前言
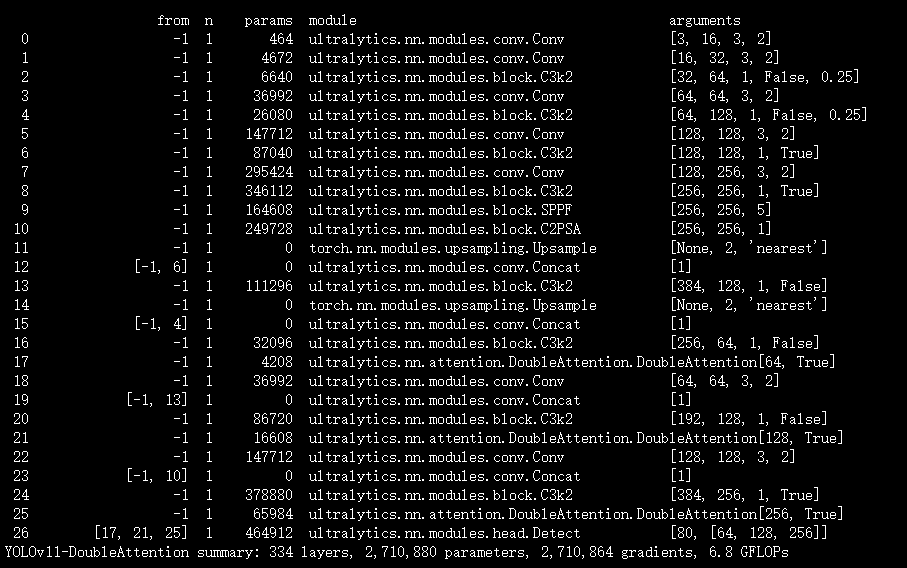
本文介绍了双重注意力机制(Double Attention)及其在YOLOv11中的结合应用。双重注意力机制由特征聚合和特征分配两个步骤组成,旨在有效捕获输入数据的全局特征,使后续卷积层能高效访问这些特征。该机制通过二阶注意力池化和注意力向量分配,让模型能更好地利用全局信息。其组件易于采用,可方便插入现有深度神经网络。我们将双重注意力块集成进YOLOv11。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
@[TOC]
介绍

摘要
捕获远程依赖关系是图像与视频识别任务的核心基础。现有卷积神经网络模型通常通过增加网络深度来建模此类关系,然而这种方法效率较低。本研究提出了一种创新的"双重注意力块"组件,该组件能够从输入图像或视频的完整时空空间中聚合并传播有价值的全局特征,使得后续卷积层能够高效地访问整个空间的特征信息。该组件采用两步式双重注意力机制设计:第一阶段通过二阶注意力池化操作将全局空间特征聚合为紧凑的特征集合,第二阶段利用另一注意力机制自适应地为每个空间位置选择并分配相应特征。所提出的双重注意力块具有良好的兼容性,可便捷地集成到现有深度神经网络架构中。我们开展了系统的消融实验与性能评估,验证了该方法在图像和视频识别任务中的有效性。在图像识别任务中,集成双重注意力块的ResNet-50模型在ImageNet-1k数据集上以超过40%的参数量减少和更低的计算复杂度(FLOPs),性能表现超越了规模更大的ResNet-152架构。在动作识别任务中,所提出模型在Kinetics和UCF-101数据集上均达到了当前最先进的性能水平,且计算效率显著优于近期相关研究工作。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
双重注意力机制(Double Attention)的详细介绍及其技术原理
技术原理
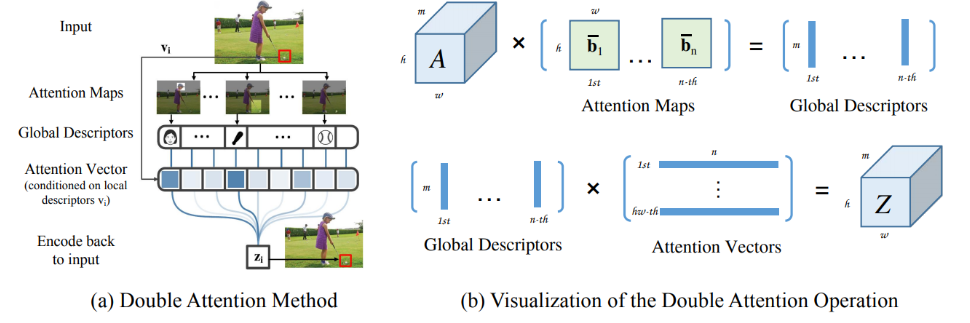
双重注意力机制(Double Attention Mechanism)由两个主要步骤组成:特征聚合(Feature Gathering)和特征分配(Feature Distribution)。这一机制旨在有效地捕获输入数据中全局特征,从而使后续的卷积层能够更高效地访问这些特征。
- 特征聚合(Feature Gathering):
- 输入张量:,其中 是通道数, 是时间维度, 和 是空间维度。
- 局部特征:每个位置 处的局部特征记为 。
- 聚合函数:
其中 $A$ 和 $B$ 是由不同卷积层生成的特征图,分别表示为 $A = \phi(X; W_\phi)$ 和 $B = \text{softmax}(\theta(X; W_\theta))$。
2. 特征分配(Feature Distribution): - 分配函数:
其中 $v_i$ 是位置 $i$ 的注意力向量,确保 $\sum_j v_{ij} = 1$。
3. 双重注意力块(Double Attention Block): - 组合操作:
这一步包括:
- **特征聚合**:使用二阶注意力池化。
- **特征分配**:通过注意力向量适应性地分配局部需要的特征。
- **计算图**:包括双线性池化和注意力机制(参见文档中的实现图)。
计算考虑
- 左结合:在实际实现中更优,因为内存和计算成本更低。
- 复杂度:矩阵乘法的计算复杂度为 。
- 内存:存储中间结果的效率较高。
实现步骤及公式
第一步注意力:特征聚合
- 输入张量:。
- 特征图: 和 。
- 二阶注意力池化公式:
第二步注意力:特征分配
- 特征分配公式:
- 分配过程:
其中 。
核心代码
class DoubleAttention(nn.Module):
def __init__(self, in_channels, c_m, c_n, reconstruct=True):
super().__init__()
self.in_channels = in_channels
self.reconstruct = reconstruct
self.c_m = c_m
self.c_n = c_n
# 定义三个1x1卷积层
self.convA = nn.Conv2d(in_channels, c_m, 1)
self.convB = nn.Conv2d(in_channels, c_n, 1)
self.convV = nn.Conv2d(in_channels, c_n, 1)
# 如果需要重构,定义一个重构卷积层
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)
def forward(self, x):
b, c, h, w = x.shape # 获取输入的维度
assert c == self.in_channels # 确认输入通道数正确
A = self.convA(x) # 通过 convA 卷积层,输出形状为 (b, c_m, h, w)
B = self.convB(x) # 通过 convB 卷积层,输出形状为 (b, c_n, h, w)
V = self.convV(x) # 通过 convV 卷积层,输出形状为 (b, c_n, h, w)
tmpA = A.view(b, self.c_m, -1) # 改变 A 的形状为 (b, c_m, h*w)
attention_maps = F.softmax(B.view(b, self.c_n, -1)) # 计算 B 的注意力图,形状为 (b, c_n, h*w)
attention_vectors = F.softmax(V.view(b, self.c_n, -1)) # 计算 V 的注意力向量,形状为 (b, c_n, h*w)
# 步骤1:特征门控
global_descriptors = torch.bmm(tmpA, attention_maps.permute(0, 2, 1)) # 计算全局描述符,形状为 (b, c_m, c_n)
# 步骤2:特征分配
tmpZ = global_descriptors.matmul(attention_vectors) # 分配特征,形状为 (b, c_m, h*w)
tmpZ = tmpZ.view(b, self.c_m, h, w) # 改变形状为 (b, c_m, h, w)
if self.reconstruct:
tmpZ = self.conv_reconstruct(tmpZ) # 如果需要重构,通过重构卷积层
return tmpZ # 返回输出
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-DoubleAttention.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='DoubleAttention',
)
结果