

Deep Research 把长任务检索、分步阅读、带引用报告推到台前。用户给一个模糊问题,系统会拆查询、翻资料、压缩上下文,再产出一篇结构完整的报告。
这件事很有用。普通搜索解决的是“找页面”,Research Agent 解决的是“把一批材料组织成叙事”。问题也藏在这里:报告越顺,读者越容易把排版、引用和逻辑连贯误判成证据充分。
科研和技术调研里,最麻烦的报告往往引用很多。链接能打开,DOI 看着正规,段落后面挂着参考文献。细查会发现:综述套综述,新闻稿混进实证研究,预印本被写成已验证结果,开放域 QA 实验被外推到企业知识库,低质 AI 论文也被检索系统纳入上下文。
图1:头图——左侧是格式漂亮但来源混杂的报告,右侧是每个判断都能追到 DOI、PMID 或 OpenAlex ID 的证据链
OpenAI Deep Research 让大众看到“多步检索 + 引用报告”的体验;Google AI co-scientist 把焦点推向科研假设生成;FutureHouse 更接近生物医学文献阅读与推断;PaperQA 关注论文片段级问答;AutoResearchBench 这类评测提醒开发者,报告质量需要拆成可验证任务。它们共同暴露了一个问题:模型会读材料,也会把材料组织得很像研究,但来源质量、任务边界和结论强度仍要单独审计。
漂亮引用最容易掩盖错配
科研证据有层级。随机对照试验、队列研究、系统评价、机制实验、预印本、观点文章、新闻解读,不能放在同一格里。数据库也有边界:PubMed 更适合医学与生命科学;OpenAlex 覆盖广,但元数据、重复项和学科分类需要复核;工程系统、企业 RAG、开发者工具还要看 ACM、ACL、arXiv、企业技术报告和基准数据集。
看一个模拟审计案例。
Research Agent 生成判断:
“2021 年以来,RAG 已在企业知识库问答中显著降低幻觉率。”
候选来源包括三类:一篇开放域 QA 论文,实验在 Natural Questions / TriviaQA 上做,指标是 EM/F1;一篇 RAG 综述,讨论检索增强对答案质量的影响;一篇企业博客,讲内部知识库上线经验,没有公开数据和评测协议。
逐条查后,问题很清楚:开放域 QA 不是企业知识库;EM/F1 不是幻觉率;综述没有新增实验;博客缺少可复现实验设计。引用都存在,支撑关系偏弱,强判断必须降级。
| 报告原句 | 来源类型 | 错配点 | 审计后表述 |
|---|---|---|---|
| RAG 已在企业知识库问答中显著降低幻觉率 | 开放域 QA 实验 | 场景、指标都不匹配 | 部分开放域 QA 实验显示检索增强可提升答案匹配指标,不能直接外推到企业知识库幻觉率 |
| 研究表明该方法已验证有效 | 预印本 | 未经同行评审,缺少独立复现 | 预印本报告了正向结果,证据强度需单独标记 |
| 多篇综述支持该结论 | 综述 | 综述引用综述,未回到原始实验 | 综述显示该方向被持续讨论,结论需回查原始研究 |
伪证据链常见信号很固定:段末统一挂引用,句子和来源无法对应;只有网页链接,没有 DOI、PMID、OpenAlex ID;“实验研究”“综述”“预印本”“新闻”统一写成“研究表明”;结论缺少样本、任务、时间范围和排除条件。
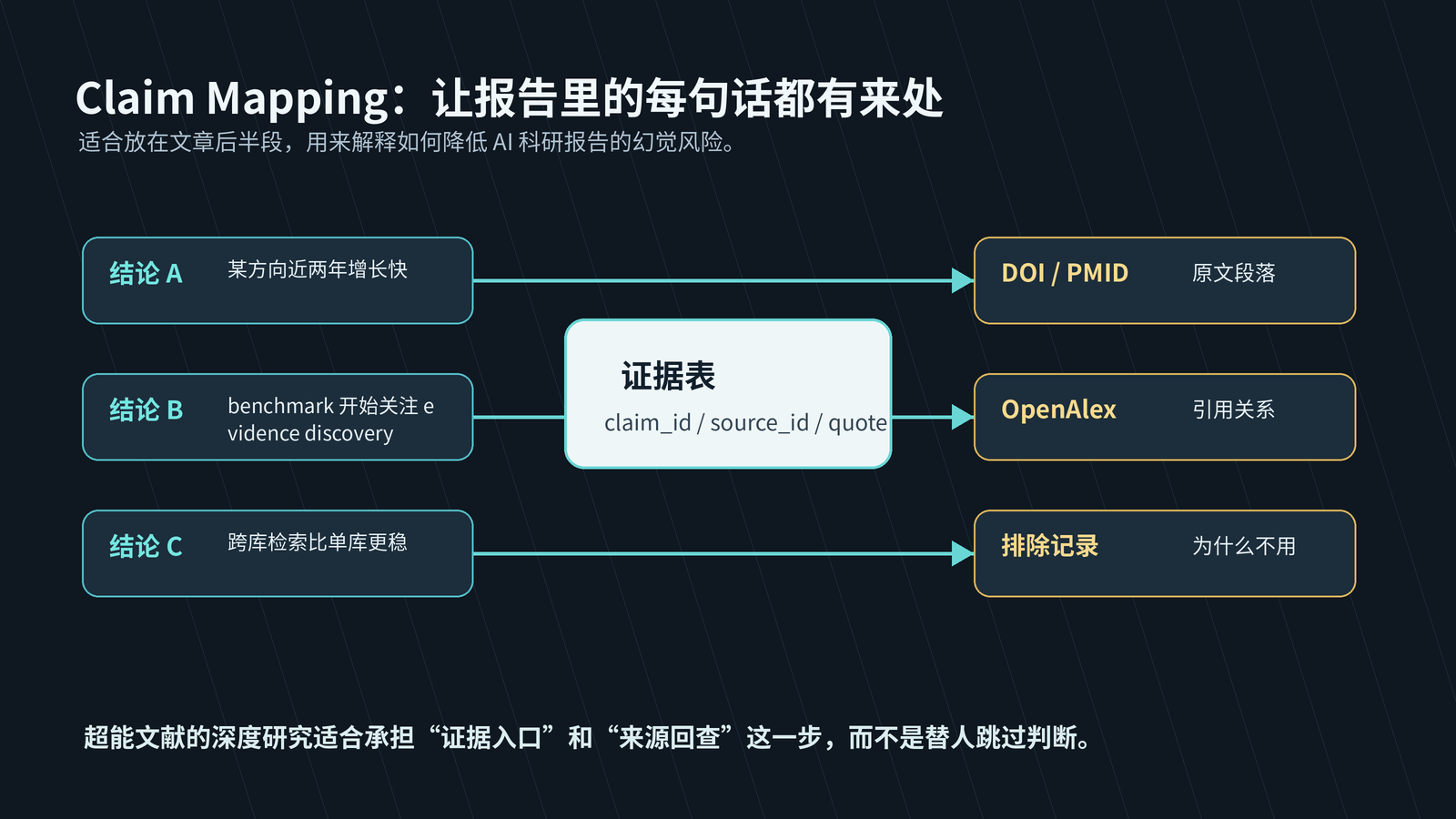
图2:流程图——报告生成后,抽取关键判断,回查来源 ID、证据类型、原文位置和支持强度
把审计做成句子级工作流
Research Agent 输出适合当初稿和线索池。科研场景要把审计压到句子级:每个强判断对应哪篇文献、哪张表、哪个实验设置、哪个结论段;对应不上,就降级或删除。
一个最小 claim-source alignment 结构可以这样写:
{
"claim": "2021年以来,RAG显著降低企业知识库问答幻觉率",
"scope": {
"time": "2021-2025",
"domain": "enterprise_knowledge_base_qa",
"metrics": ["hallucination", "attribution"]
},
"source": {
"title": "example paper",
"ids": {
"doi": "",
"pmid": "",
"openalex": ""
},
"type": "empirical_study",
"evidence_location": "results/table_2",
"matched_scope": {
"domain": false,
"task": true,
"metric": false
},
"support_level": "weak",
"reason": "开放域QA实验,未评估企业知识库幻觉率"
},
"action": "downgrade_claim_or_search_more"
}
开发者可以把它做成质检 pipeline:先抽取报告里的强判断,再按句子检索来源片段,接着判定文献类型、任务范围、指标匹配度,最后输出支持等级。UI 上左侧放 claim,右侧放来源 ID、原文片段、证据类型、错配点和降级建议。审稿人不用先读完整报告,就能定位高风险句子。
图3:claim-source alignment 矩阵——行是报告判断,列是来源 ID、文献类型、任务范围、指标、原文位置、支持强度
假设用户要问:“RAG 在企业知识库里靠谱吗?”
不要直接丢给 Deep Research。先改成可检索问题:
“2021—2025 年,RAG 用于企业或组织内部知识库问答时,在答案准确性、幻觉率、可追溯性和安全风险上的实证研究、基准评测与系统综述。”
同时写排除条件:不收纯产品新闻;不收没有实验或案例设计的观点文章;预印本单独标记;企业知识库、文档问答、开放域 QA 分层比较。检索词围绕 enterprise knowledge base QA、document question answering、citation grounding、source attribution、prompt injection、retrieval augmented generation evaluation 展开。
在来源整理阶段,可以用超能文献做前置检索:用中文限定研究范围,检索 PubMed、OpenAlex 等数据库,并保留 DOI、PMID、OpenAlex ID,方便后续沿引用回查原文;它只负责提高检索和追溯效率,不判断结论对错。suppr.wilddata.cn?referralCode=jpiUdA&utm_source=juejin
最后交给 Research Agent 的材料,不应是一串链接,而是一张审计表:年份、数据库、文献类型、任务、数据、指标、原文位置、支持强度。下一次生成报告前,先要求系统补齐这张表。