

导语:
当拥有 5 倍理论性能提升的Arm SME2,撞上 SOTA 级别的PP-OCRv5模型,究竟是一拍即合,还是性能翻车?
在真实场景充分释放SME2的AI加速性能并不仅仅是调用一个API那样简单,它必然是模型结构、内存数据与底层硬件的深度协同!
今天,我们将复盘 PP-OCRv5 在 Apple M4 (Arm SME2) 上的推理加速实践,拆解如何将Arm SME2 性能彻底榨干的思路和方法。
刚才,Arm 的专家向大家展示了 SME2 极其诱人的硬件潜能。
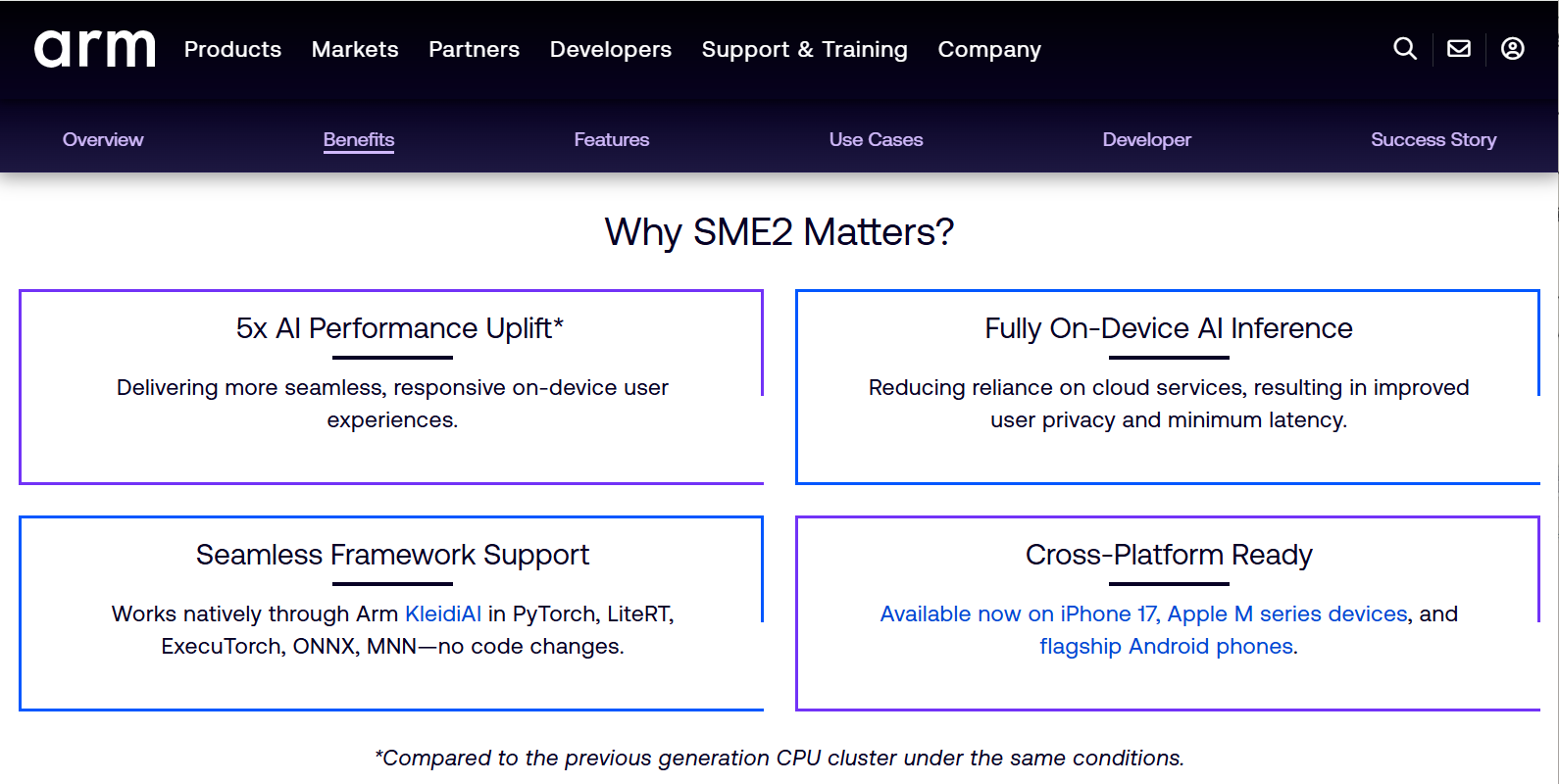
但作为每天在业务里摸爬滚打的工程师,我们必须面对一个极其骨感的现实:在真实的端侧场景里,获得极致的加速性能,往往不容易。
今天,我将以 PP-OCRv5 为例,带大家重走一遍这场涉及模型结构、内存数据与底层硬件的软硬协同实战。
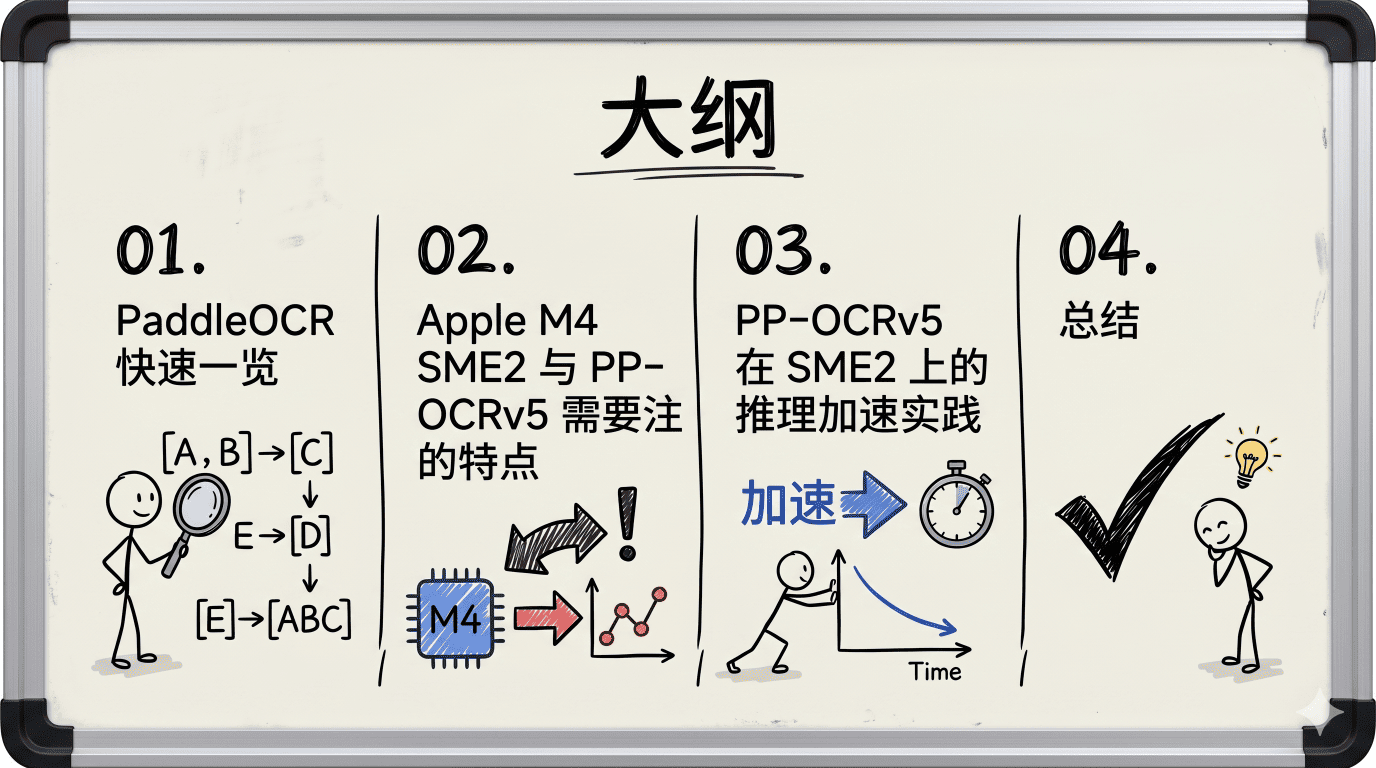
为了把这套实战方法论讲透,今天的分享将从四个维度展开:从生态愿景,到底层硬件解剖,再到极其硬核的端到端加速实战,最后沉淀为通用的端侧部署方法论。
什么是大模型时代的"机器之眼"?
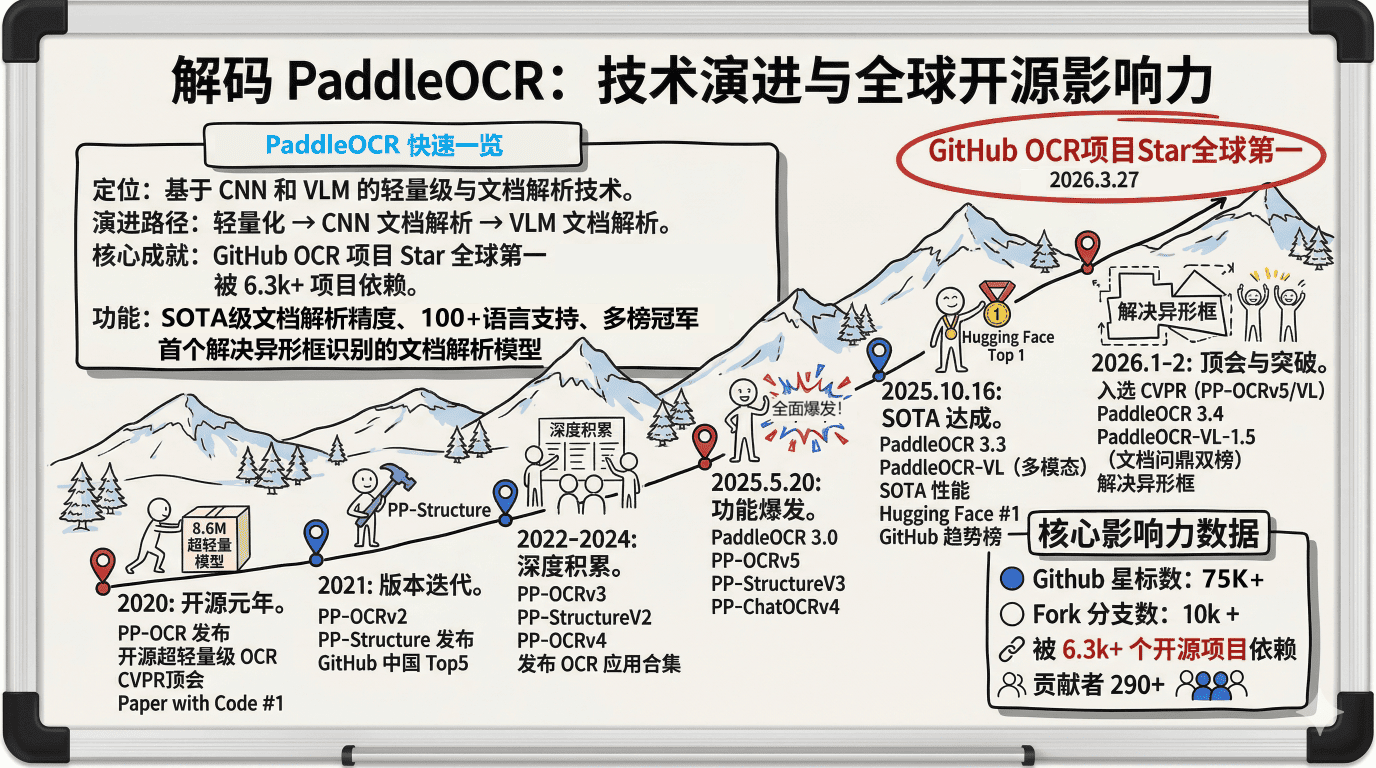
熟悉计算机视觉的开发者,对 PaddleOCR 肯定不陌生,一直以来,我们的定位非常明确,那就是为大家提供最好用的OCR和文档解析能力。
就在上个月底,2026 年 3 月 27 日,PaddleOCR 迎来了一个里程碑时刻:我们的 GitHub Star 数正式登顶全球 OCR 类项目第一!目前我们收获了超过 7.5 万的 Star,1 万多的 Fork。
PaddleOCR 不仅包含被应用广泛的PP-OCRv5模型,还包含基于VLM的,全球唯一能解决异形框识别的SOTA级别精度的文档解析模型PaddleOCR-VL,值得一提的是,PaddleOCR-VL模型在去年10月16日开源的时候,仅20小时就登顶Hugging Face Trending榜第一,引发了全球开发者的热烈关注、下载和使用。
在大模型烈火烹油的今天,为什么很多 AI 1.0 时代的传统视觉模型声量越来越小,但像 PaddleOCR 这样的模型却越来越火爆?答案其实就藏在这四个字里:Quality in, Quality out(高质量输入,高质量输出)。
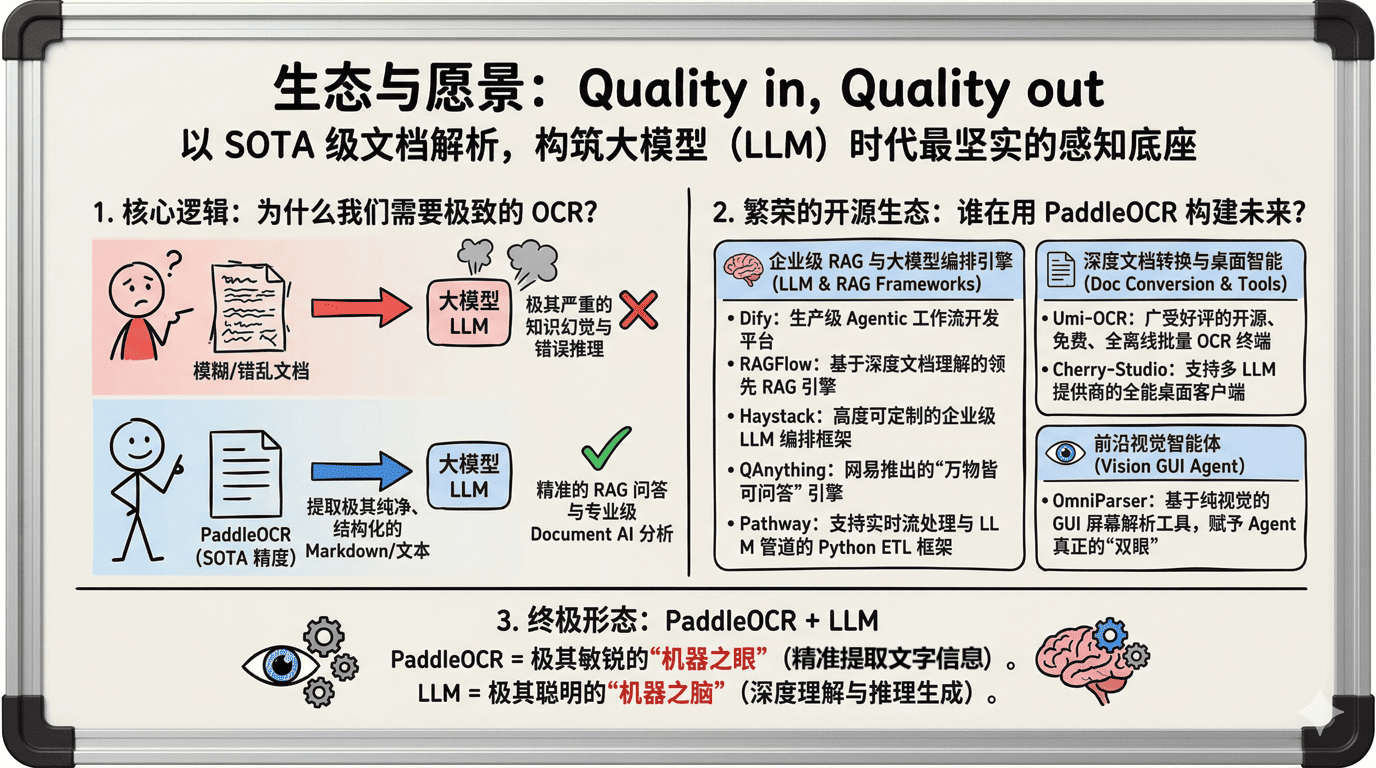
无论是做 RAG 还是 Agent 应用,如果喂给大模型的文档是版面错乱、满是乱码的,大模型必然会产生严重的"知识幻觉"。
PaddleOCR 的核心使命,就是做好大模型时代最坚实的感知底座,把复杂的研报、论文、扫描件,精准转化为极其准确、干净和结构化的 Markdown 数据,让大模型在高质量数据基础上为您推理出高质量的答案。
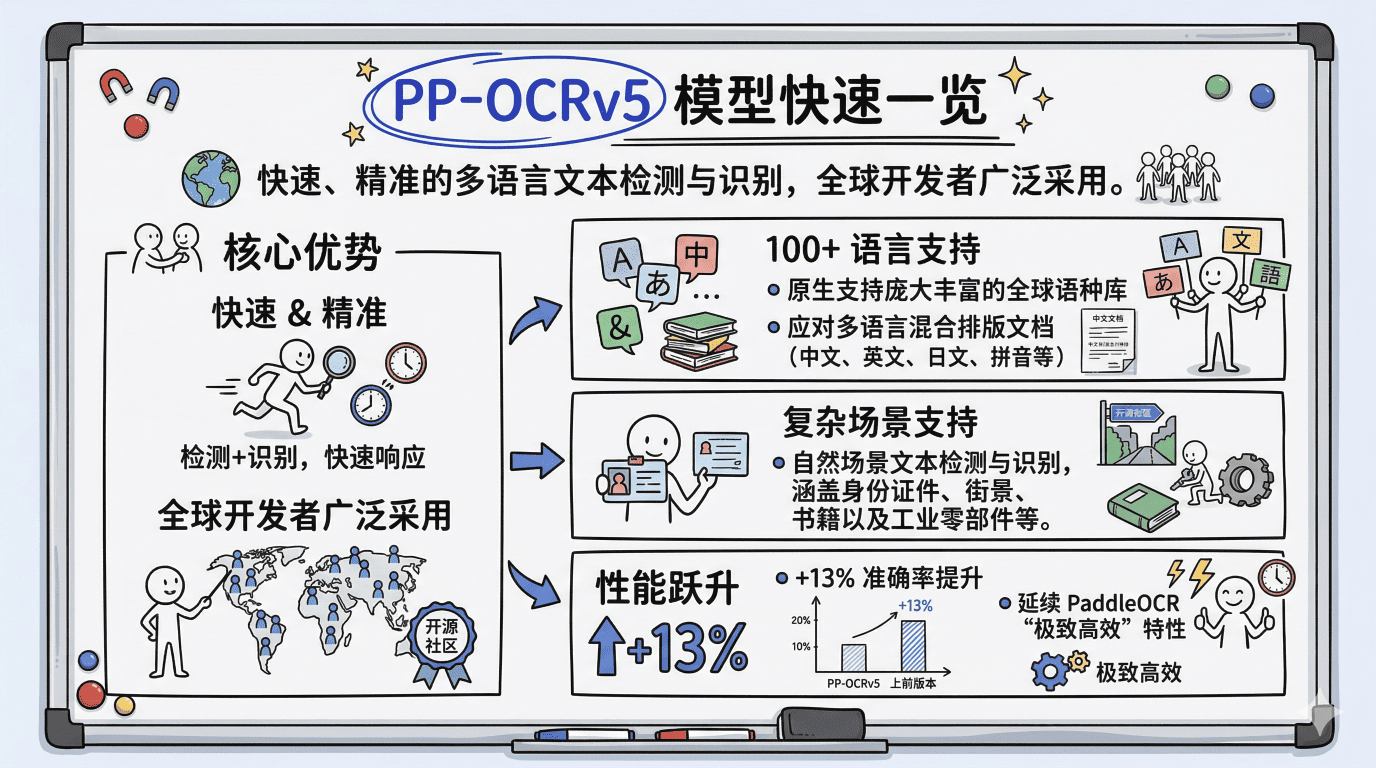
为了胜任这双"机器之眼",2025年5月20日正式发布了 PP-OCRv5,四个字来概括它的核心优势,那就是:快速+精准。
为什么大家都爱用它?主要有三个原因:
- 第一是语言覆盖广。 它原生支持了全球 100 多种语言,无论你是常规的中文文档,还是中英日韩甚至拼音混排的复杂版面,它都能准确剥离。
- 第二是场景泛化强。 从规整的身份证件、扫描文档,到光照阴影复杂的自然街景、甚至是工业零部件上的钢印字符,它都能轻松拿捏。
- 第三是绝对的性能跃升。 相比于上一代,在延续了 PaddleOCR 一贯的‘极致高效’底色的同时,我们将核心准确率硬生生又拔高了 13%!
当 M4 遇见 PP-OCRv5
算力再强,不懂底层的软硬协同,也只是纸面参数。让我们像拿着显微镜一样,解剖 Apple M4 芯片和 PP-OCRv5 模型,看看是哪些隐藏特性在左右着AI推理性能。
首先,请大家死死盯住 M4 芯片的一个核心参数:P 核的 L1 数据缓存是 128 KB。
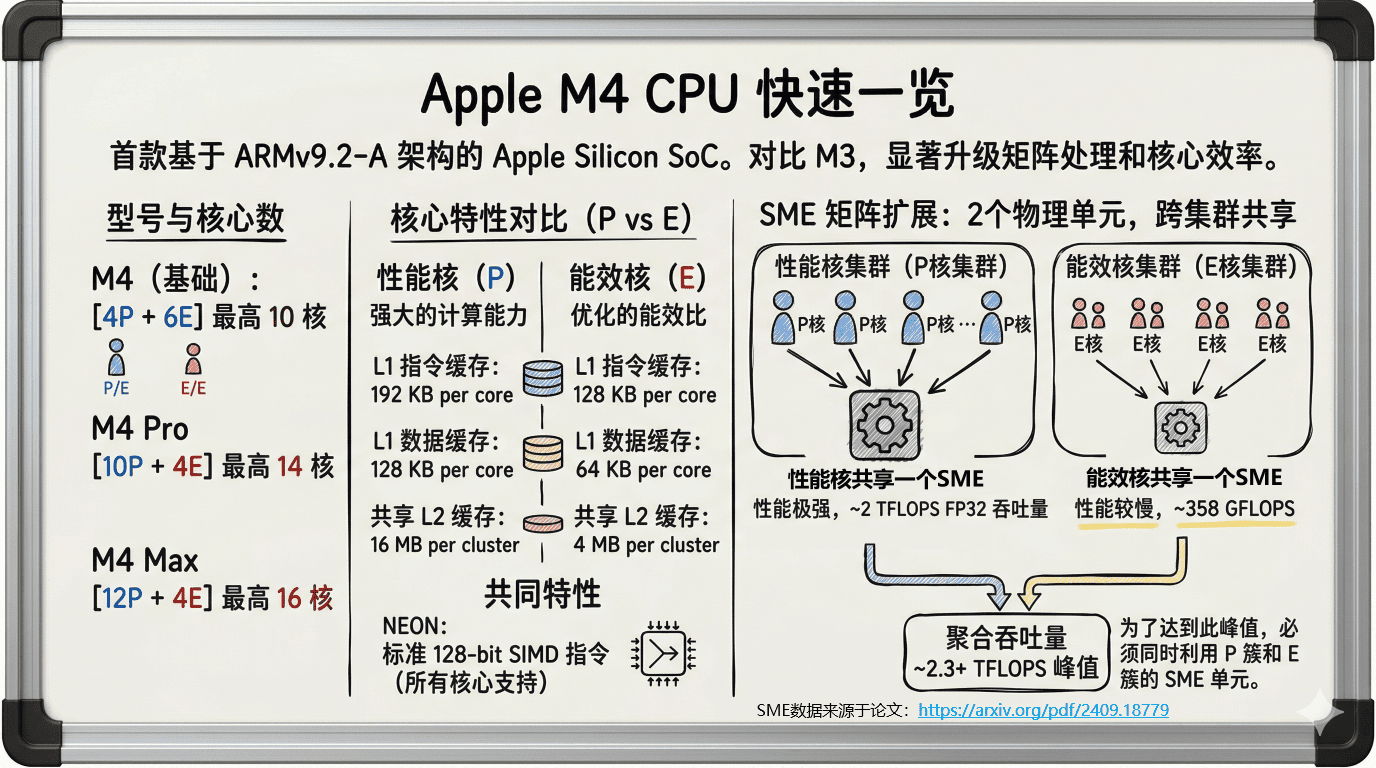
这 128KB 极其致命。虽然 M4 里的 SME 矩阵扩展单元拥有高达 2 TFLOPS 的强悍算力,但它极其“挑食”。只要你的数据搬运稍微有一点卡顿,这头算力巨兽就会因为“吃不饱”而原地空转。
底层框架是如何喂饱它的呢?这就引出了核心的 IGEMM 机制。
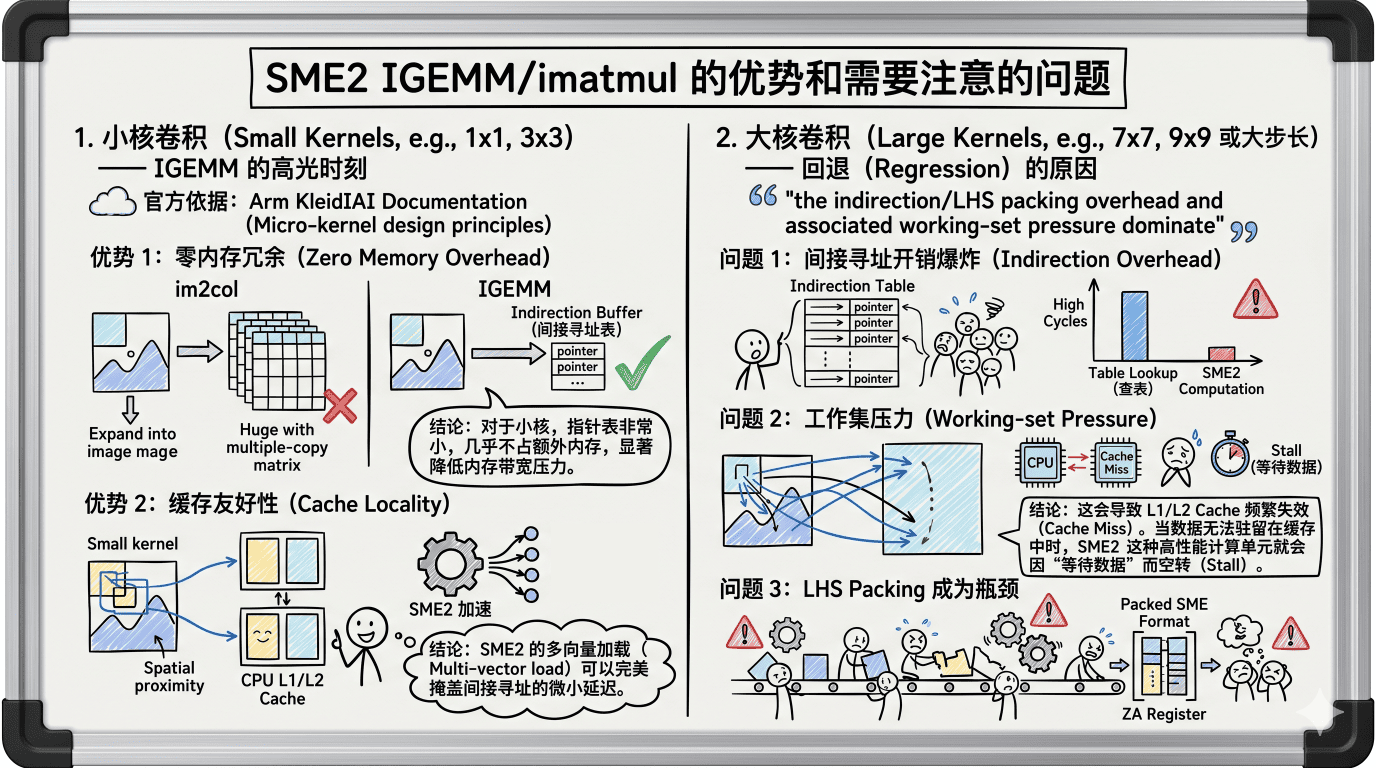
IGEMM 的本质,是**用极其微小的 CPU 间接寻址延迟,换取显著的内存空间收益,**即通过“间接指针表”即不物理复制数据的索引表方式,来规避昂贵的内存搬运。
对于
小核卷积(如 1x1, 3x3):
IGEMM 表现极佳。由于卷积核小,指针表非常精简,可以完全驻留在 L1/L2 缓存中。这种方式消除了 im2col 带来的多倍内存冗余,极大地降低了内存带宽压力。同时,由于访问地址跨度小,
CPU 硬件预取器(Prefetcher) 能精准预测数据需求,使 SME2 的矩阵算力得到满载释放。
对于大核卷积(如 7x7 及以上):IGEMM 反而可能成为性能瓶颈。随着核尺寸增大,间接寻址开销(Indirection Overhead) 剧增,巨大的指针表会产生严重的工作集压力(Working-set Pressure),挤占缓存资源。更重要的是,大跨度的内存访问模式超出了预取器的识别范围,导致 Cache Miss(缓存失效) 频繁发生。在这种情况下,SME2 强大的算力会因等待内存数据而出现空转。
记住IGEMM对于不同卷积的加速特点,接下来,我们就要详细解剖PP-OCRv5模型了。
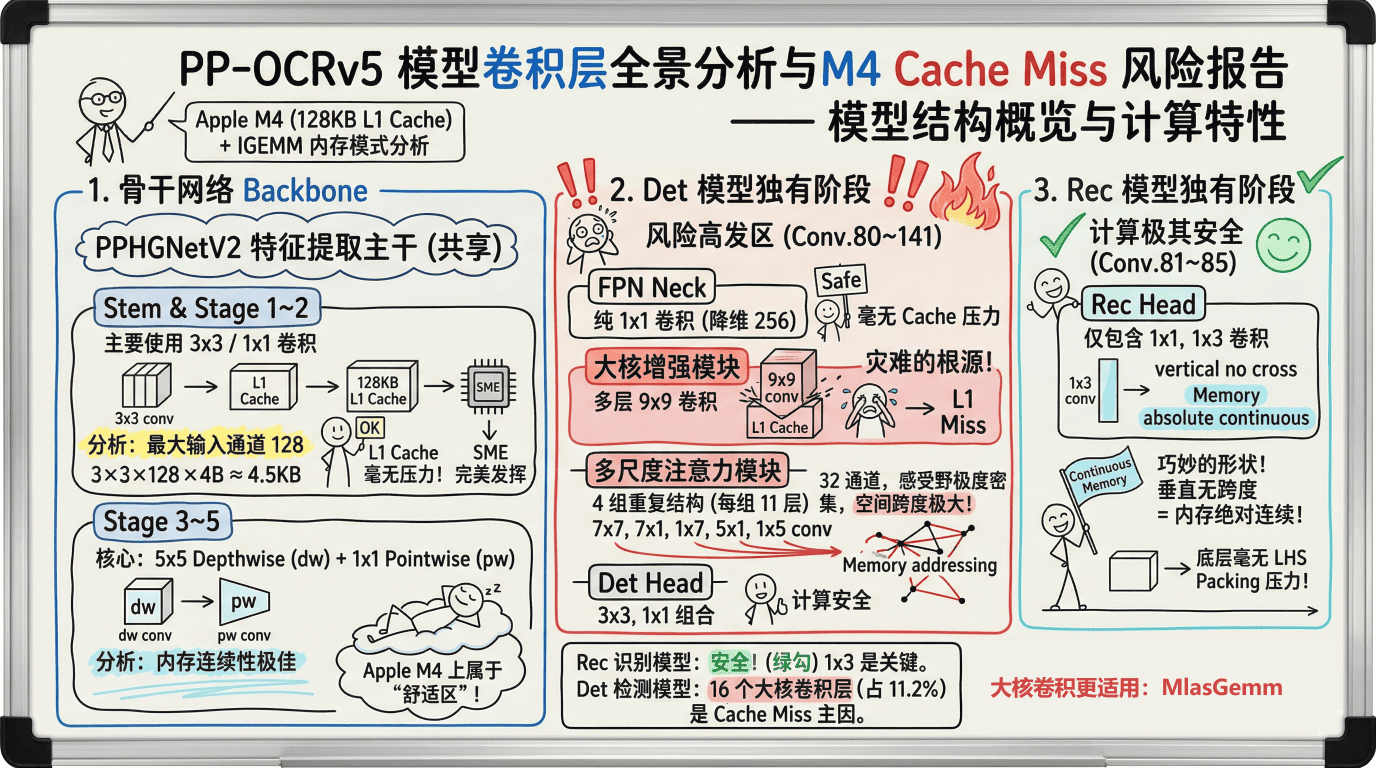
PP-OCRv5 的 Rec 和 Det 模型都采用同样的特征提取骨干网络 PPHGNetV2,由于都是小核卷积,这部分在 M4 上基于 IGEMM 跑得非常舒服。
Rec 文本识别模型,在骨干网络 PPHGNetV2之后,接入了仅仅包含了 1x1 和 1x3 卷积的Rec Head。大家注意看这个 1x3 卷积,它在图像特征上是垂直方向的,没有任何横向跨度。这意味着什么?这意味着它在底层的物理内存上,是绝对连续的!大家回想一下刚才讲的SME2 最喜欢什么?是连续内存!所以在这里,LHS Packing 几乎零压力,Rec 模型 和 IGEMM 的友好程度极佳!
Det 文本检测模型,在骨干网络 PPHGNetV2之后,为了提升复杂场景的检测精度,使用了多层 9x9 的超大核卷积,以及跨度极大的多尺度注意力模块(比如 7x7、1x7)。
当** IGEMM 试图去抓取大核卷积的数据时**,由于:
- 空间跨度太大,导致CPU 硬件预取器预测失效;
- 数据太多,Cache装不小;由此导致频繁的Cache Miss(缓存未命中)!
缓存一旦 Miss,CPU 就得去主存里慢吞吞地搬数据,此时 SME 只能干等。
Det模型的大核卷积设计会引发 IGEMM 的性能回退。
推理加速的最佳实践
找准了影响性能的根因,接下来就是见招拆招的实战破局。
Step 1:端到端 100% 精度对齐。
脱离精度谈加速,都是耍流氓。
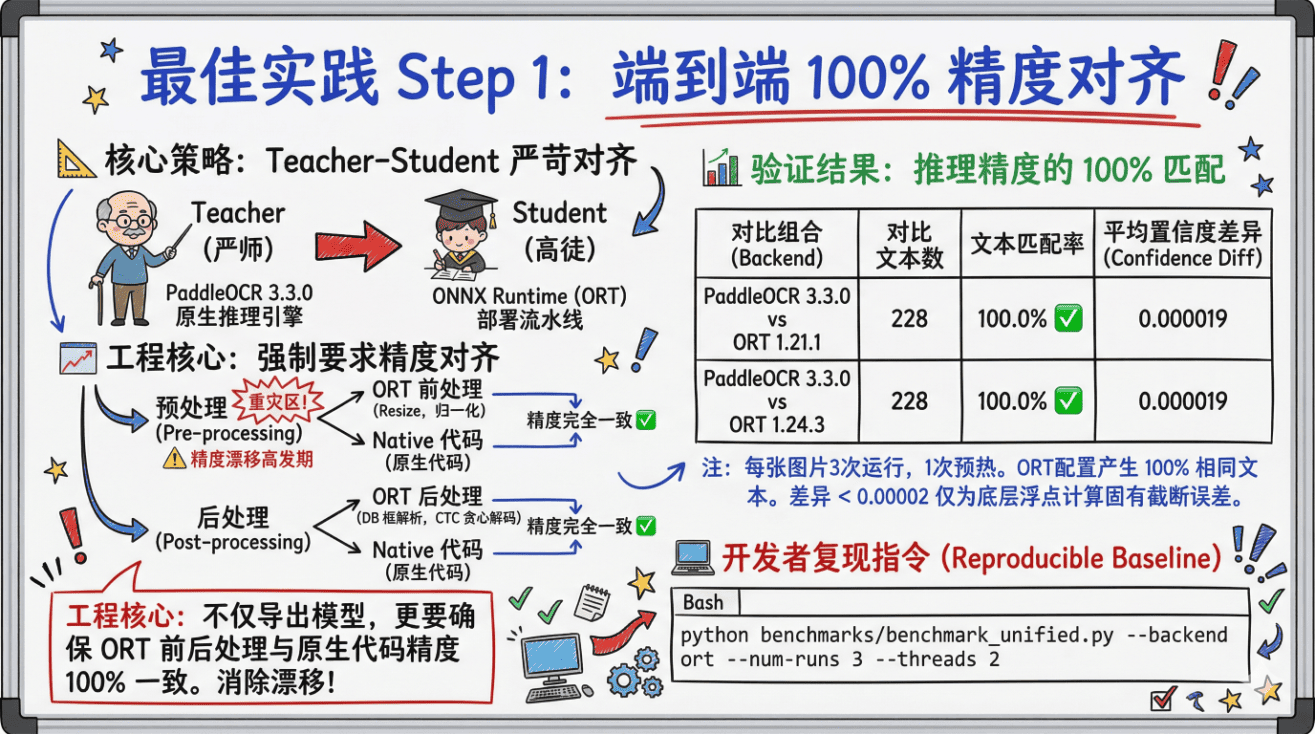
我们采用极其严苛的 Teacher-Student 策略,不仅对齐模型,更强制要求 ONNX Runtime 的前后处理与原生代码做到 100% 的像素级一致,彻底消除预处理带来的"精度漂移"。
Step 2:Rec 识别模型满血爆发!
在做性能优化时,大家需要知道,在PP-OCRv5的端到端流水线中,由于Det模型只运行一次,所以Rec模型的执行时间占大头。

根据上文分析,Rec 模型 和 IGEMM 的友好程度极佳,当使用IGEMM直接加速Rec 模型时,获得了惊人的结果:耗时从 11703ms 瞬间削减至 2647ms,单线程加速比高达惊人的 4.4 倍!
Step 3:算子重路由,暴力破局 Det 性能黑洞!
大家看左下角的账本,那个含有多个 9x9 大核卷积的 Det 模型,在最初测试时不仅没加速,反而爆出了 **4300 毫秒 **的性能回退!
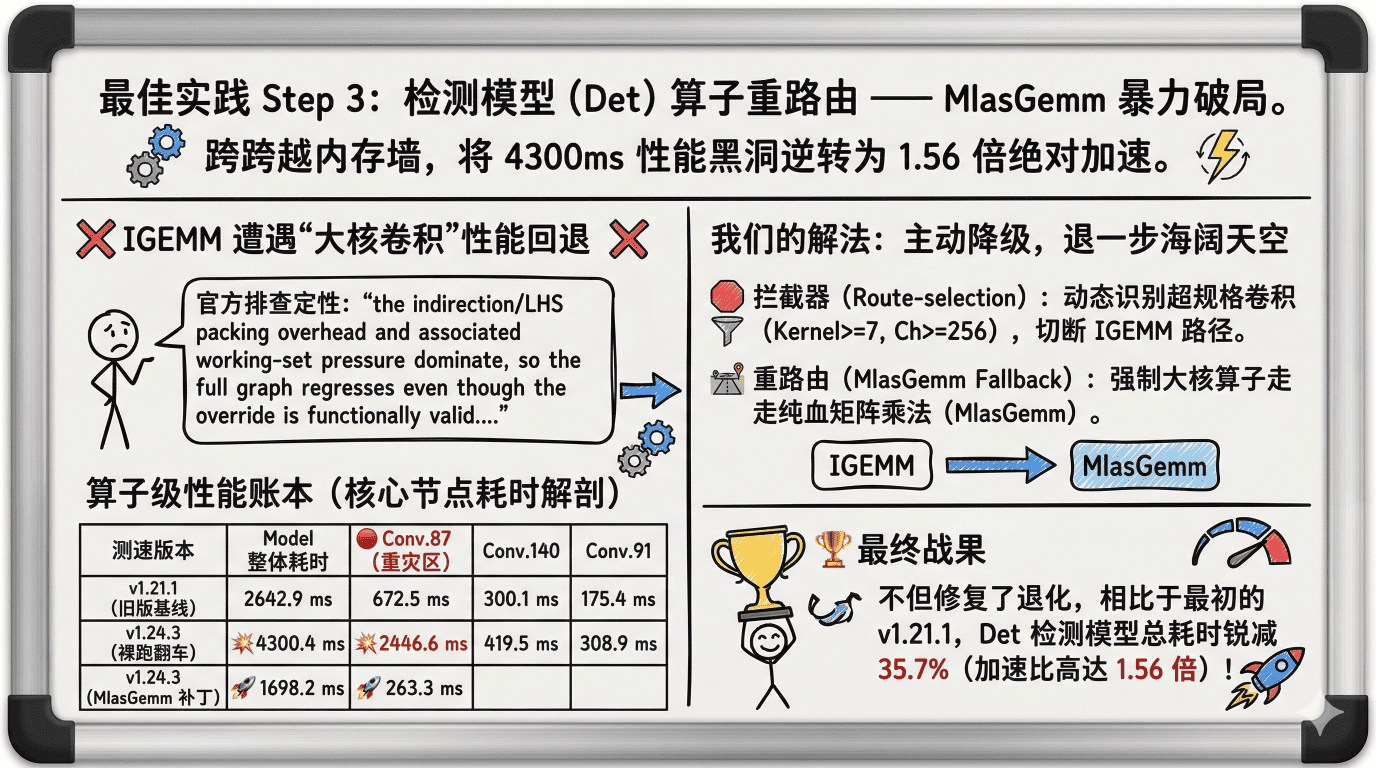
面对物理瓶颈,我们的解法非常硬核:使用拦截器,动态扫描大核卷积,一旦发现,直接切断 IGEMM 路径,让它们走传统的 MlasGemm 矩阵乘法。
补丁打上后,那个耗时 2446ms 的毒瘤算子瞬间被秒杀至 263ms,不仅修复了退化,更让 Det 模型总耗时锐减 35.7%,实现了 1.56 倍的绝对加速!
详情参见:
总结:软硬协同解锁端侧 AI
经历了所有的排雷与重构,我们最终斩获了**全链路 2.04 倍****的满血加速,并且将所有极其硬核的策略,浓缩为了仅 **550 行的单文件部署模块,实现了秒级生产迁移。
这就是我们沉淀的**"软硬协同解锁端侧AI"**方法论。
不要把模型当成黑盒,要让合适的算子,跑在最合适的硬件+算法实现路径上。
最后,我想用一句话作为今天的总结:
极致的 AI 推理加速,绝不是 API 的一键调用,而是模型结构、内存数据与底层的硬件的深度协同!
本文的代码已开源,欢迎克隆使用并给我们提出优化意见:github.com/AIwork4me/p…
