

Agent 记忆这件事,又往前走了一步。当记忆系统更加精细化之后,我们发现,除了让 Agent 记得准,还应该让它明白——记住了之后哪条还算数。
用户去年说自己住在北京,今年说现在住在上海;之前喜欢喝咖啡,最近改喝茶;去年国庆去了西安,今年五一去了杭州。对一个 Agent 来说,这些都不是简单的“知识点”,而是一条条带着时间线的记忆。
如果系统只会把它们平铺存起来,问题就来了:问“我现在住哪?”和问“我去年住哪?”可能召回同一批内容;问“我喜欢喝什么?”时,旧偏好和新偏好可能一起冒出来;问“我最近去哪旅游了?”时,系统甚至可能把几次事件揉成一句“用户喜欢旅游”。
这次 MemOS v2.0.15,我们把重点放在三件事上:让记忆检索具备时间感知能力,让 Agent 可以检索用户自定义 Skill,并把 filter 字段升级到更适合复杂 Agent 场景的形态。
本次版本亮点
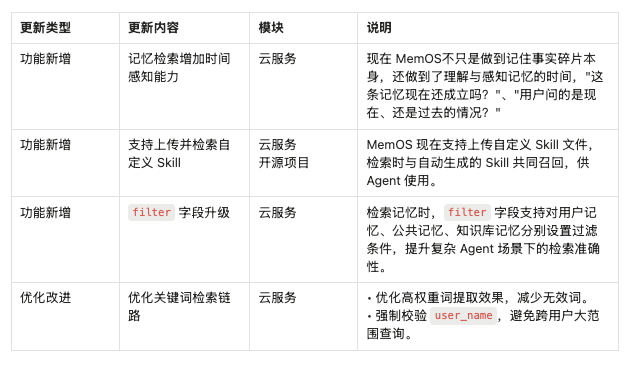
一、记忆检索增加时间感知能力
记忆不是一张静态便签。
很多信息会变。住址会变,偏好会变,关系会变,当前状态也会变。还有一些信息不是“状态”,而是某次具体发生过的事件,比如一次旅行、一笔购买、一场会议。
过去,系统面对这些记忆时,容易遇到三类问题。
1.1 新旧信息冲突
用户先说:我喜欢吃苹果。
后来又说:我不喜欢吃苹果了。
旧系统可能同时保留两条记忆。等用户问“我喜欢吃苹果吗?”时,两条信息都可能被召回,结果就变得不稳定。
现在,MemOS 会自动识别这类前后变化,只返回当前有效的认知:不喜欢。旧版本不会被删除,需要回溯时依然可以查到。
人话说,就是它不再像一个把所有纸条都塞进抽屉的人,而更像一个会在纸条旁边标注“这条已经过期了”“这条是当前版本”的助理。
1.2 问“现在”和问“以前”,不该得到同一个答案
用户说过:
我去年住在北京。
我现在住在上海。
如果问“我现在住哪?”,答案应该是上海。 如果问“我去年住哪?”,答案应该是北京。
这两个问题看起来都在问“住哪”,但真正的差别在时间。
MemOS 现在会理解问题里的时间线索。问“现在”,就优先返回当前版本;问“去年”,就回溯到历史版本。
1.3 事件不应该被粗暴合并
用户说过:
去年国庆我去西安旅游了。
今年五一我去杭州旅游了。
这两条记忆描述的是两次不同事件。它们不应该被合并成一句模糊的“用户喜欢旅游”。
MemOS 现在会保留每次事件的完整信息。用户问“我最近去哪里旅游了?”时,系统会优先把更近的杭州排在前面,同时不丢掉西安这条历史事件。
这就像整理相册。一次西安旅行、一次杭州旅行,应该各自成册,而不是被压缩成一个标签:爱旅游
怎么做到的?
一句话说清:写入时做分类,检索时识别时间线索。
在添加记忆阶段,MemOS 会自动判断一条记忆更像哪一种:
- 会变化的状态:住在哪、喜欢什么、和谁关系近。 这类记忆会更新同一条记忆,并保留不同时间下的版本。
- 某次发生的事件:去了哪、买了什么、参加了什么。 这类记忆会完整保留事件本身,不强行合并。
在检索记忆阶段,系统会根据问题中是否存在时间线索,决定是否启用对应能力:
- 没有时间相关问题时,走正常检索。
- 有时间相关问题时,理解时间指向,选择对应版本,并按时间相关性排序。
记忆的整理、冲突处理与更新会在后台异步处理,不会阻塞对话。
代码示例
云服务:
import os, time, uuid, requests
API_KEY = "YOUR_API_KEY"
BASE_URL = "<https://memos.memtensor.cn/api/openmem/v1>"
HEADERS = {"Content-Type": "application/json", "Authorization": f"Token {API_KEY}"}
user_id = f"temporal-test-{uuid.uuid4().hex[:8]}"
conversation_id = f"conv-{uuid.uuid4().hex[:6]}"
# 1. 写入几条混合了状态变更和事件的记忆
messages = [
"我去年住在北京。",
"我现在住在上海。",
"去年国庆我去西安旅游了。",
"今年五一我去杭州旅游了。",
"我之前喜欢喝咖啡,最近改喝茶了。",
]
for msg in messages:
requests.post(f"{BASE_URL}/add/message", headers=HEADERS, json={
"user_id": user_id,
"conversation_id": conversation_id,
"messages": [{"role": "user", "content": msg}],
})
time.sleep(10) # 留出后台处理时间
# 2. 检索——不需要额外参数,MemOS 自己识别时间线索
queries = [
"我现在住哪?", # 期望:上海
"去年我住哪?", # 期望:北京
"我最近去哪旅游了?", # 期望:杭州优先
"我喜欢喝什么?", # 期望:茶
]
for query in queries:
res = requests.post(f"{BASE_URL}/search/memory", headers=HEADERS, json={
"user_id": user_id,
"query": query,
})
memories = res.json().get("data", {}).get("memory_detail_list", [])
print(f"Q: {query}")
for i, m in enumerate(memories[:3], 1):
print(f" {i}. {m.get('memory')}")
开源项目用法基本一致,把 BASE_URL 换成本地地址:
import time, uuid, requests
BASE_URL = "<http://127.0.0.1:8001>"
user_id = f"temporal-test-{uuid.uuid4().hex[:8]}"
mem_cube_id = f"cube-{user_id}"
# 注册用户
requests.post(f"{BASE_URL}/product/users/register", json={
"user_id": user_id,
"mem_cube_id": mem_cube_id,
})
# 写入
for msg in messages:
requests.post(f"{BASE_URL}/product/add", json={
"user_id": user_id,
"mem_cube_id": mem_cube_id,
"messages": [{"role": "user", "content": msg}],
})
time.sleep(10)
# 检索
for query in queries:
res = requests.post(f"{BASE_URL}/product/search", json={
"user_id": user_id,
"query": query,
"mem_cube_id": mem_cube_id,
"top_k": 5,
})
data = res.json().get("data") or {}
memories = []
for bucket in data.get("text_mem") or []:
memories.extend(bucket.get("memories") or [])
print(f"Q: {query}")
for i, m in enumerate(memories[:3], 1):
info = (m.get("metadata") or {}).get("internal_info") or {}
print(f" {i}. {m.get('memory')}")
print(f" timespec={info.get('timespec')} form={info.get('memory_form')}")
评测效果
在 LME 的 multi-session 场景上,效果从 65.41% 提升到 75.18%。这个场景专门考察跨会话、跨时间的信息变化——正好是上面三类问题最容易出现的地方。
二、支持上传并检索自定义 Skill:把团队流程变成 Agent 能用的记忆
MemOS 一直主张"记忆即资产"。
在真实对话里沉淀下来的解决路径、用户偏好、业务流程,不只是历史记录,它们也可以变成 Agent 后续执行任务时能调用的技能素材。
这次更新后,MemOS 支持上传自定义 Skill 文件。检索时,自定义 Skill 会和自动生成的 Skill 一起被召回,供 Agent 使用。
一句话说清楚就是,以前 Agent 像一个只靠临场发挥的新人;现在,你可以把团队已经验证过的 SOP、客服流程、排障手册直接交给它。遇到相关问题时,它先把合适的流程找出来,再按流程做事。
下面用一个「客服 Agent 退货处理流程」的例子,把整个链路走一遍。
2.1 通过 API 上传到知识库
你可以通过上传知识库文件的方式,把一份指导客服 Agent 协助用户完成退货的 Skill 文件上传到知识库。文件内容支持 URL 与 Base64。
import os
import json
import requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {os.environ['MEMOS_API_KEY']}",
}
data = {
"knowledgebase_id": "kb_xxx", # 替换为你的知识库 ID
"file": [
{
"type": "skill",
"content": "https://cdn.memtensor.com.cn/file/SKILL.md",
}
],
}
url = f"{os.environ['MEMOS_BASE_URL']}/add/knowledgebase-file"
res = requests.post(url=url, headers=headers, data=json.dumps(data))
print(f"result: {res.json()}")
🌰 举个栗子
客服 Agent 遇到用户说:我想退一件三天前买的耳机
这时,MemOS 可以召回“客服退货处理流程”这个 Skill,让 Agent 按既定流程确认订单、判断是否符合退货条件、引导用户进入后续处理。
2.2 通过控制台上传
也可以直接从控制台上传。
路径是:
控制台 → 知识库 → 选择目标知识库 → 上传文档 → 选择「技能文件」
支持上传 Markdown 文件或 ZIP 包。
这对非开发同学会更友好。比如运营、客服负责人、解决方案同学已经维护了一份 Markdown SOP,不需要写代码,也可以把它变成 Agent 可检索的 Skill。
2.3 检索 Skill
上传成功后,检索时传入 knowledgebase_ids 并开启 include_skill,MemOS 会返回与查询内容相关的技能。
data = {
"query": "用户想退一件三天前买的耳机",
"user_id": "memos_user_123",
"conversation_id": "session_001",
"knowledgebase_ids": ["kb_xxx"],
"include_skill": True,
}
res = requests.post(
url=f"{os.environ['MEMOS_BASE_URL']}/search/memory",
headers=headers,
data=json.dumps(data),
)
print(f"result: {res.json()}")
这一步的价值不在于“搜到一个文件”,而在于 Agent 能拿到一段可执行的流程。
知识库文档更像“资料”,Skill 更像“做事方法”。当 Agent 面对用户请求时,它不只是知道退货政策是什么,还能知道该按什么步骤把事情办完。
2.4 Skill 文件规范
单文件 .md 规范:
- 大小限制:≤ 100KB
- 必须包含
name和description字段
技能压缩包 .zip 规范:

开源项目同样支持对上传的 Skill 压缩包文件进行记忆生成和检索。
用户在添加记忆时可以提供一个可下载链接,启动本地部署服务后,可以通过接口写入并检索相关 Skill 记忆。
# 添加 Skill
curl -X POST '<http://localhost:8001/product/add>' \\
-H 'Content-Type: application/json' \\
-d '{
"user_id": "test_user_1234567890",
"writable_cube_ids": ["test_user_1234567890"],
"messages": [
{
"type": "file",
"file": {
"file_data": "<https://xxxx.oss-cn-xxxx.aliyuncs.com/memos-memory-guide.zip>"
}
}
],
"async_mode": "async",
"mode": "fine",
"session_id": "1234567890",
"is_upload_skill": true
}'
# 检索 Skill
curl -X POST '<http://localhost:8001/product/search>' \\
-H 'Content-Type: application/json' \\
-d '{
"user_id": "test_user_1234567890",
"readable_cube_ids": ["test_user_1234567890"],
"query": "memos memory",
"include_skill_memory": true
}'
三、filter 字段升级:不同来源的记忆,可以分开筛
检索接口的 filter 以前只支持全局过滤——所有记忆走同一套条件。复杂场景里这不够用。
这次 filter 字段升级后,检索记忆时可以对用户记忆、知识库记忆、公共记忆分别设置过滤条件。
3.1 升级前:设置全局过滤条件
假设要对今年所有有关“阅读”的“对话”做年终总结,可以用一个全局 filter:
data = {
"user_id": "memos_user_123",
"query": "整理我今年和阅读相关的要点",
"filter": {
"and": [
{"tags": {"contains": "阅读"}},
{"create_time": {"gte": "2025-01-01"}},
{"create_time": {"lte": "2025-12-31"}},
{"scene": "chat"},
],
},
}
这个写法适合来源比较单一的场景。
3.2 升级后:用户、知识库、公共记忆分别过滤
如果一个 Agent 要同时结合知识库制度、用户对话记录和项目公告,就可以分别设置过滤条件:
data = {
"user_id": "memos_user_123",
"query": "结合已有知识库中的制度、我的对话记录和项目公告,整理一份合规要点",
"knowledgebase_ids": ["kb_xxx"],
"filter": {
"knowledgebase": {
"and": [
{"tags": {"contains": "制度"}},
{"create_time": {"gte": "2025-01-01"}},
{"create_time": {"lte": "2025-12-31"}},
]
},
"user": {
"and": [
{"agent_id": "compliance_assistant"},
{"scene": "chat"},
{"create_time": {"gte": "2025-06-01"}},
]
},
"public": {
"and": [
{"tags": {"contains": "公告"}},
]
},
},
}
一句话说清楚,过去是“所有资料一起按同一套条件筛”;现在是“不同资料柜用不同筛选规则”。
四、关键词检索链路优化:少捞无效词,少查错用户
这次版本也优化了关键词检索链路,主要有两点:
- 优化高权重词提取效果,减少无效词。
- 强制校验
user_name,避免跨用户大范围查询。
这类改进看起来不像新功能那么显眼,但对检索质量很关键。
关键词检索有点像在一段话里抓重点。抓得太松,会把很多无效词也拿去检索;抓得太偏,真正有用的信息反而被稀释。高权重词提取优化后,检索链路会更少被无效词干扰。
user_name 强制校验则更像入口处的身份确认。该查谁的记忆,就查谁的记忆,避免查询范围被错误放大。
开源社区代码更新记录
新功能
- 记忆检索增加时间感知能力
- 支持上传并检索自定义 Skill
- filter 字段升级
改进
- 优化关键词检索链路
- 优化高权重词提取效果,减少无效词
- 强制校验
user_name,避免跨用户大范围查询 Bug 修复 - 本次素材中未提供具体 Bug 修复项,暂不展开。
老规矩!
感兴趣的同学直接上手试:
- 云服务控制台: memos.memtensor.cn
- 开源项目 GitHub: github.com/MemTensor/M…
关于 MemOS
MemOS 为 AI 应用构建统一的记忆管理平台,让智能系统如大脑般拥有灵活、可迁移、可共享的长期记忆和即时记忆。
作为记忆张量首次提出“记忆调度”架构的 AI 记忆操作系统,我们希望通过 MemOS 全面重构模型记忆资源的生命周期管理,为智能系统提供高效且灵活的记忆管理能力。
