

很多科研 AI 工具最容易演示的部分,是把一堆文献整理成报告。真正难的部分在前面:问题有没有拆对,候选文献池有没有漏掉关键分支,模型最后写出来的判断能不能回到来源。
如果只是查一个明确关键词,普通检索足够快。但复杂问题不一样,比如“近三年 LLM agent 在 systematic review、experiment design、data analysis 里的可复现 benchmark”。这里面有时间范围、任务类型、评价方式、论文类型和跨学科表达差异。一个 query 很难一次打中。

问题不是“搜不到”,是搜到以后不可审计
复杂科研检索常见的失败不是空结果,而是结果看起来很多,实际证据结构很乱。
比如 Research Agent 相关主题,可能同时出现这些表达:
- AI scientist / autonomous scientist
- literature review agent
- research copilot
- hypothesis generation
- experiment planning
- scientific discovery benchmark
如果系统只把它们混成一个大向量召回,再让模型总结,报告会很顺滑,但你很难知道:哪些 query 贡献了结果,哪些方向没覆盖,哪些论文只是关键词相似,哪些结论真的有来源支撑。
更稳的做法是把检索拆成几个可检查的中间产物:
| 产物 | 作用 | 失败时怎么发现 |
|---|---|---|
| query plan | 记录问题如何被拆成多组检索式 | 看是否遗漏时间、任务、对象和排除项 |
| candidate table | 保存候选文献、来源库、DOI/PMID/OpenAlex ID | 抽样检查 top-k 是否贴题 |
| dedupe report | 去重同题论文、预印本、会议版、期刊版 | 看重复项是否污染排序 |
| claim map | 把报告里的判断绑定来源 | 看结论是否脱离证据 |
这套东西不性感,但它决定了 AI 写出来的报告能不能被复核。
专家模式适合放在“候选池构建”这一步
所谓专家模式,不应该被理解成“按一下就得到最终答案”。更合理的位置,是在候选池构建阶段用更多推理和检索轮次,把复杂问题拆开、扩展、交叉验证。
以“AI Agent 辅助科研”这个题为例,我会先写一个粗 query:
LLM agent for scientific research literature review benchmark experiment design data analysis
这条 query 很容易召回泛泛的 AI for science 文章。下一步要拆:
("LLM agent" OR "research agent" OR "AI scientist")
AND ("literature review" OR "systematic review" OR "hypothesis generation")
AND ("benchmark" OR "evaluation" OR "workflow")
AND (2023 OR 2024 OR 2025 OR 2026)
然后再分支检索:
branch_1 = literature review agent + evidence discovery
branch_2 = AI scientist + benchmark + autonomous research
branch_3 = experiment design agent + tool use + reproducibility
branch_4 = data analysis agent + workflow + human review
专家模式的价值就在这里:它更适合把一个中文复杂问题拆成多轮检索、候选池和来源回查,而不是把“检索”和“写报告”压成一步。你可以把 超能文献 当作这个流程里的证据入口:用中文描述研究问题,跨 PubMed / OpenAlex 做候选文献发现,再回到来源列表和摘要做人工复核。这里说的是工作流节点,不是让工具替你判断论文质量。
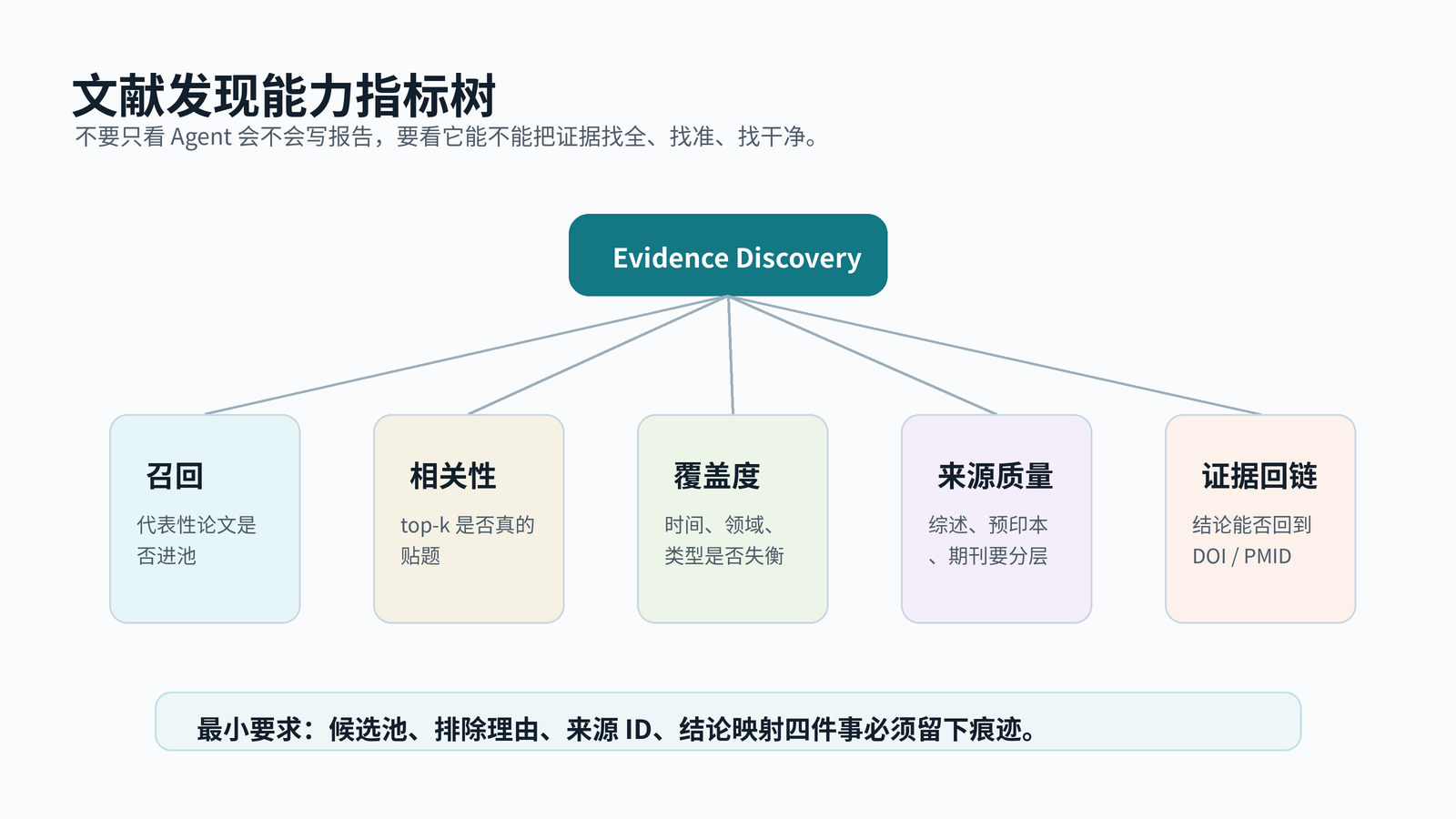
判断检索质量,别只看报告写得像不像
我更关心四个指标。
第一是覆盖度。候选池里是否同时有综述、benchmark、方法论文、应用案例,而不是只挤在一个热门关键词上。
第二是相关性。top 20 里有多少文章真的回答你的问题。这个指标最好人工抽样,不要完全交给模型自评。
第三是来源质量。预印本、会议论文、期刊论文、综述、数据集说明,应该分层标注。否则模型可能把“观点很新”和“证据更强”混在一起。
第四是结论回链。报告里每个关键判断,都应该能回到候选文献表里的来源 ID。没有来源 ID 的句子,最好先当成写作建议,而不是事实结论。
一个最小可落地流程
如果要在团队里试这件事,不必一开始做完整 Research Agent。我会先做一个很朴素的流程:
{
"question": "LLM agent 在科研工作流中的可复现评测进展",
"query_plan": ["literature_review", "benchmark", "experiment_design", "data_analysis"],
"source_scope": ["PubMed", "OpenAlex"],
"candidate_pool": {
"dedupe_by": ["doi", "pmid", "openalex_id", "title_similarity"],
"sample_top_k": 30
},
"review_fields": ["relevance", "study_type", "task", "evidence_level", "limitations"],
"report_rule": "每个关键判断必须绑定 source_id"
}
先用这个流程跑 3 个主题,人工抽样看候选池质量。候选池稳定以后,再让模型写报告。顺序反过来,很容易得到一篇漂亮但没法追责的综述。
结尾
复杂科研问题不是不能用 AI 查,而是不能把检索、筛选、去重、证据映射和写作混成一个黑箱。专家模式真正值得用的地方,是把问题拆细、把候选池做厚、把来源留下来。
报告可以晚一点生成。证据入口先干净,后面的 AI 写作才有可信的地基。
