

SeaTunnel部署及其Demo
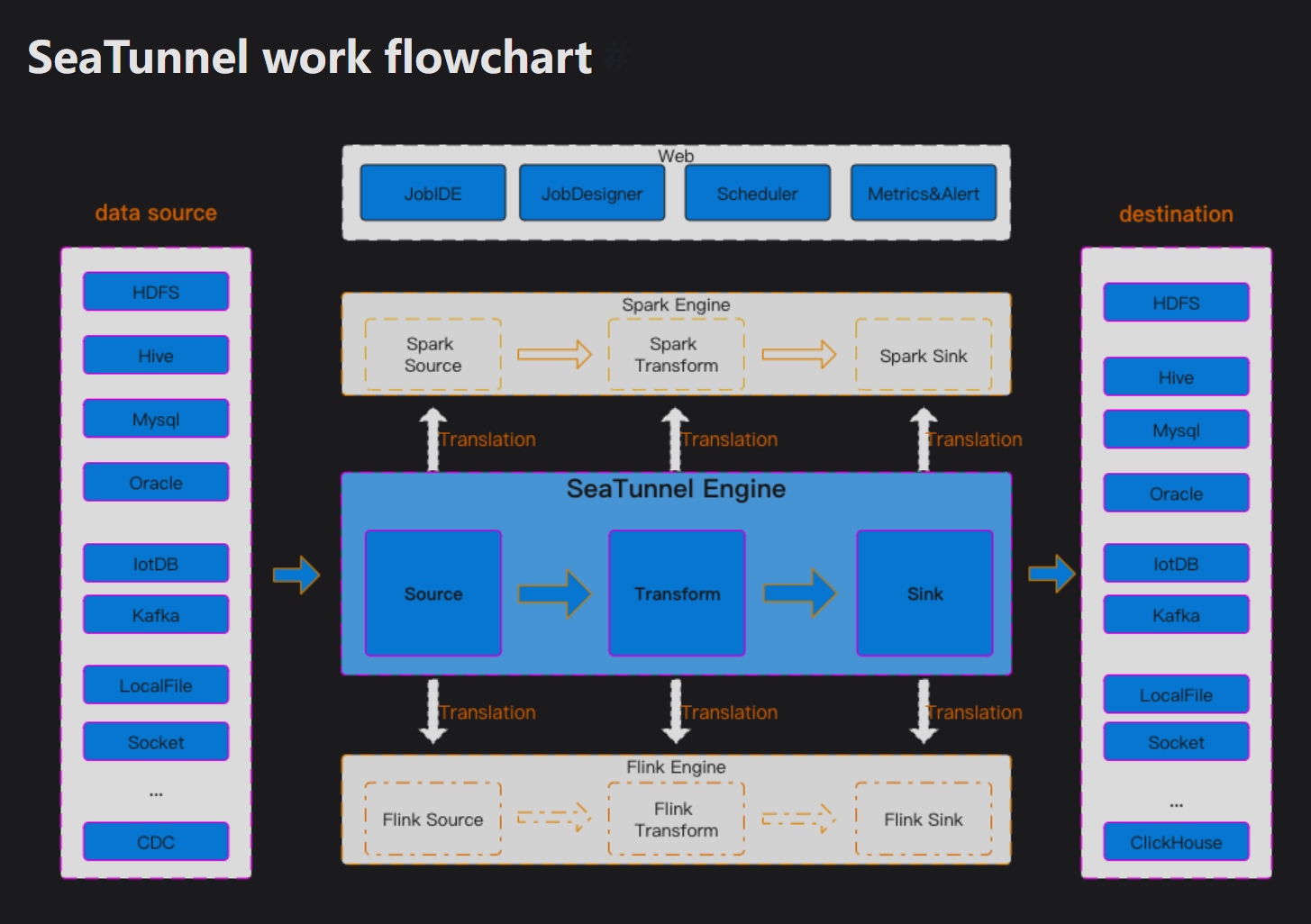
从上图可以看出seatunnel的conf(执行命令文件),主要是source、transform、sink组成
- 📥 Source(数据源):作用:从各种数据源读取数据
- 🔄 Transform(数据转换):作用:对数据进行清洗、转换、加工
- 📤 Sink(数据目标):作用:将处理后的数据写入目标系统
- jdbc的文档(官方):seatunnel.apache.org/docs/connec…
- mysql的source文档(官方):seatunnel.apache.org/docs/2.3.3/…
- mysql的sink文档(官方):seatunnel.apache.org/docs/2.3.3/…
1 环境、安装下载(国内镜像下载)
- 环境准备:确保你的系统已安装 Java 8 或 11,并正确设置了 JAVA_HOME 环境变量。
1.1 下载,解压
https://mirrors.tuna.tsinghua.edu.cn/apache/seatunnel/2.3.12/apache-seatunnel-2.3.12-bin.tar.gz
tar -zxvf apache-seatunnel-2.3.12-bin.tar.gz
1.2 下载插件(根据需要下载)
安装连接器插件:从2.2.0-beta版本开始,二进制包默认不包含连接器,需要手动安装。
进入解压后的SeaTunnel目录,执行安装脚本:
如果需要指定连接器版本(例如2.3.8),则执行 sh bin/install-plugin.sh 2.3.8。
你通常不需要全部连接器。可以编辑 config/plugin_config 文件,按格式(例如下方)指定所需插件。要让示例应用运行,通常需要 connector-fake 和 connector-console。
连接器插件的作用
连接器插件 = 数据源驱动程序
每个插件让 SeaTunnel 能够连接特定的数据源
MySQL 插件:连接 MySQL 数据库
Oracle 插件:连接 Oracle 数据库
Console 插件:输出到控制台
Fake 插件:生成测试数据
- 修改 config/plugin_config,只保留你需要的:(也可以不改,全部下载)
--connectors-v2--
connector-jdbc-mysql
connector-jdbc-oracle
connector-console # 这个建议保留,用于调试输出
--end--
- 安装插件,执行命令
# 进入 SeaTunnel 目录
sh bin/install-plugin.sh
1.3 JVM参数的配置
- 编辑 bin/seatunnel.sh 文件,在文件开头附近添加或修改
export JVM_ARGS="-Xmx2g -Xms1g -XX:MaxDirectMemorySize=1g"
# 其他配置
- 内存配置建议
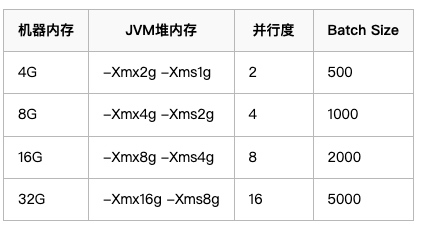
2 使用
2.1、特殊参数说明
2.1.1、source
- 2.3.x 新版本:必须使用 query,不再支持 table 参数
2.1.2、sink
- generate_sink_sql = true:生成自动插入sql。如果目标库没有表,也会自动建表
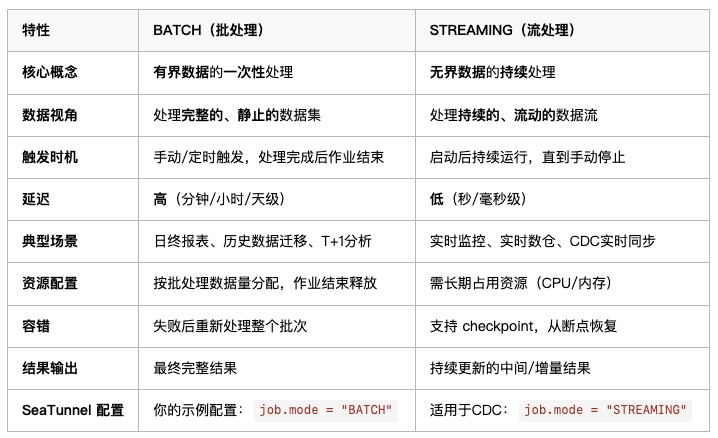
2.1.3、env的job.mode参数📋 BATCH vs STREAMING 对比
在 SeaTunnel 中,job.mode 是决定任务执行方式和数据处理逻辑的核心配置。
🎯 如何选择?
-
如果选择 BATCH:
- 场景:定时同步(如每天凌晨同步前一天数据)、一次性数据迁移、对历史数据的分析计算。
- 特点:数据量已知、处理有明确的开始和结束、不需要实时看到结果。
- 你的案例:从 t_8_100w 表一次性读取100万行数据写入另一数据库,这正是典型的批处理场景,你的配置 job.mode = "BATCH" 是完全正确的。
-
如果选择 STREAMING:
- 场景:需要实时捕获MySQL的INSERT/UPDATE/DELETE操作(CDC)、监控日志流、实时计算仪表盘。
- 特点:数据持续产生、需要低延迟响应、作业长期运行。
- 配置示例:
env {
job.mode = "STREAMING"
# 流处理通常需要checkpoint来保证状态一致性
checkpoint.interval = 60000 # 每60秒做一次checkpoint(毫秒)
}
source {
MySQL-CDC { # 使用CDC源连接器
...
startup.mode = "initial" # 先同步历史全量,再持续读取增量binlog
}
}
- 💡 重要补充:模式决定可用的连接器 你的选择会直接影响可以使用的Source(源) 和Sink(目标) 连接器:
- 仅支持 BATCH 的连接器:通常是那些只能做一次性读取的,比如大部分Jdbc源(你的配置中使用的)、Hive源等。
- 仅支持 STREAMING 的连接器:通常是那些持续监听数据变化的,比如Kafka、Pulsar以及各种CDC源(如MySQL-CDC、SqlServer-CDC)。
- 两者都支持的连接器:部分连接器设计时兼容两种模式,但行为可能不同。例如Fake源在BATCH模式下生成固定数量的数据,在STREAMING模式下则持续生成。
一个关键原则:一个作业内的所有连接器(Source和Sink)必须兼容你设定的job.mode。例如,你不能在一个STREAMING作业中使用一个只支持BATCH的源。
- 🔄 与执行引擎的关系
- SeaTunnel支持多种底层执行引擎(如Zeta、Spark、Flink)。你选择的job.mode必须与引擎能力匹配:
- SeaTunnel Zeta引擎(目前使用的本地模式-e local):同时支持BATCH和STREAMING。
- Spark引擎:主要面向BATCH,其STREAMING是微批处理。
- Flink引擎:原生为STREAMING设计,BATCH是其特例。
总结来说,job.mode = "BATCH" 非常适合当前的一次性全量迁移任务。如果想改为实时同步变更,才需要切换到STREAMING模式并改用CDC源连接器。
2.1.4、sink.jdbc的schema_save_mode 和 data_save_mode参数
- schema_save_mode:表结构处理策略
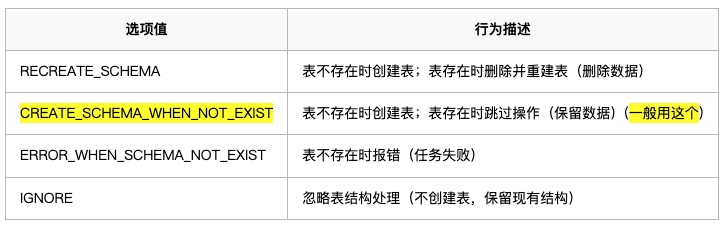
- data_save_mode:数据处理策略
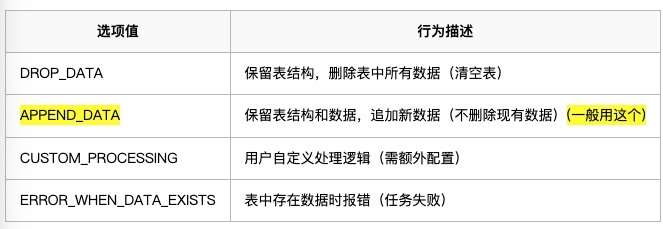
2.2、lib下增加jdbc的包(才能使用对应的数据库)
放置到正确目录:
对于 SeaTunnel (Zeta引擎):将JAR文件复制到 ${SEATUNNEL_HOME}/lib/ 目录。
对于 SeaTunnel (Spark/Flink引擎):将JAR文件复制到 ${SEATUNNEL_HOME}/plugins/jdbc/lib/ 目录。
- 使用mysql的话,需要拷贝jar包到seatunnel安装包/lib 下(Zeta引擎)
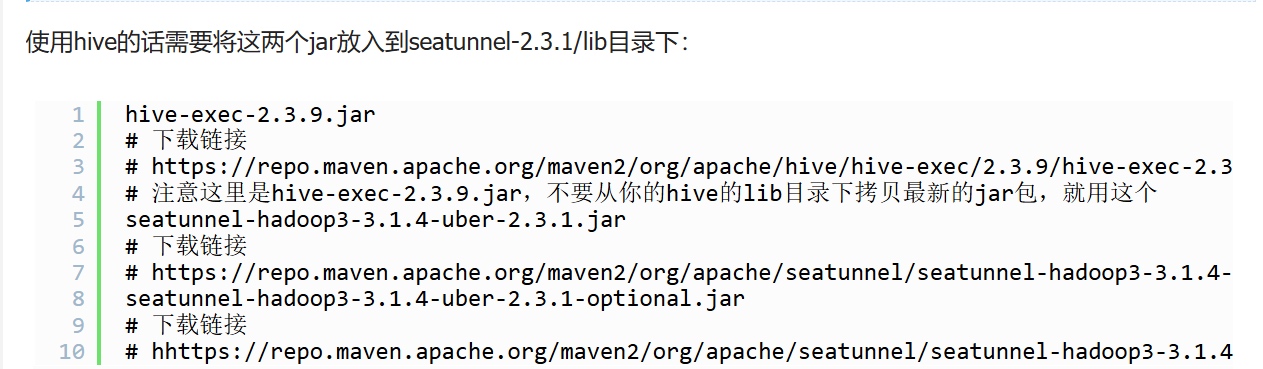
- 其他jdbc,自己去下:seatunnel.apache.org/docs/connec…
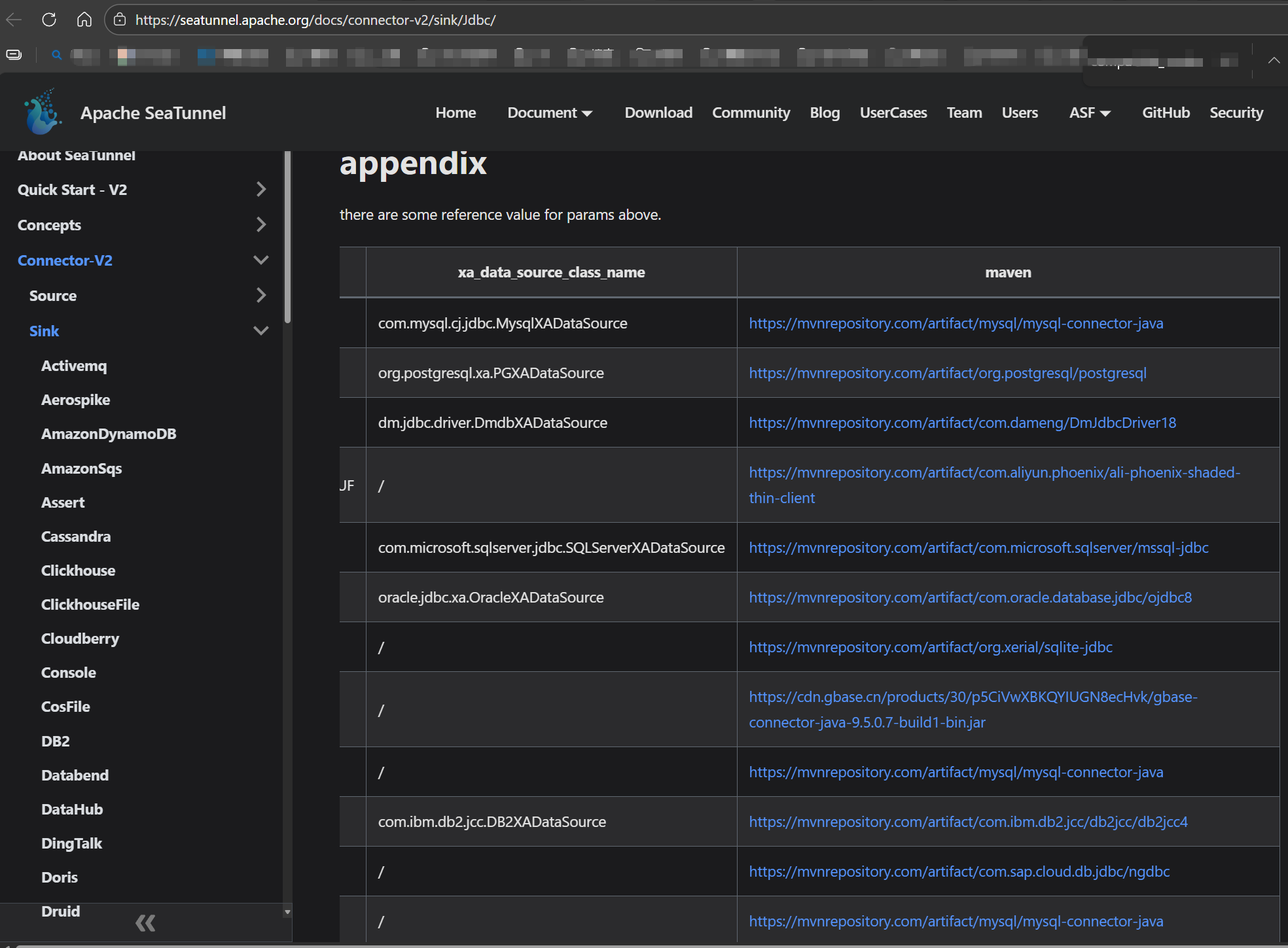
2.3、增加测试数据
- 100万测试数据:t_8_100w
-- mysql建表
CREATE TABLE `t_8_100w` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(2000) NULL COMMENT '名字',
`sex` int null COMMENT '性别:1男;2女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) DEFAULT '13456780000' COMMENT '电话',
`age` varchar(255) NULL COMMENT '字符串年龄转数字',
`create_time` timestamp DEFAULT CURRENT_TIMESTAMP COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
-- 新增存储过程
DELIMITER $$
CREATE PROCEDURE InsertMultipleRows_Batch(
IN start_id INT, -- 起始ID
IN end_id INT, -- 结束ID
IN batch_size INT -- 批次大小
)
BEGIN
DECLARE i INT DEFAULT start_id;
DECLARE description_text LONGTEXT;
DECLARE address_text VARCHAR(255);
DECLARE sex_text INT;
DECLARE total_to_insert INT;
SET total_to_insert = end_id - start_id;
-- 开始事务
START TRANSACTION;
WHILE i < end_id DO
-- 生成精确的1KB文本
SET description_text = REPEAT(CONCAT('DataX_Test_Text_', i, '_ABCDEFGHIJKLMN_'), 41);
-- 根据i%2生成地址
IF i % 2 = 0 THEN
SET address_text = CONCAT('地址', i);
SET sex_text = 1;
ELSE
SET address_text = NULL;
SET sex_text = 2;
END IF;
-- 插入数据
INSERT INTO t_8_100w (`id`, `name`, `sex`, `decimal_f`, `age`, `description`, `address`)
VALUES (
i,
CONCAT('名字', i),
sex_text,
i + 0.000001,
ROUND((RAND() * 12) + 18),
description_text,
address_text
);
SET i = i + 1;
-- 每batch_size条提交一次
IF i % batch_size = 0 OR i = end_id THEN
COMMIT;
IF i < end_id THEN
START TRANSACTION;
END IF;
-- 显示进度
IF i % 50000 = 0 OR i = end_id THEN
SELECT CONCAT('批次 ', start_id, '-', end_id, ': 已插入 ', i - start_id, ' / ', total_to_insert, ' 条记录') AS progress;
END IF;
END IF;
END WHILE;
SELECT CONCAT('批次完成! ID范围: ', start_id, ' 到 ', end_id - 1, ' (共', total_to_insert, '条)') AS batch_complete;
END$$
DELIMITER ;
-- 分别执行新增数据
-- 测试1万条
CALL InsertMultipleRows_Batch(0, 10000, 500);
-- 每10万条创建一次,分批执行
CALL InsertMultipleRows_Batch(10000, 100000, 1000);
CALL InsertMultipleRows_Batch(100000, 200000, 1000);
CALL InsertMultipleRows_Batch(200000, 300000, 1000);
CALL InsertMultipleRows_Batch(300000, 400000, 1000);
CALL InsertMultipleRows_Batch(400000, 500000, 1000);
CALL InsertMultipleRows_Batch(500000, 600000, 1000);
CALL InsertMultipleRows_Batch(600000, 700000, 1000);
CALL InsertMultipleRows_Batch(700000, 800000, 1000);
CALL InsertMultipleRows_Batch(800000, 900000, 1000);
CALL InsertMultipleRows_Batch(900000, 1000000, 1000);
- 10条测试数据:t_8_10(测试增量)
-- 建表
CREATE TABLE `t_8_10` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(2000) NULL COMMENT '名字',
`sex` int null COMMENT '性别:1男;2女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) DEFAULT '13456780000' COMMENT '电话',
`age` varchar(255) NULL COMMENT '字符串年龄转数字',
`create_time` timestamp DEFAULT CURRENT_TIMESTAMP COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
-- 增加10条数据
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(0, '名字11', 1, 0.000001, '13434240000', '29', '2025-12-02 13:28:51', 'test_test', '地址011');
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(1, '名字22', 2, 1.000001, '13456780000', '27', '2025-12-02 13:28:51', 'test_test', NULL);
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(2, '名字33', 1, 2.000001, '13456780000', '19', '2025-12-02 13:28:51', 'test_test', '地址2');
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(3, '名字44', 1, 4.000001, '13456780000', '23', '2025-12-02 13:28:51', 'test_test', '地址4');
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(4, '名字45', 1, 4.000001, '13456780000', '23', '2025-12-02 13:28:51', 'test_test', '地址4');
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(5, '名字5', 2, 5.000001, '13456780000', '26', '2025-12-02 13:28:51', 'test_test', NULL);
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(6, '名字6', 1, 6.000001, '13456780000', '29', '2025-12-02 13:28:51', 'test_test', '地址6');
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(7, '名字7', 2, 6.000001, '13456780000', '26', '2025-12-02 13:28:51', 'test_test', NULL);
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(8, '名字8', 1, 6.000001, '13456780000', '25', '2025-12-02 13:28:51', 'test_test', '地址8');
INSERT INTO t_8_10
(id, name, sex, decimal_f, phone_number, age, create_time, description, address)
VALUES(9, '名字9', 2, 6.000001, '13456780000', '28', '2025-12-02 13:28:51', 'test_test', NULL);
2.4、DEMO1(直接把采集数据打印到控制面板)
# test2mysql.conf - 测试源数据
env {
# 并行度(线程数)
execution.parallelism = 2
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://ip:port/Cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "******"
query = "select * from t_sea_01"
# 连接参数
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
}
}
}
sink {
Console {}
}
执行命令
./data/seatunnel/apache-seatunnel-2.3.12/bin/seatunnel.sh --config ./data/seatunnel/myconf/test2mysql.conf -m local
查看结果

真背CPU啊(2核云服务器)

2.5、DEMO2(mysql2mysql的不同库)
- 可以测试自动建表
-- 在mysql另一个数据库执行
CREATE TABLE `t_8_100w_import` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(2000) NULL COMMENT '名字',
`sex` int null COMMENT '性别:1男;2女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) COMMENT '电话',
`age` varchar(255) NULL COMMENT '字符串年龄转数字',
`create_time` timestamp COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
- conf文件
# mysql2mysql.conf
# 2025-11-28 16:47:47
#
env {
execution.parallelism = 8
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://ip:13306/Cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "abc123"
query = "select * from t_8_100w"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 8
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
fetch_size = 500
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "500"
}
}
}
transform {}
sink {
jdbc {
url = "jdbc:mysql://ip:13306/Cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "abc123"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = Cs2
table = "t_8_100w_import"
# 批量写入条数
batch_size = 500
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
- 执行命令
- 进入bin目录执行
sh seatunnel.sh --config /data/seatunnel/myconf/mysql2mysql.conf -m local
# 后台打印日志执行
nohup seatunnel.sh --config /data/seatunnel/myconf/mysql2mysql.conf -m local > /data/seatunnel/logs/seatunnel.log 2>&1 &
- 结果
***********************************************
Job Statistic Information
***********************************************
Start Time : 2025-11-28 23:18:38
End Time : 2025-11-29 00:40:29
Total Time(s) : 4910
Total Read Count : 1000000
Total Write Count : 1000000
Total Failed Count : 0
***********************************************
2.5、DEMO3(Mysql2Sqlserver、Sqlserver2Mysql)
同一网段 + 不同字段 + 大字段采集(1kb) + 100万数据(1.63GB)
2.5.1、要用sqlserver,必须要先下载ss的jdbc包到lib中(非Spark/Flink引擎)
- 下载地址:learn.microsoft.com/zh-cn/sql/c…
- Seatunnel 主要支持 SQL Server 2008 之后的版本
- 解压并找到JAR:解压后找到 mssql-jdbc-13.2.1.jre8.jar(或类似文件)。
- 放置到正确目录: 对于 SeaTunnel (Zeta引擎):将JAR文件复制到 {SEATUNNEL_HOME}/plugins/jdbc/lib/ 目录。
- 验证驱动版本与Java版本兼容性,检查你的Java版本:
java -version
- 如果Java版本是 8,请使用 mssql-jdbc-12.4.0.jre8.jar
- 如果Java版本是 11或以上,使用 mssql-jdbc-12.4.0.jre11.jar
2.5.2、演示:mysql2sqlserver
注意事项:table要加模式名
table = "DATAX_DEMO.t_8_100w_import_st_d3"
注意事项:sink:jdbcUrl参数:
encrypt=false;trustServerCertificate=true
# encrypt=false:禁用SSL加密。在内网环境中通常安全。
# trustServerCertificate=true:即使使用SSL,也信任服务器证书(跳过验证)。
与encrypt=false一起使用确保连接成功。
执行语句
sh /……/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /……/seatunnel/myconf/myconf/demo3-mysql2sqlserver-107.conf -m local
conf配置
# demo3-mysql2sqlserver-107.conf
env {
execution.parallelism = 5
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://ip:port/cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "******"
query = "select id,name as user_name,sex,decimal_f,phone_number,age,create_time,description,address from t_8_100w"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 5
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
transform {}
sink {
jdbc {
url = "jdbc:sqlserver://ip:1433;databaseName=HR_MZ;encrypt=false;trustServerCertificate=true"
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
user = "sa"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = "HR_MZ"
# 如果不是默认模式dbo,表名前要加模式名。因为sqlserver中是:数据库-模式的概念
table = "DATAX_DEMO.t_8_100w_import_st_d3"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
# SQL Server连接属性(简化,移除MySQL特有参数)
properties = {
# 保持字符编码设置
useUnicode = true
characterEncoding = "utf8"
# 时区设置对SQL Server通常不是必须,但可保留
# serverTimezone = "Asia/Shanghai"
# 可添加SQL Server的批处理优化参数——提升varchar性能
sendStringParametersAsUnicode = "false"
}
}
}
结果
2025-12-09 13:47:25,976 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 2025-12-09 13:39:14
End Time : 2025-12-09 13:47:25
Total Time(s) : 491
Total Read Count : 1000006
Total Write Count : 1000006
Total Failed Count : 0
***********************************************
sqlserver建表
-- sqlserver_st_d3
BEGIN TRANSACTION;
CREATE TABLE [DATAX_DEMO].[t_8_100w_import_st_d3] (
[id] bigint NOT NULL,
[user_name] nvarchar(2000) NULL,
[sex] nvarchar(20) NOT NULL,
[decimal_f] decimal(32,6) NULL,
[phone_number] varchar(20) NULL,
[age] int NULL,
[create_time] DATETIME2 NULL,
[description] varchar(max) NULL,
[address] varchar(2000) NULL,
PRIMARY KEY CLUSTERED ([id])
);
EXEC sp_addextendedproperty
'MS_Description', N'主键',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'id';
EXEC sp_addextendedproperty
'MS_Description', N'名字',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'user_name';
EXEC sp_addextendedproperty
'MS_Description', N'性别',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'sex';
EXEC sp_addextendedproperty
'MS_Description', N'大数字',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'decimal_f';
EXEC sp_addextendedproperty
'MS_Description', N'电话',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'phone_number';
EXEC sp_addextendedproperty
'MS_Description', N'字符串年龄转数字',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'age';
EXEC sp_addextendedproperty
'MS_Description', N'新增时间',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'create_time';
EXEC sp_addextendedproperty
'MS_Description', N'大文本',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'description';
EXEC sp_addextendedproperty
'MS_Description', N'空地址转默认值:未知',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3',
'COLUMN', N'address';
EXEC sp_addextendedproperty
'MS_Description', N'导入ss的表',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d3';
COMMIT TRANSACTION;
2.5.2、演示:sqlserver2mysql
mysql建表
-- demo3-2-sqlserver2mysql-st-107
CREATE TABLE cs2.`t_8_100w_import_sqlserv2mysql_demo3_2` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(2000) NULL COMMENT '名字',
`sex` int null COMMENT '性别:1男;2女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) COMMENT '电话',
`age` varchar(255) NULL COMMENT '字符串年龄转数字',
`create_time` timestamp COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
执行语句
sh /……/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /……/seatunnel/myconf/demo3-2-sqlserver2mysql-st-107.conf -m local
conf配置
# demo3-2-sqlserver2mysql-st-107.conf
env {
# 并行度(线程数)
execution.parallelism = 16
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:sqlserver://ip:1433;databaseName=HR_MZ;encrypt=false;trustServerCertificate=true"
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
user = "sa"
password = "zysoft"
# 如果不是默认模式dbo,表名前要加模式名。因为sqlserver中是:数据库-模式-表的概念
query = "select id,user_name as name,sex,decimal_f,phone_number,age,create_time,description,address from HR_MZ.DATAX_DEMO.t_8_100w_import_st_d3"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 16
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
# 保持字符编码设置
useUnicode = true
characterEncoding = "utf8"
# 时区设置对SQL Server通常不是必须,但可保留
# serverTimezone = "Asia/Shanghai"
# 可添加SQL Server的批处理优化参数——提升varchar性能
sendStringParametersAsUnicode = "false"
}
}
}
transform {}
sink {
jdbc {
url = "jdbc:mysql://ip:port/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = "cs2"
table = "t_8_100w_import_sqlserv2mysql_demo3_2"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
# SQL Server连接属性(简化,移除MySQL特有参数)
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
结果
2025-12-09 14:58:55,560 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 2025-12-09 14:54:32
End Time : 2025-12-09 14:58:55
Total Time(s) : 263
Total Read Count : 1000000
Total Write Count : 1000000
Total Failed Count : 0
***********************************************
2.6、DEMO4(清洗转换:Mysql2Mysql、Mysql2Sqlserver)
- 数据流的概念:seatunnel中有数据流的概念,通过:plugin_output、plugin_input实现数据流向
- 清洗转换规则:
字段映射:name → user_name(不用特殊处理:sql中使用as,出来的字段是目标库的字段名就行)
数据清洗:手机号脱敏 138****1234
类型转换:年龄字段:字符串转数字(本身是字符串的数字:可以直接保存,不用特殊操作。如果转换错误会报错)
值转换:性别字段:1=>男;2=>女
数据过滤:只保留 age>25 的记录
默认值设置:地址:空地址设为'未知'
2.6.1、清洗转换:Mysql2Mysql(transform的插件方式)
- 【transform的插件方式 (seatunnel的设计思路需要让用户去source的query的sql中处理,这里只做demo,生产中不能这样用)】
- mysql建表
-- demo4-1-mysql2mysql-qxzh-st-107.conf
CREATE TABLE cs2.`t_8_100w_imp_st_qxzh_demo4_1` (
`id` bigint NOT NULL COMMENT '主键',
`user_name` varchar(2000) NULL COMMENT '名字',
`sex` varchar(20) null COMMENT '性别:男;女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) COMMENT '电话',
`age` int NULL COMMENT '字符串年龄转数字',
`create_time` timestamp COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
执行语句
# demo4-1-mysql2mysql-qxzh-st-107.conf
sh /……/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /……/seatunnel/myconf/demo4-1-mysql2mysql-qxzh-st-107.conf -m local
conf
# demo4-1-mysql2mysql-qxzh-st-107.conf
env {
# 并行度(线程数)
execution.parallelism = 5
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
jdbc {
url = "jdbc:mysql://ip:port/cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# 实现了:1字段映射(实际生成中,必须在这里做字段转换);5数据过滤:只保留 age>25 的记录(transform中做,实际生成中,必须在这里做数据过滤)
# 使用sql来做清洗转换
query = "select id,name,sex,decimal_f,phone_number,CAST(age AS SIGNED) as age,create_time,description,address from t_8_100w where age > 25"
# 给这个数据集起个名字
plugin_output = "source_data"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 5
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
# 清洗转换
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
FieldRename {
plugin_input = "source_data"
plugin_output = "FieldRename_data"
specific = [
{
field_name = "name"
target_name = "user_name"
}
]
}
# 还可以用:FieldMapper插件,来映射字段
# 2. 手机号脱敏:13812341234 -> 138****1234
Replace {
plugin_input = "FieldRename_data"
plugin_output = "Replace_phone_number_data"
replace_field = "phone_number"
# 正则匹配:第4位到第7位(共11位手机号)
pattern = "(\\d{3})\\d{4}(\\d{4})"
replacement = "$1****$2"
is_regex = true
replace_first = true
}
# 还可以用Sql插件来做脱敏,用这个方式做,还不如直接写到source中query的sql中直接转换
#Sql {
# query = "select id,user_name,sex,decimal_f,CONCAT(LEFT(phone_number, 3), '****', RIGHT(phone_number, 4)) AS phone_number,age,create_time,description,address FROM dual"
#}
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# sql的方式替换(演示成功),这种方式,还不如写到source.query的sql中
Sql {
plugin_input = "Replace_phone_number_data"
plugin_output = "Sql_sex_data"
# 注意:1、使用sql插件,字段必须和source中的字段一致;2、表名可以固定:dual
query = "SELECT id,user_name,CASE sex WHEN 1 THEN '男' WHEN 2 THEN '女' ELSE '未知' END AS sex,decimal_f,phone_number,age,create_time,description,address FROM dual"
}
# Replace的连续替换方案会报错:因为源头sex是int类型,目标sex是varchar类型,Replace1的时候,用的是源头表的sex的int类型,会报错:转换错误,所以转换只能用Sql或者自己写插件
# 第一个Replace:将"1"替换为"男"
#Replace {
# plugin_input = "Replace_phone_number_data"
# plugin_output = "Replace_sex_1_data"
# replace_field = "sex"
# pattern = 1
# replacement = "男"
# is_regex = false
# # 当 is_regex=false 时,不需要 replace_first 参数
#}
# 第二个Replace:将"2"替换为"女"
#Replace {
# plugin_input = "Replace_sex_1_data"
# plugin_output = "Replace_sex_2_data"
# replace_field = "sex"
# pattern = 2
# replacement = "女"
# is_regex = false
# # 当 is_regex=false 时,不需要 replace_first 参数
#}
# 5. 数据过滤:只保留 age > 25 的记录。
# 注意:不能用:Filter,Filter是过滤字段是否要不要的,不是过滤值的。只有使用Sql插件
# (只能用这种方式)注意:实际生成中,数据过滤不在这里做,在source.Jdbc.query的sql中的where过滤做(效率高)
# 注意:age在源头表中的类型是varchar,目标库age的类型是int。这里转换类型会报错
# Sql插件使用的是SeaTunnel内置的SQL解析与执行引擎,它并非完整的数据库,因此在SQL语法支持(特别是类型转换函数)上远不如真实的MySQL。
#Sql {
# plugin_input = "Sql_sex_data"
# plugin_output = "Sql_age_data"
# # 注意:1、使用sql插件,字段必须和source中的字段一致;2、表名可以固定:dual
# query = "SELECT id,user_name,sex,decimal_f,phone_number,CAST(age AS SIGNED) as age,create_time,description,address FROM dual where age > 25"
#}
# 6. 地址默认值:空地址设为'未知'
Sql {
plugin_input = "Sql_sex_data"
plugin_output = "Sql_address_data"
query = "SELECT id,user_name,sex,decimal_f,phone_number,age,create_time,description,case when address is null then '未知' else address end as address FROM dual"
}
# 注意:Replace的正则无法匹配null,会直接跳过,所以不能用Replace
# 第一步:将 NULL 值替换为特殊标记字符串
#Replace {
# plugin_input = "Sql_sex_data"
# plugin_output = "Replace_address_1_data"
# replace_field = "address"
# pattern = "Null"
# replacement = "未知"
# is_regex = false
#}
}
sink {
jdbc {
url = "jdbc:mysql://ip:port/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = cs2
table = "t_8_100w_imp_st_qxzh_demo4_1"
# 接收的最终数据集
plugin_input = "Sql_address_data"
# 表不存在时报错(任务失败),一般用:CREATE_SCHEMA_WHEN_NOT_EXIST(表不存在时创建表;表存在时跳过操作(保留数据))
schema_save_mode = "ERROR_WHEN_SCHEMA_NOT_EXIST"
# 保留表结构和数据,追加新数据(不删除现有数据)(一般用这个)
data_save_mode = "APPEND_DATA"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
结果
2025-12-10 16:22:36,196 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 2025-12-10 16:21:06
End Time : 2025-12-10 16:22:36
Total Time(s) : 89
Total Read Count : 374702
Total Write Count : 374702
Total Failed Count : 0
***********************************************
2.6.2、清洗转换:Mysql2Mysql(使用source.query的sql直接转换、过滤数据方式)
mysql建表
-- demo4-3-mysql2mysql-qxzh-st-107.conf
CREATE TABLE cs2.`t_8_100w_imp_st_qxzh_demo4_3` (
`id` bigint NOT NULL COMMENT '主键',
`user_name` varchar(2000) NULL COMMENT '名字',
`sex` varchar(20) null COMMENT '性别:男;女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) COMMENT '电话',
`age` int NULL COMMENT '字符串年龄转数字',
`create_time` timestamp COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
执行语句
# demo4-3-mysql2mysql-qxzh-st-107.conf
sh /……/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /……/seatunnel/myconf/demo4-3-mysql2mysql-qxzh-st-107.conf -m local
conf
# demo4-3-mysql2mysql-qxzh-st-107.conf
env {
# 并行度(线程数)
execution.parallelism = 5
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
jdbc {
url = "jdbc:mysql://ip:port/cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# 使用sql来做清洗转换
query = "select id,name as user_name,CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '未知' END AS sex,decimal_f,CONCAT(LEFT(phone_number, 3), '****', RIGHT(phone_number, 4)) AS phone_number,CAST(age AS SIGNED) as age,create_time,description,case when address is null then '未知' else address end as address from t_8_100w where age > 25"
# 给这个数据集起个名字
# plugin_output = "source_data"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 5
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
# 清洗转换(简单的清洗转换,直接在source的query的sql中处理了就行)
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
# 还可以用:FieldMapper插件,来映射字段
# 2. 手机号脱敏:13812341234 -> 138****1234
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# 5. 数据过滤:只保留 age > 25 的记录。
# 6. 地址默认值:空地址设为'未知'
}
sink {
jdbc {
url = "jdbc:mysql://ip:port/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = cs2
table = "t_8_100w_imp_st_qxzh_demo4_3"
# 接收的最终数据集
# plugin_input = "Sql_address_data"
# 表不存在时报错(任务失败),一般用:CREATE_SCHEMA_WHEN_NOT_EXIST(表不存在时创建表;表存在时跳过操作(保留数据))
schema_save_mode = "ERROR_WHEN_SCHEMA_NOT_EXIST"
# 保留表结构和数据,追加新数据(不删除现有数据)(一般用这个)
data_save_mode = "APPEND_DATA"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
结果
datax:111s,快了27s(24%)
2025-12-10 16:40:49,784 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 2025-12-10 16:39:25
End Time : 2025-12-10 16:40:49
Total Time(s) : 84
Total Read Count : 374702
Total Write Count : 374702
Total Failed Count : 0
***********************************************
2.6.3、清洗转换:Mysql2Sqlserver(使用source.query的sql直接转换、过滤数据方式)
建表
-- sqlserver_st_d4_qxzh
BEGIN TRANSACTION;
CREATE TABLE [DATAX_DEMO].[t_8_100w_import_st_d4_qxzh] (
[id] bigint NOT NULL,
[user_name] nvarchar(2000) NULL,
[sex] nvarchar(20) NOT NULL,
[decimal_f] decimal(32,6) NULL,
[phone_number] varchar(20) NULL,
[age] int NULL,
[create_time] DATETIME2 NULL,
[description] varchar(max) NULL,
[address] varchar(2000) NULL,
PRIMARY KEY CLUSTERED ([id])
);
EXEC sp_addextendedproperty
'MS_Description', N'主键',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'id';
EXEC sp_addextendedproperty
'MS_Description', N'名字',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'user_name';
EXEC sp_addextendedproperty
'MS_Description', N'性别',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'sex';
EXEC sp_addextendedproperty
'MS_Description', N'大数字',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'decimal_f';
EXEC sp_addextendedproperty
'MS_Description', N'电话',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'phone_number';
EXEC sp_addextendedproperty
'MS_Description', N'字符串年龄转数字',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'age';
EXEC sp_addextendedproperty
'MS_Description', N'新增时间',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'create_time';
EXEC sp_addextendedproperty
'MS_Description', N'大文本',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'description';
EXEC sp_addextendedproperty
'MS_Description', N'空地址转默认值:未知',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh',
'COLUMN', N'address';
EXEC sp_addextendedproperty
'MS_Description', N'导入ss的表',
'SCHEMA', N'DATAX_DEMO',
'TABLE', N't_8_100w_import_st_d4_qxzh';
COMMIT TRANSACTION;
执行语句
# demo4-2-mysql2sqlserver-qxzh-st-107.conf
sh /……/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /……/seatunnel/myconf/demo4-2-mysql2sqlserver-qxzh-st-107.conf -m local
conf
# demo4-2-mysql2sqlserver-qxzh-st-107.conf
env {
# 并行度(线程数)
execution.parallelism = 5
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
jdbc {
url = "jdbc:mysql://ip:port/cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# 使用sql来做清洗转换
query = "select id,name as user_name,CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '未知' END AS sex,decimal_f,CONCAT(LEFT(phone_number, 3), '****', RIGHT(phone_number, 4)) AS phone_number,CAST(age AS SIGNED) as age,create_time,description,case when address is null then '未知' else address end as address from t_8_100w where age > 25"
# 给这个数据集起个名字
# plugin_output = "source_data"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 5
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
# 清洗转换(简单的清洗转换,直接在source的query的sql中处理了就行)
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
# 还可以用:FieldMapper插件,来映射字段
# 2. 手机号脱敏:13812341234 -> 138****1234
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# 5. 数据过滤:只保留 age > 25 的记录。
# 6. 地址默认值:空地址设为'未知'
}
sink {
jdbc {
# encrypt=false:禁用SSL加密。在内网环境中通常安全。
# trustServerCertificate=true:即使使用SSL,也信任服务器证书(跳过验证)。与encrypt=false一起使用确保连接成功。
url = "jdbc:sqlserver://ip:port;databaseName=HR_MZ;encrypt=false;trustServerCertificate=true"
driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"
user = "sa"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = HR_MZ
table = "DATAX_DEMO.t_8_100w_import_st_d4_qxzh"
# 接收的最终数据集
# plugin_input = "Sql_address_data"
# 表不存在时报错(任务失败),一般用:CREATE_SCHEMA_WHEN_NOT_EXIST(表不存在时创建表;表存在时跳过操作(保留数据))
schema_save_mode = "ERROR_WHEN_SCHEMA_NOT_EXIST"
# 保留表结构和数据,追加新数据(不删除现有数据)(一般用这个)
data_save_mode = "APPEND_DATA"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
结果
2025-12-11 09:38:04,300 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 2025-12-11 09:34:52
End Time : 2025-12-11 09:38:04
Total Time(s) : 191
Total Read Count : 374702
Total Write Count : 374702
Total Failed Count : 0
***********************************************
2.7、demo5:全量采集
-
方案选择:见datax:www.cnblogs.com/kakarotto-c…
-
只有一种方式-清空重灌:job.mode = "BATCH" + sink.jdbc.data_save_mode = "DROP_DATA"
- 只做一次性的全量采集,直接使用 job.mode = "BATCH" 的JDBC Source方案就是官方推荐的最佳实践。如果需要同时满足“初始化全量”和“后续实时同步”,则应选择CDC模式。
-
如果要实现类似datax可配置的:覆盖更新,需要在sink.jdbc.data_save_mode使用 CUSTOM_PROCESSING 模式 + 自定义SQL
🛠️ SeaTunnel 实现“覆盖更新”的两种方式

2.7.1、全量方式1:清空重灌(使用 DROP_DATA 模式(推荐)**)
建表
-- demo5-1-mysql2mysql-qxzh-st-ql-107.conf
CREATE TABLE cs2.`t_8_100w_imp_st_qxzh_ql_demo5_1` (
`id` bigint NOT NULL COMMENT '主键',
`user_name` varchar(2000) NULL COMMENT '名字',
`sex` varchar(20) null COMMENT '性别:男;女',
`decimal_f` decimal(32, 6) NULL COMMENT '大数字',
`phone_number` varchar(20) COMMENT '电话',
`age` int NULL COMMENT '字符串年龄转数字',
`create_time` timestamp COMMENT '新增时间',
`description` longtext NULL COMMENT '大文本',
`address` varchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (`id`)
);
执行语句
# demo5-1-mysql2mysql-qxzh-st-ql-107.conf
sh /……/seatunnel/seatunnel-2.3.12/bin/seatunnel.sh --config /……/seatunnel/myconf/demo5-1-mysql2mysql-qxzh-st-ql-107.conf -m local
conf
# demo5-1-mysql2mysql-qxzh-st-ql-107.conf
env {
# 并行度(线程数)
execution.parallelism = 5
# 任务模式:BATCH:批处理模式;STREAMING:流处理模式
job.mode = "BATCH"
}
source {
jdbc {
url = "jdbc:mysql://ip:port/cs1"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# 使用sql来做清洗转换
query = "select id,name as user_name,CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '未知' END AS sex,decimal_f,CONCAT(LEFT(phone_number, 3), '****', RIGHT(phone_number, 4)) AS phone_number,CAST(age AS SIGNED) as age,create_time,description,case when address is null then '未知' else address end as address from t_8_100w where age > 25"
# 给这个数据集起个名字
# plugin_output = "source_data"
# 并行读取配置
# 数值型主键字段
partition_column = "id"
# 分片数,匹配并行度
partition_num = 5
# 批量提交数
fetch_size = 5000
# partition_lower_bound = 1 # 可选:起始ID
# partition_upper_bound = 1000000 # 可选:结束ID
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 使用游标提高大结果集性能
useCursorFetch = "true"
# 每次获取行数
defaultFetchSize = "5000"
}
}
}
# 清洗转换(简单的清洗转换,直接在source的query的sql中处理了就行)
transform {
# 1. 字段映射:sql中做了,实际生成中不在这里处理。直接在source的query的sql中处理了就行
# 还可以用:FieldMapper插件,来映射字段
# 2. 手机号脱敏:13812341234 -> 138****1234
# 3. 年龄转换:字符串转整数(实际生产中,不用转换,也没有内置的转换插件,可以直接保存成功)
# 4. 性别转换:1->男,2->女
# 5. 数据过滤:只保留 age > 25 的记录。
# 6. 地址默认值:空地址设为'未知'
}
sink {
jdbc {
url = "jdbc:mysql://ip:port/cs2"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "zysoft"
# query = "insert into test_table(name,age) values(?,?)"
# 生成自动插入sql。如果目标库没有表,也会自动建表
generate_sink_sql = true
# generate_sink_sql=true。所以:database必须要
database = cs2
table = "t_8_100w_imp_st_qxzh_ql_demo5_1"
# 接收的最终数据集
# plugin_input = "Sql_address_data"
# 表不存在时报错(任务失败),一般用:CREATE_SCHEMA_WHEN_NOT_EXIST(表不存在时创建表;表存在时跳过操作(保留数据))
schema_save_mode = "ERROR_WHEN_SCHEMA_NOT_EXIST"
# APPEND_DATA:保留表结构和数据,追加新数据(不删除现有数据)(一般用这个)
# DROP_DATA:保留表结构,删除表中所有数据(清空表)——实现清空重灌
data_save_mode = "DROP_DATA"
# 批量写入条数
batch_size = 5000
# 批次提交间隔
batch_interval_ms = 500
# 重试次数
max_retries = 3
# 连接参数
# 连接超时时间300ms
connection_check_timeout_sec = 300
properties = {
useUnicode = true
characterEncoding = "utf8"
serverTimezone = "Asia/Shanghai"
# 关键:启用批量重写
rewriteBatchedStatements = "true"
# 启用压缩
useCompression = "true"
# 禁用服务端预处理
useServerPrepStmts = "false"
}
}
}
结果
2025-12-11 10:18:57,313 INFO [s.c.s.s.c.ClientExecuteCommand] [main] -
***********************************************
Job Statistic Information
***********************************************
Start Time : 202
