# MySQL 索引优化-补充总结
## 一、索引下推(Index Condition Pushdown,ICP)
### 问题引入
```sql
EXPLAIN SELECT * FROM employees WHERE name LIKE 'LiLei%' AND age = 22 AND position = 'manager';
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position = 'manager';
```

### 原理说明
对于辅助的联合索引 `(name, age, position)`,正常情况按照最左前缀原则,`SELECT * FROM employees WHERE name LIKE 'LiLei%' AND age = 22 AND position = 'manager'` 这种情况**只会走 name 字段索引**,因为根据 name 字段过滤完,得到的索引行里的 age 和 position 是无序的,无法很好地利用索引。
**MySQL 5.6 之前的行为:**
在联合索引里匹配到名字是 `'LiLei'` 开头的索引后,拿这些索引对应的主键逐个**回表**,到主键索引上找出相应的记录,再比对 age 和 position 这两个字段的值是否符合。
**MySQL 5.6 引入索引下推优化(ICP):**
可以在索引遍历过程中,对索引中包含的所有字段先做判断,**过滤掉不符合条件的记录之后再回表**,可以有效减少回表次数。
使用了索引下推优化后,上面那个查询在联合索引里匹配到名字是 `'LiLei'` 开头的索引之后,同时还会在索引里过滤 age 和 position 这两个字段,拿着过滤完剩下的索引对应的主键 id 再回表查整行数据。

> **注意:** 索引下推会减少回表次数,对于 InnoDB 引擎的表,索引下推**只能用于二级索引**,InnoDB 的主键索引(聚簇索引)树叶子节点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
### 为什么范围查找 MySQL 没有用索引下推优化?
估计应该是 MySQL 认为范围查找过滤的结果集过大,`LIKE KK%` 在绝大多数情况下,过滤后的结果集比较小,所以 MySQL 选择给 `LIKE KK%` 用了索引下推优化。当然这也不是绝对的,有时 `LIKE KK%` 也不一定就会走索引下推。
这取决于 MySQL 的索引选择 cost 算法,这要自己看 MySQL 的底层源码实现。
## 二、Trace 工具分析优化器决策
### 开启 Trace
```sql
SET SESSION optimizer_trace = "enabled=on", end_markers_in_json = on;
SELECT * FROM employees WHERE name > 'a' ORDER BY position;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
```
### Trace 输出示例
```json
{
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `employees`.`id` AS `id`,`employees`.`name` AS `name`,`employees`.`age` AS `age`,`employees`.`position` AS `position`,`employees`.`hire_time` AS `hire_time` from `employees` where (`employees`.`name` > 'a') order by `employees`.`position`"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`employees`.`name` > 'a')",
"steps": [
{ "transformation": "equality_propagation", "resulting_condition": "(`employees`.`name` > 'a')" },
{ "transformation": "constant_propagation", "resulting_condition": "(`employees`.`name` > 'a')" },
{ "transformation": "trivial_condition_removal", "resulting_condition": "(`employees`.`name` > 'a')" }
]
}
},
{
"table_dependencies": [
{
"table": "`employees`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": []
}
]
},
{
"rows_estimation": [
{
"table": "`employees`",
"range_analysis": {
"table_scan": {
"rows": 100185,
"cost": 10108.9
} ,
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "idx_name_age_position",
"usable": true,
"key_parts": ["name", "age", "position", "id"]
}
] ,
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_name_age_position",
"ranges": ["'a' < name"],
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 50092,
"cost": 17532.5,
"chosen": false,
"cause": "cost"
}
]
}
}
}
]
},
{
"considered_execution_plans": [
{
"table": "`employees`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 100185,
"access_type": "scan",
"resulting_rows": 100185,
"cost": 10106.8,
"chosen": true,
"use_tmp_table": true
}
]
}
}
]
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": [
{
"sorting_table": "employees",
"filesort_summary": {
"memory_available": 262144,
"sort_algorithm": "std::stable_sort",
"sort_mode": "<fixed_sort_key, packed_additional_fields>"
}
}
]
}
}
]
}
```
> **结论:** 全表扫描的成本(10106.8)低于索引扫描(17532.5),所以 MySQL 最终选择全表扫描。
## 三、ORDER BY 与 GROUP BY 优化
### 优化总结
1. **MySQL 支持两种方式的排序:** `filesort` 和 `index`。
- `Using index`:MySQL 扫描索引本身完成排序,**效率高**
- `filesort`:文件排序,**效率低**
2. **`ORDER BY` 满足以下两种情况会使用 `Using index`:**
- `ORDER BY` 语句使用索引最左前列
- 使用 `WHERE` 子句与 `ORDER BY` 子句条件列组合满足索引最左前列
3. 尽量在索引列上完成排序,遵循索引建立时的**最左前缀法则**。
4. 如果 `ORDER BY` 的条件不在索引列上,就会产生 `Using filesort`。
5. 能用覆盖索引尽量用覆盖索引。
6. `GROUP BY` 与 `ORDER BY` 很类似,其实质是**先排序后分组**,遵照索引创建顺序的最左前缀法则。
- 对于 `GROUP BY` 的优化,如果不需要排序的可以加上 `ORDER BY NULL` 禁止排序
- 注意:`WHERE` 高于 `HAVING`,能写在 `WHERE` 中的限定条件就不要去 `HAVING` 限定
## 四、Using filesort 文件排序原理详解
### 两种排序方式
#### 单路排序
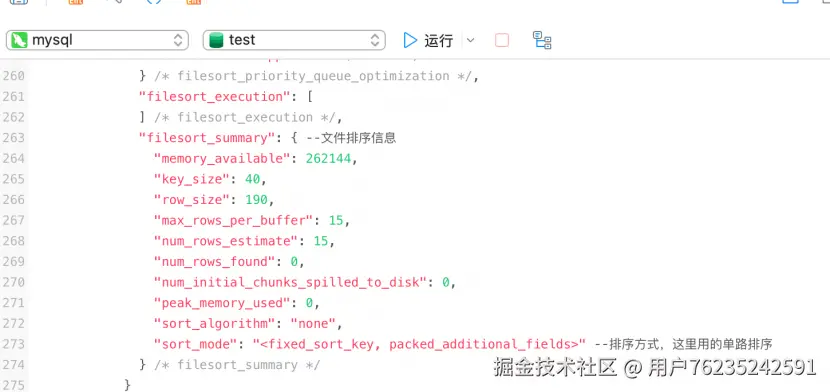
一次性取出满足条件行的所有字段,然后在 `sort_buffer` 中进行排序。
用 trace 工具可以看到 `sort_mode` 信息里显示:
- `<sort_key, additional_fields>`
- 或 `<sort_key, packed_additional_fields>`
**单路排序详细过程(以 `name = 'zhuge'` 为例):**
1. 从索引 name 找到第一个满足 `name = 'zhuge'` 条件的主键 id
2. 根据主键 id 取出整行,取出**所有字段的值**,存入 `sort_buffer` 中
3. 从索引 name 找到下一个满足 `name = 'zhuge'` 条件的主键 id
4. 重复步骤 2、3 直到不满足 `name = 'zhuge'`
5. 对 `sort_buffer` 中的数据按照字段 position 进行排序
6. 返回结果给客户端
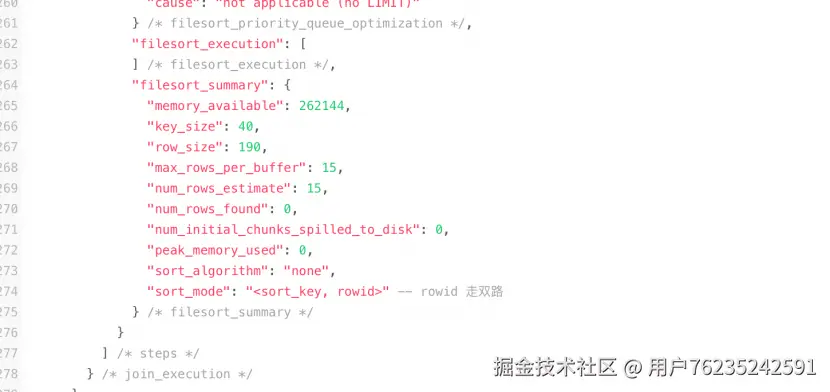
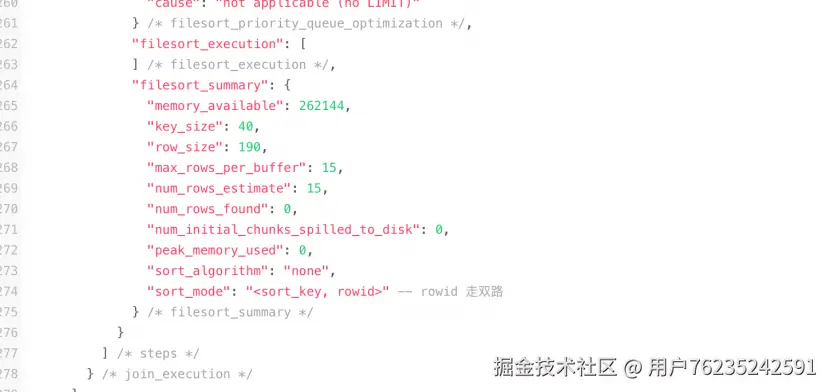
#### 双路排序(回表排序模式)
首先根据相应的条件取出相应的**排序字段和行 ID**,然后在 `sort_buffer` 中进行排序,排序完后需要再次取回其它需要的字段。
用 trace 工具可以看到 `sort_mode` 信息里显示:`<sort_key, rowid>`
**双路排序详细过程(以 `name = 'zhuge'` 为例):**
1. 从索引 name 找到第一个满足 `name = 'zhuge'` 的主键 id
2. 根据主键 id 取出整行,把排序字段 position 和主键 id **这两个字段**放到 `sort_buffer` 中
3. 从索引 name 取下一个满足 `name = 'zhuge'` 记录的主键 id
4. 重复步骤 3、4 直到不满足 `name = 'zhuge'`
5. 对 `sort_buffer` 中的字段 position 和主键 id 按照字段 position 进行排序
6. 遍历排序好的 id 和字段 position,**按照 id 的值回到原表**中取出所有字段的值返回给客户端
### MySQL 如何选择排序方式?
MySQL 通过比较系统变量 `max_length_for_sort_data`(默认 1024 字节)的大小和需要查询的字段总大小来判断:
| 条件 | 选择方式 |
|
| 字段总长度 < `max_length_for_sort_data` | 单路排序 |
| 字段总长度 > `max_length_for_sort_data` | 双路排序 |
其实就还是**时间换空间,空间换时间**的问题:放入内存的结果不超过特定空间,就用单路更快;占用内存太大,就用双路,再去用主键索引查一次。
> **注意:** 如果全部使用 `sort_buffer` 内存排序一般情况下效率会高于磁盘文件排序,但不能因为这个就随便增大 `sort_buffer`(默认 1M),MySQL 很多参数设置都是做过优化的,不要轻易调整。

## 五、索引设计原则
### 1. 代码先行,索引后上
一般应该等到主体业务功能开发完毕,把涉及到该表相关 SQL 都要拿出来分析之后再建立索引。
### 2. 联合索引尽量覆盖条件
比如可以设计一个或者两三个联合索引(**尽量少建单值索引**),让每一个联合索引都尽量去包含 SQL 语句里的 `WHERE`、`ORDER BY`、`GROUP BY` 的字段,还要确保这些联合索引的字段顺序尽量满足 SQL 查询的**最左前缀原则**。
### 3. 不要在小基数字段上建立索引
索引基数是指这个字段在表里总共有多少个不同的值,比如一张表总共 100 万行记录,其中有个性别字段,其值不是男就是女,那么该字段的基数就是 2。
如果对这种小基数字段建立索引的话,还不如全表扫描了,因为索引树里就包含男和女两种值,根本没法进行快速的二分查找。
> **建议:** 一般建立索引,尽量使用那些**基数比较大**的字段,才能发挥出 B+ 树快速二分查找的优势。
### 4. 长字符串可以采用前缀索引
尽量对字段类型较小的列设计索引(如 `TINYINT` 之类的),因为字段类型较小的话,占用磁盘空间也会比较小,搜索性能也会比较好。
对于 `VARCHAR(255)` 这种大字段,可以稍微优化下,比如针对这个字段的前 20 个字符建立索引:
```sql
KEY index(name(20), age, position)
```
此时在 `WHERE` 条件里搜索时,会先到索引树里根据 name 字段的前 20 个字符去搜索,定位到之后再回到聚簇索引提取出来完整的 name 字段值进行比对。
> **注意:** 假如要 `ORDER BY name`,那么 name 在索引树里仅仅包含了前 20 个字符,所以这个排序是**没法用上索引的**,`GROUP BY` 也是同理。
### 5. WHERE 与 ORDER BY 冲突时优先 WHERE
在 `WHERE` 和 `ORDER BY` 出现索引设计冲突时,一般让 `WHERE` 条件去使用索引来快速筛选出来一部分指定的数据,接着再进行排序。
因为大多数情况基于索引进行 `WHERE` 筛选往往可以最快速度筛选出少部分数据,然后做排序的成本可能会小很多。
### 6. 基于慢 SQL 查询做优化
可以根据监控后台的一些慢 SQL,针对这些慢 SQL 查询做特定的索引优化。
> 一般在公司,DBA 都会定期去看慢 SQL 日志,然后告诉相关开发去优化。
### 7. 范围查询字段放在索引最后
- 范围查询的字段,尽量把它放在索引最后,如果放到中间,范围查出来的数据就可能不再是有序的,后面的索引就不会再命中。
- 利用联合索引(**读多写少**可以多建复合索引,**读少写多**不建议建太多复合索引,会影响写的性能),满足 80% 的公司业务,就是合适的索引。
## 总结
对于优化,总结一句话就是:
> **合理设计索引,根据索引命中原理,调整业务 SQL 让它命中索引。**



