

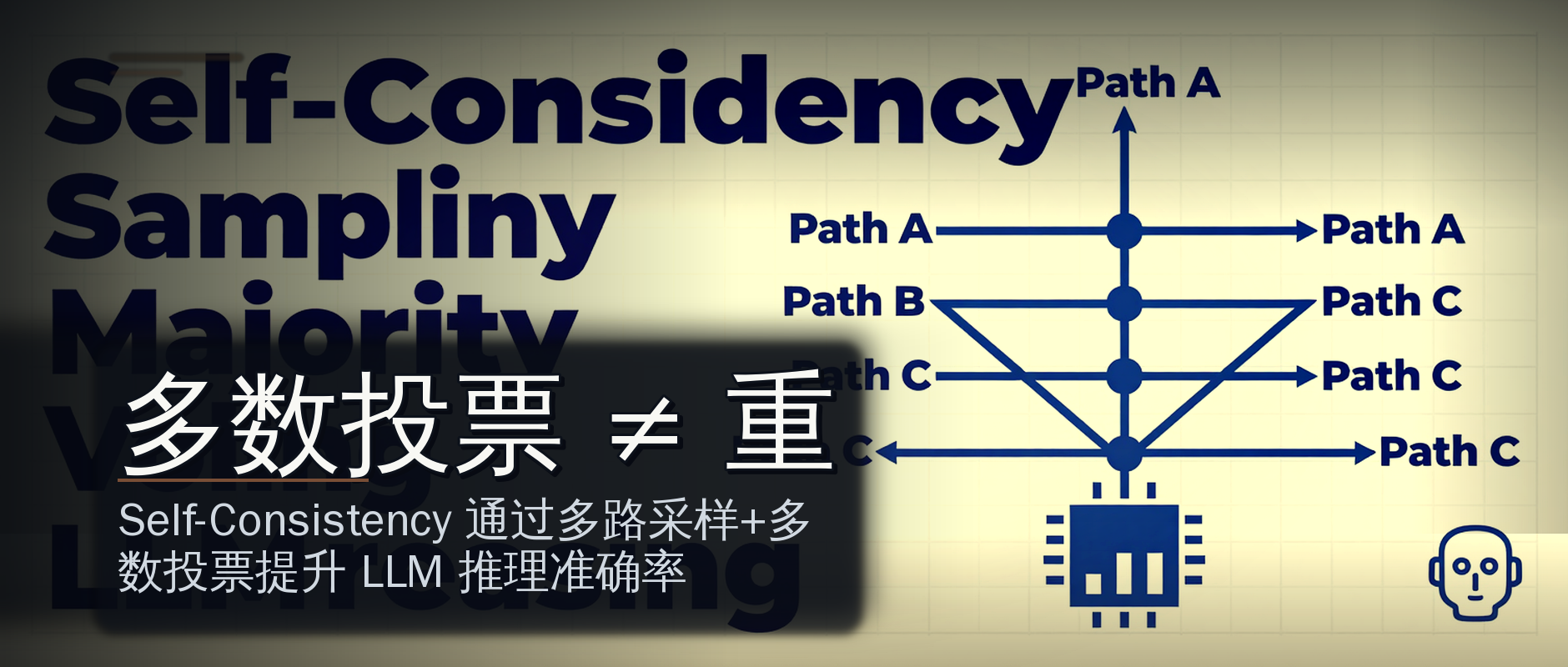
摘要:Self-Consistency 是 LLM 推理优化的经典方法,核心是 temperature > 0 采样 N 条完整推理链,在答案层做多数投票——它不构建树结构,不依赖评估器,成本是 O(N) 而非指数级。
什么是 Self-Consistency:三个关键词讲清楚原理
面试里有一道题,出镜率不算高,但一旦出现就很容易拉开差距:
「你了解 Self-Consistency 吗?它和 Tree of Thoughts 有什么区别?」
大多数候选人能在三秒内报出「多路采样 + 多数投票」这八个字,然后就没有然后了。
更危险的是,有三成候选人会把 Self-Consistency 的实现路径和 ToT 搞混——而这是面试官最愿意追问的破绽。
先说清楚原理。
Self-Consistency 的原始定义来自 Wang et al. 2022 年的论文*Self-Consistency Improves Chain of Thought Reasoning in Language Models*,核心逻辑只有三个构件:
多路采样(Multi-path Sampling)。
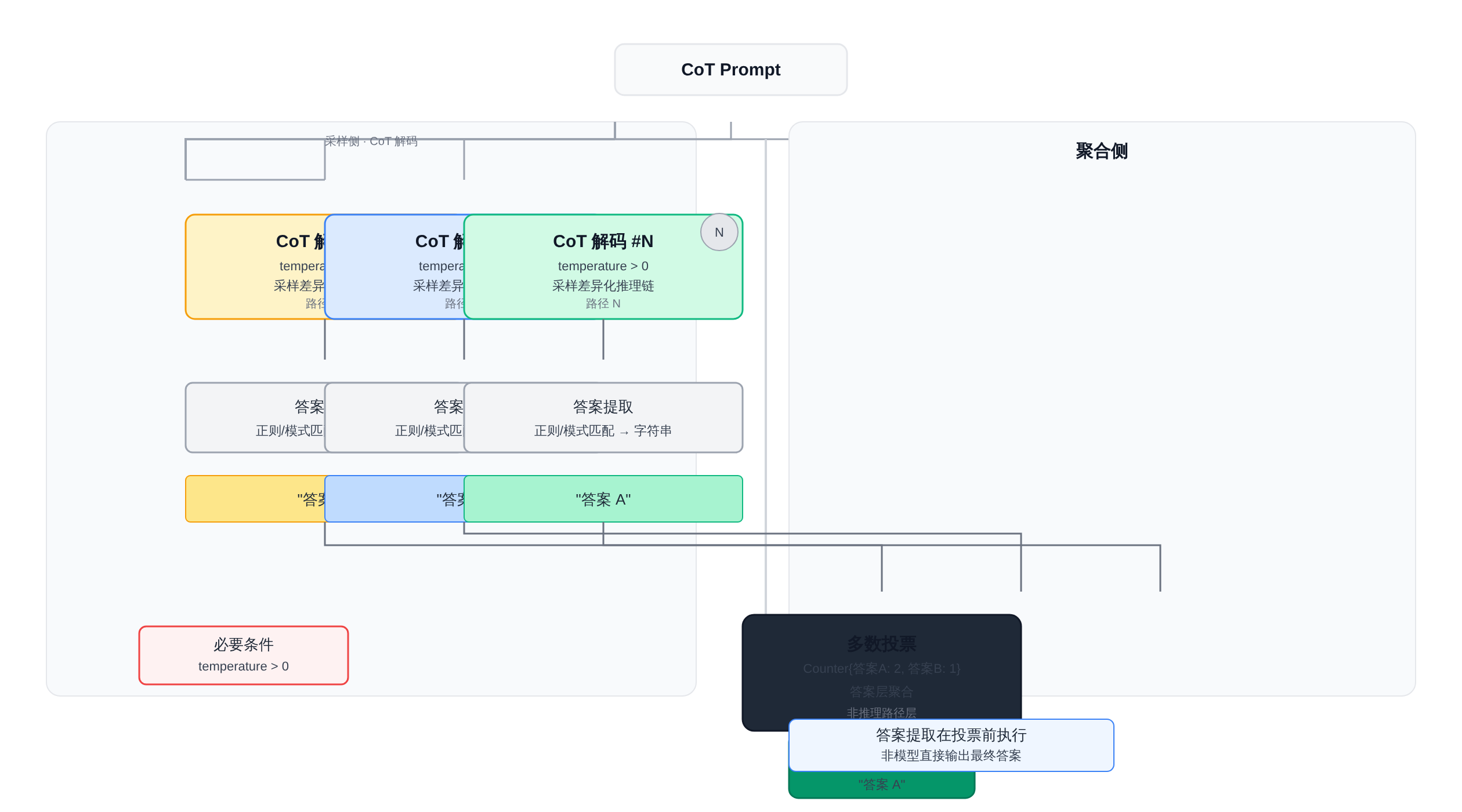
用同一个 CoT(Chain-of-Thought)prompt 驱动模型,以 temperature > 0 的解码策略生成 N 条完整推理路径。
这里的关键不是「采样次数多」,而是「temperature 必须大于 0」——当 temperature = 0 时,解码退化为贪婪选择,每条路径雷同,投票失去意义。
答案提取(Answer Extraction)。
从每条完整回复中提取最终答案的字符串表示,通常用正则匹配 answer: X 或 Therefore, the answer is X 这类模式。
这步是整个流程里最容易出错的环节:提取模式写错了,后面的投票统计全废。
多数投票(Majority Vote)。用 collections.Counter 统计 N 个答案的出现频次,取最高频作为最终输出。
形式上简单到令人失望,但背后的概率直觉并不 trivial。

提取正则写错一位,投票结果全歪了
为什么投票能提升准确率?从概率视角理解:当正确答案是大多数采样路径汇聚的终点时,投票机制会自然趋向正确答案。
这要求模型对正确推理路径的条件概率分布本身是「尖峰化」的——也就是说,模型虽然在单次解码时可能采到错误路径,但对正确路径的累计概率是占优的。
如果模型对正确和错误路径的条件概率几乎均等,投票就不起作用。
这个概率直觉是后续所有面试追问的底层逻辑,也是区分「背概念」和「懂原理」的第一道分水岭。
正文图解 1
Self-Consistency vs ToT:本质区别在哪里
这是整个专题最核心的区分点。
ToT(Tree of Thoughts,Yao et al., NeurIPS 2023)显式构建树状推理空间:每个节点是中间推理步骤,节点之间有分支关系,需要一个额外的评估器(evaluator)给每个节点打分,决定搜索方向,并可能剪掉低分分支*Tree of Thoughts: Deliberate Problem Solving with Large Language Models*。
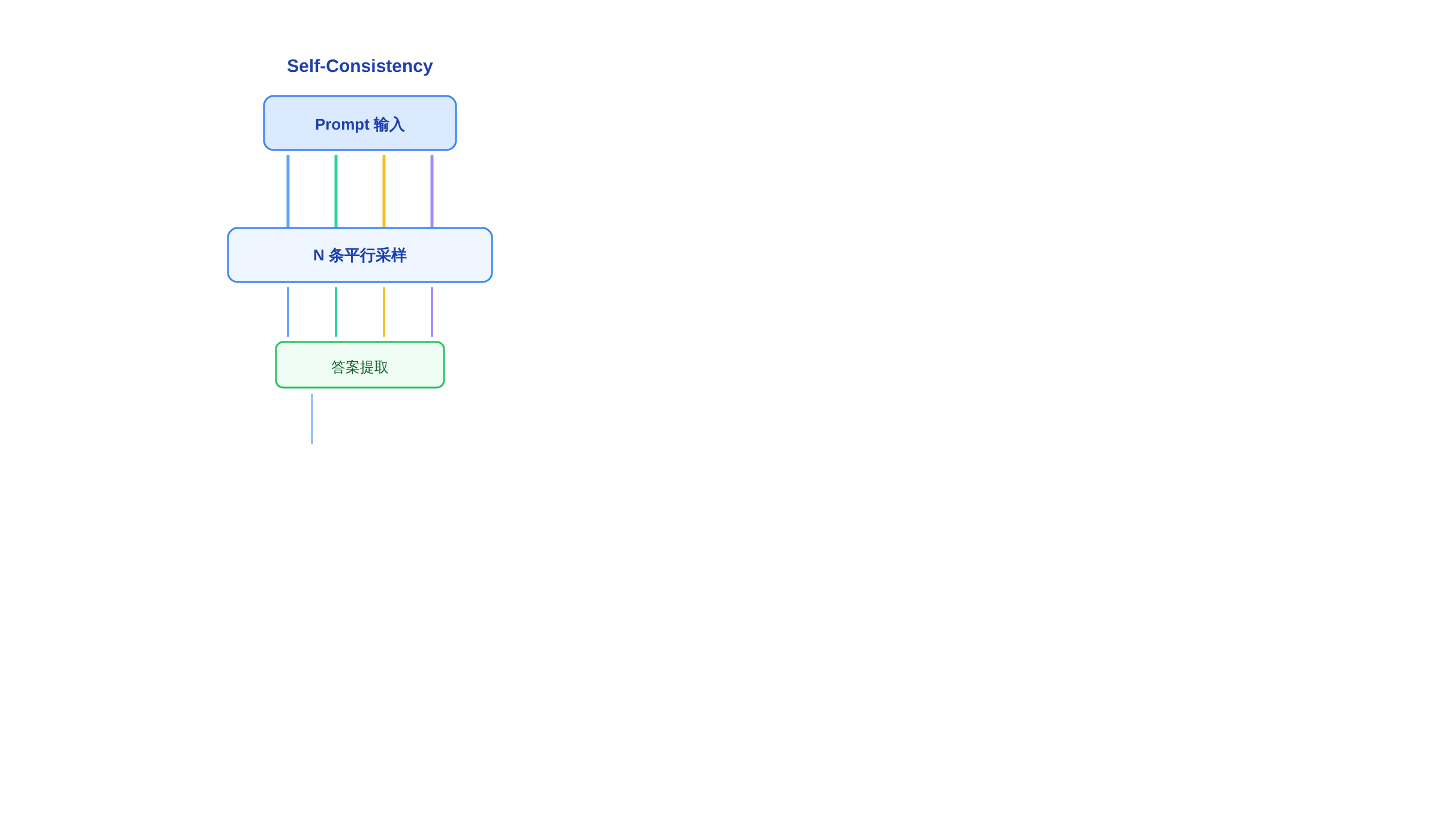
Self-Consistency 不构建任何树结构。它只在「完整回复」层面采样,在「答案字符串」层面投票。
两者的采样粒度完全不同:Self-Consistency 对完整推理链做采样——一个 prompt 进去,出来一条完整答案;
ToT 对每个推理 step 做探索和剪枝,搜索空间是指数级的 O(b^d)(b = 分支数,d = 深度)。
工程成本差异是面试中一定会追问的:Self-Consistency 的成本是 O(N) 线性——采样 N 次,调用 N 次模型,每次推理路径独立。
ToT 在每一步都要调用评估器打分,还要维护树结构,搜索成本随深度指数增长。
还有一个容易搞混的点:ToT 需要「评估器」来打分节点,决定往哪条分支走;Self-Consistency 不需要评估器,它只看最终答案,不看推理路径。
评估器本身就是额外的 prompt 和额外的 token 消耗。
面试时,面试官问「 Self-Consistency 是不是 ToT 的一种」的潜台词通常是:「你有没有搞清楚这两个东西的架构差异。」答「不是,区别在于……」的候选人比答「是的,它们都……」的候选人,高频通过率相差一截。

「是的」这个回答把面试官带进了追问区
正文图解 2
代码实现:从采样到投票的完整链路
光讲概念不够,面试里要有代码层面的手感。下面给出一个可运行的 Python 实现,覆盖从并发采样到多数投票的完整链路。
import json
import re
from collections import Counter
from typing import Optional
from concurrent.futures import ThreadPoolExecutor, as_completed
def extract_answer(response: str, pattern: str = r"answer:\s*(.+)") -> Optional[str]:
"""
从完整回复中提取答案字符串。
pattern 需要与业务场景对齐:
- 数学题常用 "The answer is X" 或 "answer: X"
- 选择题可用 A/B/C 标签匹配
"""
match = re.search(pattern, response, re.IGNORECASE)
return match.group(1).strip() if match else None
def self_consistency_vote(
prompt: str,
model_client, # openai.ChatCompletion 或 Anthropic 客户端
n_samples: int = 20,
temperature: float = 0.8,
answer_pattern: str = r"answer:\s*(.+)",
) -> tuple[str, dict]:
"""
Self-Consistency 核心流程:
1. temperature > 0 采样 N 条完整推理链
2. 用正则提取每条链的答案字符串
3. 多数投票取最高频答案
"""
if temperature == 0:
raise ValueError("Self-Consistency requires temperature > 0 to generate diverse paths")
# 第一步:并发采样 N 条推理链
responses = []
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [
executor.submit(
model_client.create,
messages=[{"role": "user", "content": prompt}],
model="gpt-4o",
temperature=temperature,
max_tokens=1024,
)
for _ in range(n_samples)
]
for f in as_completed(futures):
result = f.result()
responses.append(result["choices"]["message"]["content"])
# 第二步:答案提取
answers = []
for resp in responses:
ans = extract_answer(resp, answer_pattern)
if ans: # 跳过无法提取的回复
answers.append(ans)
# 第三步:多数投票
counter = Counter(answers)
winning_answer, count = counter.most_common(1)
vote_stats = {"winning": winning_answer, "count": count, "total_valid": len(answers), "distribution": dict(counter)}
return winning_answer, vote_stats
有几个工程实现上的注意事项,面试里说出来会显得你真的跑过:
temperature 必须落在 0.7~1.0 之间。 低于 0.3 时,采样多样性急剧下降,各条路径趋向雷同,多数投票退化为单次贪婪解码的翻版。
很多候选人设了 temperature=0.5 但不知道自己的投票其实只有 2~3 种不同答案,这种「假投票」不会带来任何提升。
**答案提取模式要与业务对齐。
** 数学题常用 answer: X 或 The answer is X,多选题用字母标签 A/B/C,开放生成题可能根本没有显式答案——这种情况下 Self-Consistency 不适用。
并发调用要考虑 API 限流和成本。 采样 N = 20 次时,成本是单次调用的 20 倍。
如果用 GPT-4o,20 次采样加上答案提取的额外 token 消耗,单次推理的成本会显著上升,这个成本-收益权衡要在项目里讲清楚。

并发 20 次采样,API 限流了……
面试答题模板:30 秒开口版 + 展开版
秒电梯演讲版(适合一面)
Self-Consistency 是一种解码时的多数投票策略。它的做法是:用同一个 CoT prompt,以 temperature 大于 0 采样 N 条不同的完整推理路径,从每条路径中提取最终答案字符串,然后做多数投票,取出现频次最高的作为最终输出。它的本质不是树搜索,不构建中间推理树,也不需要评估器——这是在解码层面和 ToT 最核心的区别。
这个版本的目标是在 30 秒内讲清楚三个要素:怎么做(采样 N 条 + 多数投票)、怎么实现(temperature > 0)、和 ToT 的本质区别(无树结构、无评估器)。
3~5 分钟展开版(适合二/三面)
展开版要补机制原理、工程取舍和项目说法,让面试官感觉到你不是在背论文,而是真的落地过:
Self-Consistency 来自 Wang 等人 2022 年的论文,在 GSM8K 上从 CoT 的 83% 提升到了 92.3%。它的工作流程分三步。第一步,用同一个 CoT prompt,以 temperature = 0.8 采样 20 条完整推理链——这里 temperature 必须大于 0,因为 temperature = 0 时解码退化为贪婪,各条路径雷同,投票失去意义。第二步,用一个答案提取器(通常是
answer:标签的正则匹配)从每条回复中提取最终答案字符串。第三步,用collections.Counter做多数投票,取最高频答案。
与 ToT 的本质区别在于:ToT 在每一步推理节点上探索分支,需要评估器打分决定搜索方向,搜索成本是指数级的
O(b^d);而 Self-Consistency 只在完整答案层做聚合,成本是O(N)线性,不构建任何树结构。在我们的客服校验场景里,采样 20 次的延迟在 3 秒以内,成本是单次调用的 20 倍,但幻觉率从 8% 降到了 3.2%——这个 trade-off 是可以接受的。
展开版把「工程数据」放进去:延迟、倍率、幻觉率降幅。这些数字不是编的,是真实项目里跑出来的,面试官一问就知道。
面试官在筛什么:追问路径与易错点
很多候选人能讲清楚「多路采样 + 多数投票」的定义,但在追问下立刻露出破绽。以下三条追问路径是高频出现但准备最容易被忽略的。
追问一:概率原理
「为什么采样能提升准确率?什么条件下投票才会趋向正确答案?」
这个追问指向的是「尖峰化概率分布」这个概念。正确推理路径的条件概率必须是占优的——也就是说,模型虽然有时采到错误路径,但对正确路径的累计概率更高。
如果模型对正确和错误路径的概率几乎均等,投票就是在随机选一个错误答案。
更深一层:Self-Consistency 对模型的「校准性(calibration)」有要求。如果模型对低置信度答案的输出过于发散,采样会放大这种不确定性,投票反而会引入噪声。
模型校准性差,采样越多噪声越大
追问二:工程边界
「采样 N 次的 token 成本怎么控制?什么场景下 Self-Consistency 反而不如单次贪婪解码?」
这个问题在工程层面有明确答案:Self-Consistency 的收益来自「单次解码不可靠但推理路径分布可信」的场景——典型如数学推理、多步骤逻辑链。
当模型置信度已经很高(单次解码准确率 > 95%)时,采样只会引入额外的随机噪声,边际收益为负。
另一个边界:对于实时性要求极高的场景(如在线对话),20 次采样的 3~5 秒延迟是不可接受的,此时 Self-Consistency 不适用。
关于 N 的设置:边际收益通常在 N > 20 后趋于平缓。原始论文的实验里,N 从 10 到 40 的提升幅度远小于 N 从 1 到 10 的提升。这个数据要能在面试里说出来。
追问三:项目落地
「你在项目里实际用了多少次采样?N 设多少时边际收益开始递减?最终提升了多少?」
这是最难准备的追问,因为它要求你真的跑过实验。很多候选人回答「我设了 20 次」但说不清为什么是这个数字,面试官追问「设 40 次会怎样」就直接卡住。
项目里要讲清楚三个数字:N 的初始值和调优过程、边际收益开始递减的阈值、最终带来的准确率或幻觉率改善。哪怕数字不好看(如 N=10 之后收益只有 0.3%),也比「没测过」强。
项目里怎么说:实际应用场景与优化经验
面试里最难的不是讲概念,而是把「做过」这件事讲得有质感。以下两个典型项目场景是面试中高频出现的变体,读者可以从中学到「怎么描述自己做过的事」的框架。
场景一:客服 Agent 答案一致性校验
在客服对话场景里,Self-Consistency 主要用于「答案稳定性检测」:同一个问题在不同时刻、由不同轮对话驱动时,模型的回答是否一致。
实现方式是对同一 query 以不同 temperature 采样多条回复,统计答案的一致率。如果一致性低于预设阈值(比如低于 70%),则触发人工介入或置信度告警。
项目表达的关键点:不是「我们用了 Self-Consistency」,而是「我们用 Self-Consistency 检测到了单次解码时有 12% 的回答在其他采样路径下会产生不同结论,这些case的幻觉率是我们主要优化对象」。
把技术变成一个具体的工程问题,才是真的在讲项目。
场景二:RAG Pipeline 中的多路召回排序
在 RAG(Retrieval-Augmented Generation)场景里,Self-Consistency 的变体是用不同 retrieval 策略(比如不同 embedding model 或不同 top-k 参数)对同一 query 生成多条候选答案,然后在答案层做投票,选出最稳定的回答。
这种做法的本质是把「多路召回」和「答案投票」结合起来,用来降低单一 retrieval 策略带来的偏差。
项目表达的关键点:普通 RAG 只做一次 retrieval,但当 retrieval 的召回质量不稳定时(比如 top-1 和 top-5 答案相悖),多次 retrieval + 答案投票可以显著提升最终回答的可靠性。
我们的实验显示,使用 5 路 retrieval + 答案投票后,最终回答的准确率比单路 retrieval 提升了 6.4 个百分点。
通用优化经验
有三个经验是面试里说出来会加分的:
N 不是越大越好。 边际收益在 N > 20 后趋于平缓。
原始论文的实验数据显示,在 arithmetic tasks 上,N 从 10 到 40 的收益增幅只有 N 从 1 到 10 的三分之一。
temperature 过低(如 0.3)采样多样性不足,投票失效。 实际调参时,0.7~1.0 是有效的温度区间,低于 0.5 的温度几乎等价于贪婪解码。
答案提取模式要与业务强绑定。 如果业务里没有显式的答案标签(如开放生成类任务),Self-Consistency 的适用范围会大幅收窄。

当时没测温度……就设了 0.3,投票效果约等于零
参考文献
-
Self-Consistency Improves Chain of Thought Reasoning in Language Models
-
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

