

一句话介绍:
kubernetes-ontology是一个只读的 Kubernetes 拓扑和诊断服务。它把 Pod、Workload、Service、Node、存储、RBAC、Event、Webhook 等对象之间的关系恢复成图,并提供 CLI、HTTP API 和本地可视化页面,方便人排障,也方便 AI Agent 做稳定查询。
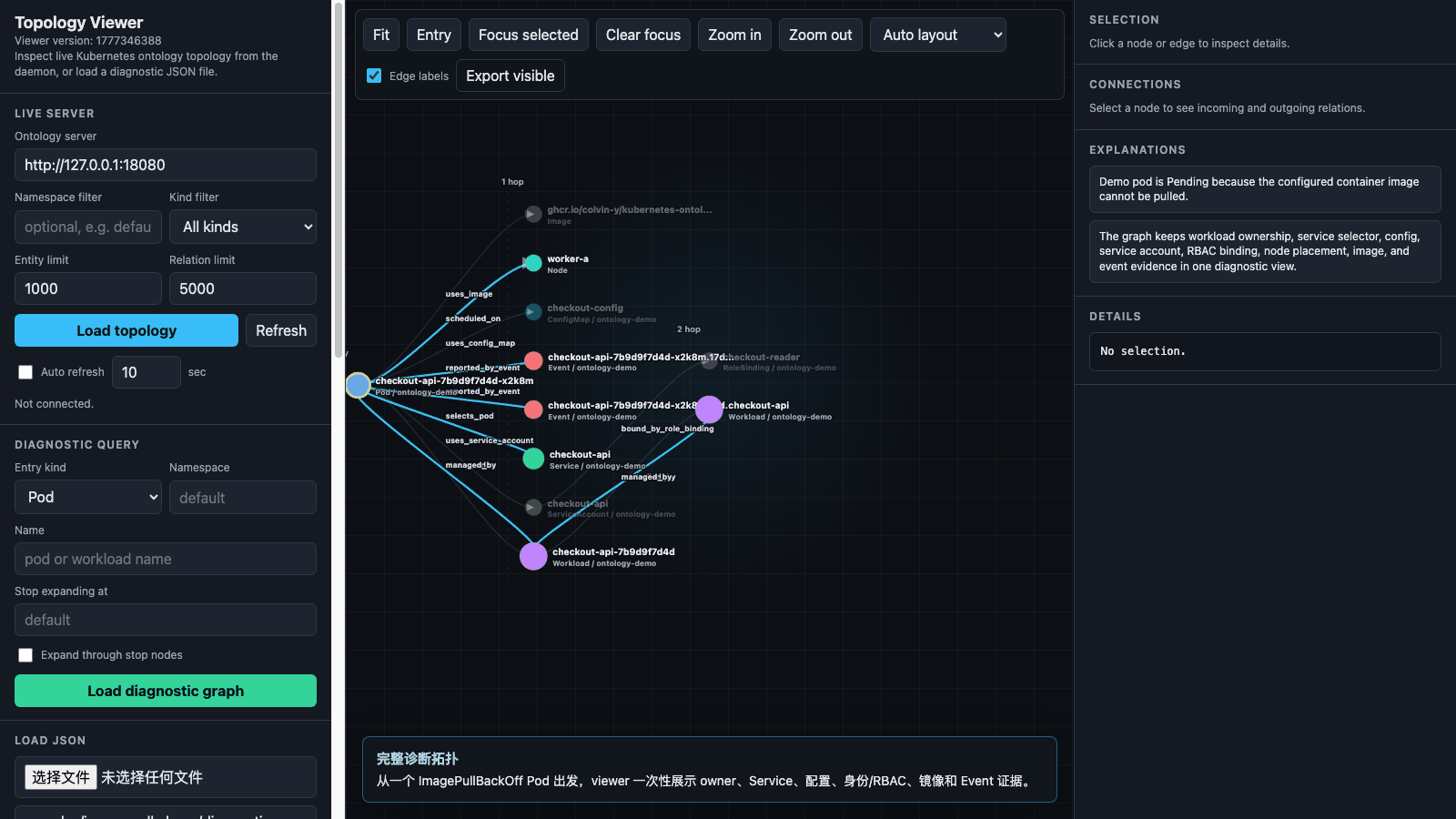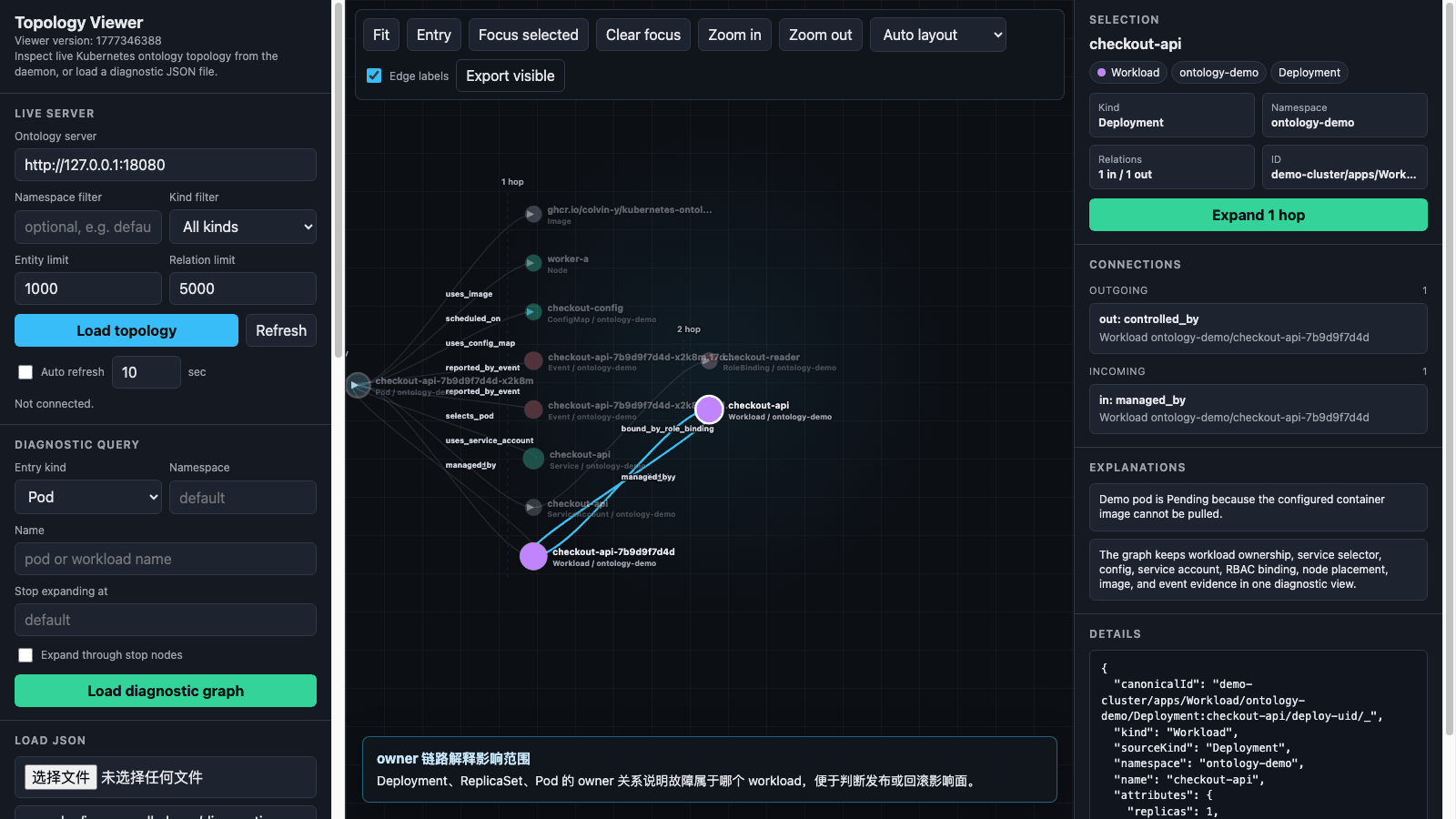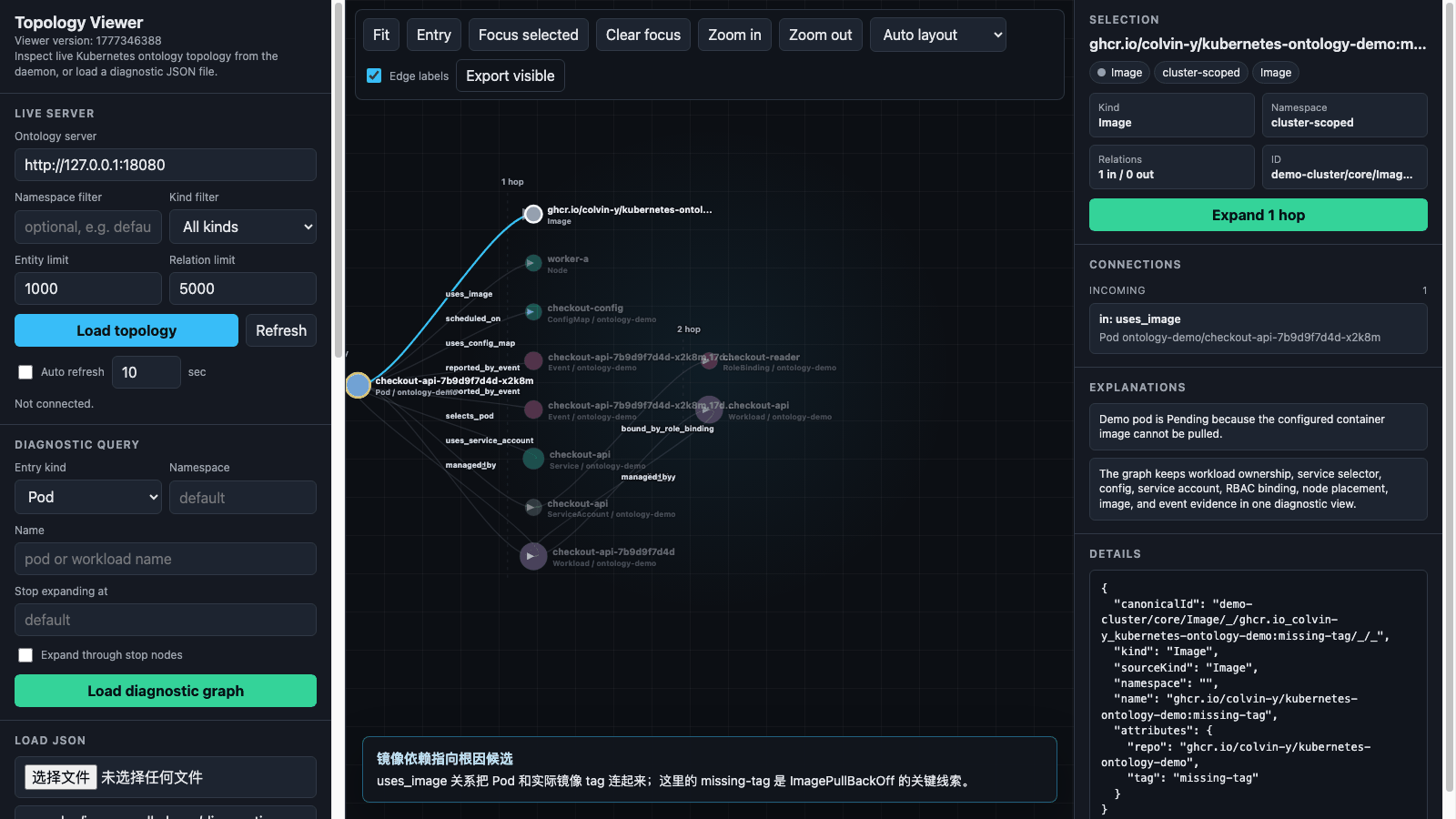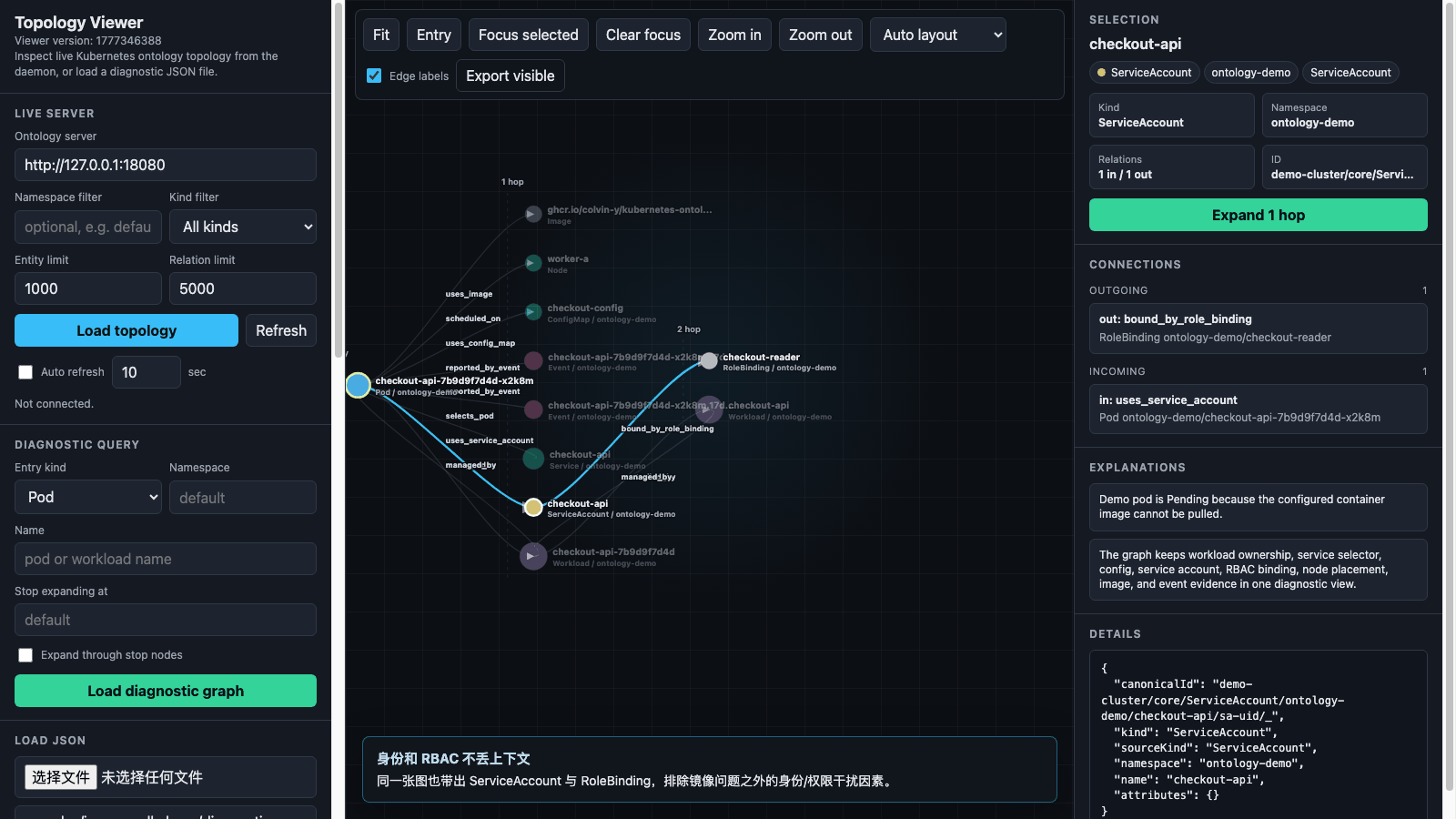
上图来自真实 viewer 页面捕获,展示从一个 ImagePullBackOff Pod 出发,逐步查看
workload、Service、配置、身份/RBAC、镜像和 Event 证据的过程。
为什么做这个项目
Kubernetes 排障通常不是一条命令能结束的。
一个 Pod 起不来时,我们往往会从 kubectl get pod 开始,然后继续查:
- 这个 Pod 属于哪个 Deployment、StatefulSet 或自定义 workload
- 哪个 Service 选中了它
- 调度到了哪个 Node
- 依赖了哪些 ConfigMap、Secret、ServiceAccount、PVC 和镜像
- 是否有失败 Event
- 是否被 Admission Webhook、RBAC 或 CSI 相关组件影响
这些信息都在 Kubernetes API 里,但它们分散在不同对象、不同字段、不同 namespace
和不同 controller 语义里。人可以一层层追,但这个过程很容易遗漏上下文;AI Agent
如果每次都从零散 kubectl 输出开始推理,也很难稳定复用。
kubernetes-ontology 的思路是:不要把 Kubernetes 对象当作一堆平铺 JSON,
而是把它们变成带类型、带证据来源、可查询的关系图。
它解决什么问题
当前开源 MVP 聚焦三个场景。
第一,人类排障。你可以从一个 Pod 或 Workload 出发,快速看到它周围的关键依赖: owner 链路、Service selector、Node、配置、身份、存储、镜像、Event、Webhook 等。
第二,AI Agent 查询。Agent 不需要每次重新拼很多 kubectl 命令,可以通过稳定的
只读 CLI 和 HTTP API 查询实体、关系、邻居和诊断子图。
第三,拓扑观察。daemon 会从 Kubernetes API 做启动快照,并通过 informer 优先的 增量刷新保持内存图更新;如果 informer 不可用,也可以回退到 polling。
项目刻意保持轻量:
- 不需要图数据库
- 不需要安装业务 CRD
- 不需要修改被观测 workload
- 运行时不 create、patch、update、delete 被观测的 Kubernetes 资源
- MVP 的图状态只保存在内存中,重启后从 Kubernetes API 重新构建
Demo:一个 ImagePullBackOff 怎么变成关系图
仓库里放了一个合成 demo:
samples/image-pull-demo/
这个 demo 创建了一个 ontology-demo namespace,里面有一个故意使用不存在镜像
tag 的 checkout-api Deployment。Pod 会进入 ImagePullBackOff。
传统排障时,我们可能会分别看 Pod、Deployment、Service、ConfigMap、
ServiceAccount、RoleBinding 和 Event。用 kubernetes-ontology 查询后,这些证据会
出现在同一张诊断图里:
Deployment -> ReplicaSet -> Pod:工作负载 owner 链路Service -> Pod:selector 是否选中目标 PodPod -> Node:Pod 调度到了哪里Pod -> ConfigMap:运行配置依赖Pod -> ServiceAccount -> RoleBinding:身份和 RBAC 证据Pod -> Image:实际使用的镜像Event -> Pod:拉镜像失败和 backoff 事件
如果只是想看效果,不需要连 Kubernetes 集群:
make visualize
然后打开:
http://127.0.0.1:8765/?file=samples/image-pull-demo/diagnostic-graph.json
如果想在测试集群里复现:
kubectl apply -f samples/image-pull-demo/manifests.yaml
启动 daemon 后,查询失败 Pod 的诊断图:
POD="$(kubectl -n ontology-demo get pod -l app.kubernetes.io/name=checkout-api -o jsonpath='{.items[0].metadata.name}')"
./bin/kubernetes-ontology \
--server "http://127.0.0.1:18080" \
--diagnose-pod \
--namespace ontology-demo \
--name "${POD}"
也可以打开本地 viewer,从 Diagnostic 面板加载这个 Pod 的关系图。
适合哪些人试
如果你经常做 Kubernetes 排障、平台工程、SRE、云原生工具开发,或者正在尝试让 AI Agent 理解集群状态,这个项目应该会有用。
比较适合先尝试的场景:
- 想把集群拓扑和故障上下文可视化
- 想让 Agent 用稳定 JSON 查询 Kubernetes 依赖关系
- 想分析 Pod、Service、Workload、存储、RBAC、Event 之间的关系
- 想在不引入图数据库和控制器的情况下做轻量诊断
当前状态
项目现在是开源 MVP,已经支持:
- Pod 和 Workload 诊断入口
- CLI、HTTP API、本地 viewer
- ownerReference 链路恢复
- Service selector 匹配
- Pod 到 Node、ConfigMap、Secret、ServiceAccount、Image、PVC 的关系
- PVC、PV、StorageClass、CSI Driver 的存储链路
- ServiceAccount 到 RoleBinding、ClusterRoleBinding 的证据
- Event 和 Admission Webhook 证据
- informer 增量刷新和 polling fallback
- Helm 部署和源码本地运行两种方式
后续会继续补齐更多 Kubernetes 语义、诊断策略、Agent 工作流和 viewer 体验。
安全边界
这个项目的运行时目标是只读诊断。daemon 不会修改被观测的 Kubernetes 资源,不会给 业务 workload 写 annotation/status,也不会安装业务 CRD 或 controller。
Helm 模式会安装项目自己的 Deployment、Service、ServiceAccount、ConfigMap 和只读
RBAC,这是服务运行所需的安装 footprint。默认 RBAC 只包含采集资源的
get、list、watch 权限;Secret 读取默认开启,以便恢复 Secret 节点和
uses_secret 关系;如需关闭可设置 rbac.readSecrets=false。
HTTP API 建议只暴露在本机或受控内网环境,不建议直接作为公网多租户服务。
欢迎试用和反馈
如果你想快速体验,建议从这几个文件开始:
- 中文说明:
README.zh-CN.md - 快速开始:
QUICKSTART.md - demo:
samples/image-pull-demo/README.zh-CN.md
如果这个方向对你有用,欢迎在 GitHub 上点一个 star,也欢迎提 issue 反馈你希望恢复的 Kubernetes 关系、诊断场景或 Agent 查询方式。
如果你正在做 Kubernetes 排障、平台工程、SRE 工具或 AI Agent 运维,我很想听听你觉得还应该优先支持哪些 failure mode。欢迎直接在 GitHub 提 issue / discussion。
