

面试官问:让你设计一个消息队列,你会怎么答?
很多人一听到这道题,第一反应就是开始背 Kafka、RabbitMQ、RocketMQ。
但这其实不是一道“背八股”的题,而是一道标准的系统设计场景题。
面试官真正想看的,不是你记住了多少名词,而是你能不能:
- 先抓住消息队列的本质需求
- 从简单版本一步步演进到可用架构
- 讲清楚性能、可靠性、顺序性、高可用之间的权衡
- 用工程视角回答“为什么这样设计”
这篇文章,我把这道经典题目整理成一篇适合收藏、适合复习、也适合公众号阅读的版本。
你看完之后,至少能做到两件事:
- 真正理解消息队列的核心设计思路
- 面试时能用一套清晰框架把答案讲出来
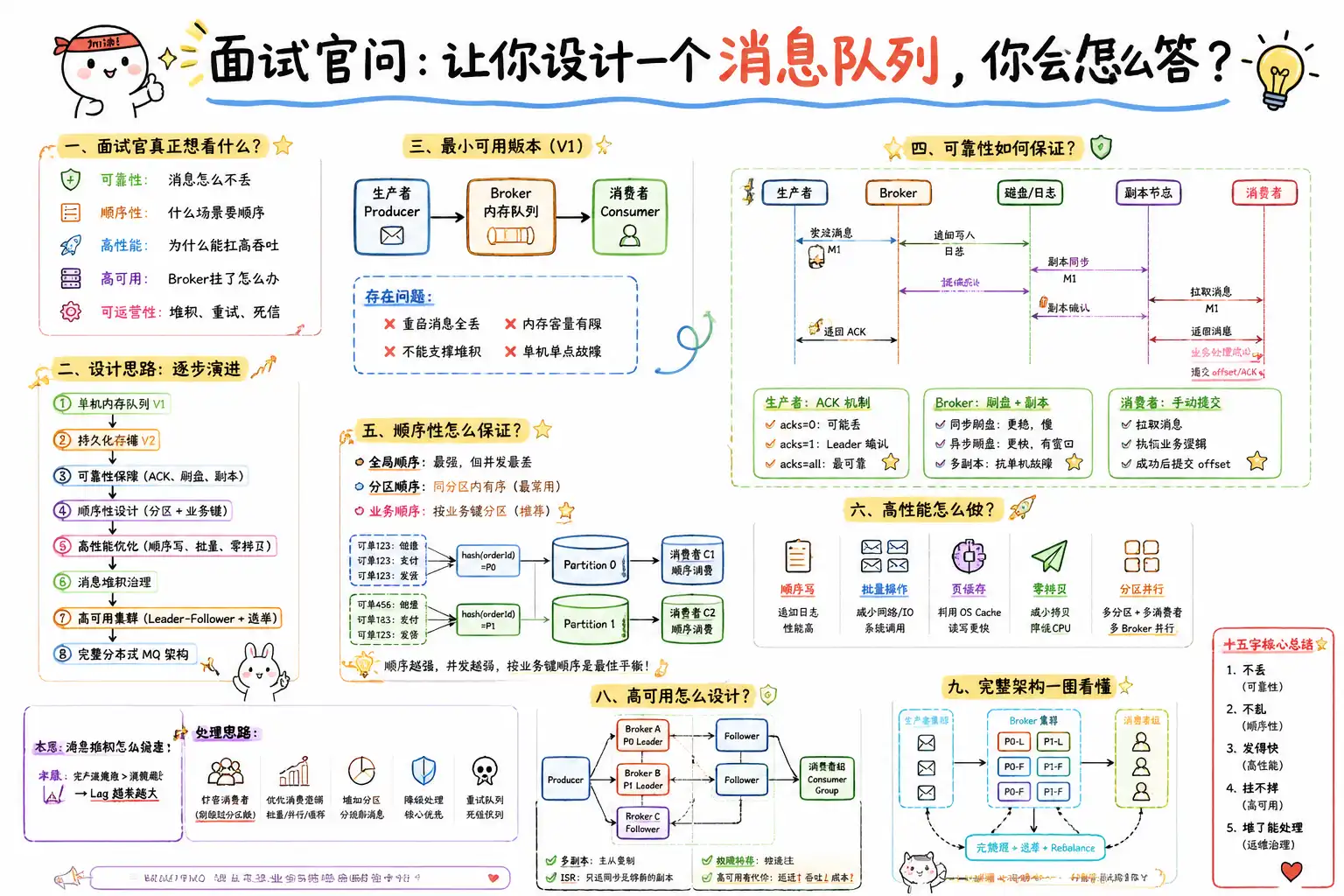
一、面试官真正想看什么
这道题表面是在问:
如果让你设计一个消息队列,你会怎么设计?
但它背后真正考察的是 5 个维度:
- 可靠性:消息怎么保证不丢
- 顺序性:什么场景要顺序,怎么保顺序
- 高性能:为什么能扛高吞吐
- 高可用:Broker 挂了怎么办
- 可运营性:消息堆积、失败重试、死信怎么处理
所以正确的回答方式,不是上来就说:
- 用零拷贝
- 用 Raft
- 用 ZooKeeper
- 用主从复制
而是应该这样展开:
先给出一个最小可用版本,再逐步解决“会丢、会乱、会慢、会挂、会堆积”这些问题。
二、回答这道题,最稳的方式是“逐步演进”
先从一个最简单的消息队列讲起,然后一层层补能力。
flowchart TD
A[单机内存队列 V1] --> B[持久化存储 V2]
B --> C[可靠性保障
ACK 刷盘 副本]
C --> D[顺序性设计
分区 + 业务键]
D --> E[高性能优化
顺序写 批量 零拷贝]
E --> F[消息堆积治理]
F --> G[高可用集群
Leader-Follower + 选举]
G --> H[完整分布式 MQ 架构]
面试里最怕一种回答:
一上来就直接抛最终架构,没有演进过程。
因为系统设计题最重要的,不是“终局长什么样”,而是你能不能解释:
为什么必须从这个版本演进到下一个版本。
三、第一步:先给出一个最小可用版本
最简单的 MQ,本质上就是一个生产者、一个 Broker、一个消费者,中间放一个队列。
flowchart LR
P[生产者 Producer] --> Q[Broker 内存队列]
Q --> C[消费者 Consumer]
这个版本的能力非常直接:
- 生产者把消息放进去
- Broker 临时存起来
- 消费者从里面取消息处理
如果你在面试里先讲这个版本,其实是加分的。
因为这说明你知道:
复杂系统不是凭空长出来的,而是从最小模型逐步长出来的。
这个版本为什么不够?
因为它只能说明“消息队列是什么”,还远远说明不了“消息队列怎么在生产环境可用”。
它至少有 4 个致命问题:
- 机器重启,消息全丢
- 内存容量有限,容易 OOM
- 不能支撑大量消息堆积
- 单机就是单点故障
所以第一轮演进,几乎一定是:
把消息从内存搬到磁盘。
四、第二步:先解决“消息会丢”的问题
1)为什么一定要持久化
消息队列不是普通缓存。
很多业务场景里,一条消息的背后可能就是一次下单、一次支付、一次库存扣减、一次发货通知。
如果消息因为 Broker 重启直接丢了,业务就会出严重问题。
所以 Broker 至少要具备一种能力:
收到消息后,把它可靠地落到磁盘。
2)存储为什么一般是顺序写
消息队列通常不会像数据库那样大量随机更新,而是不断追加新消息。
这就决定了一个很自然的设计:
- 数据按追加方式写入日志文件
- 一个 Topic 可以拆成多个 Partition
- 每个 Partition 内部是一个顺序追加日志
这样做的优势非常大:
- 顺序写性能高
- 结构简单
- 适合批量刷盘
- 便于按 offset 读取
可以把它理解成:
MQ 的底层核心,不像“表”,更像“日志”。
3)消息不丢,不只是刷盘这么简单
消息丢失其实可能发生在 3 个环节:
- 生产者发送到 Broker 的路上丢了
- Broker 还没真正落盘就挂了
- 消费者拿到消息但还没处理完就挂了
这 3 个环节,都要单独设计。
sequenceDiagram
participant P as 生产者
participant B as Broker
participant D as 磁盘/日志
participant R as 副本节点
participant C as 消费者
P->>B: 发送消息 M1
B->>D: 追加写入日志
B->>R: 副本同步 M1
R-->>B: 副本确认
B-->>P: 返回 ACK
C->>B: 拉取消息 M1
B-->>C: 返回消息
C->>C: 业务处理成功
C-->>B: 提交 offset / ACK
4)可靠性的 3 个关键机制
生产者侧:ACK 机制
生产者发完消息后,不能默认就算成功。
通常需要一个确认机制:
acks=0:不等确认,性能高,但可能丢acks=1:Leader 写成功就返回acks=all:所有 ISR 副本都确认后再返回,最稳
如果是订单、支付这类核心业务,面试里你最好明确表达:
我会优先选择更可靠的确认策略,比如
acks=all。
Broker 侧:刷盘 + 副本
只写内存不够,只刷本地磁盘也不够。
为什么?
- 只写内存:进程挂了就没了
- 只写本地盘:机器挂了也可能没了
所以通常需要:
- 刷盘策略:同步刷盘 or 异步刷盘
- 副本策略:主从复制 or 多副本复制
这里一定要讲权衡:
- 同步刷盘更可靠,但吞吐下降
- 异步刷盘更快,但会有短暂丢失窗口
消费者侧:处理成功后再提交 offset
消费者这边的经典坑是:
先提交 offset,再处理业务。
如果这样做,业务还没处理完,消费者挂了,Broker 会认为这条消息已经消费成功,于是消息就“逻辑丢失”了。
正确姿势通常是:
- 拉取消息
- 执行业务逻辑
- 业务成功后提交 offset
五、第三步:消息不重复,靠什么保证?
很多人会说:“那我设计成不重复消费就好了。”
但在分布式系统里,完全不重复其实非常难。
更现实的表达应该是:
Broker 尽量减少重复,业务侧通过幂等保证最终效果正确。
为什么会重复?
常见原因有两个:
- Broker 明明已经写成功了,但 ACK 回生产者时丢了,生产者以为失败,于是重试
- 消费者业务处理成功了,但 offset 提交失败,重启后又重新消费一次
面试里推荐怎么答
优先讲 幂等消费,因为这是最工程化的答案。
常见幂等方案:
- 用业务唯一键去重,比如订单号
- 用数据库唯一索引避免重复插入
- 用状态机控制合法状态流转
- 必要时用分布式锁控制重复执行
可以这样表达:
MQ 很难轻易承诺绝对不重复,我更倾向于在消费者侧做幂等,让系统整体达到“重复投递也不出业务错”的效果。
为了更直观理解消息生命周期,可以画成这样:
stateDiagram-v2
[*] --> 已创建
已创建 --> 已接收: Broker 收到消息
已接收 --> 已持久化: 写入日志成功
已持久化 --> 已复制: 副本同步成功
已复制 --> 可投递: 满足投递条件
可投递 --> 消费中: 消费者拉取消息
消费中 --> 已消费: 业务处理成功并提交 offset
消费中 --> 重试中: 处理失败
重试中 --> 消费中: 重试再次投递
重试中 --> 死信队列: 超过最大重试次数
死信队列 --> [*]
已消费 --> [*]
这张图你在面试里不一定真的画得这么全,但你脑子里最好有这条状态链。
六、第四步:顺序性到底该怎么保证?
顺序性是这道题很高频的追问。
但顺序性不是一句“我保证顺序”就讲清楚的。
你要先区分 3 种顺序:
1)全局顺序
所有消息严格按发送顺序消费。
这当然最强,但代价也最大:
- 基本只能单分区
- 很难并行扩展
- 吞吐容易被打死
所以一般不推荐。
2)分区顺序
同一分区内严格有序,不同分区之间不保证顺序。
这是最常见、也最实用的方案。
3)业务顺序
同一个业务实体内部有序,比如:
- 同一订单:创建 → 支付 → 发货
- 同一用户:注册 → 绑卡 → 首单
这通常是最合理的答案。
做法是:
按业务 ID 做分区,让同一业务对象的消息永远落到同一 Partition。
flowchart LR
P1[订单 123 创建] --> K1["hash(orderId) → P0"]
P2[订单 123 支付] --> K1
P3[订单 123 发货] --> K1
Q1[订单 456 创建] --> K2["hash(orderId) → P1"]
Q2[订单 456 支付] --> K2
Q3[订单 456 发货] --> K2
K1 --> A[Partition 0]
K2 --> B[Partition 1]
A --> C1[消费者 C1 顺序消费]
B --> C2[消费者 C2 顺序消费]
顺序消费的难点是什么?
难点不在“落同一个分区”,而在“失败时怎么办”。
比如某个分区里:
- M1 失败了
- M2、M3、M4 都在后面排队
如果你要求严格顺序,那后面的消息都得等 M1。
所以顺序性的本质权衡是:
顺序越强,并发能力越弱。
面试里推荐的回答方式是:
大多数场景我会保证业务键级别的顺序,而不是全局顺序。这样既能满足业务需求,也能保留并行能力。
七、第五步:高性能怎么做?
如果面试官追问:“那怎么做到高吞吐?”
你可以从 5 个点展开。
1)顺序写
顺序写磁盘远快于随机写。
消息天然适合追加写日志,所以 MQ 在存储模型上,天生有高吞吐优势。
2)批量操作
无论是生产者发送、Broker 刷盘,还是消费者拉取,批量都非常关键。
因为批量可以减少:
- 网络往返次数
- 系统调用次数
- 磁盘 I/O 次数
3)页缓存
很多 MQ 不会每条消息都立刻打到底层物理盘,而是先进入 OS Page Cache。
好处是:
- 写路径更顺滑
- 热数据读取更快
- 操作系统帮你做缓存管理
4)零拷贝
如果 Broker 要把磁盘里的消息发给消费者,可以减少用户态与内核态之间的多次拷贝。
这能显著降低 CPU 消耗,提高吞吐。
5)分区并行
高吞吐不是靠一台机器硬扛出来的,而是靠多分区 + 多消费者 + 多 Broker 并行处理。
高性能部分,面试里怎么概括最漂亮?
可以直接背这一句:
MQ 的高性能,本质来自于顺序写、批量处理、缓存利用和分区并行,而不是单点技术奇迹。
八、第六步:消息堆积怎么办?
这也是非常常见的追问。
消息堆积本质上就是:
生产速度 > 消费速度
一旦这种差值持续存在,Lag 就会越来越大。
常见堆积原因
- 消费逻辑太慢
- 外部依赖太慢,比如数据库、下游接口
- 消费者实例数不够
- 分区数不足
- 某个消费者异常退出
处理堆积,别只会说“扩容”
扩容当然是手段之一,但不是唯一答案。
更完整的处理思路,应该是这样:
flowchart TD
A[发现消息堆积 / Lag 飙升] --> B{先看原因}
B -->|消费逻辑慢| C[优化业务处理
批量 异步 缓存]
B -->|消费者数量不足| D[扩容消费者实例]
B -->|分区数量不足| E[增加分区分流新消息]
B -->|下游服务慢| F[限流/降级/熔断]
B -->|失败消息过多| G[重试队列 + 死信队列]
C --> H[恢复消费速率]
D --> H
E --> H
F --> H
G --> H
实战里常见的治理手段
1)扩容消费者
前提是:消费者数量不要超过分区数。
因为同一个消费者组内,一个分区同一时刻通常只能由一个消费者实例处理。
2)优化消费逻辑
比如:
- 单条处理改为批量处理
- 串行 I/O 改为并行 I/O
- 数据库单条写改成批量写
- 高频查询加缓存
3)增加分区
这是用来提高后续并行消费能力的,但要注意:
- 新消息可以分流到新分区
- 老消息不会自动迁移
- 有些系统扩分区后会影响原有哈希分布,需要评估
4)降级处理
业务峰值时,不同消息的重要性可能不一样。
你可以把消息拆成:
- 核心消息:必须优先处理
- 重要消息:尽量处理
- 普通消息:允许延迟甚至丢弃
面试里如果你能提到“优先级队列”“死信队列”“重试队列”“Lag 监控”,基本就已经比大多数答案更完整了。
九、第七步:高可用怎么设计?
前面解决的是“消息能不能稳稳地进来和出去”。
但只要还是单 Broker,就始终有一个问题:
这台 Broker 挂了怎么办?
所以消息队列最终一定会走向集群化。
典型思路:Leader-Follower
每个 Partition 都会有多个副本:
- 一个 Leader 负责读写
- 多个 Follower 负责同步数据
一旦 Leader 挂了,就从同步足够新的副本里选一个新的 Leader 顶上来。
flowchart TB
subgraph ProducerSide[生产者集群]
P1[Producer 1]
P2[Producer 2]
end
subgraph Cluster[Broker 集群]
subgraph B1[Broker 1]
P0L[Partition 0 Leader]
P1F[Partition 1 Follower]
end
subgraph B2[Broker 2]
P0F[Partition 0 Follower]
P1L[Partition 1 Leader]
end
subgraph B3[Broker 3]
P0F2[Partition 0 Follower]
P1F2[Partition 1 Follower]
end
end
subgraph Meta[协调服务]
M[元数据管理 / 选举 / Rebalance]
end
subgraph ConsumerSide[消费者组]
C1[Consumer 1]
C2[Consumer 2]
end
P1 --> P0L
P2 --> P1L
P0L --> P0F
P0L --> P0F2
P1L --> P1F
P1L --> P1F2
P0L --> C1
P1L --> C2
M -.协调.-> B1
M -.协调.-> B2
M -.协调.-> B3
M -.协调.-> C1
M -.协调.-> C2
高可用的关键点,不只是“有副本”
面试里一定要讲到下面几个词:
1)副本机制
- 一个 Partition 有多个副本
- Leader 负责读写
- Follower 负责追赶同步
2)故障转移
Leader 宕机后,要能快速选举出新 Leader。
3)ISR 机制
不是所有副本都适合被选为 Leader。
更合理的做法是:
只有和 Leader 保持足够同步的副本,才有资格进入 ISR,才有资格在故障时接管。
这样做的核心目的,是避免把一个“数据落后很多”的副本选成新 Leader,导致更多消息丢失。
高可用一定要顺手讲一个权衡
高可用不等于没有代价。
副本越多、确认越严格,系统越稳,但:
- 写入延迟会上升
- 吞吐会下降
- 集群管理更复杂
所以成熟的回答应该是:
我会根据业务重要性来选择副本数、ACK 策略和刷盘策略,而不是所有 Topic 一刀切。
十、完整的消息队列设计,脑图应该长什么样
到这里,你其实已经可以把整道题串起来了。
mindmap
root((消息队列设计))
核心能力
生产者发送
Broker 存储
消费者消费
可靠性
ACK 机制
刷盘策略
副本同步
手动提交 offset
幂等消费
顺序性
全局顺序
分区顺序
业务键顺序
高性能
顺序写
批量发送
页缓存
零拷贝
分区并行
高可用
Leader-Follower
多副本
ISR
Leader 选举
运营治理
Lag 监控
重试队列
死信队列
降级处理
你可以把这张脑图理解成:
一道消息队列设计题,最终其实就是围绕“存得住、发得快、顺序对、挂不掉、堵了能处理”这几个目标展开。
十一、如果是实际业务场景,该怎么落地?
场景 1:电商订单链路
如果是订单、库存、支付这类核心链路,重点一定不是极致吞吐,而是:
- 不能丢
- 不能乱
- 重复投递不能造成重复扣减
这类场景的典型思路:
- 分区按
orderId路由 - ACK 选择更可靠策略
- 副本数至少 3
- 消费端做幂等控制
- 失败消息进入重试或死信
场景 2:日志收集链路
如果是日志、埋点、监控采集,重点又会变成:
- 吞吐优先
- 成本优先
- 允许少量丢失
这类场景更倾向于:
- 更大的批量
- 更激进的压缩
- 相对宽松的 ACK 策略
- 异步刷盘
所以你在面试里一定要体现一个意识:
没有完美的 MQ 设计,只有适合当前业务目标的设计。
十二、这道题最容易犯的 4 个错误
错误 1:上来就背 Kafka
错误说法:
Kafka 是这样设计的……
更好的说法:
我会先从一个最小模型出发,再逐步引入持久化、分区、副本和高可用机制,这套思路和 Kafka 这类成熟 MQ 的设计方向是一致的。
错误 2:只会堆名词,不会解释问题
比如只说:
- 零拷贝
- ZooKeeper
- Raft
- ISR
但说不清:
- 它解决什么问题
- 为什么放在这个阶段引入
- 会带来什么代价
错误 3:把“高可靠”和“绝不重复”混在一起
面试里最好明确:
- 不丢失 ≠ 不重复
- 不重复 ≠ 绝对 exactly-once
- 很多时候要靠幂等设计实现业务结果正确
错误 4:没有权衡意识
系统设计题最怕一种表达:
这个方案什么都能保证,而且没有代价。
这是不可能的。
真正成熟的表达应该是:
- 同步刷盘更稳,但更慢
- 单分区顺序最强,但并发最差
- 副本更多更稳,但写入更贵
- 批量更高吞吐,但延迟会上升
十三、面试时,一套标准回答模板怎么说
下面这套结构,基本可以直接拿去用。
第一步:先确认需求边界
你可以先问:
- 消息量级有多大?
- 对可靠性的要求是什么?
- 是否要求顺序性?
- 更关注低延迟还是高吞吐?
- 是否要支持消息堆积和故障切换?
这样做的价值在于:
你不是在背标准答案,而是在根据业务要求设计系统。
第二步:先给最小模型
可以这样说:
我会先从单 Broker 的生产者—队列—消费者模型开始,用它定义消息发送、存储和消费的最基本流程。
第三步:逐个补齐核心能力
接着按顺序讲:
- 持久化:解决重启丢消息
- ACK + 副本:解决传输和单机故障
- 手动提交 offset:解决消费过程丢消息
- 幂等消费:解决重复投递
- 分区 + 业务键:解决顺序与扩展性
- 批量、顺序写、零拷贝:解决高吞吐
- 集群、副本、选举:解决高可用
- 重试、死信、Lag 监控:解决运营治理问题
第四步:最后一定讲权衡
这一句非常关键:
这个系统的核心不是追求某一个指标极致,而是在可靠性、顺序性、性能和成本之间做平衡。
十四、如果让我用 1 分钟总结这道题,我会这样答
我会先设计一个最简单的生产者—Broker—消费者模型,然后通过持久化解决内存丢失问题,通过 ACK、刷盘和副本机制保证可靠性,通过消费者手动提交 offset 和幂等设计控制重复消费,通过按业务键分区保证局部顺序,通过顺序写、批量处理、零拷贝和分区并行提升吞吐,最后通过多副本、Leader 选举和 ISR 机制实现高可用。同时,我会根据业务场景在可靠性、实时性和性能之间做权衡,而不是追求绝对完美的设计。
如果你把这一段说顺了,已经足够覆盖大部分面试官的预期。
十五、最后总结
设计一个消息队列,核心不是炫技术,而是抓住主线:
你真正要解决的,是这 5 个问题
- 消息怎么不丢
- 消息怎么不乱
- 消息怎么发得快
- Broker 挂了怎么办
- 消息堆积了怎么办
你真正要体现的,是这 3 个能力
- 从简单系统逐步演进的能力
- 讲清技术方案与业务目标关系的能力
- 说明设计权衡的能力
