池表
第一轮候选池,最容易脏在看不见的地方
跨库检索的难点,不等于“多搜几个库”。PubMed 有 PMID 和 publication type,OpenAlex 覆盖广但类型混杂,arXiv 更新快却常有正式发表版本。三者混排后,排序靠前不代表证据更强。
常见污染包括:
- 术语歧义:RAG 在计算机语境里指 retrieval-augmented generation,在医学语境里可能出现在其他缩写链条中。
- 预印本重复:arXiv 版本和期刊 DOI 版本同时出现,模型可能当成两篇独立证据。
- 综述挤占:综述可读性强,容易被模型过度引用,压住实验论文和评估论文。
- 学科漂移:OpenAlex 会召回教育学、管理学、HCI 里的 agent 研究,未必服务临床证据合成。
- 旧论文漏检:经典筛选、数据抽取、系统综述自动化方法,标题未必命中最新 LLM 术语。
如果问题进入医疗 AI 场景,还要加一条安全边界:这些系统只能做证据入口、文献追踪和研究审计,不能输出诊断、治疗建议,也不能替代医生判断。医学 RAG 的错误引用,会直接影响后续假设和研究设计。
模拟审计:一个模糊问题怎么变成候选表
示例问题:
“AI Agent 在临床研究证据合成里有没有可靠应用?重点看自动筛选、数据抽取和综述生成,排除纯聊天机器人。”
我会先把它拆成检索任务:对象是 clinical evidence synthesis;任务是 screening、data extraction、systematic review automation;技术词包括 agent、LLM、RAG、PaperQA;排除 patient-facing chatbot、clinical diagnosis。
第一轮可以用中文自然语言发起,再落到结构化字段。比如把 超能文献 放在上游入口,用中文问题召回 PubMed / OpenAlex 结果,并保留 DOI、PMID、OpenAlex ID 等来源信息;arXiv 预印本单独抓取,后续再做版本合并。它在这里只承担检索与证据入口角色。
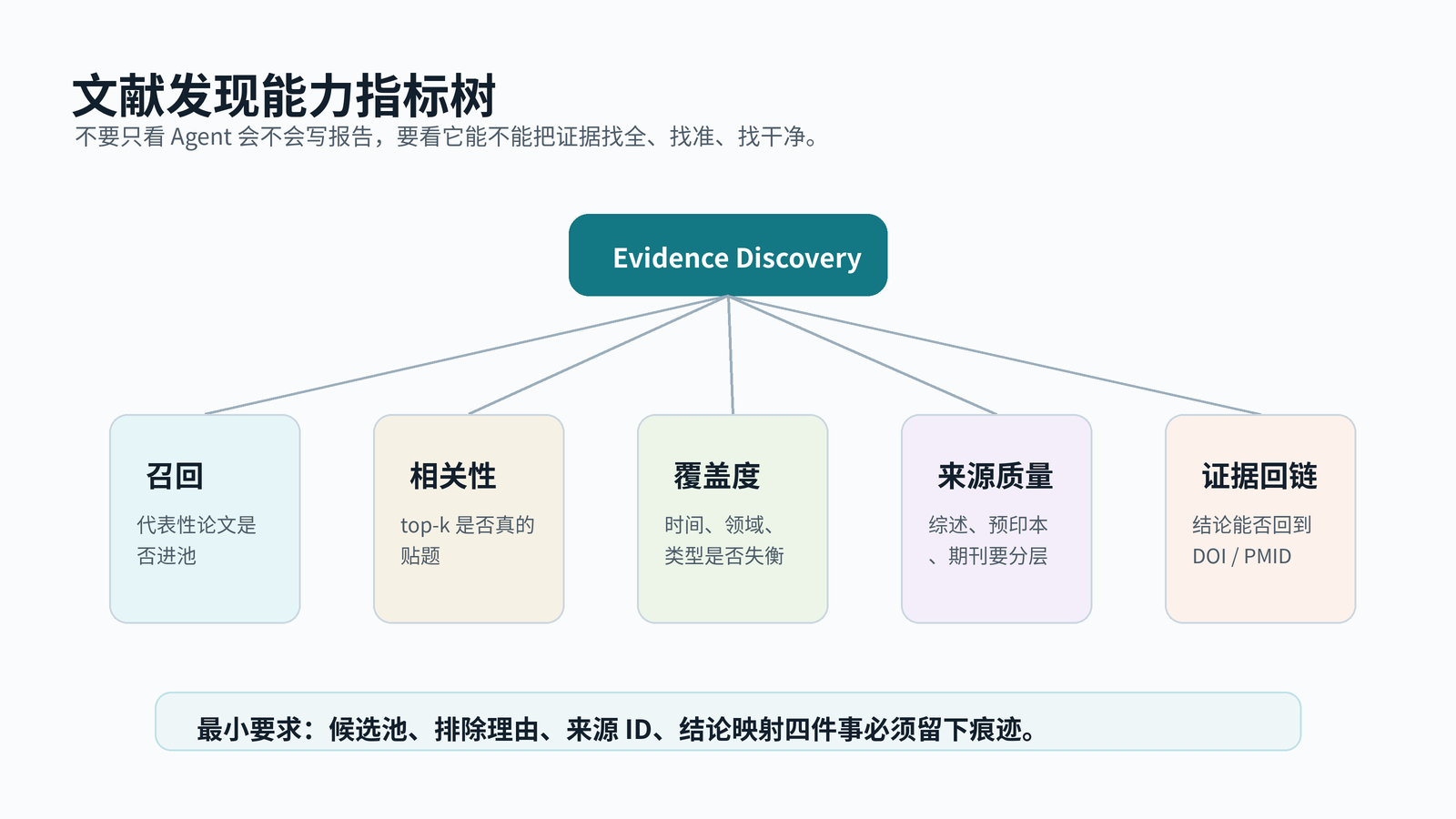
图2:自然语言问题 → 查询重写 → 多库召回 → 候选池去重/分层 → Evidence Record → Deep Research 报告
模拟审计时,第一张表要有现场感:
| title 简写 | source | type | version_group | include_reason / exclude_reason |
|---|---|---|---|---|
| LLMs for systematic review automation | PubMed | review | null | 纳入背景层;排除效果证据层,缺少人工对照评估 |
| Agentic workflow for evidence screening | arXiv | preprint | vg-017 | 暂存;发现期刊 DOI 后降级为版本记录 |
| Automated data extraction in clinical reviews | PubMed | method | vg-021 | 纳入方法评估层;有任务指标和人工标注对照 |
| AI agents in medical education search | OpenAlex | other | null | 排除;学科漂移,目标是教学反馈 |
| PaperQA-style retrieval for biomedical QA | OpenAlex | method | vg-033 | 纳入候选;需复核是否覆盖 evidence synthesis |
最小字段可以这样落库,先别急着做漂亮 UI:
{
"record_id": "string",
"title": "string",
"abstract": "string",
"source": ["PubMed", "OpenAlex", "arXiv"],
"doi": "string|null",
"pmid": "string|null",
"openalex_id": "string|null",
"publication_type": "trial|review|preprint|method|other",
"query_trace": [
{
"query": "LLM agent systematic review screening",
"database": "PubMed",
"rank": 12,
"time": "2026-05-16"
}
],
"version_group": "string|null",
"include_reason": "string",
"exclude_reason": "string|null",
"audit_status": "candidate|included|excluded|needs_human"
}
这里最容易被省略的是 query_trace。它决定后面能否复盘:一篇论文来自“systematic review automation”,还是来自“AI agent clinical trial”,含义差很多。前者可能服务筛选与抽取,后者可能只是临床试验招募 agent,进入报告后会把问题带偏。
长上下文会放大排序错误
长上下文能吞下更多材料,但模型读到的是一串已经排序的输入。候选池把综述、预印本、新闻式论文和实证评估混排后,生成模型会顺着可读性最高的材料组织叙事。它未必编造,却会把弱证据写得像强证据。
多 Agent 系统也不该让所有角色读同一层材料。Hypothesis Agent 可以看宽候选层,用来发现研究空白;Critic Agent 要看到排除理由和版本关系;Reviewer Agent 只读经过去重、标注类型、能追溯 ID 的 Evidence Record。否则,多 Agent 只是把同一批脏数据复述多遍。
图3:直接喂给 LLM 的长列表 vs 经候选池治理后的分层证据
回到开头的矛盾:PubMed、arXiv、OpenAlex 混查之后,前 200 篇看起来很丰富,实际可能把同一预印本和正式论文算了两次,把综述当成效果证据,把教育学里的 agent 研究带进临床证据合成。报告越顺,越要先看它有没有留下检索边界和排除记录。
下一步可以很小:先做 50 条候选文献审计集。每条保留 source、ID、query_trace、publication_type、include_reason、exclude_reason 和 version_group。等这张表能被人工复核,再让 Research Agent 写综述、提假设、生成报告。
