


摘要:Skill SDK 是 AI Agent 工程化的核心基础设施,涵盖 manifest 元数据定义、Tool Schema 校验、permissions 权限模型、脚手架开发、热重载和 SemVer 发布链路六大模块。
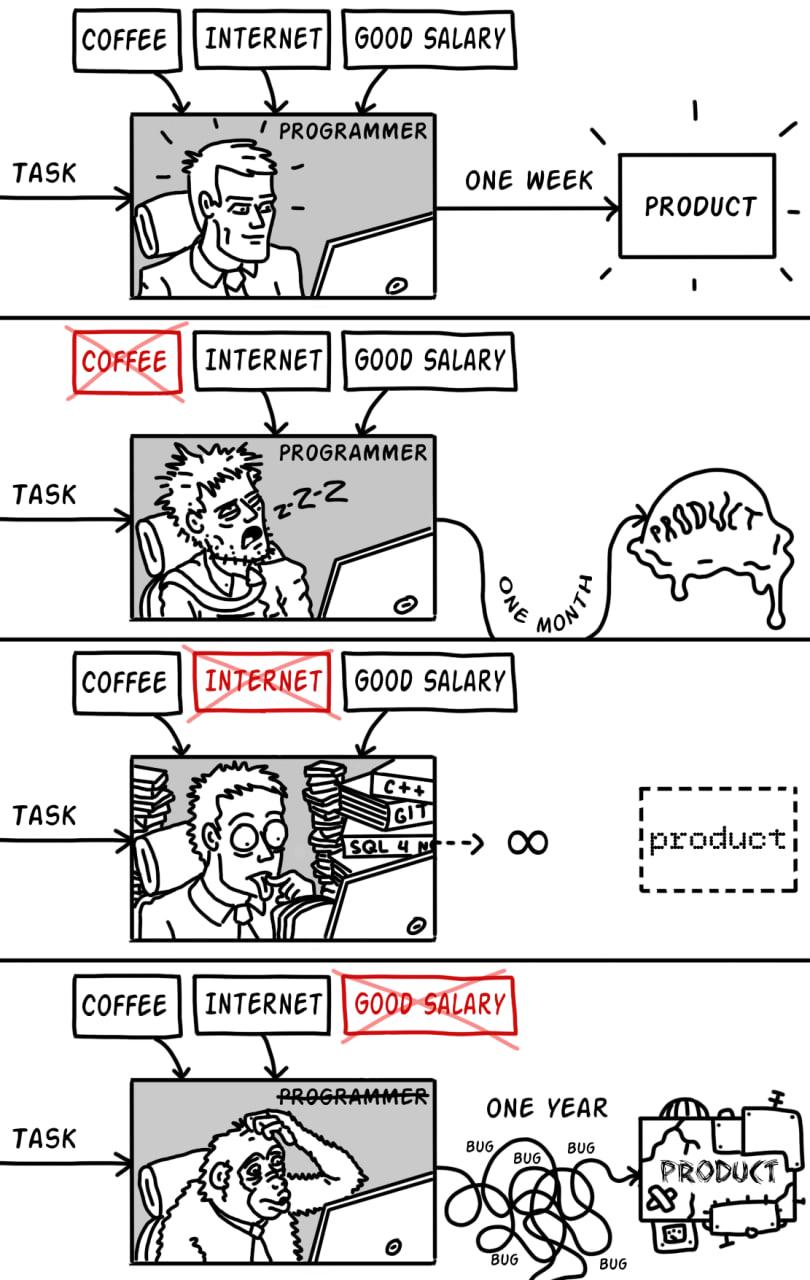
群里突然弹出一条告警:「线上 Agent 工单路由功能集体失效,用户输入什么都回复『无法理解任务』」。
值班工程师查了半天,发现是一个 Tool Schema 里的 required 字段在 Anthropic 侧根本没有显式声明——模型以为自己猜对了参数,实际上把必填字段当成了可选项。
这个 bug 藏在两套 Schema 规范的细微差异里,在测试环境没触发,因为测试用例碰巧把所有字段都填全了,上线才炸。
这不是段子。这是 Skill SDK 在生产环境里真实会遇到的典型翻车。
为什么 Skill SDK 成了 AI Agent 面试的新门槛
2026 年上半年,Anthropic 的 Claude Code 已被不少企业内部团队定为首选 AI Coding 工具,OpenAI 在 4 月密集更新了 Codex,宣布支持后台多 Agent 并行运行
这条告警,我去年Q3见过一次
。
整个 Agent 开发赛道呈现「三足鼎立 + 快速迭代」的格局,Skill 作为 Agent 调用工具的标准封装单位,其 SDK 设计能力开始直接出现在岗位 JD 上。
OpenAI 放出的 Applied AI Engineer (Codex Core Agent) 岗位,薪资范围在 385K,核心要求之一就是「能设计可组合的 Tool Schema,支持多 Agent 工作流」OpenAI Jobs: Applied AI Engineer, Codex Core Agent。
Anthropic 的 Fellows Program 在 AI Safety 和 AI Security 两个方向上,也都把「理解工具调用机制」列为加分项 Anthropic Fellows Program。
这些信号说明一件事:Skill SDK 的完整生命周期——从 manifest 定义、Schema 校验、权限管理,到脚手架开发、热重载调试和 SemVer 发布——已经成为 AI 应用工程师的工程硬技能,不再只是「会用 LangChain 调一下 API」那么简单。
面试官开始问这个的底层逻辑也很简单:Agent 能不能稳定跑起来,不取决于 Prompt 写得有多漂亮,而取决于 Tool Schema 定义得够不够精确、权限边界划得够不够清晰、发布流程有没有 CI 校验兜底。
当面试官追问「你们团队的 Skill 是怎么管理的」,他想知道的其实是你有没有踩过「本地跑通、线上炸」「OpenAI 侧校验通过、Anthropic 侧静默失败」这类坑。
manifest.yaml:Skill 的「身份证」与所有元数据的起点
任何一个 Skill 上线之前,必须先有一份 manifest.yaml。
这份文件是 Skill 的「身份证」——Agent 运行时从这里读取 Skill 叫什么、版本多少、提供哪些工具、需要哪些权限、从哪个入口文件启动。
没有它,Agent 根本不知道这个 Skill 能干什么、该不该加载、出了问题怎么排查。
六大核心字段的设计意图
manifest.yaml 的核心字段通常包含以下六项:
name: ticket-triage # Skill 全局唯一标识,遵循 kebab-case
version: 1.2.0 # 语义化版本,SemVer 规范
description: >-
将客服工单按紧急程度分类并路由到对应团队。
支持 enterprise 用户和含 "outage" 关键词的工单自动标记高优先级。
# description 是给 LLM 看的第一手上下文,不是给人看的说明文档
tools:
- name: route_ticket
description: 当用户提交了一个客服工单时调用,用于分类优先级和路由团队
input_schema:
type: object
properties:
subject:
type: string
description: 工单主题
customer_tier:
type: string
enum: [free, pro, enterprise]
required: [subject, customer_tier]
permissions:
- network: read # 仅允许读操作,不允许主动外发请求
- filesystem: none # 不需要文件系统访问
- database: write # 需要写入工单状态
- external_api: none # 不调用外部第三方 API
entry: ./src/index.ts # Skill 的入口文件,Agent 运行时加载此模块
name 和 version 构成 Skill 的唯一身份标识,这和 npm 包管理逻辑一致。
description 是给 LLM 看的——它的措辞直接决定模型是否正确选择这个 Skill 而不是隔壁那个功能相近的 Skill,这是 Anthropic 官方文档反复强调的「description 权重」问题 Anthropic Tool Use Documentation。
tools 数组定义 Skill 暴露的所有工具,每个工具的 input_schema 是 JSON Schema 规范的子集,这里就是 OpenAI 和 Anthropic 分歧最大的地方。
permissions 字段是沙箱安全模型的核心,后面会单独拆。entry 则告诉 Agent 运行时该加载哪个文件。
典型 manifest 编写错误与避坑
实际开发中最常见的 manifest 错误有三类。
第一类是 name 不规范。有的团队用驼峰命名 ticketTriage,有的用下划线 ticket_triage,还有的直接写中文。
Skill SDK 通常要求 kebab-case(字母小写、单词间用连字符),因为这个名字会被用在文件路径、API 路由和日志标签里,不一致会导致路径解析失败或日志无法关联。
第二类是 version 不遵守 SemVer。Breaking Change 没有升 Major,导致下游 Skill 依赖方在不做任何适配的情况下升级后集体报错。
SemVer 规范很明确:Major(不兼容的 API 变更)、Minor(向后兼容的功能新增)、Patch(向后兼容的 bug 修复)。
如果修改了 input_schema 的必填字段、删除了某个 tool 或者改变了 entry 文件的导出接口,这都属于 Breaking Change,必须升 Major。
第三类是 description 写得太空洞。「这是一个工单路由 Skill」这种描述等于没写,LLM 无法据此判断什么时候该调用这个 Skill。
正确做法是把 description 写成「在用户提交客服工单、需要按紧急程度分流到 support-ops 或 customer-care 团队时调用」,让模型能从上下文里直接推理出调用时机。

description 写太泛,模型选错工具,这 bug 比代码错还难查
Tool Schema 的六处结构差异与生产级校验策略
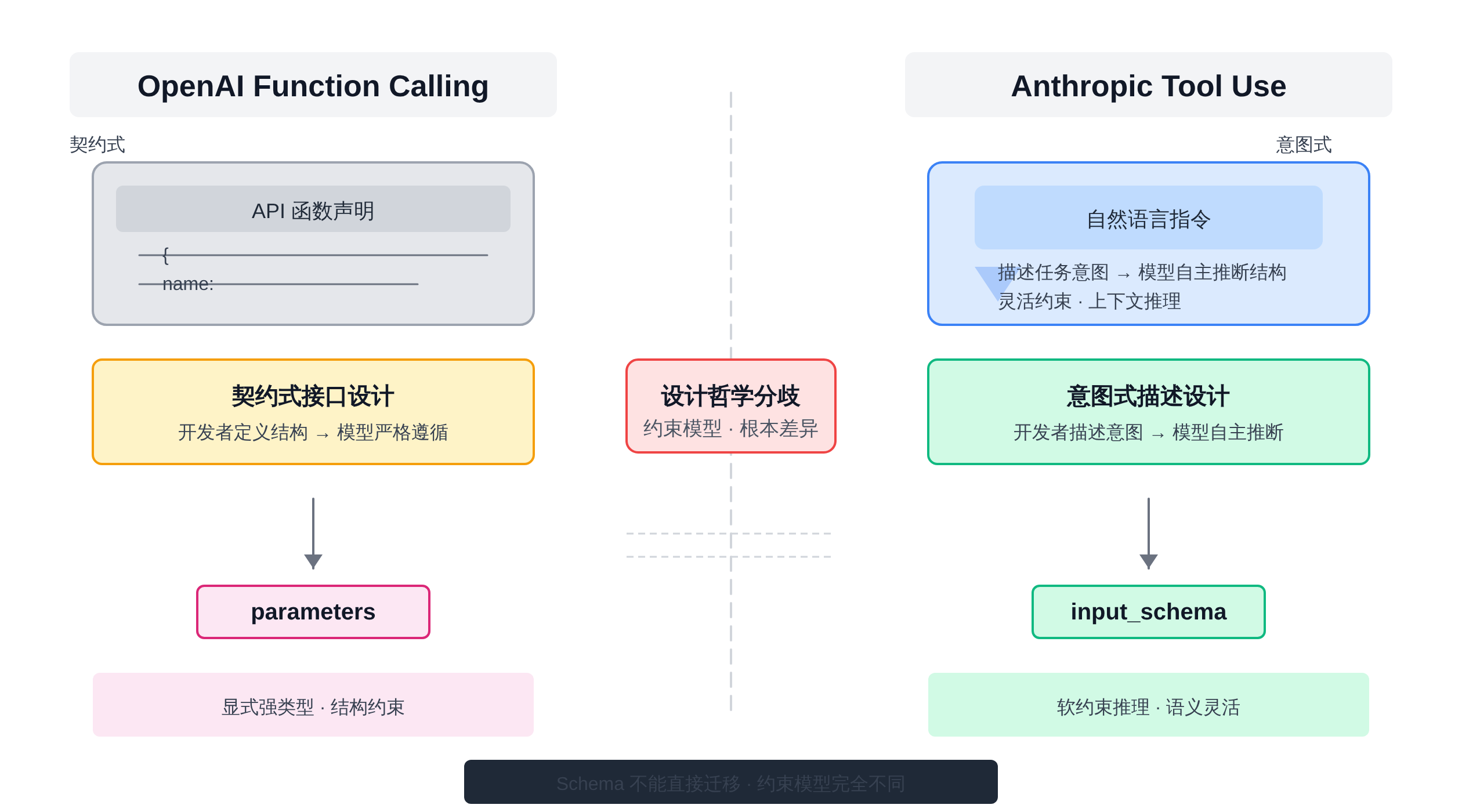
把 OpenAI Function Calling 和 Anthropic Tool Use 的 Schema 规范放在一起对比,最先感受到的不是技术细节,而是设计哲学的根本分歧。
这个分歧是理解后面所有结构差异的根因,也是面试里「为什么 Schema 不能直接跨平台迁移」这个追问的标准答案起点。
OpenAI 的 Function Calling 从一开始就走「开发者友好」路线:Schema 本质上是给 GPT 一个函数签名,让它理解「我应该调用哪个函数、传什么参数」。
因此 OpenAI 的规范天然更接近 OpenAPI 规范,字段命名、层级结构和 REST API 世界的主流约定保持一致。
Anthropic 的 Tool Use 是从「模型推理」角度出发的:Schema 是一段给 Claude 的指令描述,它不强制用标准 API 风格,而是允许用更接近自然语言的方式描述工具能力。
换句话说:OpenAI 的 Tool 是「API 函数声明」,Anthropic 的 Tool 是「工具能力描述」。
正文图解 1
parameters vs input_schema:顶层字段的本质分歧
最直接的差异在顶层字段名。OpenAI 用 parameters,Anthropic 用 input_schema:
# OpenAI Function Calling 结构
{
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
# Anthropic Tool Use 结构
{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"input_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
}
}
}
这不只是字段名不同——parameters 默认继承 JSON Schema 的全部约束,而 input_schema 是 Anthropic 自定义的 schema 容器,在某些边界行为上与标准 JSON Schema 并不完全一致 Anthropic Tool Use Documentation。
required 约束:硬校验与软约束的分水岭
OpenAI 的 required 字段是显式的、强制执行的——如果模型没有传必填参数,API 会返回参数校验错误。
Anthropic 在 input_schema 层面没有一个统一的 required 字段声明机制,官方推荐的方式是把「必填」信息写在 description 里,让 Claude 自己判断是否需要这个字段。
这意味着两种截然不同的约束模型:OpenAI 的必填约束是「硬约束」,由 API 层面校验兜底;Anthropic 的必填约束是「软约束」,由模型的推理能力兜底。
生产环境里这个差异会导致:当 Claude 选择不传某个字段时,你不会收到 400 错误,但你的工具会因为缺少关键参数在执行层失败——这个失败是在工具执行层发生的,不是在 Schema 校验层发生的。
这正是开头那个「线上 Agent 集体哑火」故事的根因。
enum 校验行为:类型边界还是参考建议
这是最容易踩坑的一处。
在 OpenAI 的 Function Calling 里,enum 字段的行为和 JSON Schema 一致:模型生成的参数值如果在 enum 列表之外,API 会返回校验错误。
在 Anthropic 的 Tool Use 里,enum 的约束力更弱。
Claude 有可能因为 description 里的上下文信息,生成一个不在 enum 列表中但语义相近的值。
这背后的逻辑是:OpenAI 把 enum 当「类型边界」,Anthropic 把 enum 当「参考建议」。
如果你在生产系统里写了严格的 enum 校验逻辑,然后迁移到 Anthropic 的 Tool 调用路径上,你加的那些校验条件会突然变得多余——因为 Claude 在更早的推理层就已经「替你处理」了 enum 约束。
更麻烦的是,这种处理不是每次都发生,取决于 description 的措辞和输入上下文,结果是不可预测的。
enum 在 A 家是约束,在 B 家是参考建议,这差异能让人 debug 到怀疑人生
additionalProperties:嵌套对象字段的静默丢弃陷阱
OpenAI 的 parameters 继承完整的 JSON Schema 语义,可以用 additionalProperties: false 明确禁止未定义字段。
Anthropic 的 input_schema 对 additionalProperties 的支持有限。
在实际测试中,当嵌套对象包含 additionalProperties: false 时,Anthropic 有时会静默丢弃那些「未在 schema 中声明但确实传进来了」的字段,而不是像 OpenAI 那样抛出校验错误。
这个差异在复杂嵌套对象的应用里会变成隐性 bug:前端表单收集了完整数据,传给 Agent,Agent 转发给工具,工具执行后发现某些字段神秘失踪——因为中间的 Schema 层静默丢弃了它们。
这类 bug 的可怕之处在于「静默成功」:请求执行完了,但数据不完整,而且没有任何报错日志。
description 权重:Anthropic 的一等公民如何影响工具选择
在 OpenAI 的规范里,description 是「元信息」,作用是帮助模型理解工具用途,但不影响参数校验。
在 Anthropic 的规范里,description 是 Schema 的「一等公民」。
官方文档明确指出,Claude 对工具的选择和参数的理解高度依赖 description 的措辞 Anthropic Tool Use Documentation。
description 会直接影响:模型是否选择调用这个工具;模型如何填充嵌套参数的默认值;模型在 enum 冲突时选择哪个值。
一个实操经验:如果你的工具在 Anthropic 侧经常出现「选错工具」或「参数填错」的情况,与其加更多的类型约束,不如先检查 description 写得够不够精确、够不够具体。
最佳实践是:不是「这个工具是干什么的」,而是「在什么场景下应该选这个工具而不是另一个」。
比如你有两个工具 cancel_order 和 query_order_status,如果 description 都写了「处理订单相关操作」,Claude 在面对「帮我看看这个订单」这样的用户输入时,很可能会选 cancel_order 而不是 query_order_status。
流式响应:Schema 传递格式的不可共用性
在流式响应中,OpenAI 在 stream 模式下会分块返回 function_call 的片段(chunk),最终由调用方拼接成完整的 call 对象;
Anthropic 的 Tool 调用返回格式是 content_block 类型的 tool_use,结构与 OpenAI 的 function_call 流式格式完全不同 Anthropic Tool Use Documentation。
如果你在写一个同时支持流式和非流式调用的 Agent 框架,这个差异意味着两者的 Schema 解析路径必须独立维护,不能简单复用非流式响应的解析逻辑。
这也是为什么 Skill SDK 通常会提供双格式兼容机制——比如 LangChain 的 StructuredTool 允许你在同一个 Tool 对象里同时声明 OpenAI Schema 和 Anthropic Schema,runtime 根据模型类型自动编译成对应格式 LangChain StructuredTool。

流式响应的 Schema 解析不能共用,这坑踩过的都知道疼
permissions 声明分级:network / filesystem / database / external_api
权限分级的工程意义
如果说 manifest 是 Skill 的「身份证」,那么 permissions 就是 Skill 的「护照签证页」——它决定了当前这个 Skill 在运行时能碰到什么、不能碰什么。
在 AI Agent 系统里,权限控制不是可选项,而是架构级安全边界。
当一个 Skill 被加载进 Agent 实例时,它的 permissions 声明决定了该 Skill 是否可以访问网络请求、读写本地文件系统、连接数据库或调用外部第三方 API。
这个设计背后的工程逻辑很清楚:Agent 系统本质上是一个「由 LLM 驱动的命令执行引擎」,LLM 生成调用指令,但实际执行发生在特权环境里。
如果 Skill 的权限没有边界限制,一个描述模糊的 prompt 或者一个被恶意构造的工具选择,就可能让 Agent 在你的服务器上执行意外的操作。
permissions 分级体系通常分为四层 AI Engineering Field Guide:
network 权限 控制 Skill 是否可以发起 HTTP 请求。
具备 network 权限的 Skill 可以访问内部服务 API、调用外部工具接口,或者向消息队列推送数据。
没有 network 权限的 Skill 只能做纯内存计算或操作已经加载到沙箱内的数据。
filesystem 权限 控制 Skill 是否可以读写宿主机文件系统。这个权限在 Skill 需要读取配置文件、写日志、或生成产物文件时是必需的。
但 filesystem 权限也是最容易被滥用的——一个权限过宽的 Skill 理论上可以覆盖系统关键文件,或者在容器逃逸场景下修改宿主机文件。
database 权限 控制 Skill 是否可以连接数据库实例并执行查询。
这个权限在企业级 AI 应用里很常见,比如客服工单 Skill 需要查用户表,工单路由 Skill 需要读部门配置表。
database 权限通常还会进一步细分为 read-only 和 read-write 两档。
external_api 权限 控制 Skill 是否可以调用第三方商业 API,比如调用 OpenAI 的 ChatGPT 接口、Stripe 的支付 API、或者公司内部自建的微服务。
这个权限有时候会单独拎出来管理,因为它涉及成本结算和密钥安全——一个 Skill 如果拿到了 external_api 权限,却没有配额限制,理论上可以无上限消耗公司的 API 预算。

权限全开跑通再说——这是所有灾难的第一步
主流沙箱提供方的权限模型对照
权限声明的具体实现方式取决于你使用的沙箱提供方。不同的执行环境对权限粒度和默认值有不同的处理逻辑。
以 OpenAI Agents SDK 的沙箱模型为例,它通过 Manifest 来定义 Skill 可见的文件、目录与输出 OpenAI Agents SDK with Modal Sandboxes。
Manifest 里的 entries 字段定义了沙箱内文件系统的初始状态,Skill 的 filesystem 权限边界由这个 Manifest 决定——Skill 只能看到 Manifest 里声明的文件,超出这个范围的读写操作会被沙箱拦截。
# manifest.yaml 中的 permissions 声明示例
name: ticket-triage-skill
version: 1.2.0
description: >-
在用户提交客服工单、需要按紧急程度分流到
support-ops 或 customer-care 团队时调用。
permissions:
network: false # 不允许发起 HTTP 请求
filesystem:
read:
- /workspace/project-a/config/*.yaml
- /workspace/project-a/README.md
write:
- /workspace/project-a/output/
database:
mode: read-only
hosts:
- internal-db.company.internal:5432
external_api: false
entry: src/triage.py
相比之下,Modal 的 sandbox 环境在启动时会接收一个 app_name 和 workspace_persistence 参数,这些参数决定了沙箱的资源配额和工作区持久化方式。
Sandbox 的网络隔离默认是开启的,如果需要让 Skill 访问内网服务,需要显式配置 VNet 或私有网络规则 Modal Sandbox Documentation。
E2B、Cloudflare Workers 等其他沙箱提供方的权限模型也大同小异:核心逻辑都是「显式声明 + 运行时校验 + 最小权限原则」,但声明语法和校验粒度各有差异。
如果你在项目里使用了多沙箱提供方切换(比如开发环境用 E2B,生产环境用 Modal),权限声明的兼容层设计就成了必须考虑的工程问题。
一个实际经验:在脚手架初始化阶段,skill create 命令生成的标准 manifest 文件里通常会默认把所有 permissions 设为 false 或 none。
这个默认配置是安全优先的,但也是最容易让新手卡住的地方——Skill 写好了,跑不通,报错说「network request blocked」,然后发现 permissions 没配。
skill link <user/system>:用户空间与系统空间的隔离设计
权限分级的另一个维度是空间隔离。Skill 加载到哪个「空间」,决定了它能被谁调用、对谁可见。
s kill link 命令通常支持两个挂载目标:user 和 system。
user 空间 的 Skill 只能被当前用户创建的 Agent 实例加载,其他用户的 Agent 看不到也调用不了。
这类 Skill 通常存放个人工具、自定义工作流或者正在开发中的实验性模块。
system 空间 的 Skill 是全局共享的,任何 Agent 实例都可以加载它们,通常由平台管理员或核心开发团队维护。
企业级 AI 应用里,系统空间存放的是经过安全审计的、生产级别的 Skill,比如统一日志查询 Skill、标准工单创建 Skill、内部知识库检索 Skill。
这个设计解决了一个很现实的问题:团队里不是所有人都应该有能力给生产 Agent 添加工具。
如果任何用户都可以往系统空间挂 Skill,那权限声明体系就形同虚设——一个权限配置过宽的 Skill 被某个不了解安全边界的同事挂上去,整条 Agent 链路都会面临风险。
s kill link system 的执行通常需要管理员权限,CI 流水线在发布阶段调用这个命令时,需要持有对应的 service account 凭证。
设计这个机制的人显然是踩过「同事随手 link 导致生产事故」的坑。

不是我 link 的,是 pipeline 自动化的
脚手架与本地开发:skill create、skill validate、skill test
skill create :模板生成的四个标准文件
skill create 是 Skill 开发的起点,它不是简单地在目录下创建一个文件夹,而是生成一套完整的脚手架。
一个标准的 skill create ticket-triage 命令会生成四个标准文件:
第一个是 manifest.yaml,即 Skill 的身份证。
这是最核心的文件,包含了 name、version、description、tools、permissions 和 entry 六大字段的骨架。
脚手架生成的 manifest 里,description 默认是一段 TODO 注释,提示开发者填写具体的调用时机描述——这个设计本身就在告诉你「description 不能留空」。
第二个是 src/index.py(或 src/index.ts),即 Skill 的入口文件。
这个文件导出一个标准化的 handler 函数,接收 LLM 生成的参数字典,返回结构化的执行结果。
脚手架生成的 index.py 里通常会包含一个带类型注解的 stub handler,开发者只需要在函数体内填入实际逻辑。
第三个是 tests/test_skill.py,即 Skill 的测试文件。
脚手架生成的测试文件会提供几个 mock 测试用例模板,包括正常调用路径、超参数场景和错误参数场景的基本覆盖。
测试文件的作用不仅是质量保障,也是 CI 流水线的入口——没有通过测试的 Skill 不允许进入发布流程。
第四个是 README.md,即 Skill 的使用文档。脚手架生成的 README 包含一段标准模板,提示开发者填写 Skill 的用途说明、参数描述、返回格式和典型使用场景。
这个 README 非常重要:它不只是给人看的文档,也是 AI Agent 在没有足够上下文时推断 Skill 用途的重要依据。
这四个文件的组合,构成了一个 Skill 最基本的可独立交付单元。
脚手架的标准化价值就在这里——所有 Skill 都遵循同一套结构,审核者只需要知道 manifest 在哪、入口在哪、测试在哪,不需要在每个 Skill 里重新理解一套自定义目录。
skill validate:双层校验拦截(Schema + 业务规则)
skill validate 是 Skill 上线前的第一道安检门。
它执行双层校验:第一层是格式校验,检查 manifest.yaml 的字段是否完整、Schema 是否符合 JSON Schema 规范;
第二层是业务规则校验,检查 permissions 声明是否合理、entry 指向的文件是否存在、依赖声明是否可解析。
格式校验层通常使用 jsonschema 或 pydantic 这类库来验证 manifest 结构。
如果 name 字段包含空格或非 ASCII 字符,如果 version 不符合 SemVer 格式,如果 input_schema 里有语法错误——格式校验层会在这里拦截,并给出具体的错误位置和原因描述。
# skill validate 格式校验层伪代码示例
import yaml
from jsonschema import validate, ValidationError
def validate_manifest_format(manifest_path: str) -> list[str]:
errors = []
with open(manifest_path) as f:
manifest = yaml.safe_load(f)
# 校验 name 字段
if not re.match(r'^[a-z0-9-]+$', manifest.get('name', '')):
errors.append(
f"name '{manifest['name']}' must match ^[a-z0-9-]+$"
)
# 校验 version 符合 SemVer
if not re.match(r'^\d+\.\d+\.\d+(-[a-zA-Z0-9]+)?$',
manifest.get('version', '')):
errors.append(
f"version '{manifest['version']}' must follow SemVer"
)
# 校验 tool schema
try:
validate(
instance=manifest.get('tools', [{}]).get('input_schema', {}),
schema=JSON_SCHEMA_DRAFT_2020_12
)
except ValidationError as e:
errors.append(f"tool schema validation failed: {e.message}")
return errors
业务规则校验层是格式校验的补充。
它检查那些「格式正确但语义错误」的情况——比如 permissions 里声明了 database 访问权限但没有指定具体的 hosts,或者 entry 指向的 src/triage.py 文件实际上不存在。
业务规则校验的策略因团队而异。有些团队会在这个层面加入命名规范检查(比如 description 长度不能少于 30 个字符,确保开发者真的写了具体描述而不是留空);
有些团队会校验 permissions 里声明的权限是否与 Skill 的实际行为一致(比如声明了 network 权限,但 Skill 代码里没有任何 HTTP 请求调用)。
两层校验都通过后,skill validate 才会返回 exit code 0,CI 流水线才允许继续走到下一步。
如果校验失败,错误信息会直接输出到终端,开发者不需要去看日志文件就能知道哪里出了问题。
validate 过了,CI 红了——这种 bug 的讽刺程度堪比代码写对但逻辑全错
skill test:本地模拟调用与配额隔离
skill test 是开发阶段的第二道关卡,但它和 skill validate 解决的问题完全不同。
skill validate 解决的是「Skill 格式对不对」的问题,skill test 解决的是「Skill 逻辑对不对」的问题。
本地测试框架通常会模拟一个 Agent 调用上下文,把一组预定义的输入参数直接传给 Skill 的 handler 函数,然后断言返回结果是否符合预期。
这个过程不发起真实的 API 请求,不会消耗 LLM 的 token 配额,也不会触碰任何外部服务。
为什么强调「不消耗真实 API 配额」?因为 Skill 开发阶段需要大量调试,如果每次改一行代码都要走完整的 Agent 推理链路,token 消耗会非常可观。
本地模拟调用把 Skill 的逻辑验证和 Agent 的推理过程解耦,开发者可以在 Skill 层面快速迭代,不需要每次都等完整的 Agent 执行结果。
# tests/test_skill.py 典型测试用例结构
import pytest
from src.triage import handler
def test_high_urgency_enterprise_user():
"""企业用户 + outage 关键词 → high priority"""
params = {
"subject": "Production outage affecting checkout",
"customer_tier": "enterprise"
}
result = handler(params)
assert result["priority"] == "high"
assert result["team"] == "support-ops"
def test_normal_priority_regular_user():
"""普通用户 + 常规描述 → normal priority"""
params = {
"subject": "Question about invoice format",
"customer_tier": "standard"
}
result = handler(params)
assert result["priority"] == "normal"
assert result["team"] == "customer-care"
def test_missing_required_field():
"""缺少必填字段 → 应抛出 TypeError 或返回错误结构"""
params = {"subject": "Test ticket"} # 缺少 customer_tier
with pytest.raises((TypeError, KeyError)):
handler(params)
本地测试的另一个价值是回归保护。当一个 Skill 经过多次迭代后添加了新功能,本地测试套件可以在几分钟内告诉你「原有的功能有没有被改坏」。
这对维护生产级 Skill 非常重要——一个工单路由 Skill 如果因为某次修改导致 enterprise 用户的优先级判断出错,线上所有企业客户的工单都会被错误分配。
脚手架版本与 Skill SDK 版本的兼容矩阵管理
skill create 生成的文件里,通常会嵌入一个 skill_sdk_version 字段,记录当前脚手架对应的 SDK 版本号。这个字段不是装饰品,它是兼容矩阵管理的关键锚点。
Skill SDK 作为框架工具,会随着时间演进增加新字段、废弃旧字段或调整校验规则。
如果你的团队同时维护多个 Skill,这些 Skill 可能是在不同时间点、用不同版本的脚手架生成的。当 SDK 升级时,你需要知道哪些 Skill 需要迁移。
兼容矩阵通常是一张二维表,横轴是 SDK 版本,纵轴是脚手架生成日期。矩阵里的每个格子标注「兼容 / 需要升级 / 不兼容」。
这个矩阵在大型团队里尤为重要。
当平台团队决定升级 Skill SDK 到某个新 major 版本时,使用新版本脚手架生成的 Skill 会自动支持新特性,但老 Skill 仍然跑在旧版本的 manifest 规范上。
CI 流水线需要能识别这种差异,并在必要时触发 Skill 的强制升级提示。
一个实际建议:如果你的团队负责维护一个 Skill 市场或 Skill 平台,建议在发布页面显式标注「此 Skill 基于 Skill SDK v1.x 生成,建议在 v1.x 以上环境使用」。
这样使用者可以在部署前判断兼容性,而不是跑到线上才发现不对。
热重载:Skill 修改后自动重新注册的工程实现
文件系统事件监听与自动重新注册机制
热重载是 Skill 本地开发体验的核心。
当你在本地修改了 src/triage.py 或更新了 manifest.yaml,重新注册 Skill 不需要重启整个 Agent 实例——文件系统的变化被监听器捕获后,会触发 Skill 的自动重新注册流程。
这个机制的实现通常依赖 watchdog 或 inotify 这类文件系统事件监听库:
# 热重载监听器典型实现
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class SkillHotReloadHandler(FileSystemEventHandler):
def __init__(self, skill_name: str, agent_instance):
self.skill_name = skill_name
self.agent = agent_instance
self.debounce_seconds = 1.0
self.last_reload_time = 0
def on_modified(self, event):
if not event.is_directory and event.src_path.endswith(
('.py', '.yaml', '.json')
):
self._schedule_reload()
def _schedule_reload(self):
"""防抖:避免短时间内多次事件触发重复注册"""
now = time.time()
if now - self.last_reload_time < self.debounce_seconds:
return
self.last_reload_time = now
self._reload_skill()
def _reload_skill(self):
print(f"Detected change in {self.skill_name}, reloading...")
# 1. 重新加载 manifest
manifest = load_manifest(self.skill_name)
# 2. 验证格式合法性
errors = validate_manifest_format(manifest)
if errors:
print(f"Validation failed, skipping reload: {errors}")
return
# 3. 注销旧版本 Skill
self.agent.unregister_skill(self.skill_name)
# 4. 注册新版本 Skill
self.agent.register_skill(self.skill_name, manifest)
print(f"Skill '{self.skill_name}' hot-reloaded successfully")
# 启动监听
observer = Observer()
handler = SkillHotReloadHandler("ticket-triage", agent_instance)
observer.schedule(handler, path="./skills/ticket-triage", recursive=True)
observer.start()
这个实现里有几个值得注意的工程细节。
第一个是防抖(debounce)机制。
编辑器保存文件时,操作系统可能会在短时间内触发多次 on_modified 事件——比如某些编辑器会先写入临时文件再 rename,导致两次 modify 事件。
如果没有防抖,Skill 会在几毫秒内被注销再注册好几次,既浪费资源,也可能在两次注册之间产生竞态条件。
第二个是验证先于注册。热重载不等于「盲目相信新文件」。
在重新注册之前,_reload_skill 会先跑一次 validate_manifest_format,只有格式合法的 Skill 才会被重新挂载。
如果一个开发者刚把 manifest 改出了语法错误就保存,热重载不会把这个错误版本注册上去——它会打印错误信息并保持上一个正常版本继续运行。
第三个是递归监听。整个 Skill 目录被监听,而不是只监听 manifest.yaml 一个文件——这样当 src/ 子目录下的代码文件发生变化时,Skill 同样会被重新加载。

热重载听着很美好,直到你发现编辑器保存一次触发了三次事件,Agent 给你重启了三次
热重载的边界条件:超时调参与步骤日志
热重载不是万能的,它有自己的边界条件。
最常见的边界是 Skill 内部有长耗时操作时的重载冲突。
如果一个 Skill 正在执行一个耗时 5 分钟的数据导出任务,开发者在第 3 分钟修改了代码并保存——此时热重载会触发,但 Skill 的 handler 还没有执行完。
多数实现会在这种情况下拒绝重载,等待当前任务完成后再加载新版本。
这个行为本身是对的,但需要有明确的日志输出,让开发者知道「Skill 没有热重载是因为有任务正在运行」,而不是制造「保存了怎么还没生效」的困惑。
第二个边界是并发注册。在多沙箱或多实例部署场景下,同一个 Skill 可能同时被加载到多个 Agent 实例里。
热重载需要处理「部分实例注册成功、部分实例注册失败」的分布式一致性场景。常见的处理方式是:热重载在主实例触发,然后通过消息队列广播到其他实例,所有实例在下一个心跳周期内完成同步。
第三个边界是超参数调优场景。
如果 Skill 在 manifest 里声明了一些运行时可配置的参数(比如 timeout、retry_count、batch_size),热重载对这些参数的变更需要特殊处理——有些团队选择「立即生效」,有些团队选择「等当前任务结束再生效」。
哪种策略更合理,取决于 Skill 的业务特性。

线上 Skill 正在跑,CI 在热重载,这场面懂的都懂
skill publish 与 SemVer:把 Skill 送进生产流水线的完整链路
skill publish:打包 + 推送 + Tag 触发三段式
一个 Skill 在本地通过热重载反复调试,终于在本地测试套件里跑过了全部用例。接下来要把这个 Skill 送进生产环境。
skill publish 不是一条孤立的命令,它是一条三段式流水线:打包 → 推送 → Tag 触发发布。
打包阶段把 Skill 目录下的所有文件(manifest.yaml、入口脚本、测试文件、README 等)压缩成一个可分发包。
这个包通常包含:manifest 的解析结果(工具列表、权限声明、版本号)、入口脚本的编译或解释形态、以及依赖清单。```
为什么用 Git Tag 作为触发源?
因为 Tag 对应的是版本快照,每一次 skill publish 都会在 Git 历史里留下精确的版本标签——当某个生产问题需要回滚时,你有一个精确的版本锚点可以切回去AI 工程师 Field Guide:Home assignments(面试准备) - take-home assignments and paid work trials...。
这个设计在工程上借鉴了语义化版本的约定:Tag 里的版本号不只是标记,它是元数据的一部分,会被 registry 解析并用于版本兼容性校验。
Semantic Versioning:Breaking Change 必须升 Major 的强制约定
Skill SDK 采用 Semantic Versioning(SemVer)作为版本管理规范,这套规范在 package ecosystem 里用了很多年,但 Skill 场景有其特殊性AI 工程师 Field Guide:Interview questions(面试准备) - consolidated from 100+ sources。
SemVer 的基本逻辑:主版本号.次版本号.补丁版本号(MAJOR.MINOR.PATCH)。
-
补丁号(PATCH)递增:向后兼容的 bug 修复,比如修复了某个参数校验的边界 case。
-
次版本号(MINOR)递增:新增功能,向后兼容——现有 Skill 不受新功能影响。
-
主版本号(MAJOR)递增: Breaking Change,向后不兼容——旧 Skill 需要修改 manifest 才能在新 SDK 环境运行。
Breaking Change 的强制约定是 SemVer 的核心:当你的改动破坏了对旧版本的兼容性,必须升主版本号。这是硬性约定,不是建议。
Breaking Change 在 Skill 场景里通常包括:manifest 字段被删除或重命名、Tool 的 inputSchema 结构发生变化(移除了 required 字段、修改了 enum 值列表)、权限模型做了结构性调整。
举个例子。
如果 Skill SDK 在 v2.0.0 决定把 manifest 的 permissions 字段从顶层拆到 tools[].permissions,那么所有基于 v1.x manifest 编写的 Skill 在 v2.x 环境里都会报「权限声明格式不兼容」——这属于 Breaking Change,必须升 major。
生产团队在升级 SDK 时,通常会维护一个「版本迁移指南」,说明从 v1.x 到 v2.x 需要手动修改哪些字段。这个指南会随 SDK 一起发布,而不是让开发者自己猜。
CI 流水线在发布阶段会做一次额外检查:如果检测到当前 Tag 的版本号相比上一个 Tag 是降级的,或者 patch/minor 变化但包含 Breaking Change(这说明违反了 SemVer 约定),pipeline 会拒绝发布并返回明确错误。
manifest 格式校验工具链在 CI 中的角色
skill validate 不只是本地开发工具,它在 CI 流水线里扮演两道门卫的角色。
第一道门:格式合法性校验(Schema 层)。
CI 在构建阶段跑 skill validate,检查 manifest.yaml 是否符合 Skill SDK 的 Schema 定义——字段是否存在、类型是否正确、必填字段是否缺失。
这道门的作用和 ESLint 对 TypeScript 代码的作用一样:在问题进入 registry 之前拦截掉格式错误。
第二道门:业务规则校验(规则层)。
在格式校验通过后,CI 会运行一套业务规则检查:工具名称是否与平台已有工具重名、permissions 声明的资源范围是否超出平台允许的最大范围(某些平台不允许 Skill 声明 database: write 权限)、版本号是否符合 SemVer 格式。
两道门都通过后,CI 才会执行打包和推送。
如果第一道门失败,构建直接失败,错误信息会告诉你是「manifest.yaml 第 12 行字段名不存在」还是「version 字段格式不符合 SemVer」。
如果第二道门失败,CI 会报告具体的业务规则冲突——比如你声明了平台不允许的 external_api 权限,或者 Tool 的名称和已有 Skill 冲突。
这个双层校验设计的目标是:让格式问题在本地就被发现(不需要等待 CI 反馈),同时让业务层问题在 CI 阶段被系统化拦截(不需要人工 review)。
DX 设计原则:如何降低非技术人员参与 Skill 开发的门槛
human-readable manifest 与错误信息本地化
Skill 的目标用户不只有后端工程师。
在一个成熟的 Skill 生态里,产品经理、领域专家甚至客户自己,都可能需要创建或修改 Skill——他们不一定能读懂 YAML 的结构约束,但他们能读懂「这个 Skill 用来做什么」和「它需要哪些权限」。
这要求 manifest 的设计在技术表达和业务表达之间找到平衡。
一个典型做法是把 manifest 分层:机器可读的字段保持 YAML 原生格式,同时提供一个 description 字段用自然语言描述 Skill 的用途和边界——这个字段对模型有用,对人类也有用。
# 人类可读 + 机器可解析的双层 manifest 设计
name: ticket-triage
version: 1.2.0
description: |
工单优先级分流 Skill。根据用户等级(enterprise/standard)和
工单主题关键词(outage/downtime/bug)判断优先级,并将工单分配
给 support-ops(高优先级)或 customer-care(普通)。
此 Skill 不访问数据库,不发起外部 API 调用。
tools:
- name: route_ticket
description: |
将工单按优先级和部门分组。必填参数:subject(工单主题)、
customer_tier(用户等级)。可选参数:custom_category(自定义分类)。
input_schema:
type: object
properties:
subject:
type: string
description: 工单主题文本
customer_tier:
type: string
enum: ["enterprise", "standard"]
description: 用户等级
permissions:
filesystem: none
network: none
database: none
external_api: none
这个 manifest 的 description 字段用自然语言说清楚了 Skill 的输入、输出和权限边界。
产品经理读完这段话,大概能判断「这个 Skill 能处理什么场景、不能处理什么场景」,而不需要去研究 YAML 的结构细节。
错误信息的本地化是另一个 DX 维度。当 skill validate 报错时,错误信息应该用「这个字段不应该出现」还是「你的 Tool 缺少必填参数 input_schema」?
前者是技术语言,后者是操作指引。
好的 DX 设计会把错误信息翻译成「发生了什么 + 为什么重要 + 怎么修复」,而不是只给一个技术术语让非技术人员去猜。
自动化程度与灵活性的取舍哲学
DX 设计里有一个核心张力:自动化程度越高,开发门槛越低,但灵活性也越受限制。
skill create 命令把模板生成自动化了——一个命令生成四个文件,新手不需要知道文件结构和字段规范。这是高自动化。
但如果一个团队需要自定义模板(比如在 manifest 里预置企业内部的权限检查逻辑),这个自动化模板就成了限制。这类团队需要的是「模板可扩展」的设计,而不是「所有团队用同一套模板」的方案。
主流的取舍策略是分层:一层是「Opinionated Scaffold」,默认生成最常用的结构,适合新手和快速原型;
另一层是「Unopinionated Foundation」,只提供文件骨架和 Schema 校验,不预设任何业务逻辑,适合需要深度定制的团队。
Skill SDK 通常提供两种命令:skill create 生成 Opinionated 模板,skill init --bare 生成 Unopinionated 骨架。
这不是两个工具,而是同一个工具的两套模式——降低选择成本,同时保留扩展空间。
另一个取舍维度是「显式优于隐式」。在 manifest 里声明 permissions: network: none,比「默认允许网络访问但需要时再声明限制」要安全得多。
非技术人员在修改 Skill 时,如果架构允许他们「声明式地描述权限」而不是「理解权限模型的默认行为」,犯错的空间会大幅缩小。
声明式的意思是:你告诉系统「我需要什么」,而不是「我不需要什么」——前者更难漏掉关键点。
面试标准回答与项目落地说法
秒开口模板
当面试官问「你用过 Skill SDK 吗,讲讲 Skill 的生命周期」,最怕的不是答不全,而是答成清单背诵。推荐一个 30 秒开口版,先把核心链路串成一句话:
「Skill 的生命周期绕不开四个核心阶段:manifest 定义元数据和工具入口、Schema 校验确保工具调用参数合法、权限声明控制 Skill 能访问哪些资源、本地测试通过后走 publish 流水线进生产,热重载保证开发阶段修改能实时生效。
这套流程里最容易出问题的环节是 Schema 和 permissions——Schema 写错会导致 Agent 选错工具或参数校验失败,permissions 漏报或报错则会在运行时触发权限异常。」
这个版本踩中了三个关键点:链路完整性(四个阶段)、高风险环节识别(Schema + permissions)、生产影响判断(选错工具 vs 权限异常)。面试官接下来通常会追问其中一个环节深挖。
面试官已经开始在本子上画结构图了
追问 A:从 SDK 调用流程展开
如果面试官顺着「SDK 调用流程」追问,可以从执行路径展开:
「Skill SDK 在调用时走的路径是:Agent 接收用户意图 → 根据 manifest 里的 Tool 列表做工具选择 → 用对应 Tool 的 inputSchema 校验模型生成的参数 → 校验通过后交由 sandbox 执行 → 执行结果通过 outputSchema 格式返回给 Agent。
Schema 在这个链路里出现了两次:选择阶段靠 description 字段判断该选哪个 Tool,参数填充阶段靠 input_schema 做硬校验。
如果 input_schema 定义了 required: ["city"] 但模型漏传了这个参数,OpenAI 侧会直接返回 400 错误,Anthropic 侧则会由模型自己判断要不要补默认值——两种行为在生产环境里的调试路径完全不一样。」
这段展开的逻辑线是:调用路径 → Schema 出现两次 → 两次的不同行为 → 生产调试差异。
面试官可以沿着这条线继续问 Schema 校验、sandbox 执行或 outputSchema 处理。
追问 B:从 Schema 可维护性展开
如果面试官从「Schema 可维护性」角度追问,核心是讲清楚跨版本管理和多 Tool 共存问题:
「Schema 的可维护性在 Skill 场景里有三个典型挑战。
第一个是版本漂移:Skill SDK 升级后,旧 manifest 的字段结构可能和新版 Schema 不兼容,需要维护一份迁移指南。
第二个是 Tool 数量膨胀:一个 Agent 挂载了 20 个 Skill,每个 Skill 有 2 到 3 个 Tool,Schema 之间的 description 风格不统一会导致 Agent 在相似工具之间选错,这时候需要在 manifest 层做 description 标准化约束,而不是在各 Tool 内部修修补补。
第三个是多 runtime 兼容:同一个 Tool 可能同时服务 OpenAI 和 Anthropic 两条调用路径,两边的 Schema 约束强度不同(硬校验 vs 软约束),需要在 Schema 定义层做双向兼容性兜底。」
这段回答的核心是把「Schema 可维护性」拆成三个具体问题,每个问题都有工程场景和解决思路。面试官通常会挑其中一个追问细节。
项目里怎么说:LangGraph ToolRegistry + CI validator
如果面试官直接问「你们在项目里怎么管 Skill 的 Schema」,可以这样回答:
「我们用 LangGraph 的 StructuredTool 做双格式兼容——同一个 Tool 对象底下同时声明了 OpenAI 的 parameters 结构和 Anthropic 的 input_schema 结构,runtime 根据模型类型自动编译成对应格式,工具逻辑只有一份。
Schema 的一致性维护靠 CI validator 保证:所有 Skill 的 manifest 在 push 时会触发 validator,检查两边对 required 字段的描述是否对齐、enum 值列表是否完全一致。
如果 OpenAI 侧声明了 enum: ["A", "B"] 但 Anthropic 侧漏掉了 "B",CI 直接挂掉,不允许合并。」
这段说法的价值在于:既展示了 LangGraph 的工程落地能力,又展示了 CI 自动化的质量把控意识——两个维度同时命中 AI 工程师岗位的核心期待。
CI validator 挂了,reviewer 直接在群里 at 你,这场面懂的都懂
常见翻车场景与易错边界清单
manifest 编写类
翻车点 1:version 字段缺失或格式不符合 SemVer。
有些新手在本地快速起一个 Skill 时不填 version,默认变成 0.0.0,结果 CI 的第二道门检测到版本号不符合 SemVer 格式,直接拒绝发布。
更隐蔽的是:本地 skill validate 不会检查 version 格式(它只管字段存在性),但 CI 会——这个差异会导致本地跑通、CI 挂掉的困惑局面。
翻车点 2:name 字段使用了平台保留关键字。
如果你的 Skill 叫 system-info 或 admin,系统保留字段会直接拒绝注册,错误信息通常是「Skill name conflicts with reserved namespace」。
这类问题在 skill validate 的业务规则层会被拦截,但错误信息如果不是本地化的,非技术人员可能会卡在「这个名字多好,为什么不让用」这个问题上。
翻车点 3:description 写了功能描述但没写权限边界。
「这个 Skill 用来分流工单」是一个功能描述,但不是权限边界描述。
权限边界描述的意思是「此 Skill 不访问数据库、不发起外部 API 调用」——后者对安全审计人员和 Agent 的权限校验逻辑都有直接价值。
产品经理改了 description 功能描述但没改权限边界说明,这是最常见的权限说明和实际行为不一致的根因。
Schema 设计类
翻车点 4:OpenAI 和 Anthropic 的 Schema 不一致,Agent 在 Anthropic 路径上报错。
最典型的场景:OpenAI 侧定义了严格的 required 字段,Anthropic 侧漏掉了,Claude 推理时不传这个参数,工具执行层拿到空值然后崩掉。
这类问题的根因通常是「在 OpenAI 侧调通了,以为两边都通」。
翻车点 5:enum 值列表在升级时被悄悄修改,但没有升 major 版本。
Skill 从 v1.2.0 升级到 v1.3.0,把 customer_tier 的 enum 从 ["enterprise", "standard"] 改成了 ["enterprise", "standard", "trial"]。
这属于新增值,按 SemVer 应该升 minor,但如果你同时移除了某个旧 enum 值,那就是 Breaking Change,必须升 major。
下游 Agent 在不知道这个变化的情况下调用 Skill,旧数据里的 enum 值会被 Anthropic 侧静默丢弃(而不是报校验错误),调试难度极大Anthropic Tool Use Documentation。
翻车点 6:嵌套对象的 additionalProperties: false 在 Anthropic 侧静默失效。
在 OpenAI 侧,additionalProperties: false 会严格执行——不在 schema 里声明的字段会被 API 拒绝。
在 Anthropic 侧,这个约束有时会被静默放宽:字段没在 schema 里声明,但实际值传进来了,Claude 的执行层不会报校验错误,而是直接忽略这个字段。
前端表单收了完整数据,Agent 转发,工具执行,最后发现关键字段神秘失踪。这类「静默成功」比「显式失败」难定位一个数量级。

字段丢了但没报错,我该高兴还是该慌
权限声明类
翻车点 7:本地开发时用高权限沙箱,发布时没降级。
skill create 生成的模板默认 permissions 全部是 none。
但很多工程师在本地调试时,为了省事,直接把 permissions 改成 network: all 或 filesystem: write,调通之后再手动改回来——或者忘了改,就 publish 了。
线上 Skill 带着 network: all 权限运行,平台的安全审计会直接触发告警,严重时会导致 Skill 被平台下架。
翻车点 8:skill link 挂错了空间。
skill link user 和 skill link system 的区别直接影响 Skill 的可见范围:user 空间的 Skill 只有当前用户能看到,system 空间的 Skill 对所有用户可见。
如果你在内部平台上开发了一个通用 Skill,却用 skill link user 挂到了个人空间,团队其他成员加载这个 Skill 时会找不到——因为他们根本没有访问你个人空间的权限。
这类问题的调试成本很高:明明 manifest 写得没问题,但就是加载不上。
翻车点 9:permissions 声明了但 sandbox 执行层不支持该权限模型。
某些沙箱提供方不支持细粒度的 external_api 权限声明,只支持粗粒度的 network: allow/deny。
你在 manifest 里声明了 permissions: external_api: ["api.example.com"],但目标平台的 sandbox 根本不解析这个字段,运行时行为变成「完全允许」或「完全拒绝」,而不是你声明的精确范围。
本地测试类
翻车点 10:skill test 用的是模拟调用,换到生产 API 后行为不一致。
skill test 本地模拟调用不会消耗真实 API 配额,这是设计意图,但也是陷阱所在。模拟调用的响应是预设的 or 基于规则的,不反映真实模型在复杂输入下的行为。
如果你用 Anthropic 的 Tool Use,skill test 里 enum 校验是宽松的,但生产 API 在某些边界输入上可能触发 Claude 的推理修正——导致测试通过、上线挂掉。
这类问题的根因是对「模拟调用」和「真实调用」的行为差异没有建立预期管理。
翻车点 11:热重载触发后,超时参数没有同步。
本地修改了一个 Tool 的处理逻辑,增加了文件读写操作,但忘了把 sandbox 的超时参数从 300 秒调到 600 秒。
热重载重新注册了 Skill,新逻辑在第 320 秒时超时被强制终止——但这次超时发生在用户自己的代码里,不在 SDK 的日志里,错误信息通常只是一个 timeout,不告诉你是因为哪个操作卡住了。
发布流程类
翻车点 12:Tag 打错了导致版本号混乱。
skill publish 会从 manifest 的 version 字段读取版本号,生成对应的 Git Tag。
但如果你在发布前手动改了 version 字段(比如从 1.2.0 改到 1.3.0),但 git tag 已经打过了,CI 会报「Tag 冲突或版本号不匹配」错误。
如果用的是 force push 强行覆盖,Git 历史里的版本锚点就乱了——当你需要回滚时,根本不知道该切到哪个 Tag。
更严重的是:如果 force push 推到了 shared remote branch,团队其他人的本地分支直接废掉。
翻车点 13:Breaking Change 没升 major,线上 Skill 集体不兼容。
这是 SemVer 里最贵的错误。
Skill SDK 从 v1.x 升级到 v2.x,schema 结构做了不兼容调整,但你发布的 Skill manifest 仍然标注 version: 1.4.0(只升了 minor)。
CI 因为没有检测到 Breaking Change所以放行,但所有 v1.x 的 Skill 在 v2.x 环境下启动时,manifest 校验直接挂掉,Agent 找不到任何工具——「Agent 哑火」这个词就是这么来的。
修复成本是给所有 Skill 更新 manifest 并升 major 版本,这在内部分布式团队里往往需要协调多个团队同步修改。

Breaking Change 通知发出去之后,Slack 里安静了 10 分钟
参考文献与延伸阅读
参考文献
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

