

前言
本文对YOLOv11目标检测模型中的核心创新模块——C2PSA进行了深入的源码级解析。C2PSA(C2 Position-Sensitive Attention)通过引入位置敏感注意力机制(PSA),有效增强了模型对空间关键信息的捕捉能力,从而提升检测精度,尤其在复杂场景和小目标检测中表现显著。文章详细剖析了C2PSA及其子模块PSABlock、Attention的完整源码结构、前向传播流程与关键参数,并结合YAML配置文件实例,解释了不同模型规模(n/s/m/l/x)下的参数缩放规律。内容涵盖模块的设计动机、工作流程图解、常见问题解答,旨在帮助读者从根本上理解并将其应用于自定义模型改进中
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv11改进专栏
@[TOC]
注意
这里用的代码版本为: tag = 8.3.0
概述
C2PSA(C2 Position-Sensitive Attention) 是 YOLO11 中引入的创新模块,旨在通过引入PSA(Position-Sensitive Attention, 位置敏感注意力机制)来增强特征提取和处理能力。传统的CNN(卷积神经网络)在处理图像时,通常对所有位置上的特征一视同仁,忽略了不同位置特征的重要性差异,C2PSA 引入位置敏感注意力机制的核心动机正是增强特征表示——通过自注意力机制,模型可以动态地调整不同位置特征的重要性,从而更好地捕捉全局和局部信息。
C2PSA通过多个 PSABlock 堆叠实现对空间位置的自适应权重分配,每个 PSABlock 包含多头自注意力机制和前馈网络(Feed-Forward Network, FFN),从而在特征图的不同位置上进行更精细的特征学习,兼顾全局与局部信息。
- 动机:卷积对不同位置“一视同仁”,C2PSA 通过自注意力让模型学习“哪些位置更重要”。
- 核心思路:在 CSP 风格的分流-汇合中,对一支使用 PSA(自注意力 + FFN),另一支保留原始/线性特征,再拼接融合。
C2PSA 模块源码与结构
class C2PSA(nn.Module):
def __init__(self, c1, c2, n=1, e=0.5):
super().__init__()
assert c1 == c2
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n)))
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = self.m(b)
return self.cv2(torch.cat((a, b), 1))
代码位置:ultralytics/nn/modules/block.py:1002-1041
从源代码可看出,该模块可接收的参数共4个,分别为输入通道数(c1)、输出通道数(c2)、模块数量(n)、扩展系数(e)。其中,c1、c2为必选参数,缺少这两个参数将会报错,其他均设定有默认值(n默认1,e默认0.5)。
结构图解(逻辑流程)
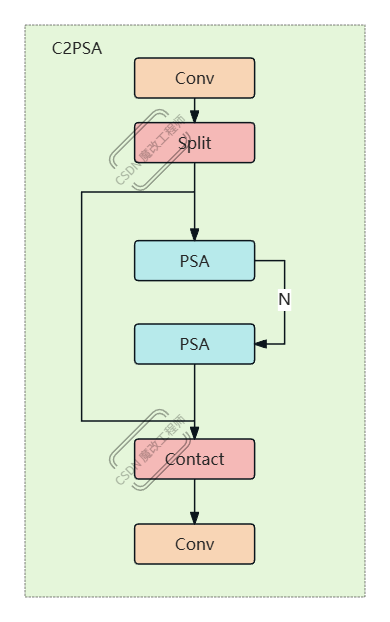
输入 x (c1)
↓ cv1 1×1 → 分成 a( c ) 与 b( c )
↓ a 直接保留
↓ b 经过 n 个 PSABlock 堆叠
↓ concat(a, b) → 通道 2c
↓ cv2 1×1 → 输出 (c1=c2)
关键点
c = int(c1 * e):隐藏通道;默认 e=0.5,将通道减半。cv1将输入通道压缩为 2c,并均分为 a、b。m为 n 个 PSABlock 串联。cv2将拼接后的 2c 还原到 c1(=c2)。
PSABlock 源码与结构
class PSABlock(nn.Module):
def __init__(self, c, attn_ratio=0.5, num_heads=4, shortcut=True) -> None:
super().__init__()
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads)
self.ffn = nn.Sequential(Conv(c, c * 2, 1), Conv(c * 2, c, 1, act=False))
self.add = shortcut
def forward(self, x):
x = x + self.attn(x) if self.add else self.attn(x)
x = x + self.ffn(x) if self.add else self.ffn(x)
return x
结构要点
- Attention:卷积版多头自注意力(区别于常规自注意力,采用卷积结构实现,见下一节),用于计算不同位置特征之间的关系。
- FFN(前馈网络):1×1 卷积升维到 2c,再 1×1 还原到 c,第二个卷积无激活,用于进一步处理经注意力机制计算后的特征。
- 残差:
shortcut=True时,两处残差(attn 后、ffn 后)均加回输入。
Attention 源码与结构
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim**-0.5
nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False) # 无激活
self.proj = Conv(dim, dim, 1, act=False) # 无激活
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False) # 深度可分离,位置编码
def forward(self, x):
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim * 2 + self.head_dim, N).split(
[self.key_dim, self.key_dim, self.head_dim], dim=2
)
attn = (q.transpose(-2, -1) @ k) * self.scale # (B, heads, N, N)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) # 聚合
x = x + self.pe(v.reshape(B, C, H, W)) # 位置编码
x = self.proj(x)
return x
要点
- PSABlock 内部的 Attention 模块负责计算查询(Query)、键(Key)和值(Value),并通过缩放点积注意力机制(Scaled Dot-Product Attention)来生成注意力权重。
- QKV 由 1×1 卷积一次性生成;无激活。
head_dim = dim // num_heads,key_dim = head_dim * attn_ratio。scale = key_dim ** -0.5,标准缩放点积注意力。pe用 3×3 深度可分离卷积(无激活)注入位置信息。proj无激活,保持线性变换。
参数解析与模型配置
模块参数
c1, c2:输入/输出通道,C2PSA 约束c1 == c2。n:PSABlock 堆叠数,默认 1。e:通道缩放,默认 0.5(隐藏通道c=int(c1*e))。- PSABlock 内部:
attn_ratio=0.5,num_heads = c // 64。
配置文件(YOLO11n 示例)
ultralytics/cfg/models/11/yolo11.yaml:
[-1, 2, C2PSA, [1024]] # layer 10 in backbone
在backbone中,最后一层使用了该模块,上述配置的含义为:
- -1: C2PSA模块的输入来自前一层的输出
- 2: 表示C2PSA模块中需要使用2个PSA模块
- C2PSA: 模块名称(搭建该模块的类)
- 1024: C2PSA模块输出的通道数,即该模块处理后生成1024种不同维度的特征信息
这行配置经过parse_model方法解析后,会得到对应的C2PSA参数如下所示: c1=256, c2=256, n=2, e=0.5
- c1/c2:输入/输出通道数
- n:PSA个数
- e:中间层的通道缩放因子
注意缩放
- depth_multiple = 0.50,width_multiple = 0.25(yolo11n)。
- parse_model 中:
n会先乘 depth_multiple 再四舍五入 ≥1;c2会乘 width_multiple 并 make_divisible。 - 以 yolo11n 为例:
- 输入通道 c1 = 256(上一层输出,已按 width 缩放)
- 配置 c2=1024 经 width=0.25 → 256,make_divisible 8 对齐
- depth=0.5, n=2 → 实际 n=1(
max(round(2*0.5),1)=1) - e 默认 0.5 →
c = 128,num_heads = 128 // 64 = 2
不同规模的实际参数(含 max_channels 约束)
- yolo11n(w=0.25, d=0.5, max=1024):c1=c2=256,n=1
- yolo11s(w=0.5, d=0.5, max=1024):c1=c2=512,n=1
- yolo11m(w=1.0, d=0.5, max=512):c1=c2=512,n=1 ← 被 max_channels=512 限制
- yolo11l(w=1.0, d=1.0, max=512):c1=c2=512,n=2 ← 被 max_channels=512 限制
- yolo11x(w=1.5, d=1.0, max=512):c1=c2=768,n=2 ← 先取 min(1024,512)=512,再乘 width=1.5
前向维度示例(yolo11n,输入 640×640)
请读者查看配置文件,当前向传播到达C2PSA模块时候,输入通道数为256(缩放后),特征图尺寸为(网络的输入规范为,经过了5层s=2的Conv模块,每一层都会将特征图缩小2倍)。同时需要注意除了s=2的Conv模块,其他模块都不会影响特征图的分辨率。
- 输入到 C2PSA 前的特征图:通道 256,分辨率 20×20(5 次 stride=2 下采样)。
- C2PSA 内:
- cv1 输出 2c=256 → 分成 128/128 两支
- b 支过 1 个 PSABlock(n=1)
- 拼接后 256,cv2 还原到 256,分辨率保持 20×20(所有卷积 stride=1,PSA 不改尺度)。
常见问题解答
Q1: n=2 为什么实际只用 1 个 PSABlock(yolo11n/s)?
A: parse_model 会用 depth_multiple(0.5)缩放 n:max(round(2*0.5),1)=1。在 m/l/x(depth=1.0)才保持 2 个。
Q2: 通道为什么不是配置里的 1024?
A: 宽度缩放 width_multiple=0.25(yolo11n),c2=make_divisible(1024*0.25, 8)=256。实际 c1=c2=256。
Q3: Attention 的头数怎么算?
A: num_heads = c // 64,c 为 int(c1*e)。yolo11n:c1=256,e=0.5 → c=128 → heads=2。
Q4: C2PSA 会改变分辨率吗?
A: 不会。所有卷积 stride=1,PSABlock 仅做注意力/FFN,无下采样。分辨率与输入一致。
Q5: 为什么先 split 再 concat?
A: 与 CSP 思路相同,一支保留/线性通路,一支做重加工(PSA),最后融合,兼顾梯度与表达。
总结
- C2PSA 通过“分流-PSA-融合”在不改分辨率的前提下增强位置敏感特征,其引入的位置敏感注意力机制解决了传统CNN对不同位置特征“一视同仁”的问题,可动态调整特征权重以捕捉全局和局部信息。
- depth_multiple 会缩放重复次数 n,width_multiple 会缩放通道 c1/c2,需结合具体 scale 解读。
- PSABlock = Attention(卷积版多头自注意力 + 位置编码)+ FFN + 残差,其中Attention模块通过卷积结构实现自注意力计算,区别于常规自注意力机制。
- 适用场景:位置信息敏感、需强化全局-局部依赖的骨干高层特征。
