人类智能和人工智能的关系,在我看来更像是鸟类飞行和飞机飞行的关系。飞机并不能让人像鸟一样自由自在地飞翔,却实现了载人飞行,并极大提升了人类的生产力和运输效率。同样,人工智能并非复刻人类智能,也对社会产生了深远影响。因此,在使用 AI 的同时,我们有必要理解它的基本原理,明确它的能力边界。虽然我个人认为现在的ai无法带领人类走向真正的AGI时代。但大语言模型已经是继计算机和互联网之后极具革命性的技术形态之一。它的伟大之处,不只是提升了信息处理效率,更在于它以工程化的方式呈现了“事物之间普遍联系”的哲学思想。
前言
在讲解当前LLM基本原理之前我个人认为应该先了解了解神经网络是怎么进行训练的,了解一下为什么neural network可以自动进行参数调整,以及神经网络为什么可以自动完成我们指定的任务而不需要再像以往那样需要我们自己完成算法规则编写。
基础知识
张量
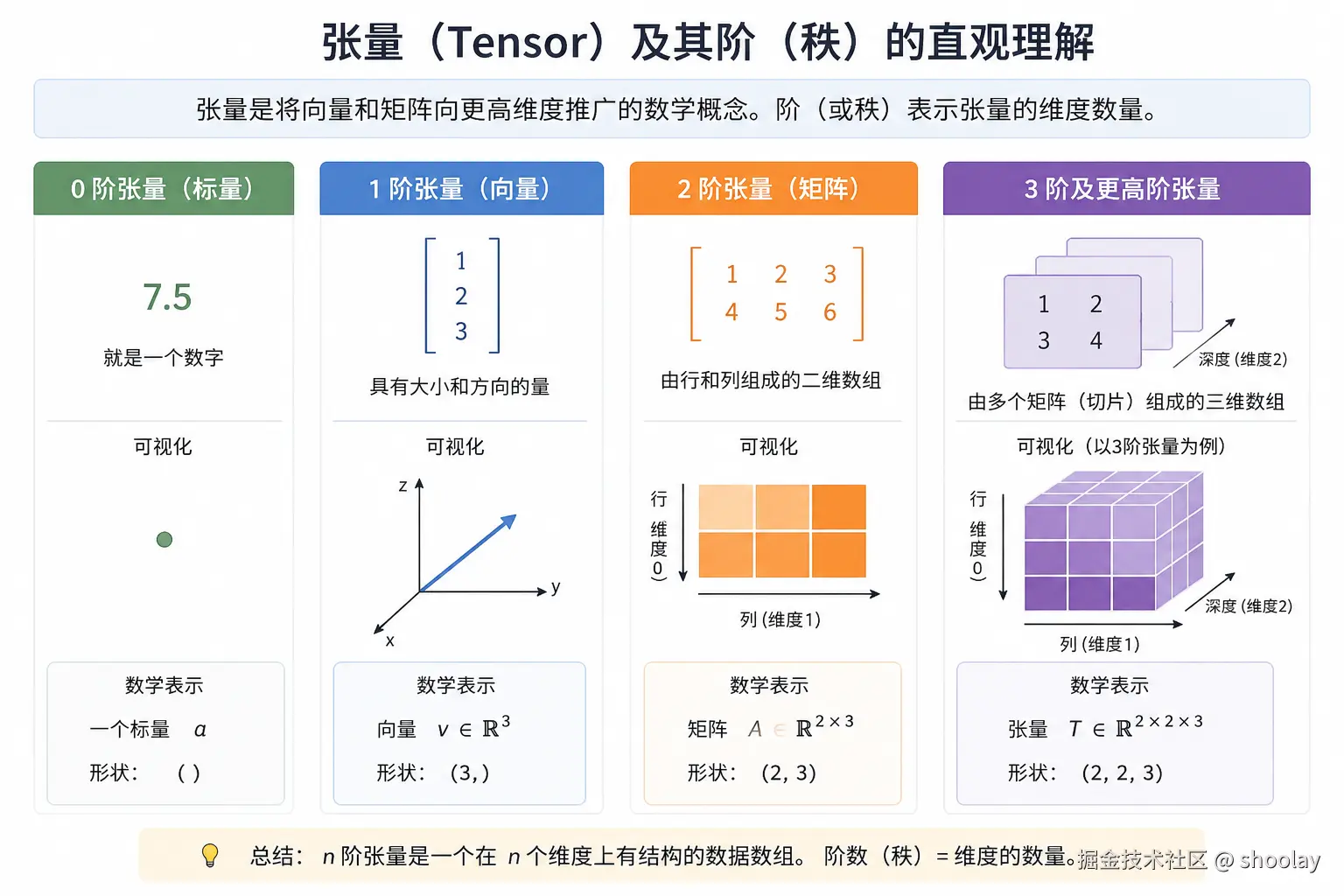
张量代表一个将向量和矩阵向更高维度的推广的数学概念。换句话说,张量是可以用它们的阶(或秩)来描述的数学对象,阶(或秩)表示了张量的维度数量。例如,一个标量(就是一个数字)是 0 阶张量,一个向量是 1 阶张量,一个矩阵是 2 阶张量。
导数
y=f(x)
一个量在某一点附近的瞬时变化率。导数就是函数图像在某一点的斜率。这里叫做导数意思就是由原函数推到出来的新的函数在某个点的值
y′=f′(x)=limΔx→0Δxf(x+Δx)−f(x)
偏微分(偏导)
当一个函数有多个变量时,只看其中一个变量的变化,暂时把其他变量当成常数,然后求它的变化率 比如
f(x,y)=x2+xy+y2
那f函数对x的偏微分可以表示为
∂x∂f=2x+y
链式法则
外层函数先求导,内层函数保持不变;然后再乘以内层函数的导数
dxd(f(g(x)))=f′(g(x))⋅g′(x)
非严格证明:
假设
y=f(x)
u=g(x)
则有
Δy=f(u+Δu)−f(u)
Δu=g(x+Δx)−g(x)
而
ΔxΔy=ΔuΔy⋅ΔxΔu
当Δx→0 如果g是可导的一定有 Δu→0
因为极限乘法公式
limΔ→0Δu=limΔx→0(ΔxΔu⋅Δx)=limΔx→0ΔxΔulimΔx→0Δx=0
取极限,使用极限的乘法公式就有
limΔx→0ΔxΔy=limΔx→0(ΔuΔy⋅ΔxΔu)=limΔx→0ΔuΔy⋅limΔx→0ΔxΔu=limΔu→0ΔuΔy⋅limΔx→0ΔxΔu
依据导数的极限定义就有
dxd(f(g(x)))=f′(g(x))⋅g′(x)
梯度
梯度是一个向量,它包含了多元函数(即输入包含多个变量的函数)的所有偏导数
(∂x1∂f,∂x2∂f,∂x3∂f...)
他的存在就是让我们的神经网络能够自动根据损失函数确定应该增加还是减少一定数值的偏导数,也就是所谓的梯度下降
神经网络
基本概念
神经网络可以理解为一个实现 y=f(x) 的复杂函数系统。它使用多层结构和大量可调参数,将输入 x 映射为输出 y。训练神经网络的过程,本质上就是不断调整这个函数系统中的参数,使函数 f 能够越来越准确地表达输入与输出之间的关系。
我们的目标是:通过足够多的数据对这个复杂系统的参数进行修正,使它不仅能在已有数据上得到正确结果,也能在面对新的数据时,仍然给出合理的输出。
这也就是为什么神经网络可以自动完成我们指定的任务而不需要再像以往那样需要我们自己完成算法规则编写。因为我们把现实的任务抽象成了这样一个有明确的输入输出计算关系的模型(也就是一旦现实任务不遵守这样的一个建模的时候,神经网络将无法得到很好的效果)
损失函数(loss)
因此,我们需要一种方法来衡量神经网络的输出结果是否合理,也就是判断模型的预测结果与我们期望的正确结果之间有多大差距。对应的计算公式称为损失函数。在实际任务中,不同类型的问题会采用不同的神经网络结构,也会使用不同的损失函数。例如,回归任务通常关注预测数值与真实数值之间的差距,分类任务则关注模型预测的类别分布与真实类别之间的差距。损失函数的作用就是量化输出结果,从而为后续的参数调整提供方向。
神经网络训练
当我们给与一个神经网络一个标注好的输出y和输入数组x=[x1,x2.......],如果这个loss函数得到的结果偏离了预期,我们应该怎么去调整参数呢
举个例子
假设我们要训练一个特别简单的神经网络,让它根据两个输入预测一个结果:
y^=w1x1+w2x2+b
其中:
x1,x2是输入;w1,w2是权重参数;b是偏置参数;y^是模型预测结果。
如果使用平方误差作为损失函数:
L=(y^−y)2
假设有一条训练数据:
x1=1,x2=2,y=5
也就是我们希望输入 (1,2) 后,输出接近真实答案5:
在模型的最开始我们假设参数随机初始化成:
w1=1,w2=1,b=0
代入上面的神经网络模型就有
y^=1×1+1×2+0=3
但真实答案是5(也就是我们给的训练数据),所以也就是模型预测小了。对应的损失函数的值是(3-5)^2 = 4
那么如何调整 w1,w2,b这几个参数让 L 变小?因为我们现在是知道x1和x2的值,不知道w1和w2的值,预测模型L=L(x)换个角度看也可以表达成L=L(w),为了能够知道应该增加w还是应该减少w,可以使用
L(w+Δw)−L(w)
来观察损失变化,如果L(w+Δw)−L(w)<0就说明本次的调整让损失函数变小了,这个时候就有了一个问题哪个方向是最好用的呢,于是可以很自然的想到了导数
dwdL=limΔw→0ΔwL(w+Δw)−L(w)
如果这个导数值<0 那我们的Δw>0可以使L(w+Δw)−L(w)<0,相反 如果这个导数值>0 我们需要让Δw<0才能让L(w+Δw)−L(w)<0
由于导数和Δw符号刚好相反,我们就可以让
Δw=−η⋅∂w∂L
其中 η>0 通常我们称这个参数为学习率
也就是
wnew=w−ηdwdL
有了调整的方法,我们回到刚才的例子并带入上面具体的值就有
∂w1∂L=2(y^−y)⋅x1=2∗(3−5)∗1=−4
∂w2∂L=2(y^−y)⋅x2=2(3−5)∗2=−8
∂b∂L=2(y^−y)=2(3−5)=−4
假设采用的学习率是0.1 可以得到新的参数值为
w1new=1−0.1×(−4)=1.4
w2new=1−0.1×(−8)=1.8
bnew=0−0.1×(−4)=0.4
验证一下 我们可以得到新的预测值
y^=1.4∗1+1.8∗2+0.4=5.4
对应的损失函数值就是(5.4-5)^2 = 0.16 < 4
所以本次学习使得预测值更加接近真实值,也就是说我们完成了一步训练
总结
以上就是我理解的神经网络如何自动完成训练的简单的过程,以及当我们把任务抽象成一个从输入到输出的复杂映射系统以后神经网络为啥可以不依靠人工手写具体规则来完成任务。
所谓“自动训练”,本质上并不是模型凭空产生智能,而是我们先将任务抽象成一个可计算、可优化的数学模型,再通过数据和优化方法不断修正参数,让模型逐渐具备完成指定任务的能力。另外从上面的推导过程也可以看出来,神经网络训练中使用的数学都是比较基础的且非严格意义上的数学推导过程,更多的还是工程实践
下一篇我们将基于以上知识点聊聊transformer架构中如何使用embedding嵌入token到多维空间,以及如何实现注意力矩阵


