

在今天举办的 Deploy 大会上,DigitalOcean 正式宣布 DeepSeek V3.2、MiniMax-M2.5 和 Qwen 3.5 397B 在 DigitalOcean Serverless Inference (AI 推理云平台)上全面可用。DigitalOcean 推理云上的 DeepSeek V3.2 和 Qwen 3.5 397B ,在参与 Artificial Analysis 测试 的所有云中实现了 第一名 的输出速度。具体到 DeepSeek V3.2,这意味着在 10,000 个输入 token 的情况下,输出速度达到 230 token/秒,首 token 时间(TTFT)低于 1 秒。
这篇文章将讲述 DigitalOcean 是如何做到这一点的:GPU 层面的工作、服务栈的调优,以及在此过程中做出的具体技术取舍。
除了开源大模型,DigitalOcean Serverless Inference 还提供 Claude Opus 4.7、GPT 5.4、GPT Image 2 等多种商用大模型,新注册用户可直接联系卓普云(aidroplet.com)申请使用权限。
为什么快速推理很重要
AI 开发的重心已经从模型训练根本性地转向了推理效率。这一转变是由智能体工作负载、Copilot 以及实时系统(这些构成了下一代 AI 应用的核心)的普及所驱动的。对于这些应用而言,速度不再仅仅是一个性能指标,它是决定一个产品是引人入胜还是被用户弃用的关键区别因素。具体来说,低延迟推理对于无缝的终端用户体验至关重要。对于对话式智能体、语音界面等高度交互的应用,任何超过 1 秒 TTFT 的延迟都会让用户感到卡顿。
快速推理的重要性因现代 AI 工作流的复杂性而进一步放大。例如,一个智能体任务往往涉及数十次顺序模型调用,即使每次调用微小的每输出 token 时间(TPOT)延迟,累积起来也会变成用户可见的几秒钟延迟。快速推理还能为企业提供可靠的性能和更低的成本。在此领域的优化(例如 DigitalOcean 推理引擎所提供的)使企业能够获得卓越的 token 经济性、持续的高吞吐量和可预测的低延迟,这对于以可靠且经济的方式扩展其 AI 原生应用至关重要。
在 Artificial Analysis 速度基准测试中领先
DigitalOcean 今天发布的基准测试结果反映了这一点。在 10K 输入 token 的 DeepSeek V3.2 上,DigitalOcean 实现了:
- 输出速度:230 token/秒(AWS Bedrock 为 59 token/秒,DigitalOcean 是其 3.9 倍)
- TTFT:0.96 秒(在测试的 12 家提供商中,仅 Google Vertex 比 DigitalOcean 更快)
- 延迟与输出速度之间的均衡性能:在 Artificial Analysis 的延迟 vs. 输出速度象限图中,DigitalOcean 是仅有的三家位列最优象限的提供商之一。
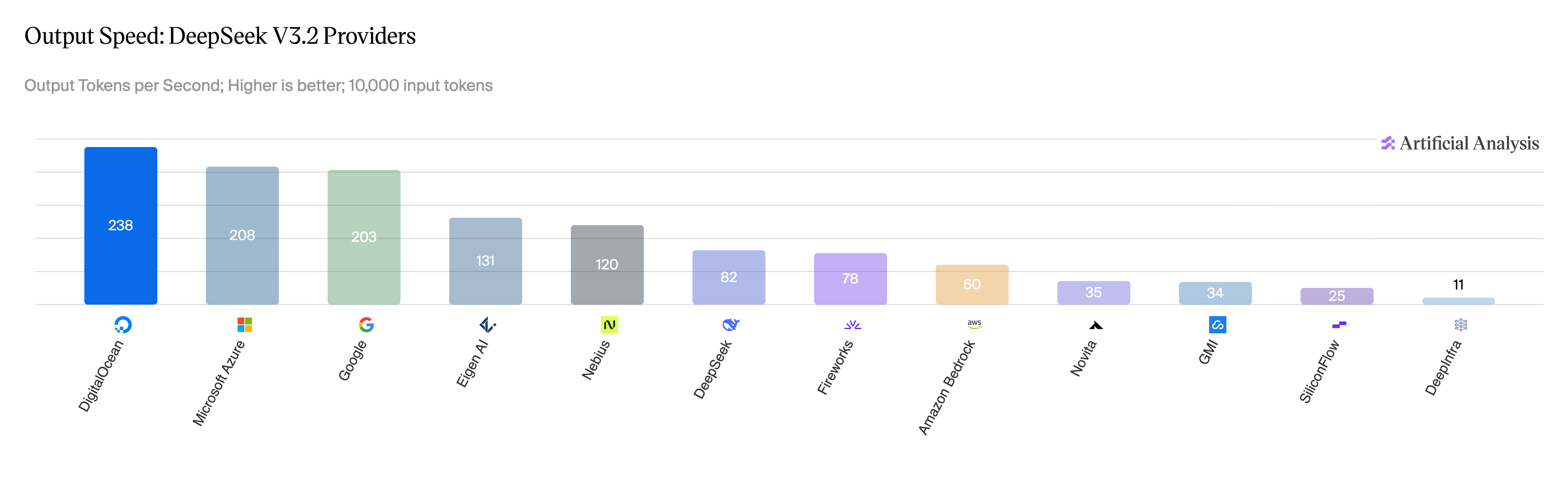 图 1:DeepSeek V3.2 非推理版,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
图 1:DeepSeek V3.2 非推理版,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
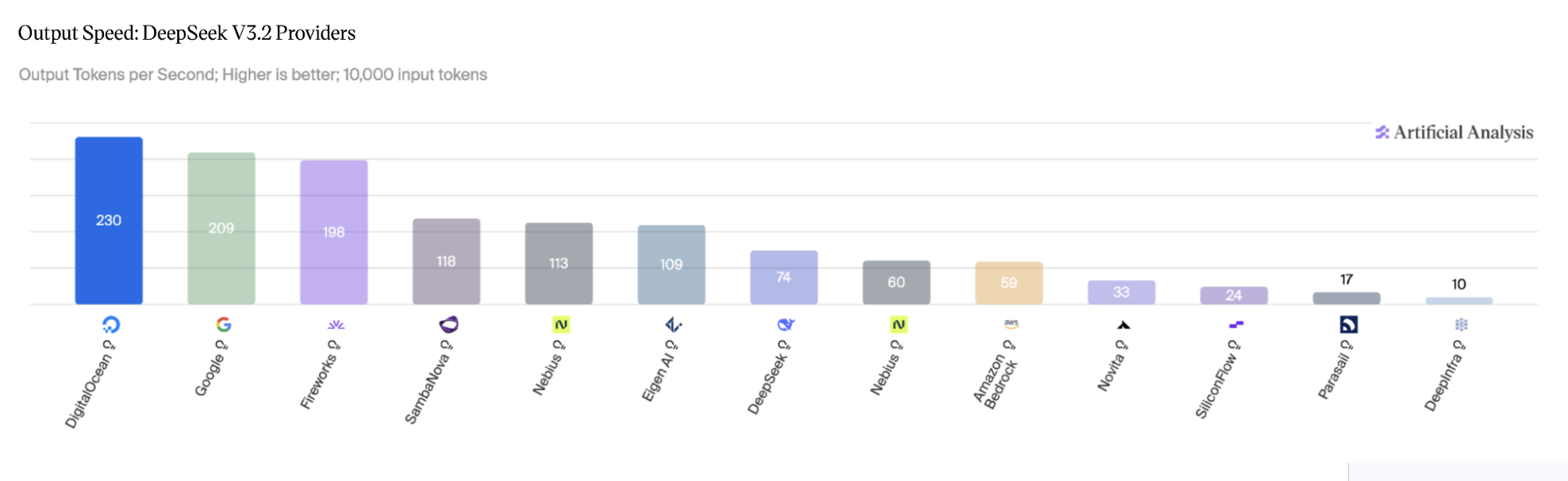 图 2:DeepSeek V3.2 推理版,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
图 2:DeepSeek V3.2 推理版,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
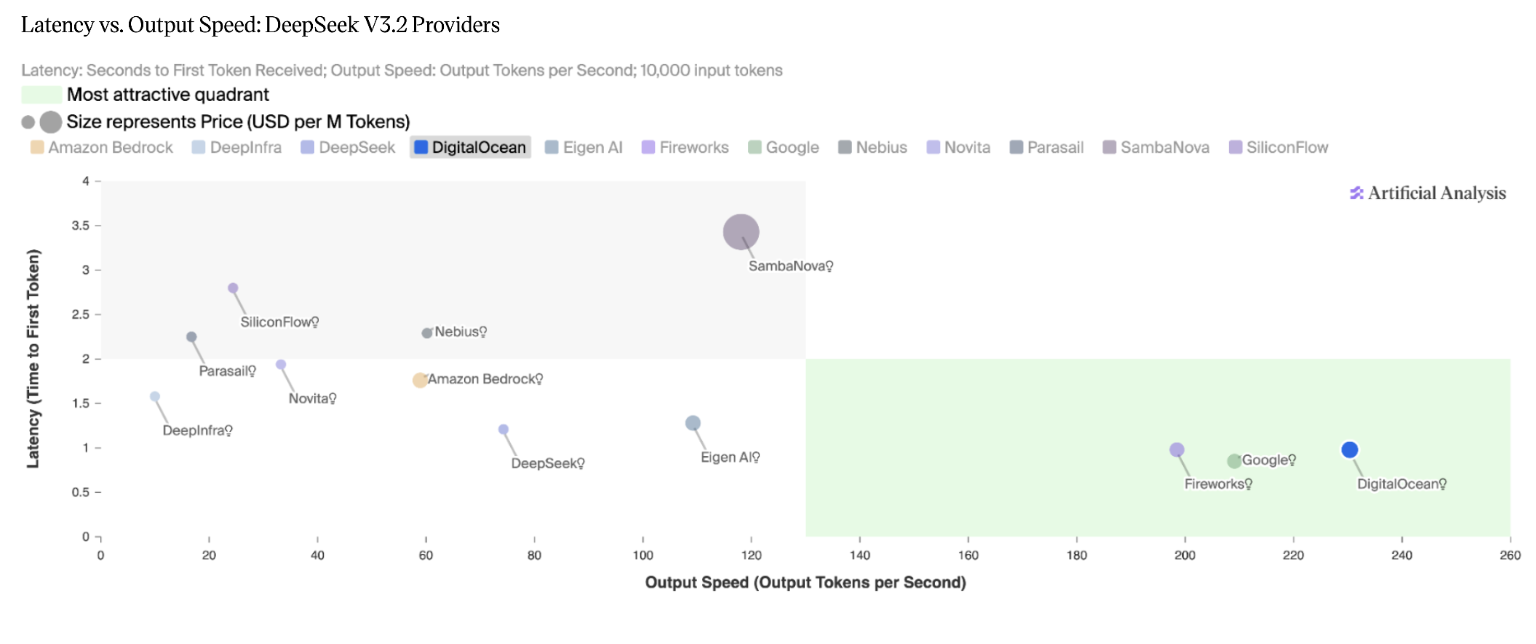 图 3:DeepSeek V3.2 推理版,延迟 vs. 输出速度象限图。来源:Artificial Analysis,2026 年 4 月。
图 3:DeepSeek V3.2 推理版,延迟 vs. 输出速度象限图。来源:Artificial Analysis,2026 年 4 月。
MiniMax-M2.5 和 Qwen3.5 397B 的性能数据类似:
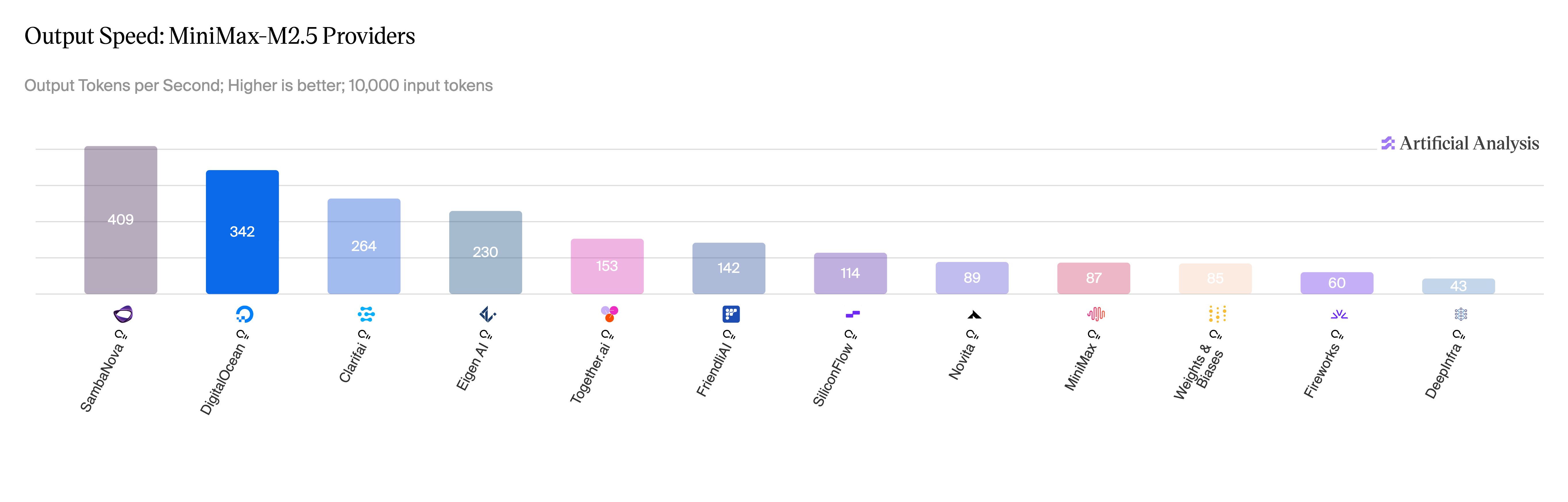 图 4:MiniMax-M2.5,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
图 4:MiniMax-M2.5,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
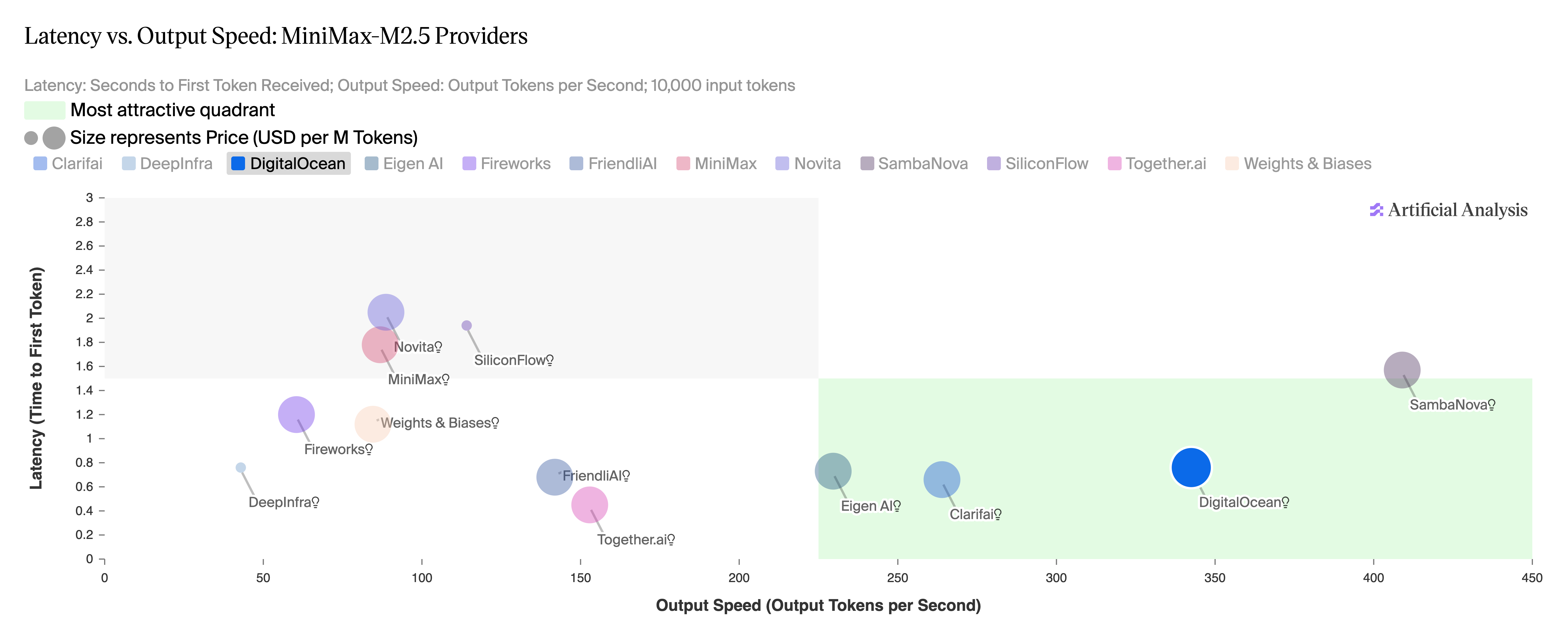 图 5:MiniMax-M2.5,各提供商延迟 vs. 输出速度对比。来源:Artificial Analysis,2026 年 4 月。
图 5:MiniMax-M2.5,各提供商延迟 vs. 输出速度对比。来源:Artificial Analysis,2026 年 4 月。
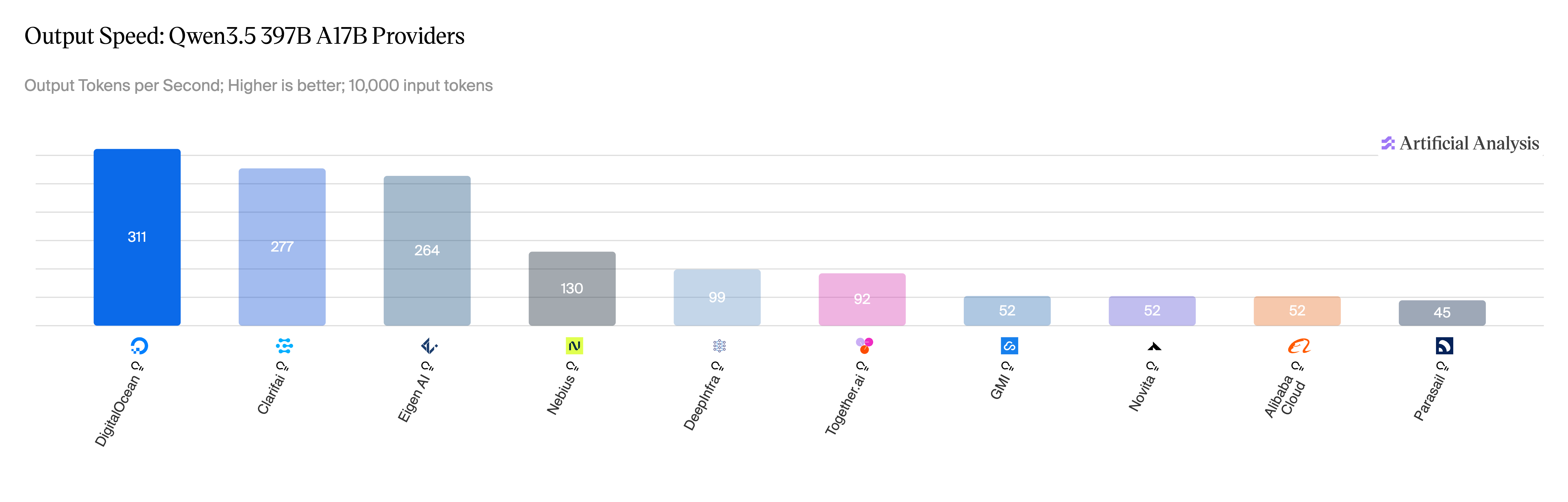 图 6:Qwen 3.5 397B,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
图 6:Qwen 3.5 397B,各提供商输出速度对比。来源:Artificial Analysis,2026 年 4 月。
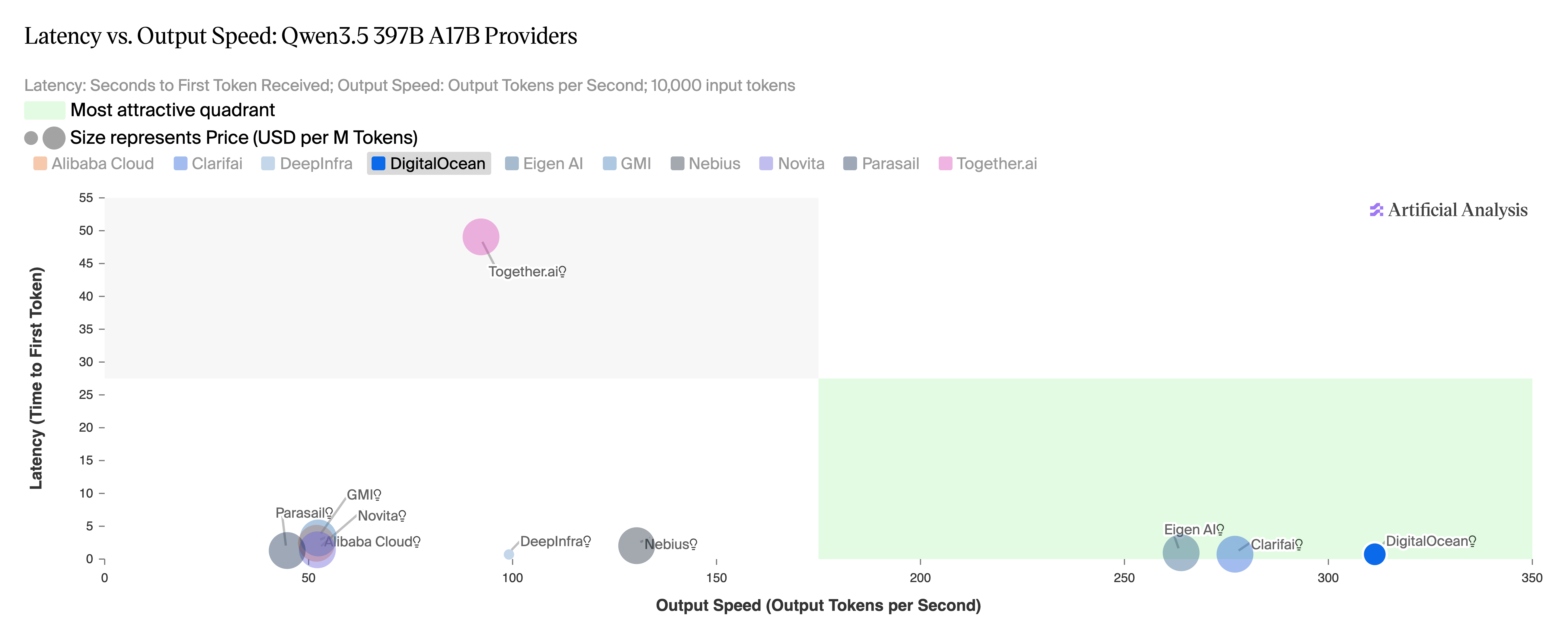 图 7:Qwen 3.5 397B,各提供商延迟 vs. 输出速度对比。来源:Artificial Analysis,2026 年 4 月。
图 7:Qwen 3.5 397B,各提供商延迟 vs. 输出速度对比。来源:Artificial Analysis,2026 年 4 月。
数字背后的工程
要达到这一性能水平,仅靠最前沿的 GPU 是不够的。在最新一代硬件上使用标准配置,往往无法在 Artificial Analysis 排行榜上登顶。为了取得这些成果,DigitalOcean 对技术栈的每一层进行了协同设计和优化:精选高端 GPU、在虚拟化 NVIDIA Blackwell Ultra GPU 上最大化 CUDA 效率、实现推测解码,以及在速度与准确性之间取得最佳平衡的位置应用量化技术。
硬件:NVIDIA Blackwell Ultra 的强大性能
DigitalOcean 性能突破的基础是 NVIDIA HGX™ B300 GPU。Blackwell Ultra 架构实现了巨大的飞跃,拥有 288GB HBM3e 容量(比 B200 增加 50%),以及 1.5 倍的 NVFP4 计算能力。这一硬件基础对于处理 DeepSeek 和 Qwen 的大规模吞吐需求至关重要。尽管在虚拟化环境中的早期部署导致性能下降了 25%,但 DigitalOcean 与 NVIDIA 的直接合作解决了这些问题,完全释放了 Blackwell 芯片的潜力。
模型量化:NVFP4 的高效性
DigitalOcean 使用了模型的 NVFP4 量化版本,这是一种专门的 4 位浮点格式,可显著减少内存占用(相比 FP8 约减少 1.8 倍)并提高推理吞吐量。这些优势由 NVIDIA Blackwell Ultra 架构独家提供,该架构具有 1.5 倍的专用 NVFP4 计算能力,从而在几乎不影响模型精度的前提下实现巨大的性能提升。有关 NVFP4 精度与原始 FP8 模型权重的对比,请参阅 DeepSeek V3.2 的模型评估。
然而,纯粹的芯片和量化只是故事的一半。要将这种硬件能力转化为世界级的推理速度,DigitalOcean 必须实现高度定制化的软件栈。
推理引擎:vLLM 的性能优化
DigitalOcean 通过一系列技术对开源 vLLM 服务框架进行了优化:
- 张量并行:DigitalOcean 使用了张量并行技术,将大型模型层分布到多个 GPU 上,这是运行超出单个 GPU 内存容量的模型所必需的技术,需要高速 GPU 互连。根据模型大小,DigitalOcean 使用 TP4 或 TP8 配置,在 4 个或 8 个 GPU 上运行推理。
- 内核融合:这项关键优化将多个运算融合到单个 GPU 内核中,从而最大限度地减少单个内核启动的开销,并减少 CPU 间隙。通过在芯片上执行这些合并后的运算,内核融合显著减少了较慢的片外内存访问,从而实现更快的处理速度。
- **可编程依赖启动(Programmatic Dependent Launch)**:DigitalOcean 使用可编程依赖启动技术,尽可能重叠内核,从而隐藏内核启动开销并减轻短运行内核的尾部效应。这使得低批量、低并发、高交互性工作负载的性能提升了约 10%。
- **推测解码与多 token 预测(MTP)**:DigitalOcean 利用最新的模型特性,如 DeepSeek 的多 token 预测,来加速 token 生成,从而改善每输出 token 时间。MTP 被用作推测解码优化的一部分,以提高生成速度。该技术使用一个较小的草稿模型(MTP 头或 EAGLE 头)来预测 token 序列,然后由较大的目标模型在单次前向传播中进行验证,从而在保持主模型输出高质量的同时显著提高吞吐量。对于 MiniMax-M2.5,DigitalOcean 使用 TorchSpec 训练了一个 EAGLE3 草稿模型——这是一个 torch 原生的在线推测解码训练框架,它同时运行 FSDP 训练和基于 vLLM 的目标推理,通过从 MiniMax-M2.5 重新生成的响应和实时的 vLLM 生成的隐藏状态中学习,来匹配基础模型的确切 token 分布。在部署时,DigitalOcean 的实验表明,减少草稿模型的张量并行度可以最小化 GPU 间通信开销,从而提升性能。对于 MiniMax-M2.5,通过在配置中设置
"draft_tensor_parallel_size": 1,每输出 token 时间(TPOT)改善了 23%。
内核融合和草稿模型训练是与 Inferact 密切合作完成的。Inferact 是领先推理服务引擎 vLLM 的原创团队,他们的专业知识对于针对特定 GPU 和模型版本优化这些复杂工作负载起到了关键作用。
真实世界的性能
这些技术已经在为客户提供大规模推理服务的生产环境中运行。Workato 使用智能体 AI 扩展其生产自动化,处理超过 1 万亿次自动化工作负载,它运行在 DigitalOcean 的推理平台上,实现了 77% 更快的首 token 时间、79% 更低的端到端延迟以及 67% 更低的推理成本。
“在 DigitalOcean 之前,DigitalOcean 没有针对多节点服务的专用解决方案,这拖慢了 DigitalOcean 的 AI 进展。DigitalOcean 让 DigitalOcean 快速启动并运行起来,通过在性能优化方面的紧密合作,帮助 DigitalOcean 加速推理性能,整体进展提高了两到三倍。”——Oscar Wu,Workato 人工智能研究科学家与技术负责人
前进之路:扩展智能
DigitalOcean 对性能的承诺不止于此。DigitalOcean 正在扩展优化模型的目录,以满足不断变化的客户需求。当 DigitalOcean 迈向推理的下一个前沿时,DigitalOcean 正在构建支持多节点服务的基础设施,具备解耦配置和 Wide Expert Parallelism 能力,以处理全球最苛刻的智能体工作负载。通过硬件与软件的协同设计,DigitalOcean 将持续为 AI 原生构建者提供规模化所需的性能。
立即在 DigitalOcean Serverless Inference 上试用 DeepSeek V3.2、MiniMax-M2.5 或 Qwen 3.5 397B 吧!
除了开源大模型,DigitalOcean Serverless Inference 还提供 Claude Opus 4.7、GPT 5.4、GPT Image 2 等多种商用大模型,新注册用户可直接联系卓普云(aidroplet.com)申请使用权限。
